第一部分 Spark介绍
第二部分 Spark的使用基础
第三部分 Spark工具箱
第四部分 使用不同的数据类型
第五部分 高级分析和机器学习
第六部分 MLlib应用
第七部分 图分析
第八部分 深度学习
本系列文档翻译自DataBricks公司于发布的Spark教程文档《A Gentle Introduction to Apache Spark》、《The Data Engineer's Guide to Apache Spark》、《Data Scientists Guide to Apache Spark》。
这三篇文档包括了《Spark权威指南》的主体结构。在介绍各工具包时,只取《权威指南》中的一个例子做介绍。非常适合入门学习,而可将《权威指南》作为工具书使用。
Apache Spark 是针对计算机集群上的并行数据处理 的 统一的计算引擎 和 一系列函数库。
spark支持 多种广泛使用的编程语言(python, java, scala, R),包含为不同任务,从SQL到流处理到机器学习,提供的函数库。可以在 从笔记本到 具有数以千计节点的集群 上运行。这使spark称为一个很容易 入手的 简单系统,并可扩展到大数据分析 乃至 难以置信的大规模分析。
如下是一个spark所提供给终端用户的 所有支持的简单的阐述。

Spark的理念
让我们 分解我们对Apache Spark的描述——一个 统一的 计算引擎 和 一系列大数据函数库(a unified computing engine and set of libraries for big data)——为其基础组分。
unified:
Spark的关键驱动目标 是提供一个为编写大数据应用的 统一的平台。统一的含义是什么?Spark被设计用来 在同样的计算引擎和一系列一致的api 下 支持广泛的数据分析任务,从简单的数据加载和sql查询 到机器学习 和流计算。
这一目的背后的主要洞见 是现实世界的数据分析任务——不论它们是在像Jupyter notebook一样的工具上的交互式分析,还是传统的产品应用的软件开发——趋向于 将许多不同类别的进程和函数库 结合在一起。
Spark统一的性质使得这些任务 即简单 有异于编写。 首先,Spark提供一致的,可组合的APIs,可用来构建应用而只需要较小的块(代码块)和现有的函数库。这使得我们可以很容易地编写我们自己的分析库。
然而,可组合的APIs还不够:在一个用户程序中不同的库和函数交叉组合在一起,Spark 的APIs 还通过最优化保证高性能。比如,如果你加载数据使用了SQL查询,然后使用ML库来评估机器学习模型,引擎会组合这些步骤到一个对数据的扫描scan中。
常规APIs的整合和高性能执行 使Spark成为一个强大的交互和产品应用平台。
spark 对界定一个统一的平台 的关注 是与 其他软件领域的统一平台 相同的观点。
比如,数据科学家 在建模时 得益于一个统一的函数库(python或R),web开发者得益于例如Node.js或Django这样的统一框架。在Spark之前,没有一个开源系统视图提供并行数据处理这种类型的统一引,这意味着用户必须将多个APIs和系统组合成一个应用程序。因此,Spark很快成为了这类开发的标准。随着时间的过去,Spark继续扩展其内嵌的APIs去覆盖更多的工作量。同时,项目的开发者不断地完善其统一引擎的主题。尤其是,在Spark2.0完成的结构化APIs(DataFrames,DtaSets,SQL)在用户应用程序中支持更强大的优化。
Computing Engine:
Spark在努力解决统一性问题的同时,Spark还小心地将其范围限制为计算引擎。 因此,Spark只处理从存储系统中加载数据 和 对其进行计算的工作,而不是将永久存储作为目的。
Spark可以同多种永久存储系统一起工作,包括云储存系统(如Azure Storage和 Amazon S3),分布式文件系统(如Apache Hadoop),键值存储(如Apache Cassandra)以及信息总线(如Apache Kafka)。然而,Spark既不自己长期存储数据,也不支持其中之一。
