Oracle-----复杂查询的习题案例(详细分析过程)
上一篇:Oracle-----having、select、from子句使用子查询
总目录震惊!史上最菜的Oracle 11g教程(大佬勿进)
文章目录
- 1、复杂查询习题案例
- 1.1 列出薪金高于在部门编号为30工作的所有员工姓名和薪金、部门名称、部门人数
- 1.2 列出与"SCOTT"从事相同工作的所有员工及部门名称,部门人数,领导姓名
- 1.3 列出薪金比"SMITH"或"ALLEN"多的所有员工的编号、姓名、部门名称、其领导姓名,部门人数、平均工资、最高及最低工资
- 1.4 列出受雇日期早于其直接上级的所有员工的编号、姓名、部门名称、部门位置、部门人数
- 1.5 列出所有"CLERK"(办事员)的姓名及其部门名称,部门人数,工资等级
大家好!我是近视的脚踏实地,这篇文章主要是来讲解5个复杂查询的详细解题思路
唯有行动 才能解除你所有的不安
1、复杂查询习题案例
1.1 列出薪金高于在部门编号为30工作的所有员工姓名和薪金、部门名称、部门人数
范例1: 列出薪金高于在部门编号为30工作的所有员工姓名和薪金、部门名称、部门人数
※ 确定要使用的数据表:
emp表:员工姓名和薪金
dept表:部门名称
emp表:统计出部门人数
※ 确定已知的关联字段:
员工与部门:emp.deptno = dept.deptno。
第一步: 找到30部门所有雇员的薪金
select sal
from emp
where deptno = 30;

第二步: 以上查询返回的是多行单列的数据,那么子查询肯定是在where子句中出现的,然后此时就可以使用三种判断符判断:in、any、all。那么根据要求发现找到的是所以员工,使用">all"。
select e.ename,e.sal
from emp e
where e.sal >all(
select sal
from emp
where deptno = 30);

第三步: 要找到部门的信息,自然在from子句之后引入dept表,而后要消除笛卡尔积。用内连接
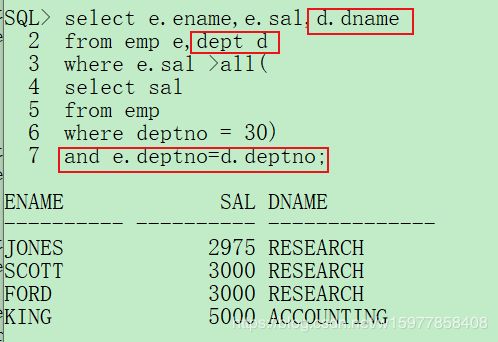
select e.ename,e.sal,d.dname
from emp e,dept d
where e.sal >all(
select sal
from emp
where deptno = 30)
and e.deptno=d.deptno;
第四步: 需要统计出部门人数的信息
思考过程:
1. 如果要进行部门人数的统计,那么一定要按照部门分组;
2. 在使用分组的时候,select子句只能出现分组字段与统计函数。
于是此时就出现了一个矛盾,如果直接在后边加了group by,select子句里面还有其他字段,
所以不可能直接使用group by分组,所以可以考虑利用子查询分组,即:在from子句之后使用子
查询先进行分组统计,而后将临时表继续采用多表查询操作
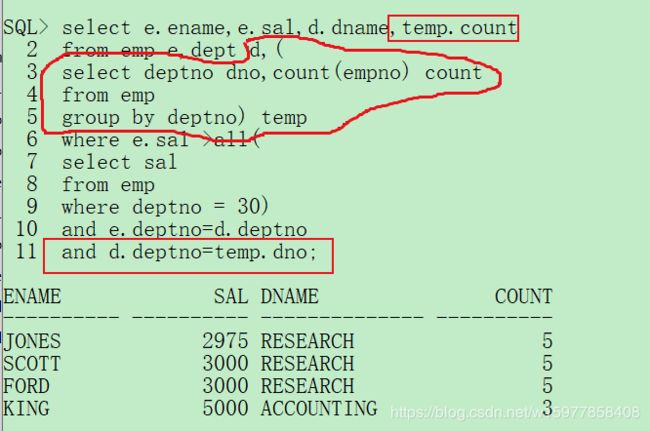
select e.ename,e.sal,d.dname,temp.count
from emp e,dept d,(
select deptno dno,count(empno) count
from emp
group by deptno) temp
where e.sal >all(
select sal
from emp
where deptno = 30)
and e.deptno=d.deptno
and d.deptno=temp.dno;
1.2 列出与"SCOTT"从事相同工作的所有员工及部门名称,部门人数,领导姓名
范例1: 列出与"SCOTT"从事相同工作的所有员工及部门名称,部门人数,领导姓名
※ 确定要使用的数据表:
emp表:员工信息
dept表:部门名称
emp表:领导信息
※ 确定已知的关联字段:
员工与部门:emp.deptno = dept.deptno。
雇员与领导:emp.mgr=memp.mgr。
第一步: 没有SCOTT的工作就无法知道哪个雇员满足这个条件,需要找到SCOTT的工作
select job
from emp
where ename = 'SCOTT';

