【深入理解Hadoop原理】Hadoop1.0 MapReduce工作原理 与 Hadoop 2.x Yarn 设计理验与基本架构理解
Hadoop1.0 MapReduce工作原理 与 Hadoop 2.x Yarn 设计理验与基本架构理解
Hadoop1.0 提交MapReduce作业,一般分为4个实体
1. 客户端 提交 MapReduce 作业
2. JobTracker 协调作业的运行, JobTracker是一个Java应用程序,其主类是 JobTracker
3.TaskTracker , 运行作业划分后的任务
4. HDFS 分布式文件系统,用来在各实体之间共享作业文件
下面具体看下MapReduce 执行流程
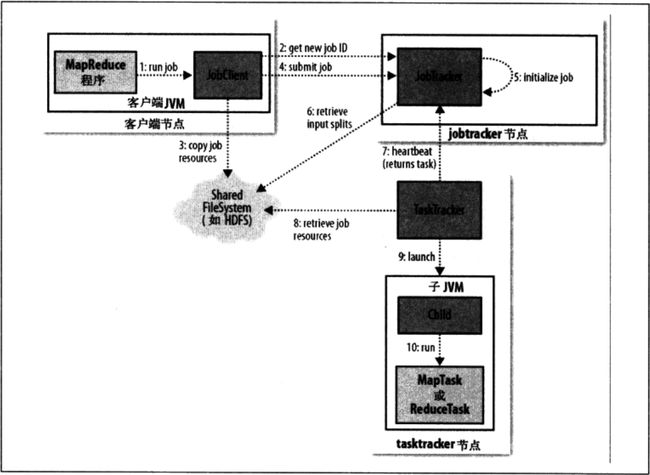
上面可以看到 一共有10 个步骤,现在居于这10个步骤做具体描述:
1.MapReduce程序 告诉jobClient runJOb
2. JobClient 接受请求后去JobTracker那申请个JobID
3. JobClient 并且将Job所需要的资源(JAR包,配置文件等) Copy到HDFS文件系统上.
4.JobClient 调用SubmitJob 提交Job给 JobTracker
5. JobTracker 初始化 JobClient提交的Job
6. JobTracker将HDFS 大文件进行分片Split,也即输入划分文件,也会将作业分成小任务MapTask和ReduceTask
7.JobTracker检测那个TaskTracker状态正常,给TaskTracker 分配MapTask,或者ReduceTask, 是按照输入划分文件 就近分配的,TaskTracker 是要运行在HDFS的DataNode上的
注: TaskTracker 有固定个数的任务槽,可以同时运行两个MapTask 和两个 ReduceTask ,默认调度器处理ReduceTask 任务前会清空空闲的Map任务槽,也就是说,如果TaskTracker只是有一个Map任务槽,那么JobTracker会分配一个Map任务,如果一个Map任务槽都没有,那只会分配一个ReduceTask
8. TaskTracker去HDFS上取得JobTracker分配的资源 Jar包,输入文件分片等
9. TaskTracker 启动TaskTracker节点JVM
10.TaskTracker j各个节点执行Map或者ReduceTask
ReduceTask或者MapTask运行结束报告改TaskTracker,TaskTracker报告给JobTracker.
