理解梯度下降法(Gradient Decent)
1. 什么是梯度下降法?
梯度下降法(Gradient Decent)是一种常用的最优化方法,是求解无约束问题最古老也是最常用的方法之一。也被称之为最速下降法。梯度下降法在机器学习中十分常见,多用于求解参数的局部最小值问题。
2. 梯度下降法的原理
引用维基百科中的一张图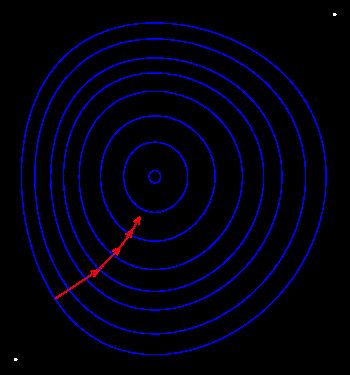
简单来说,梯度下降法就是利用了函数沿梯度方向下降最快的原理来求解极小值,当然也可以沿梯度上升方向求解极大值。具体的原理就不赘述了,可以参考Gradient Decent 的维基百科 梯度下降法。
3. 梯度下降法的求解步骤
这里参考陈宝林的《最优化理论与算法》。
梯度下降法的迭代公式是:\(x^{(k+1)} = x^{(k)} + \lambda _k d^{(k)}\),其中 \(d^{(k)}\)是从\(x^{(k)}\)出发的搜索方向,这里取在点\(x^{(k)}\)处的梯度下降方向,即
\(d^{(k)} = - \nabla f(x^{(k)})\)。
\(\lambda _k\)是从\(x^{(k)}\)出发沿方向\(d^{(k)}\)进行一维搜索的步长,即\(\lambda _k\)满足:
\(f(x^{(k)} + \lambda _k d^{(k)}) = min _{\lambda \geq 0}f(x^{(k)} + \lambda d^{(k)})\)。
计算步骤如下:
- 给定初始点\(x^{(1)} \in R^n\),允许误差\(\epsilon > 0\),置 \(k=1\)。
- 计算搜索方向\(d^{(k)} = -\nabla f(x^{(k)})\)。
- 若\(\parallel d^{(k)}\parallel \leq \epsilon\),则停止计算;否则,从\(x^{(k)}\)出发,沿\(d^{(k)}\)进行一维搜索,求\(\lambda _k\),使:
\(f(x^{(k)} + \lambda _k d^{(k)}) = min _{\lambda \geq 0}f(x^{(k)} + \lambda d^{(k)})\)。 -
令\(x^{(k+1)} = x^{(k)} + \lambda _k d^{(k)}\),令 \(k = k+1\),转步骤2。
4. 举例
1. 利用梯度下降法求解一元函数 \(f(x) = x^2 -3x + 1\)的最小值。
设初始点 \(x^{(1)} = 6\),\(\epsilon = 0.1\)。
第1次迭代:目标函数 f(x)在点\(x\)处的梯度 \(\nabla f(x) = 2x -3\)。令搜索方向 \(d^{(1)} = -\nabla f(x^{(1)}) = -9\),\(\parallel d^{(1)} \parallel = 9 > \epsilon = 0.1\)。
从 \(x^{(1)} = 6\)出发,沿\(d^{(1)}\)方向进行搜索,求步长\(\lambda _1\),即:\(min _{\lambda _1\geq 0} \phi(\lambda _1) = f(x^{(1)} + \lambda _1 d^{(1)})\),
\(x^{(1)} + \lambda _1 d^{(1)} = 6-9\lambda _1\) ,\(\phi(\lambda _1) = (6-9\lambda _1)^2 -3(6-9\lambda _1) + 1\),\(\phi ^{'}(\lambda _1) = -18(6-9\lambda _1) + 27\),令
\(\phi^{'}(\lambda _1) = 0\)得:\(\lambda _1 = \frac{1}{2}\)。于是可以得\(x^{(2)} = x^{(1)} + \lambda _1 d^{(1)} = \frac{3}{2}\)。
第2次迭代:\(d^{(2)} = -\nabla f(x^{(2)}) = 0\),\(\parallel d^{(2)} \parallel = 0 < \epsilon = 0.1\)。所以停止计算。
于是得到 \(f(x) = x^2 -3x + 1\)在 \(x = \frac{3}{2}\)处取得极小值。实际上,\(f(x)\)在\(x = \frac{3}{2}\)处取得最小值。2. 利用梯度下降法求解多元函数的极小值。这里以三元函数\(f(x_1,x_2,x_3) = (x_1 -1)^2 + (x_2 -2)^2 + (x_3 - 3)^2\)求极小值为例。
设初始点 \(x^{(1)} = (5,5,5)\),\(\epsilon = 0.1\)。
第1次迭代:目标函数 \(f(x)\)在点\(x\)处的梯度 \(\nabla f(x) = [2(x_1 -1),2(x_2 -2),2(x_3 -3)]\)。令搜索方向 \(d^{(1)} = -\nabla f(x^{(1)}) = [-8,-6,-4]\), \(\parallel d^{(1)} \parallel = \sqrt{8^2 + 6^2 + 4^2} > \epsilon = 0.1\)。从 \(x^{(1)} = [5,5,5]\)出发,沿\(d^{(1)}\)方向进行搜索,求步长\(\lambda _1\),即:\(min _{\lambda _1\geq 0} \phi(\lambda _1) = f(x^{(1)} + \lambda _1 d^{(1)})\),\(x^{(1)} + \lambda _1 d^{(1)} = [5-8\lambda _1,5 -6\lambda _1,5-4\lambda _1]\),\(\phi(\lambda _1) = (4-8\lambda _1)^2 + (3-6\lambda _1)^2 + (2-4\lambda _1)^2\),\(\phi ^{'}(\lambda _1) = -16(4-8\lambda _1) -12 (3-6\lambda _1) -8(2-4\lambda _1) = 232\lambda _1 -116\),令\(\phi ^{'}(\lambda _1) =0\)得:\(\lambda _1=\frac{1}{2}\)。于是可以得到 \(x^{(2)} = x^{(1)} + \lambda _1 d^{(1)} = [1,2,3]\)。
