半个月前BERT横空出世,在数十个数据集上屠榜,一时风头无两。外加国内一些科技自媒体的“UC式”标题推波助澜,也给这篇文章博得了更多的关注。为了更好的理解BERT,我们需要先理解Attention和Transformer结构。然后可以集中精力从Transfer Learning的角度来比较ELMo,GPT,BERT这三篇文章的优劣异同。
原文发布于个人博客(好望角),并在博客持续修改更新,不支持视频。
Attention
什么是注意力机制?可以想象这样一个画面,当电视机上有非常吸引我们的画面时,我们的视野之中除了电视画面,眼中所看到的屋子中的其他部分仿佛都变得模糊了。甚至妈妈在你的面前从一侧穿行到另外一侧,你都毫无察觉。
有所关注,有所忽略——这便是注意力机制。
从生物进化的角度上来讲,这是十分合理的“节能减排”,我们的大脑将资源集中分到了我们最关心的事物上面,让我们免受其他事务的干扰。
Attention机制最早应用于视觉领域的分类问题,而为了更好的取得词向量表达, Bengio 在2014年引入了Attention机制,这极大的提升了NMT方法的性能。尽管仍存在训练时间长,OOV,可解释性差等问题,但某些性能指标上已经媲美SMT系统,并大大减少了形态学和句法错误,提升了翻译的流畅性。这篇论文也直接影响Google在2016年用GNMT系统替换掉了上线十年之久的PBMT系统,不仅将Attention机制推到闪耀的聚光灯之下,也彻底将SMT方法推下了机器翻译的神坛,开启了NMT方法狂飙的时代。

以2013年Nal Kalchbrenner 和 Phil Blunsom的 Recurrent Continuous Translation Models 论文为标志,神经网络机器翻译诞生。该文整体采用编码器-–-–解码器框架,用CNN将源文本编码成特定的向量,再用一个RNN作为解码器将该向量转化为目标语言。但由于梯度消失/爆炸问题的存在, 长距离依存问题制约模型的表现。 为了缓解这一问题,Sutskever et al. 和 Cho et al. 引入了LSTM。

Attention Mechanism
以上就是Attention机制在NLP领域的应用背景和重要意义,下面我们来详细理解它的作用机制。
Seq2seq
普通的LSTM是采取的是序列编码的方式来获取信息,这样的一大好处就是在编码的时候可以得到词语的远距离依赖信息。如下图所示:我们在编码“力量”的时候,可以知道“知识”是它的来源。

下面我们来看一个形象化的基于sequence-to-sequence框架的NMT模型。先看编码器,除了最初状态之外,后续每个状态都接收前一个状态的编码信息以及当前位置的源句子词语信息,整个源句子顺次编码。在编码完源句子最后一个词的信息之后,才执行解码操作。同样的,解码结构也是顺序执行的。视频中给出的过程应该是测试过程,前一个位置没有传递给下一个位置真实的解码词语参考,而在训练过程中是要给出的。
Seq2seq构架的劣势也不难发现:
- 如果单向RNN编码,前面的词语在先行编码的时候没有办法得到后面词语的信息; 一个形象的例子,
“I arrived at the bank after crossing the …. ”
我们在不知道后面省略的单词是 river or road 的前提下,该如果编码单词 bank 的真实含义呢?
- 信息损失:如果句子很长,两次词语之间相隔比较远,信息传递过程中的损失比较大;
- 信息糅杂:最后一个状态中理论上包含前面所有的信息,所有信息都杂糅在一起不好区分;
- 顺序编码本质上是一个马尔可夫决策过程,无法很好的得到全局信息;
- 无法并行计算,只有当所有词语都编码结束的时候才可以开始解码,系统的训练速度很慢;
Seq2seq+Attention
加上Attention Mechainism的seq2seq结构解决了上述 Long Range Dependence弊端。与seq2seq过程对比,我们观察下面一个视频。
首先避免信息缺失问题,将Encoder每个时刻的状态都传递给Decoder,而不是只传递Encoder最后一个时刻的状态。最大程度上保留源句子的信息。
-
其次,为了避免信息冗余,我们如何只在每个时刻关注我们最关心的部分呢?用一个动态的权重向量(注意力分布),根据其与所有Encoder的隐藏状态信息的相似性大小进行加权求和。加权计算的过程,如下视频所示。
最后,解码时,每一时刻的注意力分布都由这一时刻的解码hidden states来决定。这一时刻的hidden states的输出和注意力机制加权过的向量拼接后归一化,概率最大的一维所对应的词语就是我们这一时刻的翻译结果。过程如下动画所示。
经过上述Attention结构上的剖析,我们再次来总结什么是 Attention 机制?
在我看来,Attention 其实就是一种用在Seq2seq构架上的加权词对其模型。起名为注意力机制,一方面是为了可以从大众容易理解的方式更好的解释模型设计的合理性;另一方面,我认为也是为了更容易完成学术投稿吧。Just a writing trick!
Transformer
在GNMT掀起神经网络机器翻译的热潮之后,Amazon、Microsoft、Facebook、百度、网易有道、腾讯 、搜狗、讯飞、阿里巴巴等公司都迅速跟进。其中Facebook以CNN为基础的NMT模型不但效果超过了Google的GNMT,而且在训练速度上也比前者大幅提升九倍。
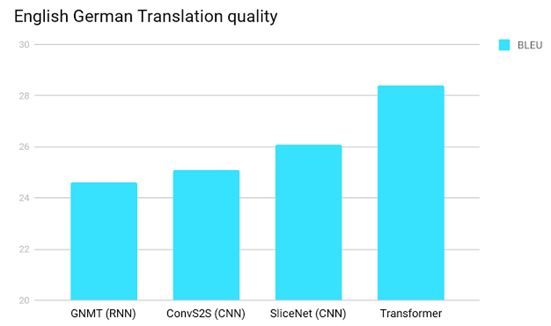
Google可不能容忍这个风头被抢,作为回应,2017.06谷歌发布了一个完全以注意力机制为基础的NMT模型,也就是我们常说的Transformer。整体构架如下所示,观察模型结构,正如作者所说,Attention is all you need。

