MySQL与TiDB基础知识类比
温故而知新 可以为师矣
(想自学习编程的小伙伴请搜索圈T社区,更多行业相关资讯更有行业相关免费视频教程。完全免费哦!)
一、存储模型
MySQL

Each tablespace consists of database pages with a default size of 16KB. The pages are grouped into extents of size 1MB (64 consecutive pages). The “files” inside a tablespace are called segments in InnoDB.
Two segments are allocated for each index in InnoDB. One is for nonleaf nodes of the B-tree, the other is for the leaf nodes. Keeping the leaf nodes contiguous on disk enables better sequential I/O operations, because these leaf nodes contain the actual table data.
- 表空间Tablespace(ibd文件)
- 段Segment(一个索引2个段)
- 区Extent(1MB):64个Page
- 页Page(16KB):磁盘管理的最小单位
从示意图可以清晰的了解到MySQL的行数据Row都是存储到数据页Page上,每个数据页的大小为16KB。然后64个数据页进而组成一个区Extent,区又是段segment组成元素,一个索引拥有两个段,其中leaf node seagment存储着逻辑上的行数据(主键索引),非主键索引存储的是主键ID。
InnoDB使用了B+树的索引模型。B+树为了维护索引的有序性,在插入新值的时候需要做必须的维护。如果在表尾插入,只需在记录后面增加,要是增加的行在表中间,就需要挪动位置给插入的行腾出空间。更糟糕的是带插入的数据页Page已经满了16KB,这时需要新申请一个新的数据页,然后将部分数据挪过去。这个过程成为也分裂。
既然存在页分裂,那么当然也会存在页合并。将利用率低的Page页进行合并,页分裂的逆过程。
不管是页的分裂还是合并,都会引起性能的损失。这里就需要考虑主键是否必须要自增?主键自增的模式下,每次插入的新纪录都是追加操作,都不涉及其它记录的挪动,不会触发叶子节点的分裂。
TiDB
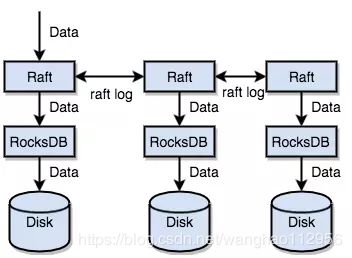
TiDB的存储与SQL模型是没有关系的,TiKV 没有选择直接向磁盘上写数据,而是把数据保存在 RocksDB 中,具体的数据落地由 RocksDB 负责。所有可以简化TiKV的存储模型为:
- 这是一个巨大的 Map,也就是存储的是 Key-Value pair
- 这个 Map 中的 Key-Value pair 按照 Key 的二进制顺序有序,也就是我们可以 Seek 到某一个 Key 的位置,然后不断的调用 Next 方法以递增的顺序获取比这个 Key 大的 Key-Value
Region
对于一个 KV 系统,将数据分散在多台机器上有两种比较典型的方案:一种是按照 Key 做 Hash,根据 Hash 值选择对应的存储节点;另一种是分 Range,某一段连续的 Key 都保存在一个存储节点上。TiKV 选择了第二种方式,将整个 Key-Value 空间分成很多段,每一段是一系列连续的 Key,我们将每一段叫做一个 Region,并且我们会尽量保持每个 Region 中保存的数据不超过一定的大小(这个大小可以配置,目前默认是 64mb)。每一个 Region 都可以用 StartKey 到 EndKey 这样一个左闭右开区间来描述。

尽管Region跟Page的概念很像,但需要注意的时候Region是键值对的存储区,与关系型数据表没有关系。Region作为TiDB提供分布式和高可用的核心工作单元,将数据划分成 Region 后会做两件事:
- 以 Region 为单位,将数据分散在集群中所有的节点上,并且尽量保证每个节点上服务的 Region 数量差不多
- 以 Region 为单位做 Raft 的复制和成员管理
那么关系型的表是如何在TiKV中进行映射呢?定义个表t1,主键为id,唯一索引name和普通索引age。
CREATE TABLE t1 {
id BIGINT PRIMARY KEY,
name VARCHAR(1024),
age BIGINT,
content BLOB,
UNIQUE(name),
INDEX(age),
};
-- 向t1中插入两条数据
insert into t1 values(1, “a”, 10, “hello”);
insert into t1 values(2, “b”, 12, “world”);
上面的两条数据就会映射成下面的键值对存储到TiKV的Map中:
PK
t_11_1 -> (1, “a”, 10, “hello”)
t_11_2 -> (2, “b”, 12, “world”)
Unique Name
i_12_a -> 1
i_12_b -> 2
Index Age
i_13_10_1 -> nil
i_13_12_2 -> nil
因为 PK 具有唯一性,所以可以用 t + Table ID + PK 来唯一表示一行数据,value 就是这行数据。对于 Unique 来说,也是具有唯一性的,所以用 i + Index ID + name 来表示,而 value 则是对应的 PK。如果两个 name 相同,就会破坏唯一性约束。当我们使用 Unique 来查询的时候,会先找到对应的 PK,然后再通过 PK 找到对应的数据,这里与MySQL的回表有点类似。
对于普通的 Index 来说,不需要唯一性约束,所以使用 i + Index ID + age + PK,而 value 为空。因为 PK 一定是唯一的,所以两行数据即使 age 一样,也不会冲突。当我们使用 Index 来查询的时候,会先 seek 到第一个大于等于 i + Index ID + age 这个 key 的数据,然后看前缀是否匹配,如果匹配,则解码出对应的 PK,再从 PK 拿到实际的数据。
二、SQL执行过程
MySQL
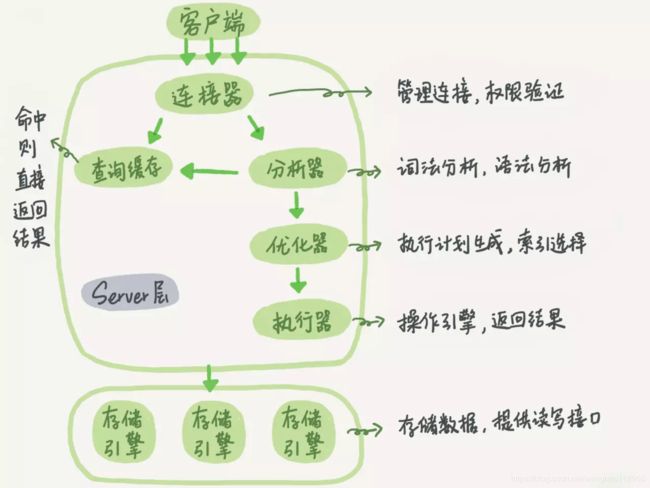
TiDB

