1、VRRP协议
VRRP协议被称为虚拟路由冗余协议
- 虚拟路由器简介
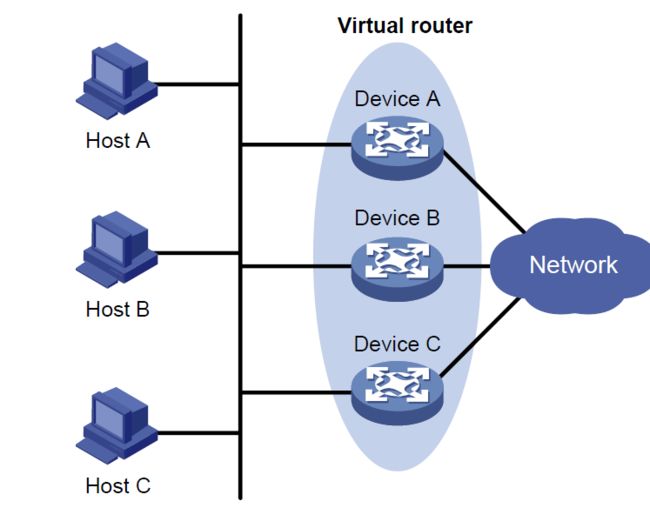
VRRP将局域网内的一组路由器划分在一起,形成一个VRRP备份组,它在功能上相当于一台虚拟路由器,使用虚拟路由器号进行标识。以下使用虚拟路由器代替VRRP备份组进行描述。
虚拟路由器有自己的虚拟IP地址和虚拟MAC地址,它的外在表现形式和实际的物理路由器完全一样。局域网内的主机将虚拟路由器的IP地址设置为默认网关,通过虚拟路由器与外部网络进行通信。虚拟路由器是工作在实际的物理路由器之上的。它由多个实际的路由器组成,包括一个Master路由器和多个Backup路由器。Master路由器正常工作时,局域网内的主机通过Master与外界通信。当Master路由器出现故障时,Backup路由器中的一台设备将成为新的Master路由器,接替转发报文的工作,如图下图
Paste_Image.png
- VRRP工作过程
VRRP的工作过程为:
(1) 虚拟路由器中的路由器根据优先级选举出Master。Master 路由器通过发送免费ARP 报文,将自己的虚拟MAC 地址通知给与它连接的设备或者主机,从而承担报文转发任务;
(2) Master 路由器周期性发送VRRP 报文,以公布其配置信息(优先级等)和工作状况;
(3) 如果Master 路由器出现故障,虚拟路由器中的Backup 路由器将根据优先级重新选举新的Master;
(4) 虚拟路由器状态切换时,Master 路由器由一台设备切换为另外一台设备,新的Master 路由器只是简单地发送一个携带虚拟路由器的MAC 地址和虚拟IP地址信息的免费ARP 报文,这样就可以更新与它连接的主机或设备中的ARP 相关信息。网络中的主机感知不到Master 路由器已经切换为另外一台设备。
(5) Backup 路由器的优先级高于Master 路由器时,由Backup 路由器的工作方式(抢占方式和非抢占方式)决定是否重新选举Master。
由此可见,为了保证Master路由器和Backup路由器能够协调工作,VRRP需要实现以下功能:
Master 路由器的选举;
Master 路由器状态的通告;
同时,为了提高安全性,VRRP 还提供了认证功能; - VRRP提供了三种认证方式:
无认证:不进行任何 VRRP 报文的合法性认证,不提供安全性保障。
简单字符认证:在一个有可能受到安全威胁的网络中,可以将认证方式设置
为简单字符认证。发送VRRP 报文的路由器将认证字填入到VRRP 报文中,
而收到VRRP 报文的路由器会将收到的VRRP 报文中的认证字和本地配置的
认证字进行比较。如果认证字相同,则认为接收到的报文是合法的VRRP 报
文;否则认为接收到的报文是一个非法报文。
MD5 认证:在一个非常不安全的网络中,可以将认证方式设置为MD5 认
证。发送VRRP 报文的路由器利用认证字和MD5 算法对VRRP 报文进行加
密,加密后的报文保存在Authentication Header(认证头)中。收到VRRP
报文的路由器会利用认证字解密报文,检查该报文的合法性。 - VRRP优先级
VRRP优先级的取值范围为0到255(数值越大表明优先级越高),可配置的范围是
1到254,优先级0为系统保留给路由器放弃Master位置时候使用,255则是系统保
留给IP地址拥有者使用。当路由器为IP地址拥有者时,其优先级始终为255。因
此,当虚拟路由器内存在IP地址拥有者时,只要其工作正常,则为Master路由器。 - 术语:
虚拟路由器:Virtual Router
虚拟路由器标识:VRID(0-255),唯一标识虚拟路由器
物理路由器:
master:主设备
backup:备用设备
priority:优先级
VIP:Virtual IP
VMAC:VirutalMAC (00-00-5e-00-01-VRID)
总结:VRRP协议可以实现ip地址的漂移,在两个物理路由器上虚拟的配置一个VIP,并且VIP刚开始时由master使用,当master损坏时备用的路由器根据优先级进行选举,选举为master路由器的使用此虚拟VIP
2、KeepAlived的配置准备
(1) 各节点时间必须同步
在两台物理路由器上做如下配置,本次实验使用centos7和centos6两台主机做为物理的路由器
在centos7上
ntpdate 172.18.0.1
vim /etc/chrony.conf
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
server 172.18.0.1 iburst ---加上这一行与谁同步的
systemctl start chronyd ---启动同步时间的服务
systemctl enable chronyd
在centos6上
ntpdate 172.18.0.1
vim /etc/ntp.conf
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
172.18.0.1 iburst
service ntpd start ---启动同步时间的服务,我们发现在centos6和centos7上同步时间的服务是不同的
chkconfig ntpd on
为什么要先同步时间再去修改配置文件,因为如果时间相差的太多是不会同步的。必须用命令将时间先同步后再去修改配置文件
(2) 确保iptables及selinux不会成为阻碍
getenfoce
iptables -vnL
(3) 各节点之间可通过主机名互相通信(对KA并非必须)
建议使用/etc/hosts文件实现
在centos7上
