MXNet的预训练:fine-tune.py源码详解
在MXNet框架下,如果要在一个预训练的模型上用你的数据fine-tune一个模型(或者叫迁移学习,即你的模型的参数的初始化不再是随机初始化,而是用别人的在大数据集上训练过的模型的参数来初始化你的模型参数),可以采用MXNet项目自带的fine-tune.py脚本,路径是~/mxnet/example/image-classification/fine-tune.py,这里的mxnet就是你从mxnet官方git上clone下来的项目名称,git地址:https://github.com/dmlc/mxnet。
接下来详细fine-tune.py的内容,总的流程就是:解析参数,导入预训练的模型,修改预训练模型的最后分类层,开始训练。
import os
import argparse
import logging
logging.basicConfig(level=logging.DEBUG)
from common import find_mxnet
from common import data, fit, modelzoo
import mxnet as mx
'''
这个函数的作用就是从原来导入的一个symbol(就是你导入的这个文件:###-symbol.json),
生成一个新的symbol:net和arguments:new_args,new_args是需要训练的参数名
'''
def get_fine_tune_model(symbol, arg_params, num_classes, layer_name):
"""
symbol: the pre-trained network symbol
arg_params: the argument parameters of the pre-trained model
num_classes: the number of classes for the fine-tune datasets
layer_name: the layer name before the last fully-connected layer
"""
all_layers = sym.get_internals()
net = all_layers[layer_name+'_output']
net = mx.symbol.FullyConnected(data=net, num_hidden=num_classes, name='fc')
net = mx.symbol.SoftmaxOutput(data=net, name='softmax')
new_args = dict({k:arg_params[k] for k in arg_params if 'fc' not in k})
return (net, new_args)
if __name__ == "__main__":
# parse args
# 在这个参数解析中,主要采用~/mxnet/example/image-classification/common目录下的fit.py中的add_fit_args()函数,
# data.py中的add_data_args()函数和add_data_aug_args()函数。这三个函数都是和参数配置相关。
parser = argparse.ArgumentParser(description="fine-tune a dataset",
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
train = fit.add_fit_args(parser)
data.add_data_args(parser)
aug = data.add_data_aug_args(parser)
parser.add_argument('--pretrained-model', type=str,
help='the pre-trained model')
parser.add_argument('--layer-before-fullc', type=str, default='flatten0',
help='the name of the layer before the last fullc layer')
# use less augmentations for fine-tune
data.set_data_aug_level(parser, 1)
# use a small learning rate and less regularizations
parser.set_defaults(image_shape='3,224,224', num_epochs=30,
lr=.01, lr_step_epochs='5', wd=0, mom=0)
# 这个num_epochs表示一共要进行的epoch的次数,lr表示学习率,lr_step_epochs表示在进行到第几个epoch的时候需要修改lr,
# 所以如果你要在第5和第10个epoch的时候修改lr,可以写成lr_step_epochs=‘5,10’。
args = parser.parse_args()
# load pretrained model
dir_path = os.path.dirname(os.path.realpath(__file__))
(prefix, epoch) = modelzoo.download_model(
args.pretrained_model, os.path.join(dir_path, 'model'))
if prefix is None:
(prefix, epoch) = (args.pretrained_model, args.load_epoch)
sym, arg_params, aux_params = mx.model.load_checkpoint(prefix, epoch)
# 这里采用~/mxnet/python/mxnet目录下的model.py脚本中的load_checkpoint函数来导入.param和.json文件,
# 前者是网络的参数,后者是网络的结构。这个load_checkpoint函数比较重要,
# 如果你想导入不同模型的参数和结构,可以在load_checkpoint函数中做修改。
# remove the last fullc layer
(new_sym, new_args) = get_fine_tune_model(
sym, arg_params, args.num_classes, args.layer_before_fullc)