3中资源具体指什么?主要包含:
● 程序jar包、作业配置文件xml
● 输入划分信息,决定作业该启动多少个map任务
● 本地文件,包含依赖的第三方jar包(-libjars)、依赖的归档文件(-archives)和普通文件(-files),如果已经上传,则不需上传
MapReduce工作原理:
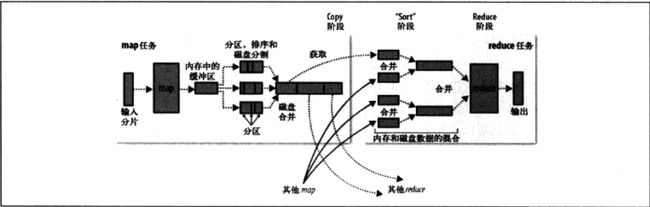
mapTask
程序会根据InputFormat 将文件分割成split ,每个split会作为一个MapTask的输入,每一个MapTask都有一个环形缓存区, 输入数据经过Map任务将中间结果写入这个缓存区,
缓存区默认是100M,阀值是0.8 ,当缓存区内容达到100*0.8阀值时,后台线程会将缓存区内容溢写到磁盘中,不影响其他中间结果写入缓存区, 溢写过程中,会对key进行排序,如果中间结果比较大,会形成多个溢写文件, 最后合并多个溢写文件为一个文件
reduce Task
所有的Map执行完成后,会形成一个文件,并且该文件按区进行划分,只要有一个maptask 运行结束 reduce通过http得到输出文件的分区,如果map输出比较小,会复制到reduce的缓存中,但是如果map输出很大时,map输出会被复制到reduce的磁盘中, 内存缓存达到阀值(shuffle参数控制),或者map输出达到阀值(merge参数控制),
会溢出,最后写到磁盘中, 最后得到的是一个已经排序的文件。
栗子: 比如map有50个输出, 合并系数是5 一次合并10 个最后得到5个排序,合并后的中间结果,最后这5个中间结果再排序合并成一个文件。
关于MapReduce这里给个实例:
Configuration conf = new Configuration();
// JobConf conf = new JobConf();
String[] ioArgs = new String[] { "hdfs://192.168.121.167:8020/user/wangxiaoming/ml/input/wordcount",
"hdfs://192.168.121.167:8020/user/wangxiaoming/ml/output/wordcount"};
System.setProperty("hadoop.home.dir", "D:\\hadoop-2.7.3");
String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount ");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
Path outPath = new Path(otherArgs[1]);
FileSystem fileSystem = outPath.getFileSystem(conf);
if (fileSystem.exists(outPath)) {
// true的意思是,就算output有东西,也一带删除
fileSystem.delete(outPath, true);
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