hostnamectl set-hostname node1
vim /etc/hosts
192.168.74.106 node2
在centos6上
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=node2
vim /etc/hosts
192.168.74.107 node1
将两台主机退出后重新登录发现主机名改变了
[root@node2 network-scripts]#ping node1
PING node1 (192.168.74.107) 56(84) bytes of data.
64 bytes from node1 (192.168.74.107): icmp_seq=1 ttl=64 time=1.14 ms
64 bytes from node1 (192.168.74.107): icmp_seq=2 ttl=64 time=0.453 ms
(4) 各节点之间的root用户可以基于密钥认证的ssh服务完成互相通信(对KA并非必须)
在centos7上
ssh-keygen ---生成公钥私钥对
ssh-copy-id -i id_rsa.pub node2: ---将公钥传给对方,不用加-i也可以,会默认将公钥转给对方的
在centos6上
ssh-keygen
ssh-copy-id -i id_rsa.pub node1:
测试
在cenots7上测试ssh node2
在centos6上测试ssh node1
3、KeepAlived实现
- 实现单主模式vip的地址转移
yum install keepalived
1、在主上的配置
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs { ---这里一定要注意所有的大括号前都有空格,并且大括号要一一对应,不然实现不了
notification_email { ---给哪个邮箱地址发通知
root@localhost
}
notification_email_from node1@localhost ---邮件来自己于谁
smtp_server 127.0.0.1 ---邮件服务器地址
smtp_connect_timeout 30
router_id node1 ----真实的物理路由器的id
vrrp_mcast_group4 224.21.21.21 ---加一个多播地址,用于主master向这个多播地址发送消息,证明自己还活着,当主master坏了的时候,多个从路由器向这个多播地址内发送信息,通过比较优先级选举出来一个master做为主来代替坏了的master工作
}
vrrp_instance VI_1 {
state MASTER
interface ens33 ----绑定为当前虚拟路由器使用的物理接口
virtual_router_id 88 ---当前虚拟路由器惟一标识,范围是0-255
priority 100 ---当前物理节点在此虚拟路由器中的优先级,范围1-254
advert_int 1 ---vrrp通告的时间间隔,默认1s
authentication { ----认证机制
auth_type PASS
auth_pass 783b7339 ---仅前8位有效,可以用openssl rand -hex 4 取个随机数
}
virtual_ipaddress {
192.168.74.88/24 dev ens33 ---vip的地址
}
}
track_interface{ ---配置监控网络接口,一旦出现故障,则转为FAULT状态实现地址转移
ens33
}
systemctl start keepalived.service
2、在从上的设置
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from node2@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id node2
vrrp_mcast_group4 224.21.21.21
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 88
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 783b7339
}
virtual_ipaddress {
192.168.74.88/24 dev eth0
}
}
track_interface{
eth0
}
3、测试
在主上输入ip a命令发现vip已经配置成功
在从上输入ip a命令发现没有vip
此时把主的网卡断开,在从上抓包
tcpdump -i eth0 -nn host 224.21.21.21可以看到切换的过程,通过向多播内发送优先级选举出master
并在从上查看ip a发现vip已经转移到从上了
ip link set dev eth0 multicast off ---可以使用如下命令关闭多播,默认都是开启的,一般不需要关闭,此服务如果关闭多播就无法选举master了和进行实时监控主master是否是活着的了
nopreempt:定义工作模式为非抢占模式,也就是原来的主master修好后即使优先级比现在的高也不会成为master
preempt_delay 300:抢占式模式,节点上线后触发新选举操作的延迟时长,默认模式
- 实现日志功能
1、vim /etc/sysconfig/keepalived ---定义一个日志设施为local2
KEEPALIVED_OPTIONS="-D -S 2"
