Zookeeper(九)依赖于ZooKeeper的分布式消息系统Kafka
Kafka
Kafka是知名社交网络公司LinkedIn于2010年12月份开源的分布式消息系统,主要由Scala语言开发,于2012年成为Apache顶级项目,目前被广泛应用在包括Twitter,Netffix和Tumblr等在内的大型互联网站点上。
Kafka主要用于实现低延迟的发送和收集大量的事件和日志数据——这些数据通常都是活跃的数据通常都是活跃的数据。所谓活跃数据,在互联网大型的Web网站应用中非常常见,通常是指网站的PV数和用户访问记录等。这些数据通常以日志的形式记录下来,然后有一个专门的系统来进行日志的收集与统计。
Kafka是一个吞吐量极高的分布式消息系统,其整体设计是典型的发布与订阅模式系统。在Kafka集群中,没有“中心主节点”的概念,集群中所有的服务器都是对等的,因此。可以在不做任何配置更改与删除,同样,消息的生产者和消费者也能够做到随意重启和机器的上下线。Kafka服务器及消息生产者和消费者之间的部署关系如下图所示: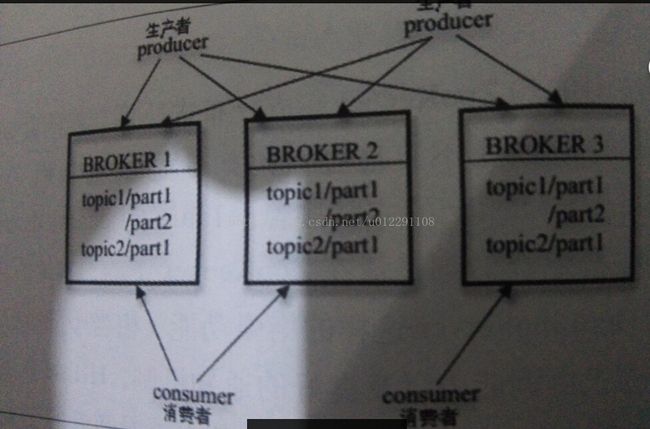
Broker注册
Broker:几Kafka的服务器,用于存储消息,在消息中间件中通常被称为Broker。
Offset:消息存储在Kafka的Broker上,消费者拉取消息数据的过程中需要知道消息在文件中的偏移量,这个便宜量就是所谓的Offset。
Kafka是一个分布式消息系统,这也体现在起Broker,Producer和Consumer的分布式部署上。虽然Broker是分布式部署并且相互之间是独立运行的,但还是需要有一个注册系统能够将整个集群中的Broker服务器都管理起来。在Kafka的设计中,选择了ZooKeeper来进行所有Broker的管理。
在ZooKeeper上会有一个专门用来进行Broker服务器列表记录的节点,下文中我们称为ieee“Broker”节点,起节点路径为/brokers/ids。
每个Broker服务器在启动时,都会到ZooKeeper上进行注册,即到Broker节点下创建属于自己的节点,其节点路径为/broker/ids[0...N]
从上面的节点路径中,我们可以看到,在Kafka中,我们使用一个全局唯一的数字来指代每一个Broker服务器,可以称其为“BrokerID”,不同的Broker必须使用不同的BrokerID进行注册,例如/broker/ids/1和/broker/ids/2分别代表了两个Broker服务器。创建完Broker节点后,每个Broker就会将自己的IP地址和端口等信息写入到该节点中。
请注意,Broker创建的节点是一个临时节点,也就是说,一旦这个Broker服务器宕机或是下线后,那么对应的Broker节点也就被删除了。因此我们可以通过ZooKeeper上Broker界定啊的变化情况来动态表征Broker服务器的可用性。
Topic注册
在Kafka中,会将同一个Topic的消息分成多个分区并将其分分布到多个Broker上,而这些分区信息以及驭Broker的对应关系也都是由ZooKeeper维护的,由专门的节点来记录,其节点路径为/brokers/topics。下文中我们将这个节点称为“Topic”u节点。Kafka中的每一个Topic,都会以/brokers/topecs/[topic]的形式记录在这个节点下,例如/brokers/topics/login和/brokers/topics/search等。