Self-Attention
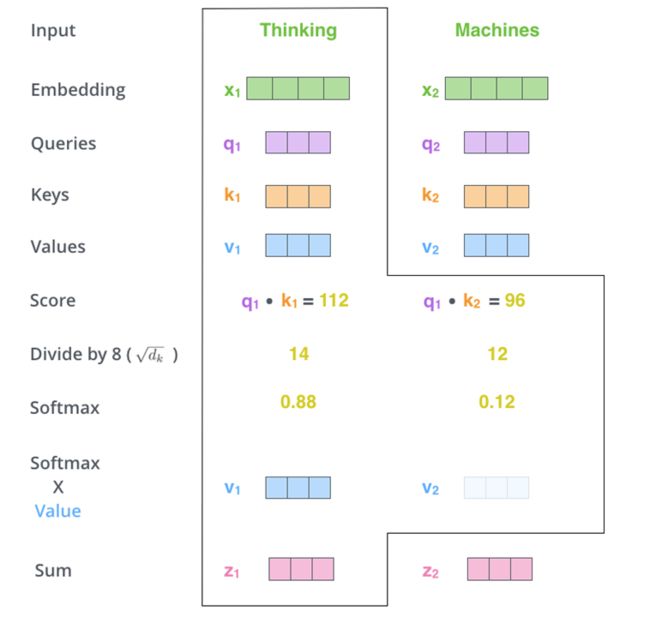
对于Transformer构架而言,最核心的部分莫过于Self-attention。如下图所示,每个词语的初始向量乘以三个权重矩阵得到q、k、v三个向量。重新编码每个词语的时候,所有词语的k向量分别与该词语的q向量相乘,然后除以模型维数的开方,最终权重归一化成values向量的权重值。这样的操作,是根据词语向量之间的相似度来完成的。也就是说,每个词语的新向量必然还是会以自身的原本的信息为主要组成部分,只是在此基础上无距离差别的补充了与其他词语的相关性信息。相当于,我们通过整个句子中所有词语之间的相互关系获取了每个词语在句子中的重要性程度,有了更加丰富的语义信息。另外,所有词语获得新向量的过程是可以并行计算的(矩阵运算),即使模型的参数量巨大,在GPU的加持下也获得了远远高于LSTM的训练速度。
Position Embedding
上述Self-Attention虽然构思巧妙,但是只能说是一个精妙的词袋模型,并没有捕捉到任何次序信息。很不幸,这对翻译任务是致命的。为了能让这个简单的结构很好的工作,这个时候作者提供了一个额外的词向量去补充词语之间的位置关系,缓解这一缺陷。公式如下,采用的是三角函数的形式,好处是在测试的时候如果遇到超出我们训练长度限制的句子,模型也可以进行位置编码。