2、vim /etc/rsyslog.conf
local2.* /var/log/keepalived.log
systemctl restart rsyslog
systemctl restart keepalived
3、cat /var/log/keepalived.log ---发现已经有日志记录了
- 定义通知脚本
也就是发生vip转移时会给本机的root发邮件
1、定义一个通知脚本
vim /app/notify.sh
#!/bin/bash
#
contact='root@localhost'
notify () {
mailsubject="`hostname` to be $1, vip floating"
mailbody="`date +'%F %T'`: vrrp transition, `hostname` changed to be $1"
echo "$mailbody" | mail -s "$mailsubject" $contact
}
case $1 in
master)
notify master
;;
backup)
notify backup
;;
fault)
notify fault
;;
*)
echo "Usage: `basename $0` {master|backup|fault}"
exit 1
;;
esac
2、在主路由器和从路由器的配置文件中调用这个脚本
vim /etc/keepalived/keepalived.conf ---加到vrrp_instance VI_1语句块里
notify_master "/app/notify.sh master" ---表示当切换到主的时候会自动给本机的root发邮件
notify_backup "/app/notify.sh backup" ---表示切换为备用的时候会自动给本机的root发邮件
notify_fault "/app/notify.sh fault"
3、测试
在主路由器上关闭keepalived服务,在从路由器上会发现root收到一封邮件,变成主的通知的邮件,当主路由器开启keepalived服务时会发现从路由器上的root收到一封变成backup的邮件
输入mail命令就可以看到发给root的邮件
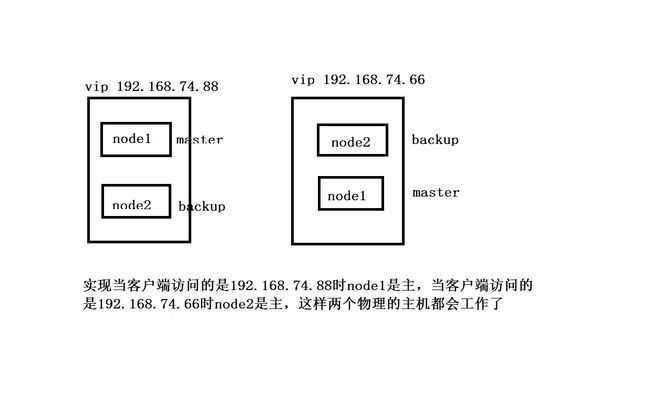
- 实现双主模式
上面的示例只是实现了一个虚拟vip,当主工作时,从不会工作,只有当主不工作了从才会变成master,得到vip开始工作,如果要实现主和从都工作,就需要配置两个虚拟的vip
实现如下图所示
无标题5.png
实现过程如下:
1、在node1上的设置
vim /etc/keepalived/keepalived.conf ---在上面的配置中增加一个实例
vrrp_instance VI_2 {
state BACKUP ---将node1设置为备份
interface ens33
virtual_router_id 66 ---虚拟路由标识改一下
priority 90 ---优先级要调低
advert_int 1
authentication {
auth_type PASS
auth_pass 683b7339 ---此项也改一下
}
virtual_ipaddress {
192.168.74.66/24 dev ens33 ---设置一个新的vip地址
}
notify_master "/app/notify.sh master"
notify_backup "/app/notify.sh backup"
notify_fault "/app/notify.sh fault"
}
track_interface{
ens33
}
2、在node2上的设置
vim /etc/keepalived/keepalived.conf
vrrp_instance VI_2 {
state MASTER ---将node2设置为主
interface eth0
virtual_router_id 66
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 683b7339
}
virtual_ipaddress {
192.168.74.66/24 dev eth0
}
notify_master "/app/notify.sh master"
notify_backup "/app/notify.sh backup"
notify_fault "/app/notify.sh fault"
}
track_interface{
eth0
}
3、将两个主机重新启动一下服务
systemctl restart keepalived.service
service keepalived restart
ip a 发现新的vip绑定到rode2上了
[root@node2 ~]#tcpdump -i eth0 -nn host 224.21.21.21 ---抓包可以看到有两个主在多播内发送优先级等信息,证明自己还活着
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 65535 bytes
15:22:35.826209 IP 192.168.74.106 > 224.21.21.21: VRRPv2, Advertisement, vrid 66, prio 100, authtype simple, intvl 1s, length 20