Broker服务器在启动后,会到对应的Topic节点下注册自己的BrokerID,并写入针对Topic的分区总数。例如,/brokers/topics/login/->2这个节点表明BrokerID为3的一个Broker服务器,对于“login”这个Topic的消息,提供了2个分区进行消息存储。同样,这个分区数节点也是一个临时节点。
消费分区与消费者关系
对于每个消费者分组,Kafka都会为其分配一个全局唯一的GroupID,同一个消费者分组内部的所有消费者都共享该ID。同时Kafka也会为每个消费者分配一个ConsumerID,通常采用“Hostname:UUID”的形式来表示。在Kafka的设计中,规定了每个消息分区有且只能同时有一个消费者进行消息的消费,因此,需要在ZooKeeper上记录下消费分区驭消费者之间的对应的关系。每个消费者一旦确定了对一个消息分区的消费权利,那么需要将其ConsumerID写入到对应消息分区的临时节点上,例如/consumers/[group_id]/owners/[topic]/[broker_id-partition_id],其中“[broker_id-partition_id]”就是一个消息分区的标识,节点内容局势消费分区上消息的消费者的ConsumerID。
消费消息进度Offset记录
在消费者对指定消息分区进行消息消费的过程中,需要定时地将分区消息的消费进度,即Offset记录到ZooKeeper节点上,以便在该消费者进行重启或者其他消费者重新接管该消息分区的消息消费后,能够从之前的进度开始继续进行消息的消费。Offset在ZooKeeper上的记录由一个专门的节点负责,起节点路径为/consumer/[group_id]/offsets/[topic]/[broker_id-partition_id],起节点内容就是Offset值。
消费者注册
下面我们来看看消费者服务器在初始化启动时加入消费者分组的过程。
1.注册到消费者分组。
每个消费者服务器在启动的时候,都会到ZooKeeper的指定节点下创建一个属于自己的消费者节点,例如/consumers/[group_id]/ids/[consumer_id].
完成节点创建后,消费者会将自己订阅的Topic信息写入该节点。注意,该节点也是一个临时节点,也就是说,一旦消费者服务器出现故障或是下线后,其对应的消费者节点就会被删除。
2.对消费者分组中消费者的变化注册监听。
每个消费者都需要关注所属消费者分组中消费者服务器的变化情况,即对/consumers/[group_id]/ids节点注册子节点变化的Watcher监听。一旦发现消费者新增或减少,就会触发消费者的负载均衡。
3.对Broker服务器的变化注册监听。
消费者需要对/brokers/ids/[0...N]中的节点进行监听的注册,如果发现Broker服务器列表发生变化,那么就根据具体情况来决定是否需要进行消费者的负载均衡。
4.进行消费者负载均衡。
所谓消费者负载均衡,是指为了能够让同一个Topic下不同分区的消息尽量均衡地被多个消费者消费者消费而进行的一个消费者于消费分区分配的过程。通常,对于一个消费者分组,如果组内的消费者服务器发上变更或Broker服务器发生变更,会触发消费者负载均衡。
小结
Kafka从设计之初就是一个大规模的分布式i消息中间件,其服务端存在多个Broker,同时为了达到负载均衡,将每个Topic消息分成了多个分区,并分布在不同的Broker上,对各生产者和消费者能够同时发送和接收消息。Kafka使用ZooKeeper作为分布式协调框架,很好滴将消息生产,消息存储和消息消费的过程有机地结合起来。同时借助ZooKeeper,Kafka能够在保持包括生产者,消费者和Broker在内的所有组件无状态的情况下,建立起生产者和和消费者之间的订阅关系,并实现了生产者和消费者的负载均衡。