# train
# 这里采用~/mxnet/example/image-classification/common文件夹下的fit.py脚本中的fit函数来启动训练,
# 这是作者写好的一个方便训练的脚本,在那个fit函数中最终是调用model下的fit函数,
# 也就是我们在MXNet官网上看到的那个启动函数,详细参考后面附录的fit.py脚本的fit函数。
fit.fit(args = args,
network = new_sym, #用了新的symbol
data_loader = data.get_rec_iter,
arg_params = new_args,
aux_params = aux_params)因此如果你要在命令行fine-tune一个模型,可以执行如下命令:
cd ~/mxnet #先进入mxnet项目的根目录
python mxnet/example/image-classification/fine-tune.py --pretrained-model imagenet1k-resnet-50 --load-epoch 0000
--gpus 0 --data-train /data/train_data.rec --data-val /data/test_data.rec --batch-size 16
--num-classes 3 --num-examples 50000 --model-prefix output/resnet-50解释下上面这个命令:python表示运行后面的这个fine-tune.py脚本;–pretrained-model表示预训练的模型,这里我用的是imagenet1k-resnet-50,这个名字在mxnet项目的默认预训练模型里面,运行的时候会从相应的网上下载模型的.param和.json文件,分别表示网络的参数和结构信息;–load-epoch 0000 表示导入的模型是imagenet1k-resnet-50-0000.params,在MXNet中,.params文件的命名后面一般都会跟epoch信息,表示一共将所有训练数据迭代多少次;–gpus 表示gpu的ID;–data-train和data-val分别表示训练集和验证集,这里我采用的是.rec格式的数据;–batch-size表示每个batch的样本数量;–num-classes 表示分类的类别数;–num-examples表示训练样本数;–model-prefix表示训练的结果要保存的路径和前缀名称,这里每运行完一个epoch就会保存这时的.params文件。以上这几个参数缺一不可,其他参数你没有在这个命令行中添加的话表示你采用默认值。
在你运行上面的fine-tune.py脚本的时候,假设你一共要运行10个epoch,但是运行到第8个epoch的时候不小心中断了,你的output文件夹下面最多只有resnet-50-0007.params和resnet-50-symbol.json,如下图:

然后你想从这resnet-50-0007.params开始训练,类似Caffe中的断点训练,怎么做呢?可以这样:
python mxnet/example/image-classification/fine-tune.py --pretrained-model output/resnet-50 --load-epoch 0007
--gpus 0 --data-train /data/train_data.rec --data-val /data/test_data.rec --batch-size 16
--num-classes 3 --num-examples 50000 --model-prefix output/resnet-50简单修改了–pretrained-model和–load-epoch,但是这里有个非常重要的地方要注意,那就是你的fine-tune.py脚本中的这个参数: lr_step_epochs=’5’,这个参数表示你进行到第5个epoch的时候会修改你的学习率,因此这个值现在是5,比你要开始训练的7要小,所以会有这样的报错:
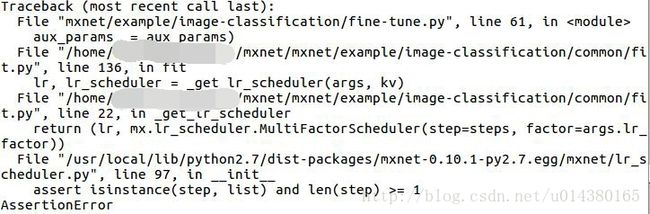
从报错可以看出具体原因就是在fit.py脚本中的这个_get_lr_scheduler函数,在return之前有个steps的计算,里面的if x-begin_epoch>0是不满足的,所以steps是没有值的,从而导致在assert isinstance(step,list) and len(step) >=1中至少len(step)>=1不满足。另外从下面这个函数中的for循环可以看出学习率的变化是直接将当前lr乘以lr_factor,这个lr_factor是默认的参数,默认是0.1,可以看附录中fit.py脚本中的add_fit_args()函数,当然你也可以在你的命令行中指定这个参数。
所以你需要修改fine-tune.py中的lr_step_epochs数值,使得它至少有一个数是大于你当前导入的.params文件的epoch值。
附录:
fit.py脚本中的fit()函数
def fit(args, network, data_loader, **kwargs):
"""
train a model
args : argparse returns
network : the symbol definition of the nerual network
data_loader : function that returns the train and val data iterators
"""
# kvstore
kv = mx.kvstore.create(args.kv_store)
# logging
# 和生成的日志相关,可以通过修改使得每次训练都生成相应的log文件。例如把原来的这三行替换成:
# 这里我直接用model_prefix作为生成的log的路径和名称,因此要先生成这个文件夹才能正常运行,
# 这里我直接将#logging这个小块的代码剪切到#save model小块代码后面,因为#save model前面的代码会生成文件夹。
'''
head = '%(asctime)-15s Node[' + str(kv.rank) + '] %(message)s'
log_file_full_name = args.model_prefix + '.log'
logger = logging.getLogger()
handler = logging.FileHandler(log_file_full_name)