15:22:35.858820 IP 192.168.74.107 > 224.21.21.21: VRRPv2, Advertisement, vrid 88, prio 100, authtype simple, intvl 1s, length 20
15:22:36.832800 IP 192.168.74.106 > 224.21.21.21: VRRPv2, Advertisement, vrid 66, prio 100, authtype simple, intvl 1s, length 20
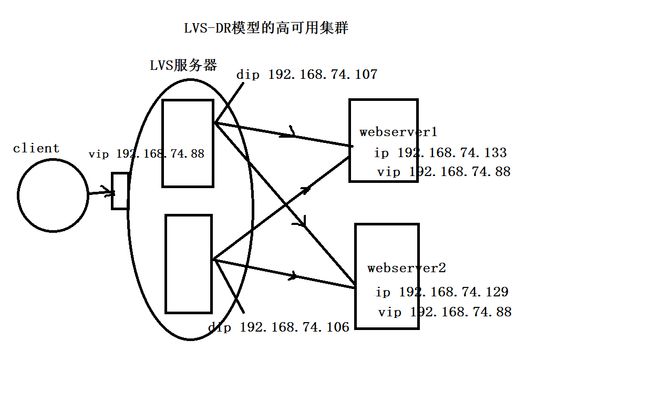
4、KeepAlived实现IPVS-DR的高可用集群
- 常用参数
delay_loop :服务轮询的时间间隔
lb_algo rr|wrr|lc|wlc|lblc|sh|dh:定义调度方法
lb_kind NAT|DR|TUN:集群的类型
persistence_timeout :持久连接时长
protocol TCP:服务协议,仅支持TCP
sorry_server :所有RS故障时,备用服务器地址
real_server {
weight RS权重
notify_up | RS上线通知脚本
notify_down | RS下线通知脚本
HTTP_GET|SSL_GET|TCP_CHECK|SMTP_CHECK|MISC_CHEC K { ... }:定义当前主机的健康状态检测方法
}
- KeepAlived配置检测
①HTTP_GET|SSL_GET:应用层检测
HTTP_GET|SSL_GET {
url{
path :定义要监控的URL
status_code :判断上述检测机制为健康状态的响应码
digest :判断为健康状态的响应的内容的校验码
}
connect_timeout :连接请求的超时时长
nb_get_retry :重试次数
delay_before_retry :重试之前的延迟时长
connect_ip :向当前RS哪个IP地址发起健康状态检测请求
connect_port :向当前RS的哪个PORT发起健康状态检测请求
bindto :发出健康状态检测请求时使用的源地址
bind_port :发出健康状态检测请求时使用的源端口
}
②如果后端的rs不是httpd服务。健康性检查利用tcp协议进行检查
TCP_CHECK {
connect_ip :向当前RS的哪个IP地址发起健康状态检测请求
connect_port :向当前RS的哪个PORT发起健康状态检测请求
bindto :发出健康状态检测请求时使用的源地址
bind_port :发出健康状态检测请求时使用的源端口
connect_timeout :连接请求的超时时长
}
无标题6.png
1、在两个webserver上的设置
systemctl start httpd
echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
echo 1 > /proc/sys/net/ipv4/conf/lo/arp_ignore
echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce
ip addr add 192.168.74.88 dev lo ---在两个webserver上配置vip
2、在主和从LVS服务器上的设置
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from node1@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id node1
vrrp_mcast_group4 224.21.21.21
}
vrrp_instance VI_1 {
state MASTER ---在另外一台上设置为BACKUP
interface ens33 ---另外一台上网卡可能不同需要修改
virtual_router_id 88
priority 100 ----在另外一台上设置为90
advert_int 1
authentication {
auth_type PASS
auth_pass 783b7339
}
virtual_ipaddress {
192.168.74.88/24 dev ens33
}
notify_master "/app/notify.sh master"
notify_backup "/app/notify.sh backup"
}
track_interface{
ens33 ---另外一台上网卡可能不同,需要修改
}
virtual_server 192.168.74.88 80 { ----在上面的配置中增加一个virtual_server的语句块,主和从LVS都要加这个语句块
delay_loop 6 ---服务轮询的时间间隔
lb_algo wrr ----定义调度方法rr|wrr|lc|wlc|lblc|sh|dh
lb_kind DR ----NAT|DR|TUN:集群的类型
# persistence_timeout :持久连接时长,此项最好不要加上,加上好测试不出来轮询,因为会保持持久连接到第一个调度的rs服务器
protocol TCP ----服务协议,仅支持TCP
sorry_server 127.0.0.1 80 ---所有RS故障时,备用服务器地址
real_server 192.168.74.133 80 {
weight 1 ---RS权重
HTTP_GET { ----应用层检测
url {
path / ----定义要监控的URL
status_code 200 ----判断上述检测机制为健康状态的响应码
}