对应Hadoop 2.x 和Hadoop1.x 发展已经有很多不同
先看下一代MapReduce基本结构
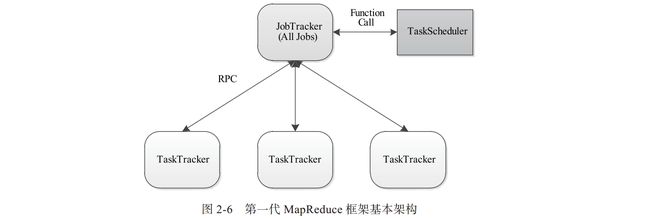
Hadoop1.x这个结构只存在一个JobTracker,JobTracker压力大,万一单点故障,成功程序就崩溃了
看下Hadoop2.x 基本结构:
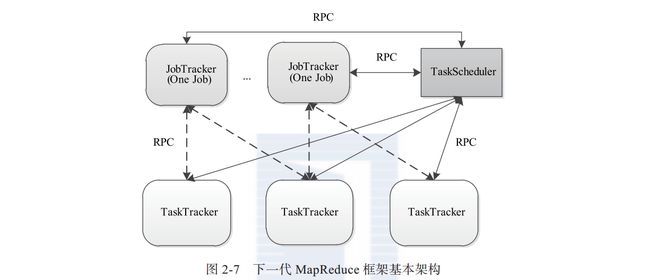
Hadoop2.0相对 Hadoop1.0的改进 主要是JobTracker两个主要功能, 1. 资源管理 2. 作业控制
将资源管理与作业控制拆分成两个独立的进程:
资源管理与应用程序无关,负责整个集群的资源(网络 ,内存,CPU,磁盘等 )管理,
作业控制进程则是直接与应用程序,每个作业进程只负责管理一个作业。
下面来一个整体的对比和说明:
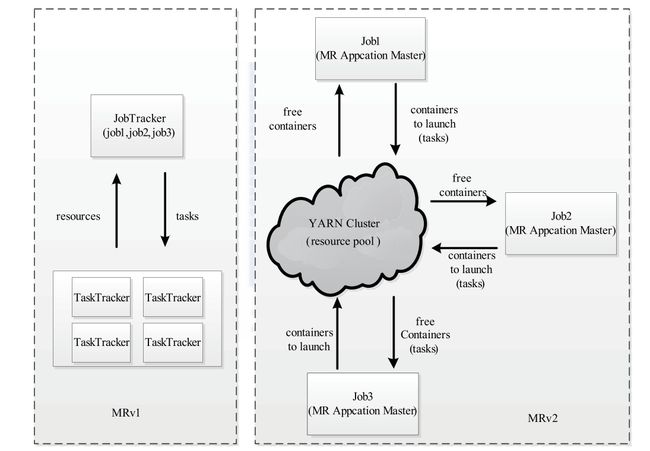
一代:
JobTracker 负责资源与任务的管理和调度。
TaskTracker 负责单个节点的资源管理和任务执行
二代:
将一代的资源管理和应用程序管理分开,分别由 Yarn 和ApplicationMaster 负责。
YARN 管理资源和调度(这个调度是纯调度,不和应用程序打交道,不监控和跟踪应用程序,只分配资源,和觉定最多执行一定数量的任务)
ApplicationMaster 负责任务的切分,任务调度和容错。
YARN 基本架构:
先看基本架构图:
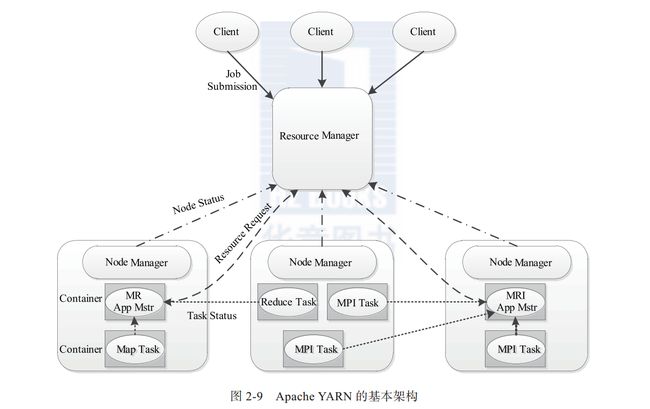
YARN主要是下面4个组件组成:
1.ResouceManager:
ResourceManager是一个全局的资源管理器, 负责整个系统的资源管理。ResourceManager会将资源(网络,IO,带宽,内存,CPU等封装抽象成一个Container)精心分配给NodeManager, 和ApplicationMaster 一起协商分配Contatiner,或者关闭Container, ResourceManager还和NodeManager交流资源使用和Container运行情况.
主要由两个部分(schedule 调度器 限制资源分配量,最多执行多少作业 2.applicationsMaster 负责和调度器协商在失败时启动applicationMaster)
总结下如下功能:
1)接收客户端请求
2)启动或者监控ApplicationMaster
3) 监控NodeManeger
4) 资源的分配和调度。
2. ApplicationMaster
主要由如下功能:
1) 与RescouceManager协商获取资源(container)
2) 将得到的任务进一步分配给内部的任务。
3)任务的监控和容错。
4)与NodeManager通讯 启动或者停止任务
5) 负责数据的切分。
3.Nodemanager
NodeManager是每个节点上的资源和任务管理器。一方面向ResourceManager汇报资源使用和Container运行情况,第二方面,接收AppliacationMaster ,启动和停止请求。
主要由如下功能:
1)管理各个节点上的资源。