第2次迭代:\(d^{(2)} = -\nabla f(x^{(2)}) = [0,0,0]\),\(\parallel d^{(2)} \parallel = 0 < \epsilon = 0.1\)。所以停止计算。
于是得到 \(f(x_1,x_2,x_3) = (x_1 -1)^2 + (x_2 -2)^2 + (x_3 - 3)^2\)在 \(x = [1,2,3]\)处取得极小值。实际上,\(f(x)\)在\(x = [1,2,3]\)处取得最小值。5.代码实现(Python)。
这里以求 \(f(x) = x_1^2 + (x_2-7)^2 + (x_3-6)^2 + (cos(x_4)+1)^2 + (sin(x_5))^2\)的极小值为例,初始点设为\((10,10,10,10,10)\),\(\epsilon = 0.1\)。
from __future__ import print_function
from sympy import *
x1,x2,x3,x4,x5 = Symbol('x1'),Symbol('x2'),Symbol('x3'),Symbol('x4'),Symbol('x5') # 定义符号
x = [x1,x2,x3,x4,x5]
lam = Symbol('lam') # 步长变量
z = [10,10,10,10,10] # 定义初始点
epsilon = 0.1
n = 5 # 定义变量个数
num = 100.0 # 求解步长时在[0,1]之间分割的数目,这里假设将步长限定为(0,1)之间
# 定义求极值的函数
def function(x):
return x[0]**2 + (x[1]-7)**2 + (x[2] - 6)**2 + (cos(x[3]) + 1)**2 + sin(x[4])**2
# 求解步长的函数
# 将(0,1)分为 num 份,第i个(i=1,2,...,num-1)步长为 i/num
# 通过遍历,我们找使得f最小(待求函数值最小)的步长
def solve_lam(f):
f_list = [f.subs(lam,i/num) for i in range(1,int(num))]
min_value = min(f_list)
index = f_list.index(min_value)
return (index+1)/num # 返回步长
# 计算梯度向量的长度(二阶范数)
def distance(gradient):
return sqrt(sum([i**2 for i in gradient]))
# 计算y在z点处的梯度
def compute_gradient(y,z):
return [float(diff(y,x[i]).subs(x[i],z[i])) for i in range(n)]
# 更新点的坐标
def compute_new_x(z,lam,gradient):
return [z[i] -lam*gradient[i] for i in range(n)]
y = function(x) # 定义函数表达式
gradient = compute_gradient(y,z)
index = 1 # 初始化梯度下降次数
while(distance(gradient) > epsilon):
s = [z[i] -lam*gradient[i] for i in range(n)]
f = function(s)
step = solve_lam(f) # 计算的实际步长
z = [float(z[i] - step*gradient[i]) for i in range(n)]
print("第%d次梯度下降,点为:" % index,z)
print("第%d次梯度下降,梯度的模长为:" % index,distance(gradient))
gradient = compute_gradient(y,z)
index += 1
print("梯度下降的最终点为:",z)
print("梯度下降最终梯度模长为:",distance(gradient))
print("最终函数极小值为:",function(z))输出结果为:
第1次梯度下降,点为: [0.0, 7.0, 6.0, 9.912451514474444, 9.543527374636186]
第1次梯度下降,梯度的模长为: 22.3799939227002
第2次梯度下降,点为: [0.0, 7.0, 6.0, 9.849088133287399, 9.407069381569496]
第2次梯度下降,梯度的模长为: 0.259399413509407
梯度下降的最终点为: [0.0, 7.0, 6.0, 9.849088133287399, 9.407069381569496]
梯度下降最终梯度模长为: 0.0811485412629629,
最终函数极小值为: 0.00817718083812317 可以看出,只经过了两次梯度下降,就找到了极小值点。这里solve_lam 函数的作用是求解使得一次梯度下降,函数沿负梯度方向下降得最快的步长。这样每次步长都是不同的且最优的,所以寻找局部极小值点的速度非常快。
还有一种方法是使用固定的步长\(\lambda\),但是要注意\(\lambda\)的取值。一般来说\(\lambda\)的取值既不能太大,又不能太小。如果步长过大,那么函数可能会在局部极小值点附近震荡或者取不到极小值;而如果步长过小,则函数收敛到局部极小值点的速度会非常慢,效率低。一般来说,可以多次尝试取不同的\(\lambda\)的值,以最接近局部极小值点的为最佳。这里假设取\(\lambda = 0.1\),程序如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2017/7/19 16:09