formatter = logging.Formatter(head)
handler.setFormatter(formatter)
logger.addHandler(handler)
logger.setLevel(logging.DEBUG)
logger.info('start with arguments %s', args)
'''
head = '%(asctime)-15s Node[' + str(kv.rank) + '] %(message)s'
logging.basicConfig(level=logging.DEBUG, format=head)
logging.info('start with arguments %s', args)
# data iterators
(train, val) = data_loader(args, kv)
if args.test_io:
tic = time.time()
for i, batch in enumerate(train):
for j in batch.data:
j.wait_to_read()
if (i+1) % args.disp_batches == 0:
logging.info('Batch [%d]\tSpeed: %.2f samples/sec' % (
i, args.disp_batches*args.batch_size/(time.time()-tic)))
tic = time.time()
return
# load model
if 'arg_params' in kwargs and 'aux_params' in kwargs:
arg_params = kwargs['arg_params']
aux_params = kwargs['aux_params']
else:
sym, arg_params, aux_params = _load_model(args, kv.rank)
if sym is not None:
assert sym.tojson() == network.tojson()
# save model
checkpoint = _save_model(args, kv.rank)
# devices for training
devs = mx.cpu() if args.gpus is None or args.gpus is '' else [
mx.gpu(int(i)) for i in args.gpus.split(',')]
# learning rate
lr, lr_scheduler = _get_lr_scheduler(args, kv)
# create model
#这一步比较重要,通过mx.mod.Module函数生成model对象,注意这里的symbol就是网络结构,
# 用fit函数的输入之一network赋值。如果你需要在训练的时候固定一些层的参数不更新,只更新部分层的参数,
# 那么可以在生成这个model对象的时候加上类似fixed_param_names = [‘layer_name1’,‘layer_name2’]这样的参数,
# 表示这两个参数不参与更新。
model = mx.mod.Module(
context = devs,
symbol = network
)
lr_scheduler = lr_scheduler
optimizer_params = {
'learning_rate': lr,
'momentum' : args.mom,
'wd' : args.wd,
'lr_scheduler': lr_scheduler,
'multi_precision': True}
monitor = mx.mon.Monitor(args.monitor, pattern=".*") if args.monitor > 0 else None
if args.network == 'alexnet':
# AlexNet will not converge using Xavier
initializer = mx.init.Normal()
else:
initializer = mx.init.Xavier(
rnd_type='gaussian', factor_type="in", magnitude=2)
# initializer = mx.init.Xavier(factor_type="in", magnitude=2.34),
# evaluation metrices
eval_metrics = ['accuracy']
if args.top_k > 0:
eval_metrics.append(mx.metric.create('top_k_accuracy', top_k=args.top_k))
# callbacks that run after each batch
batch_end_callbacks = [mx.callback.Speedometer(args.batch_size, args.disp_batches)]
if 'batch_end_callback' in kwargs:
cbs = kwargs['batch_end_callback']
batch_end_callbacks += cbs if isinstance(cbs, list) else [cbs]
# run
#这里的model是前面通过mx.mod.Module()函数生成的对象,通过调用这个对象的fit方法来启动训练,
# 你可以看到MXNet官网上的例子都是这么启动训练的。
model.fit(train,
begin_epoch = args.load_epoch if args.load_epoch else 0,
num_epoch = args.num_epochs,
eval_data = val,
eval_metric = eval_metrics,
kvstore = kv,
optimizer = args.optimizer,
optimizer_params = optimizer_params,
initializer = initializer,
arg_params = arg_params,
aux_params = aux_params,
batch_end_callback = batch_end_callbacks,
epoch_end_callback = checkpoint,
allow_missing = True,
monitor = monitor)