然而,Position Embedding对于本身模型不能捕捉位置信息,只是起到了一个弥补的作用,并不能从根本上解决模型设计上的缺陷。在实验结果上也可以察觉出一些端倪,为什么同一语系的双语翻译的BLUE数值表现会比不同语系之间的双语翻译效果要好呢?我猜测是同一语系不同语言之间的语序差别较小,而不同语系语言之间的语序差别较大。甚至说,以BLUE作为翻译效果的自动评价指标对于Transformer模型也是占便宜的,因为语言模型本身对于语序正确的要求并没有很高。
Multi-Head Attention
Multi-Head Attention这个概念是在这篇论文中第一次被提及,然而其实际操作并不罕见。其实就是将Self-Attention这一个过程随机初始化8次,相当于映射到不同的子空间,然后拼接起来并乘以权重向量产生输出层。 相当于我们从多种角度来理解同一个句子,以求更加完备的语义表达。

最后我们来观察一下Multi-Head Attention的效果,已经其背后的含义。下面的第一张图片只展示了两次的Multi-Head Attention,我们还可以尝试来解释。黄色的注意力机制敏锐了步骤到了 it这个代词所指代的对象,是 animal;而绿色的注意力机制貌似是错误的,因为直接指向了一个动词 tire。但细细琢磨,这似乎也有一定的道理,因为动词 tire是服务于主语 animal,而 it在这里恰好指代的就是主语 animal。
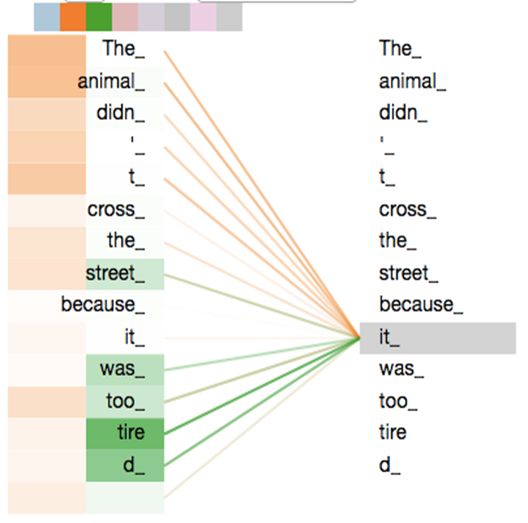
由上面的观察分析可以发现,多重的注意力机制确实可以捕捉到许多句子中隐含的语义细节,得到更好的句子标示。当这种语义表示维度过高时,我们往往难以解释其真实含义。但是,确实效果还不错。