2)和ResourceMange通讯汇报资源使用和Container运行情况
3)和ApplicationMaster通讯 启动或停止任务。
4.Container
Container是YARN 的资源抽象,封装了某个节点多维度资源,例如 网络,IO, CPU,内存,磁盘等,当ApplicationMaster向ResourceManager提交资源请求时,ResouceManager返回的资源就是以Container表示的。
YARN的工作流程:
如图:
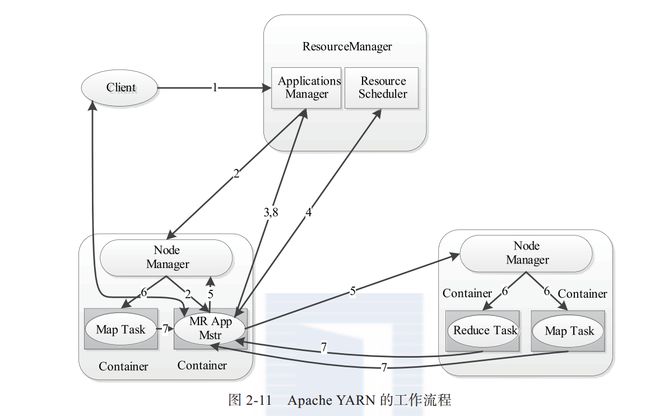
整个作业提交的详细的工作流程
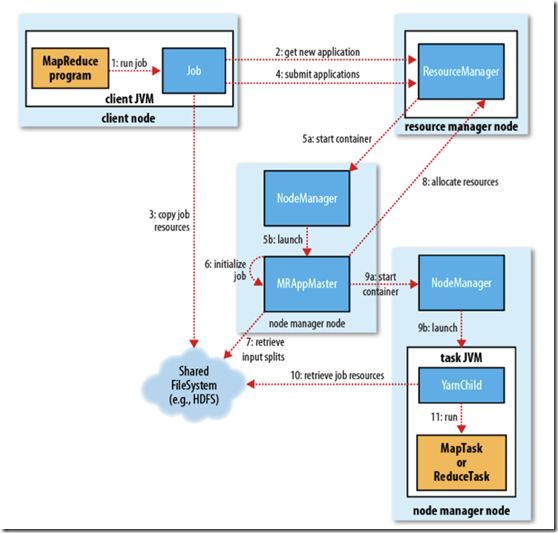
作业执行流程:
1. client 调用job.waitForCompletion方法,向整个集群提交MapReduce作业 (第1步) 。
2. Job 请求ResourceManager得到JobID
3. Job将Job运行所需要的资源Copy到HDFS文件系统
4. Job向ResourceManager提交Job
5. ResourceManager 的Schedule接收到submit Application请求, 调度NodeManager去启动Container 中的ApplicationMaster程序,
6. ApplicationMaster初始化Job
7. ApplicationMaster 去HDFS文件系统上取文件输入分片
8. applicationMaster 向ResourceManager注册,ResoureceManager就可以查看运行状态,并未其他各个任务分配资源
9. ApplicationMaster 可以和NodeManager进行通讯,让NodeManager启动任务 MapTask或者ReduceTask
10 ,MapTask或者ReduceTask 去HDFS上取 任务所需要资源, 执行任务
11.执行结束后,向ApplicationMaster 汇报任务执行完成
12,ApplicationMaster向resourceManager中的的ApplicationsMaster汇报是否执行结束。
整个作业流程就到此结束。
下面接着探讨 YARN HA问题:
上面可以看到client是向ResourceManager 提交任务的,如果只有一个ResourceManager也是会出现单点故障的问题。
Yarn HA 有两种方式,要么手动切换,要么自动切换。
先看ResourceManager HA 架构
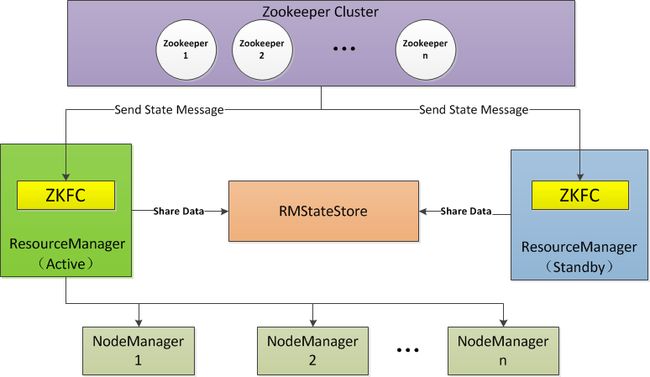
1. 从架构图可以看到 ReourceManager 作业的信息是在ZK的 RMStateStore目录下,active的ResourceManager会向RM写数据
2. 当ResourceManager启动时,会向Zk写一个lock 文件 写成功就是active, 不成功就是standby,
3. 当active 宕机后standby的ResourceManager会从RMStateStore读取信息,然后启动ResourceManager 接收NodeManager心跳,接收Client请求