第二步: 以上查询返回的是单行单列,所以只能在where或者having中使用,那么根据现在需求肯定在where中使用,对所有的雇员信息进行筛选
select e.empno,e.ename,e.job
from emp e
where job =(
select job
from emp
where ename = 'SCOTT');

第三步: 如果不需要重复的信息,那么可以删除SCOTT
select e.empno,e.ename,e.job
from emp e
where job =(
select job
from emp
where ename = 'SCOTT')
and e.ename<>'SCOTT';

第四步: 部门名称只需要加入dept表即可
select e.empno,e.ename,e.job,d.dname
from emp e,dept d
where job =(
select job
from emp
where ename = 'SCOTT')
and e.ename<>'SCOTT'
and e.deptno=d.deptno;

第五步: 此时的查询不可能直接使用group by进行分组,所以需要使用子查询实现分组
from emp e,dept d,(
select deptno dno, count(empno) count
from emp
group by deptno) temp
where job =(
select job
from emp
where ename = 'SCOTT')
and e.ename<>'SCOTT'
and e.deptno=d.deptno
and d.deptno=temp.dno;

第六步: 找到对应的领导信息,直接使用自身连接
select e.empno,e.ename,e.job,d.dname,temp.count,m.ename
from emp e,dept d,(
select deptno dno, count(empno) count
from emp
group by deptno) temp,emp m
where e.job =(
select job
from emp
where ename = 'SCOTT')
and e.ename<>'SCOTT'
and e.deptno=d.deptno
and d.deptno=temp.dno
and e.mgr=m.empno;

1.3 列出薪金比"SMITH"或"ALLEN"多的所有员工的编号、姓名、部门名称、其领导姓名,部门人数、平均工资、最高及最低工资
范例1: 列出薪金比"SMITH"或"ALLEN"多的所有员工的编号、姓名、部门名称、其领导姓名,部门人数、平均工资、最高及最低工资
※ 确定要使用的数据表:
emp表:员工的编号、姓名
dept表:部门名称:
emp表:领导姓名:
emp表:统计信息:
※ 确定已知的关联字段:
员工与部门:emp.deptno = dept.deptno。
雇员与领导:emp.mgr=memp.mgr。
第一步: 知道"SMITH"或"ALLEN",这个查询返回是多行单列(where中使用)
select sal
from emp
where ename in('SMITH','ALLEN');