connect_timeout 3 ----连接请求的超时时长
nb_get_retry 3 ----重试次数
delay_before_retry 3 ----重试之前的延迟时长
}
}
real_server 192.168.74.129 80 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
在主和从上都搭建一个httpd服务器做为sorry_server
systemctl restart keepalived ---主和从都重启服务
yum install ipvsadm
[root@node1 app]#ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.74.88:80 wrr
-> 192.168.74.129:80 Route 1 0 0
-> 192.168.74.133:80 Route 1 0 0
3、测试
关闭主LVS的keeplived服务,从LVS就开始工作
在客户端 curl 192.168.74.88 ---发现轮询
5、双主模式的lVS-DR集群
双主模式就是在两个物理的LVS上配置两个虚拟的VIP,当客户端访问192.168.74.88时node1是主,node2是备份,当客户端访问是192.168.74.66时node2是主,node1是备份,利用防火墙打标签,当无论客户端访问的是192.168.74.88还是192.168.74.66时都调度到后端的rs服务器上
实现过程如下
1、在两个rs服务器上的设置
systemctl start httpd
echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
echo 1 > /proc/sys/net/ipv4/conf/lo/arp_ignore
echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce
ip addr add 192.168.74.88 dev lo ---在两个webserver上配置两个vip
ip addr add 192.168.74.66 dev lo
2、在主和从LVS服务器上的设置
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from node1@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id node1
vrrp_mcast_group4 224.21.21.21
}
vrrp_instance VI_1 { ---定义一个虚拟的vip1
state MASTER ---在另外一台LVS上设置为BACKUP
interface ens33 ---另外一台上网卡可能不同需要修改
virtual_router_id 88
priority 100 ----在另外一台LVS上设置为90
advert_int 1
authentication {
auth_type PASS
auth_pass 783b7339
}
virtual_ipaddress {
192.168.74.88/24 dev ens33 ---另外一台网卡要修改
}
notify_master "/app/notify.sh master"
notify_backup "/app/notify.sh backup"
notify_fault "/app/notify.sh fault"
}
track_interface{
ens33 ---网卡可能不同需要修改
}
vrrp_instance VI_2 { ---定义一个虚拟的vip2
state BACKUP ---在另外一台LVS服务上设置为MASTER
interface ens33 ----在另外一台上网卡可能不同需要修改
virtual_router_id 66
priority 90 ----在另外一台LVS服务上设置为100
advert_int 1
authentication {
auth_type PASS
auth_pass 683b7339
}
virtual_ipaddress {
192.168.74.66/24 dev ens33 ---另外一台网卡名要修改
}
notify_master "/app/notify.sh master"
notify_backup "/app/notify.sh backup"
notify_fault "/app/notify.sh fault"
}
track_interface{
ens33 ---另外一台上网卡名要修改
}
virtual_server fwmark 20 { ---只要访问的是打标签为20的地址就转发到后面的rs服务器上
delay_loop 6
lb_algo wrr
lb_kind DR
protocol TCP
sorry_server 127.0.0.1 80
real_server 192.168.74.133 80 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 192.168.74.129 80 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
iptables -t mangle -A PREROUTING -d 192.168.74.88,192.168.74.66 -p tcp --dport 80 -j MARK --set-mark 20 ---无论访问哪个vip地址都打标签为20