Conclusion
总的来说,Transformer构架的核心思想是计算一句话中每个词对于这句话中其它所有词的相互关系,然后认为这些词与词之间的相互关系在一定程度上反应了这句话中不同词之间的关联性以及它们的重要程度。再利用这些相互关系来调整每个词的重要性(权重)就可以获得每个词新的表达。这个新的表征不但蕴含了该词本身,还蕴含了其他词与这个词的关系,因此和单纯的词向量相比是一个更加全局的表达。Transformer通过对输入的文本不断进行这样的注意力机制层和普通的非线性层交叠来得到最终的文本表达。拥有一个文本信息更加充分全面的表达,得到更好的BLUE数值表现也就顺理成章了。
根据上述介绍的模型结构,并且结合Transformer结构提出的背景,不难看出其浓重的CNN气息。具体的有以下几个方面:
- Attention是不是像一个没有感受野限制的CNN?所有单词之间的距离为一,一步到位的获得全局信息,免去的CNN的堆叠操作。
- Multi-Head Attention多次运算进行拼接操作,对比CNN中的多个卷积核,是否感觉似曾相识?
- 同CNN一样,需要一个Position Embedding 来辅助获得位置信息。只不过这个更为“泛化的CNN”对Position Embedding的依赖更加严重。
尽管作者的writing trick让人有些许反感,但这并不失为一篇好论文。
- 首先,模型构架大道至简。感概Google工程师扎实的炼丹功底,如此简单的方法都可调出STOA。
- Attention 并不简简单单可以完成“词对齐”工作,而且可以完成序列到序列的转换。
- 其次,写作清晰,整篇论文读起来很清爽,没有故弄玄虚的堆砌公式。(可惜没有Ablation Test,不能确定Transformer构架各个部分的作用效果)
- 最后,运用些许的写作技巧来提升自己工作的影响力这本无可厚非(这个名字确实太吸引人去阅读他们的论文了)。也是我需要尽快提高的地方。。
Transfer
源于Google扎实的工作(夸张的论文名字),Transformer 坐上了NMT模型的王座,更是在NLP领域一时风头无两,在众多任务上都取得了很好的表现。当其应用到迁移学习领域的时候,就创造出了现在Google另一个红透半边天的工作——BERT。
ELMo
2018初的NAACL上,AllenNLP祭出了大杀器ELMo。而Google将自身的 Transformer 构架用在迁移学习领域,相信少不了受到了这篇 Deep contextualized word representations 文章的启发。
在EMLo出现之前,不论时研究者习惯性地用word2vec去初始化,还是尝试性的用CNN、RNN等网络结构探索字符级别的文本向量。然而,无论再怎么折腾,怎么细化挖掘信息的级别。都有共同的一点,Embedding没有考虑到语境中的上下文信息 ,总是一成不变的,没有表征一词多义的能力。而EMLo拿出了极具说服力的表现告诉大家,是时候该放弃古老的word2vec了。。。
这篇论文有以下几个关键点:
- CNN提取字符(中文可以考虑拼音或者笔画)级别信息;
- 两个单向LSTM,loss相互独立;
- 浅层语法,深层语义;
- 层级输出线性加权,可以根据任务需要自训练不同的权重;
GPT
趁热打铁,AllenNLP 又从迁移学习 Fine-tuning的角度发布了另一个重要工作——Improving Language Understanding by Generative Pre-training(GPT)。这个工作也直接引导出了Google的重磅论文BERT。如果说ELMo的野心只是想要取代Word2vec,成为NLP领域文本输入的标准操作。那GPT显然野心更大,其试图提出一个通用的框架网络,想要成为类似于图像领域的ResNet那样的神经网络骨架,以扭转现在研究task-specific方法愈演愈烈的风气。拯救近期国内外一些公司在某些固定的数据集上穷尽奇淫巧技去调试出一个个过拟合模型,抢占所谓的STOA。
GPT提出了一个两阶段的模型。第一阶段,在大规模的无监督文本上训练一个单向的Transformer模型;第二阶段,只需要根据不同的任务要求,仅需要少量的特定标注数据进行调优训练,即可获得若干任务数据集上STOA级别的表现。这样的迁移学习方法,极大的节省了为不同的特定任务进行人工标注数据的高昂成本需求。
GPT已经取得了很令人实验结果,有以下几个点值得我们多加关注:
- 继续增加生语料,模型效果是否会继续提升?
- 泛化能力不够强,如果精细化调优技巧(类似:ULMFiT每一层设置不同的学习率?),会不会在适应各个任务的数据集上有更好的表现?
- 5GB语料,需要8块GPU训练一个月,如何合理的拓展出降低计算需求的方法?
- 现用的训练生语料,可能由于其自身局限性,导致模型认知世界产生偏差。
BERT
顺着GPT的思路,今年10月BERT的横空出世,无疑将2018年NLP领域无监督学习的热潮推向了一个新的高度! 先来看看它在GLUE leaderboard屠榜的盛况。

为什么BERT的性能如此只有优越呢?由于它在以下的几个方面在GPT的基础上有了进一步的突破:
Deep model
Jacob 以极强的工程能力成功驾驭了一个深达24层、每层1024个神经元、并且Multi-dead数为16、总参数340M的巨大Transformer模型,再一次向我们证明了对于深度学习来说,深度>宽度这一重要规律。当然,也体现了Transformer模型具有良好的稳定性这一重要优点,因为其本身就含有各种Normalization。
Masked LM
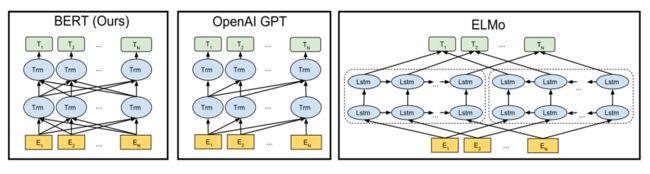
观察上图,相比于GPT,BERT在训练上解决了无法使用双向Transformer的窘境。相比于ELMo,两个方向上的loss结合在一起,而不是相互独立,更大程度上释放了Transformer构架的信息采集能力。不难理解为什么双向的Transformer效果要更好,就像我们学习英语做完形填空。我们是只看半句填的准呢?还是前后半句都阅读完填的准呢?相信这不难回答。 双向训练具体是怎么做到的呢?观察下图,当模型层数加深的时候,在每个位置上已经有了原本这个位置上的词的信息,这对于词的预测任务来说无异于作弊,显然是不可行的一种方案。

