为什么要使用百度AI的:
百度AI这个我之前用到的是语音识别,想着肯定也有图片识别成文字的,所以找了一下果然找了,而且可以免费使用一点。
![]()
注:调用的这个百度AI识别不是专门识别验证码图片的(它可以识别图片中的所有文字,包括空格),所以只能识别一些简单的验证码,专业的使用超级鹰(收费)
使用到的场景:
(1) 最近再写一个web自动化测试项目,在里面有一个selenium功能就是需要识别验证码。
(2) 在用爬虫爬取登陆后的页面内容时候,也需要识别验证码
百度AI找的地方:
支持识别的图片格式:

# 仅jpg/png/bmp格式
使用如下代码需要先申请一个AI的应用:

--------申请完需要修改代码种这三个值------------
APP_ID = 'xxxxxxxx'
API_KEY = 'xxxxxxxx'
SECRET_KEY = 'xxxxxxxxxx'
--------申请完需要修改代码种这三个值------------
识别代码如下:
# 不包含转换图片格式的写法
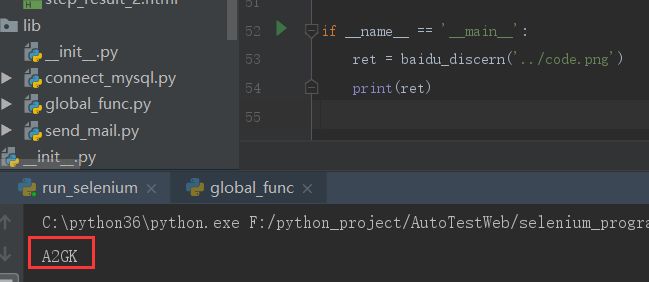
def _get_file_content(filePath): with open(filePath, 'rb') as fp: return fp.read() # 调用百度图片识别 def baidu_discern(filename): """ 你的 APPID AK SK """ APP_ID = 'xxxxxxxx' API_KEY = 'xxxxxxxx' SECRET_KEY = 'xxxxxxxxxx' client = AipOcr(APP_ID, API_KEY, SECRET_KEY) image = _get_file_content(filename) """ 调用网络图片文字识别, 图片参数为本地图片 """ ret = client.webImage(image) words = ret.get('words_result') if words: return ''.join(words[0]['words'].split(' ')) else: return '' if __name__ == '__main__': ret = baidu_discern('../code.png') print(ret)
当图片格式不是这三种格式时候,需要转换图片格式才能识别:
# 我用的是python3的pillow模块进行图片格式转换
# python2是pil模块
from PIL import Image from aip import AipOcr """ 读取图片 """ def get_file_content(filePath): with open(filePath, 'rb') as fp: return fp.read() def baidu_discern(filename): """ 你的 APPID AK SK """ APP_ID = 'xxxxxxx' API_KEY = 'xxxxxxxxx' SECRET_KEY = xxxxxxxxxx' client = AipOcr(APP_ID, API_KEY, SECRET_KEY) image = get_file_content(filename) """ 调用网络图片文字识别, 图片参数为本地图片 """ ret = client.webImage(image) words = ret.get('words_result') if words: return ''.join(words[0]['words'].split(' ')) def get_img_content(filename, format=False): if format: # 转换图片格式 new_filename = filename.split('.')[0] + '.png' Image.open(filename).save(new_filename) ret = baidu_discern(new_filename) else: ret = baidu_discern(filename) return ret if __name__ == '__main__': # 非转换的 ret = get_img_content('../code.png', format=False) # 转换的 ret = get_img_content('../code.png', format=True) print(ret)
使用效果:
# 以古诗文网的验证码为例
https://so.gushiwen.org/user/login.aspx?from=http://so.gushiwen.org/user/collect.aspx


# 用selenium执行的话,使用的时候需要截图下来