第二步: 现在应该比里边的任意一个多即可,但是要去掉两个雇员。由于是多行单列的子查询,所以使用 >any 完成
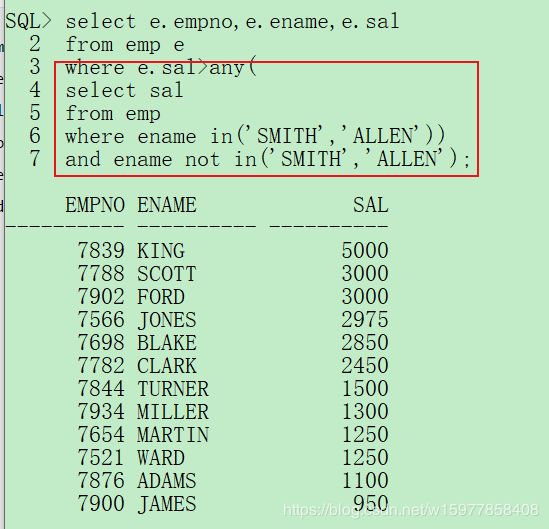
select e.empno,e.ename,e.sal
from emp e
where e.sal>any(
select sal
from emp
where ename in('SMITH','ALLEN'))
and ename not in('SMITH','ALLEN');
第三步: 找到部门名称
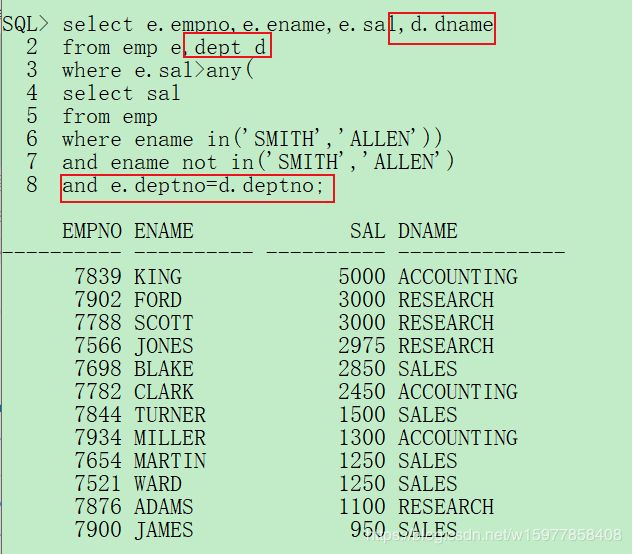
select e.empno,e.ename,e.sal,d.dname
from emp e,dept d
where e.sal>any(
select sal
from emp
where ename in('SMITH','ALLEN'))
and ename not in('SMITH','ALLEN')
and e.deptno=d.deptno;
第四步: 找到领导信息
select e.empno,e.ename,e.sal,d.dname,m.ename
from emp e,dept d,emp m
where e.sal>any(
select sal
from emp
where ename in('SMITH','ALLEN'))
and e.ename not in('SMITH','ALLEN')
and e.deptno=d.deptno
and e.mgr=m.empno(+);
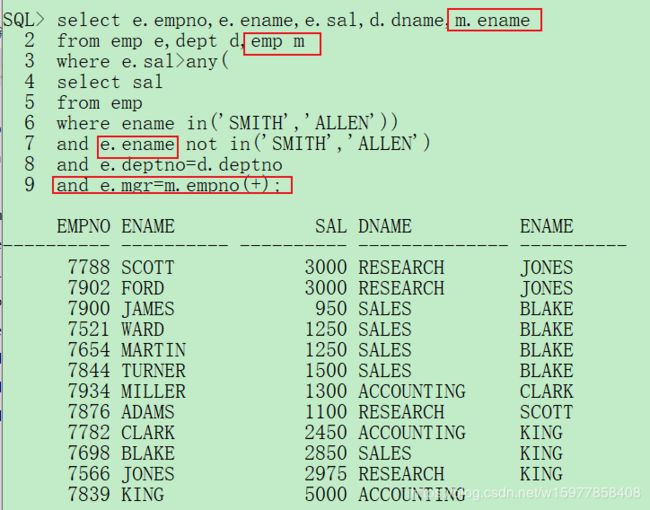
第五步: 部门人数、平均工资、最高及最低工资。整个查询里边我们不能够直接使用group by,所以现在应该利用子查询实现统计操作。
select e.empno,e.ename,e.sal,d.dname,m.ename,tepm.count,tepm.avg,tepm.max,tepm.min
from emp e,dept d,emp m,(
select deptno dno,count(empno) count,avg(sal) avg,max(sal) max,min(sal) min
from emp
group by deptno) tepm
where e.sal>any(
select sal
from emp
where ename in('SMITH','ALLEN'))
and e.ename not in('SMITH','ALLEN')
and e.deptno=d.deptno
and e.mgr=m.empno(+)
and d.deptno=tepm.dno;
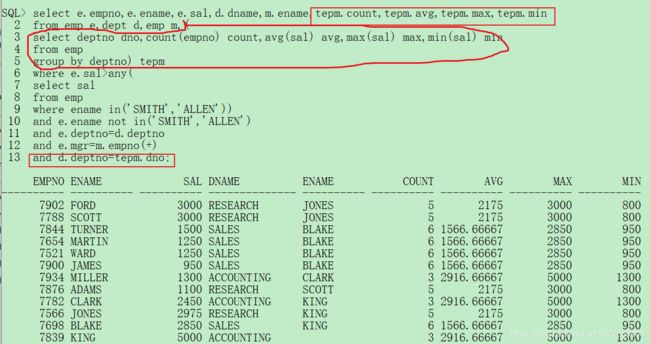
1.4 列出受雇日期早于其直接上级的所有员工的编号、姓名、部门名称、部门位置、部门人数
范例1: 列出受雇日期早于其直接上级的所有员工的编号、姓名、部门名称、部门位置、部门人数
※ 确定要使用的数据表:
emp表:员工的编号、姓名
dept表:部门名称、部门位置:
emp表:部门人数:
emp表:领导:
※ 确定已知的关联字段:
员工与部门:emp.deptno = dept.deptno。
雇员与领导:emp.mgr=memp.mgr。
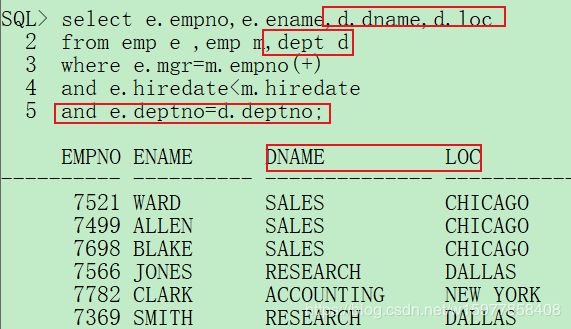
第一步: emp表进行自身关联,而后除了设置消除笛卡尔积的条件之外,还要判断受雇日期。
select e.empno,e.ename
from emp e ,emp m
where e.mgr=m.empno(+)and e.hiredate<m.hiredate;