主要的动机是因为 大多数数据已经存储在各种存储系统中。数据转移花费巨大,所以Spark关注于对数据的计算,而不论数据存储在哪里。在面向用户的APIs中,Spark专注于让这些存储系统看起来 在很大程度上是类似的,所以应用不必担心他们的数据在哪。
Spark专注计算 使得它不同于早期的大数据软件平台,如Apache Hadoop。Hadoop包含一个存储系统(Hadoop文件系统,为商用服务器集群上的低费用存储 而设计)和一个计算系统(MapReduce),两者紧密地结合在一起。然而,这种选择 使 其中一个系统在没有另一个系统时 很难运行。甚至更重要的是,需要编写 访问任何其他数据存储系统的 应用。
然而,Spark在Hadoop存储上运行得很好,如今也被广泛应用在Hadoop框架没有意义的 环境中,例如公有云(其存储可以与计算分开)或流 应用程序。
Libraries:
Spark的最终目的是它的函数库,其构建在其作为一个统一的引擎之上,来为通常的数据分析任务提供统一的API。 Spark支持 随计算引擎附带的标准函数库,也支持大量的来自开源社区的第三方外部函数库。如今,Spark的标准函数库实际上是开源社区的主要部分:Spark核心引擎自引起首次开放以来 变化不大,但函数库所提供的功能 已发展得越来越多。
Spark函数库包括 支持SQL和结构化数据的(SparkSQL)、支持机器学习的(MLlib)、支持流处理的(Spark Streaming和更新的Structured Streaming)、支持图像分析的(GraphX)。除此之外,还有丰富的 从各种存储系统的连接器到机器学习算法的 开源外部函数库。
这些外部库的索引可以在spark-packages.org中查到。
Spark的基础架构
Spark是一个管理和协调 在一个计算机集群上的数据上执行的任务 的工具。
Spark用来执行任务的集群 会有一个集群管理器来管理,如Spark的独立集群管理器、YARN或Mesos。我们会提交Spark应用到 这些集群管理器,管理器会为应用分配资源 来进行计算工作。
Spark应用
Spark应用包含一个驱动进程(driver process) 和一系列执行进程(executor processes)。
驱动进程 运行main()函数,其位于集群的一个节点上,对负责三个事情:
维护Spark应用的信息;响应用户的程序或输入;分析、分配和调度各执行器之间的工作(暂定)。
驱动进程是最根本的——是Spark应用的核心 并在应用的整个生命周期中维护所有相关数据。
执行器负责实际执行 驱动程序分配给他们的工作。这意味着,每个执行器只负责两个事情:
执行驱动程序分配给它的代码;向驱动节点 报告执行其的 计算状态。
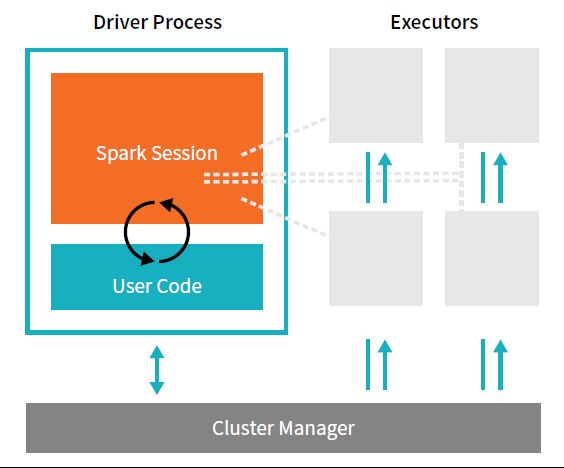
集群管理器 控制物理机器, 并为Spark应用 分配资源。管理器可以是几个核心集群管理器之一:Spark的独立集群管理器、YARN或Mesos。这意味着同一时间集群上可以运行多个Spark应用。
Production Applications一节会深入讨论集群管理器。
Spark除了集群模式,还有本地模式。驱动器和执行器都是单进程,这意味这他们可以在相同或不同的机器上运行。
在本地模式,他们都以线程的形式运行在个人电脑上。 本书以本地模式进行编写。
Spark的Language APIs
Spark的语言APIs允许你 通过其他语言来 运行Spark。在很大程度上,Spark为每种语言提供相同的概念,这些概念被编译为Spark代码 并运行在集群机器上。
如果你使用 结构化的APIs,你可以期望所有语言都具有相同的性能特征。

每个语言APIs会维护同样的之前提到的核心概念。会有一个用户可用的SparkSession,SparkSession会是运行Spark代码的入口。当使用 来自Python或R的Spark时,用户不需要明确地编写JVM指令,而只需要编写Python或R代码,Spark会将其编译为Spark可以在执行器JVM上运行的代码。
Spark APIs
虽然Spark可 由多种语言编写,但Spark为这些语言提供哪些支持 是值得一提的。
Spark有两种基本的APIs: 低级别的“非结构化”APIs 和 更高级别的 结构化APIs。本书中会介绍这两种APIs,但在介绍性章节 着重关注于 高级别的APIs。