在两个主从服务器上安装httpd服务做为sorry_server
systemctl restart keepalived.service
3、测试
在客户端测试
curl 192.168.74.66
curl 192.168.74.88
停止一个LVS上keeplived服务,继续访问这两个地址,仍然可以调度
6、高可用nginx服务
1、在后端的两个rs上搭建好httpd服务
2、在两个nginx服务器上搭建好nginx服务,并做好转发
vim /etc/nginx/nginx.conf
upstream webserver { ---在http语句块里添加
server 192.168.74.133:80;
server 192.168.74.129:80;
}
vim /etc/nginx/conf.d/vhost.conf
server{
listen 80 default_server;
server_name www.a.com;
root /app/website1;
location / {
proxy_pass http://webserver;
}
nginx -t ---检查语法
nginx ---启动服务
3、在两台nginx服务器上修改keepalived的配置文件
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from node1@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id node1
vrrp_mcast_group4 224.21.21.21
}
vrrp_script chk_down { ---创建一个测试的脚本,如果这个文件存在就把优先级减20,这样备用的就开始工作了,这个可以不加,只是测试用的
script "[ -f /etc/keepalived/down ] &&exit 1||exit 0"
interval 1
weight -20
}
vrrp_script chk_nginx { ---这个脚本是用来监控nginx服务是否正常工作,如果不正常优先级就减20,备用的开始工作
script "killall -0 nginx &>/dev/null &&exit 0||exit 1"
interval 1
weight -20 ---如果脚本的返回值为1,优先级就减20
fall 2 #2次检测失败为失败
rise 2 #2次检测成功为成功
}
vrrp_instance VI_1 {
state MASTER ---另外一台nginx上设置为BACKUP
interface ens33 ---另外一台网卡名要改
virtual_router_id 88
priority 100 ---另外一台优先级为90
advert_int 1
authentication {
auth_type PASS
auth_pass 783b7339
}
virtual_ipaddress {
192.168.74.88/24 dev ens33 ---在另外一台上网卡名要改
}
track_script { ----调用上面的两个脚本
chk_down
chk_nginx
}
notify_master "/app/notify.sh master"
notify_backup "/app/notify.sh backup"
notify_fault "/app/notify.sh fault"
}
systemctl start keepalived ----启动服务
4、测试
curl 192.168.74.88
停止一台nginx服务,发现仍可以调度,因为vip已经转移到备用的服务上了
7、同步组
LVS NAT模型VIP和DIP都需要同步,需要同步组
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from node1@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id node1
vrrp_mcast_group4 224.21.21.21
}
vrrp_sync_group VG_1 {
group {
VI_1
VI_2
}
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 88
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 783b7339
}
virtual_ipaddress {
192.168.74.88/24 dev ens33 ---定义一个vip
}
notify_master "/app/notify.sh master"
notify_backup "/app/notify.sh backup"
notify_fault "/app/notify.sh fault"
}
vrrp_instance VI_2 {
state MASTER
interface ens37
virtual_router_id 87
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 683b7339
}
virtual_ipaddress {
172.18.21.88/16 dev ens37 ---定义dip
}
notify_master "/app/notify.sh master"
notify_backup "/app/notify.sh backup"
notify_fault "/app/notify.sh fault"
}