Mysql7种join连接及mysql一些知识点
Join图:
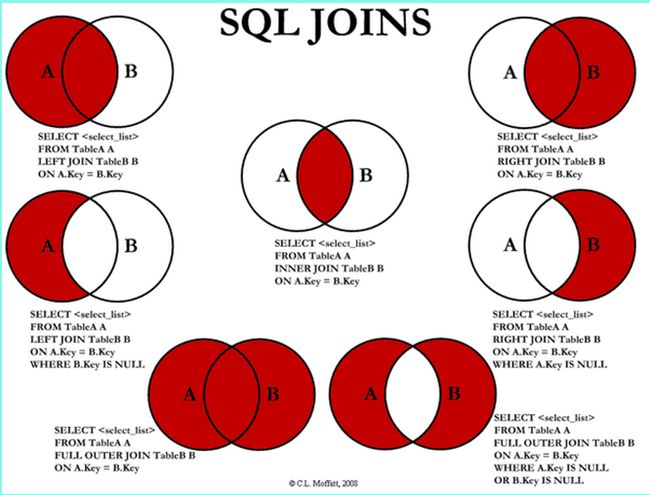
Sql如下:
1)左外连接,以左边的表为主,左连接即左边的表独有+左边表和右边表共有数据
SELECT * FROM dept t
LEFT JOIN emp t2
ON t.`id_dept` = t2.`id_dept`;

2)右外连接,以右表的表为主,右连接即右边表独有+右边和左边共有数据
SELECT * FROM dept t
RIGHT JOIN emp t2
ON t.`id_dept` = t2.`id_dept`;

3)内连接,也叫自然连接同时也叫全等连接,即左边表和右边表共有数据的查询
SELECT * FROM dept t
INNER JOIN emp t2
ON t.`id_dept` = t2.`id_dept`;

4)左连接,即查询左边表的独有数据
SELECT * FROM dept t
LEFT JOIN emp t2
ON t.`id_dept` = t2.`id_dept`
WHERE t2.`id_dept` IS NULL;
![]()
5)右连接,即查询右边表独有数据
SELECT * FROM dept t
RIGHT JOIN emp t2
ON t.`id_dept` = t2.`id_dept`
WHERE t.`id_dept` IS NULL;
![]()
6)全连接,即左边表数据+右边表数据+左边表和右边表共有数据查询
SELECT * FROM dept t
LEFT JOIN emp t2
ON t.`id_dept` = t2.`id_dept`
UNION
SELECT * FROM dept t
RIGHT JOIN emp t2
ON t.`id_dept` = t2.`id_dept`;
UNION 用于合并两个或多个 SELECT 语句的结果集,并消去表中任何重复行。
UNION 内部的 SELECT 语句必须拥有相同数量的列,列也必须拥有相似的数据类型。
同时,每条 SELECT 语句中的列的顺序必须相同.

7)全外连接,即左右表的共有数据之外的数据查询
SELECT * FROM dept t
FULL OUTER emp t2
ON t.`id_dept` = t2.`id_dept`
WHERE t.`id_dept` IS NULL
OR t2.`id_dept` IS NULL; --mysql不支持这种连接的语法
SELECT * FROM dept t
LEFT JOIN emp t2
ON t.`id_dept` = t2.`id_dept`
WHERE t2.`id_dept` IS NULL
UNION
SELECT * FROM dept t
RIGHT JOIN emp t2
ON t.`id_dept` = t2.`id_dept`
WHERE t.`id_dept` IS NULL;
![]()
oracle 的sql如下:
------------------自然连接 把一张表当两张表用
select e1.ename ,e2.ename from emp e1 join emp e2 on (e1.mgr = e2.empno ) ;
select ename,dname from emp join dept on (emp.deptno=dept.deptno);
---等值连接的简洁写法:
select ename ,dname from emp join dept using (deptno);
---外连接:
--左外连接
select e1.ename ,e2.ename from emp e1 left join emp e2 on (e1.mgr =
e2.empno ) ;
select e1.ename ,e2.ename from emp e1,emp e2 where e1.mgr=e2.empno(+);
--右外连接:
select e1.ename ,e2.ename from emp e1 right join emp e2 on (e1.mgr =
e2.empno ) ;
select e1.ename ,e2.ename from emp e1,emp e2 where e1.mgr(+) = e2.empno;
-- 复合索引 顺序, col1 col2 col3
EXPLAIN select * from t_demo v where v.col1 = '3456dasf' and v.col2 = '1234'; -- 走索引 type:ref
EXPLAIN select * from t_demo v where v.col2 = '1234' and v.col1 = '3456dasf' ; -- 走索引 type:ref
EXPLAIN select * from t_demo v where v.col1 = '3456dasf' and v.area_col4 = 'dsafdsafdsa'; -- 走索引 type:ref
EXPLAIN select * from t_demo v where v.col4 = 'dsafdsafdsa' and v.col1 = '3456dasf'; -- 走索引 type:ref
EXPLAIN select * from t_demo v where v.col4 = 'dsafdsafdsa' and v.col2 = 'gfhfdhg'; -- 不走索引 type:all
EXPLAIN select * from t_demo v where v.col4 = 'dsafdsafdsa' and v.col5 = 'gfdd' and v.col3 = '18HB0820504'; -- 不走索引 type:all
EXPLAIN select * from t_demo v where v.col4 = 'dsafdsafdsa' and v.col1 = '3456dasf'; -- 走索引 type:ref
EXPLAIN select * from t_demo v where v.col4 = 'dsafdsafdsa' and v.col2 = '3456dasf' and v.col1 = '3456dasf' ; -- 走索引 type:ref总结:
mysql 复合索引当中,MySQL联合索引最左原则
即,复合中的三个字段,如果查询条件当中没有 最左的字段作为查询条件,不走索引
如果有最靠左的两个字段,则走两个字段的索引
如果三个字段,只有最左和最右的,则只走一个最左字段的索引
反之都不走索引
4)type
4.1)访问类型排序
4.2)显示查询使用了何种类型
从最好的到最差的依次是:
System->const->eq_ref->ref->range->index->All
一般来说,得保证查询至少达到range级别,最好达到ref
数据库备份:
-- 备份全部数据库的数据(-t)
mysqldump -uroot -p123456 -P3306 -A -t > 0103.sql
-- 备份单个数据库的数据和结构(dbname 为数据库名)
mysqldump -uroot -p123456 -P3306 dbname > dbname_20190819.sql
-- 备份单个数据库结构(dbname 为数据库名,-d)
mysqldump -uroot -p123456 -P3306 dbname -d > 0105.sql
-- 备份单个数据库数据(sakila 为数据库名,-t)
mysqldump -uroot -p123456 -P3306 sakila -t > 0106.sql
-- 备份多个表的结构和数据 (table1,table2为表名)
mysqldump -uroot -p123456 -P3306 sakila table1 table2 > 0107.sql
-- 一次备份多个数据库
mysqldump -uroot -p123456 --databases db1 db2 > 0108.sql
show global variables like 'max_allowed_packet';