第二步: 找到部门信息,部门名称、部门位置:
select e.empno,e.ename,d.dname,d.loc
from emp e ,emp m,dept d
where e.mgr=m.empno(+)
and e.hiredate<m.hiredate
and e.deptno=d.deptno;
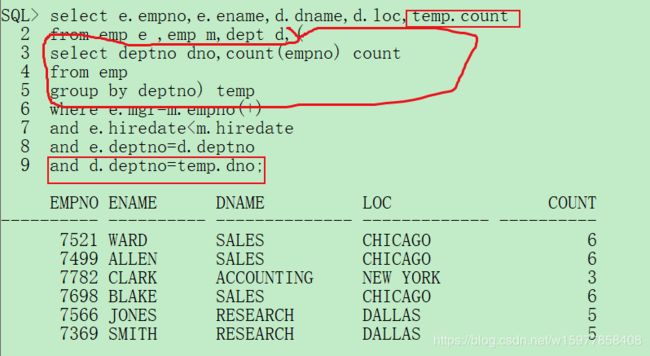
第三步: 统计部门人数
select e.empno,e.ename,d.dname,d.loc,temp.count
from emp e ,emp m,dept d,(
select deptno dno,count(empno) count
from emp
group by deptno) temp
where e.mgr=m.empno(+)
and e.hiredate<m.hiredate
and e.deptno=d.deptno
and d.deptno=temp.dno;
1.5 列出所有"CLERK"(办事员)的姓名及其部门名称,部门人数,工资等级
范例5: 列出所有"CLERK"(办事员)的姓名及其部门名称,部门人数,工资等级
※ 确定要使用的数据表:
emp表:姓名
dept表:部门名称:
emp表:部门人数:
salgrade表:工资等级:
※ 确定已知的关联字段:
员工与部门:emp.deptno = dept.deptno。
雇员与工资等级:emp.sal between salgrade.losal and salgrade.hisal;
第一步: 找到所有办事员的信息
select e.ename
from emp e
where e.job = 'CLERK';