# @Author : Lyrichu
# @Email : [email protected]
# @File : gradient_decent.py
'''
@Description:使用梯度下降法求解f(x) = x1^2 + (x2-7)^2 + (x3-6)^2 + (cos(x4)+1)^2 + (sin(x5))^2的极小值
这里采用固定步长
'''
from __future__ import print_function
from sympy import *
x1,x2,x3,x4,x5 = Symbol('x1'),Symbol('x2'),Symbol('x3'),Symbol('x4'),Symbol('x5') # 定义符号
x = [x1,x2,x3,x4,x5]
z = [10,10,10,10,10] # 定义初始点
epsilon = 0.1
n = 5 # 定义变量个数
num = 100.0 # 求解步长时在[0,1]之间分割的数目,这里假设将步长限定为(0,1)之间
step = 0.1 # 定义步长为固定值
# 定义求极值的函数
def function(x):
return x[0]**2 + (x[1]-7)**2 + (x[2] - 6)**2 + (cos(x[3]) + 1)**2 + sin(x[4])**2
# 计算梯度向量的长度(二阶范数)
def distance(gradient):
return sqrt(sum([i**2 for i in gradient]))
# 计算y在z点处的梯度
def compute_gradient(y,z):
return [float(diff(y,x[i]).subs(x[i],z[i])) for i in range(n)]
# 更新点的坐标
def compute_new_x(z,lam,gradient):
return [z[i] -lam*gradient[i] for i in range(n)]
y = function(x) # 定义函数表达式
gradient = compute_gradient(y,z)
index = 1 # 初始化梯度下降次数
while(distance(gradient) > epsilon):
z = [float(z[i] - step*gradient[i]) for i in range(n)]
print("第%d次梯度下降,点为:" % index,z)
print("第%d次梯度下降,梯度的模长为:" % index,distance(gradient))
gradient = compute_gradient(y,z)
index += 1
print("梯度下降的最终点为:",z)
print("梯度下降最终梯度模长为:",distance(gradient))
print("最终函数极小值为:",function(z))输出结果为:
第1次梯度下降,点为: [8.0, 9.4, 9.2, 9.982490302894888, 9.908705474927237]
第1次梯度下降,梯度的模长为: 22.3799939227002
第2次梯度下降,点为: [6.4, 8.92, 8.559999999999999, 9.966450751253301, 9.826338348410065]
第2次梯度下降,梯度的模长为: 17.9082149047513
第3次梯度下降,点为: [5.12, 8.536, 8.047999999999998, 9.951689717070877, 9.754385662490165]
第3次梯度下降,梯度的模长为: 14.3296722821606
第4次梯度下降,点为: [4.096, 8.2288, 7.638399999999999, 9.93804837678198, 9.693135978676548]
第4次梯度下降,梯度的模长为: 11.4658519523503
第5次梯度下降,点为: [3.2768, 7.98304, 7.310719999999999, 9.925393904908995, 9.642004324696792]
第5次梯度下降,梯度的模长为: 9.17406879033011
......
第25次梯度下降,点为: [0.037778931862957166, 7.011333679558887, 6.015111572745182, 9.78022077224335, 9.427338222547055]
第25次梯度下降,梯度的模长为: 0.115020432780820
梯度下降的最终点为: [0.037778931862957166, 7.011333679558887, 6.015111572745182, 9.78022077224335, 9.427338222547055]
梯度下降最终梯度模长为: 0.0951589383799565
最终函数极小值为: 0.00569780461165563 从结果来看,使用固定步长\(\lambda = 0.1\)需要梯度下降25次才能最终到达极小值点,最终结果与前一次基本相同,但是迭代次数却大大增加。所以实践中,还是使用方法一效率会更高一些,但是方法一对于复杂函数的求极值可能会涉及到复杂一元函数求最小值的问题,我是直接采用遍历穷举近似求解的。实践中还可以求导,然后利用二分法等方法求解导函数的零点,从而求最小值。
需要注意的是,梯度下降法只能求解函数的局部极小值,并不能保证可以达到全局最小值。对于有多个极小值点的复杂函数而言,梯度下降法往往只能求到其近似最小值点,而如果想要求全局最小值点,需要使用其他的方法,比如遗传算法、模拟退火算法等。