从两个流程图可以不难看出SQL的被执行的流程分为:
- 建立连接。
- 客户端发送一条SQL给服务器。
- 服务器先检查查询缓存,如果命中缓存立即返回存储在缓存的结果。否则进入下一阶段。
- 服务器端进行SQL解析、预处理,再由优化器生成对应的执行计划。
- 根据优化器生成的执行计划,调用存储引擎的API来执行查询。
- 将结果返回给客户端。
那么TiDB作为分布式数据库,在SQL处理过程中存在下面几个难点:
- SQL语言本身是一门复杂的语言。
- SQL是一门表意的语言,只是说『要什么数据』,而不说『如何拿数据』。
- 分布式存储引擎。需要考虑下层的数据是分片、网络不通如何处理。
三、事务隔离
MySQL
READ UNCOMMITTED
事务中可以读到其他事务未提交的修改,造成脏读。
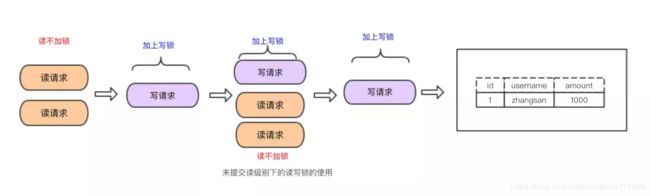
READ COMMITTED
事务未提交的修改对其它事务是不可见的,事务只会看到被提交的修改。
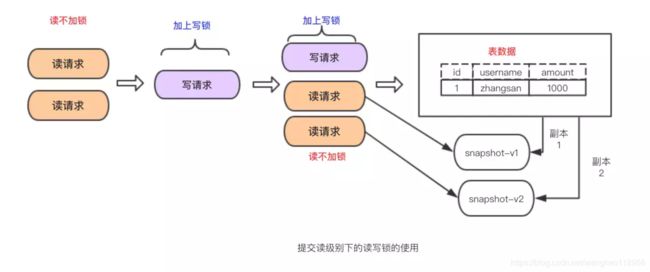
REPEATABLE READ
在同一事务中读取的数据始终是一致的,就算读取的数据有被其它事务提交过修改。
使用读写锁实现

使用mvcc实现

ERIALIZABLE事务的执行按照串行执行。
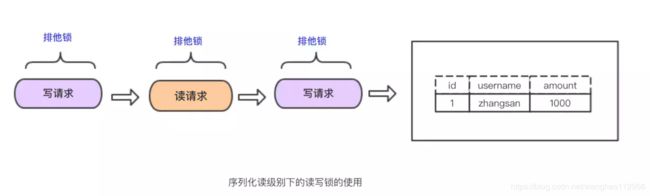
引用表格总结一下始终事务隔离

TiDB
TiKV 的事务采用的是 Percolator 模型。TiKV 的事务采用乐观锁,事务的执行过程中,不会检测写写冲突,只有在提交过程中,才会做冲突检测,冲突的双方中比较早完成提交的会写入成功,另一方会尝试重新执行整个事务。TiKV也实现了MVCC。TiKV 的 MVCC 实现是通过在 Key 后面添加 Version 来实现,简单来说,没有 MVCC 之前,可以把 TiKV 看做这样的:
Key1 -> Value
Key2 -> Value
……
KeyN -> Value
有了 MVCC 之后,TiKV 的 Key 排列是这样的:
Key1-Version3 -> Value
Key1-Version2 -> Value
Key1-Version1 -> Value
……
Key2-Version4 -> Value
Key2-Version3 -> Value
Key2-Version2 -> Value
Key2-Version1 -> Value
……
KeyN-Version2 -> Value
KeyN-Version1 -> Value
……
四、索引
MySQL
最左前缀原则
由于覆盖索引(查询中索引已经覆盖了查询的需求,可以直接提供结果不需要回表,称之为:覆盖索引)可以显著的优化查询性能,并且索引的维护也是有代价的。所以如何权衡就是个问题。
最左前缀原则:即最左优先,在检索数据时从联合索引的最左边开始匹配,也可以是字符串索引的最左边的字符开始匹配。在建立联合索引时将高频的字段放置左侧。
索引下推:(index condition pushdown) 索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉减少回表。
TiDB
这里留个坑,后面去填。 索引范围计算简介