第二步: 找到部门名称
select e.ename,d.dname
from emp e,dept d
where e.job = 'CLERK'
and e.deptno=d.deptno;

第三步: 统计出部门的人数
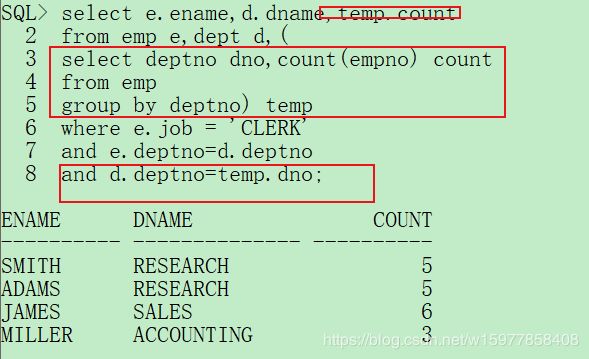
select e.ename,d.dname,temp.count
from emp e,dept d,(
select deptno dno,count(empno) count
from emp
group by deptno) temp
where e.job = 'CLERK'
and e.deptno=d.deptno
and d.deptno=temp.dno;
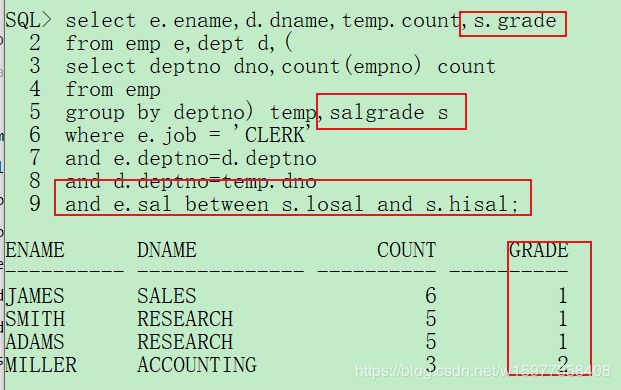
第四步: 工资等级
select e.ename,d.dname,temp.count,s.grade
from emp e,dept d,(
select deptno dno,count(empno) count
from emp
group by deptno) temp,salgrade s
where e.job = 'CLERK'
and e.deptno=d.deptno
and d.deptno=temp.dno
and e.sal between s.losal and s.hisal;
总结:所谓最复杂的复杂查询也只是将多表查询、统计查询、子查询融合在一起使用,这里里边关键注意几点
※ 笛卡尔的消除;
※ group by 的使用限制。
下一篇Oracle-----增、删、改数据
本篇博客到这就完啦,非常感谢您的阅读,如果对您有帮助,可以帮忙点个赞或者来波关注鼓励一下喔 ,嘿嘿