那么怎么办呢?直接删除需要预测的词语吗?这会是原本的句子失去顺序信息,并且丢掉了这一个词的原本信息,显然不可取。替换为一个随机的词吗?但这会使模型难以收敛,也不可以。最后作者选择只将10%的词语进行随机处理(相当于噪声),而将80%的词用“mask”标记来遮盖,让模型通过这个编辑来学习该位置的填词。然而下游任务中显然不会存在这个“mask”标记,所以最后另外10%的词语我们保持原有这个原有正确的词语。虽然通过这样一个训练技巧,使得双向的Transformer可以正常的工作了。但是由于加入了大量的噪声,模型的收敛仍有待提升。
Jointly Pre-Train
由于很多的NLP下游任务涉及到句子之间关系的理解,例如:Question Answering (QA) 、Natural Language Inference (NLI)等等。作者在原有的loss函数后面新添加了一项关于句子间关系理解的loss,来进行联合训练。如下图所示,这仅仅是一个简单的二分类问题。Jacob将此处的训练模式与下游任务相统一,都是将两个句子一起作为输入(中间有间隔符[SEP])。用无监督语料训练的时候,将一半的句子下一句进行随机句子采样,作为负例“NotNext”;而其余一半则直接给出真正的后句,作为正例“IsNext”。

Others
昨天,中文定制版model也可以在github上获取了。
Position Embedding
BERT并没有采取GNMT那篇论文中用三角函数来表达句子中词语位置的方法,而是直接设置句子的固定长度去训练Position Embedding,在每个词的位置随机初始化词向量,经过训练,将Position Embedding与Token Embedding、以及模型训练得到的Segment Embeddings 直接相加即可食用。如下图所示。

feature-based?
在倒数第二页的一栏,作者实验表明,BERT不仅仅是一个Fine-tuning迁移学习方法,还可以是一个Feature-based迁移学习方法,就像ELMo和Wordsvec。Jacob用CoNLL-2003 NER数据集做了实验,feature-based(合并最后四层的输出)版本的BERT仅仅比fine-tuning版本的BERT低0.3的准确率,再次心疼一下帅不过三秒的ElMo和GPT。
More Data
相比于GPT模型5GB、800M words 的训练数据,BERT更是用了惊人的3,200M words的训练数据。联想到GPT论文中提到,如果有更多的训练语料,该模型的效果还会进一步提升。我觉得在BERT论文中应该有一个关于Data size的Ablation study,然而令我失望的是我并没有找到。
Conclusion
总的来说,Jacob凭借着高超的工程技能,海量的训练数据,以及强大的算力,完成了一篇里程碑级别论文。它的出现在NLP社区产生了重要的影响,并在以下的几方面给我们带来了许多的惊喜和思考:
- 深度、双向的transformer构架具有强大的数据表示能力以及良好的稳定性;
- Jointly Pre-Train 对于训练的帮助;
- Pre-Training 的这把火会以何种形式烧到 NLG ?
- One for All:手握大量资源的公司越来越倾向于发布一个简单粗暴的通用模型去解决一众问题,科研院校该何去何从?
- Few-shot Learning:大数据的学习模式真的是机器学习的归宿吗?科研院校是否该从其他角度发力,来探索ML的未来?
Reference
- The Mathematics of Statistical Machine Translation: Parameter Estimation
- Recurrent Continuous Translation Models
- Sequence to sequence learning with neural networks
- Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
- Harvard NLP
- Tensor2tensor
- GLUE Leaderboard
- Recurrent Models of Visual Attention
- Neural Machine Translation by Jointly Learning to Align and Translate
- Effective Approaches to Attention-based Neural Machine Translation
- Attention is All you Need
- Universal Language Model Fine-tuning for Text Classification
- Deep Contextualized Word Representations
- Improving Language Understanding by Generative Pre-training
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- One Model to Learn Them All
- Depthwise Separable Convolutions for Neural Machine Translation
- Training Tips for the Transformer Model
- Self-Attention with Relative Position Representations
- Adafactor: Adaptive Learning Rates with Sublinear Memory Cost
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shif
- Layer Normalization
- Semi-supervised Sequence Learning