一、实验目的
1. 学会利用决策树、KNN与Navie Bayes完成预测任务
二、实验工具
1. Anaconda
2. sklearn
3. Pandas
三、实验内容
产品预测任务
1.任务描述
本次比赛主要是一个对进出口交易记录数据进行产品判别的任务。本次任务有 19046 条数据记录,其中的 18279 条记录是有类别属性的,可作为分析时的训练样本,而任务目标是对 767 条测试数据(即验证样本)进行判别(本实验采用其中的20个样本)。
1) 数据描述
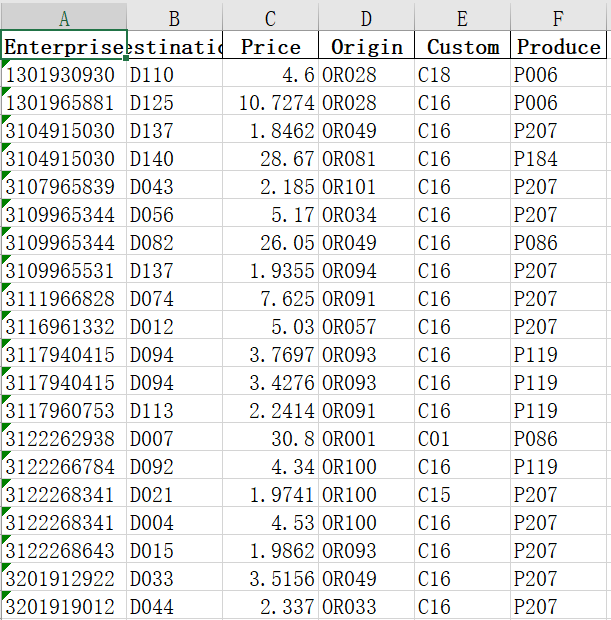
已分类的训练样本提供在比赛题目下 Excel 附件中的 cck_train 表中,训练样本的详情如下,其中,表格中的每条记录包含 7 个字段。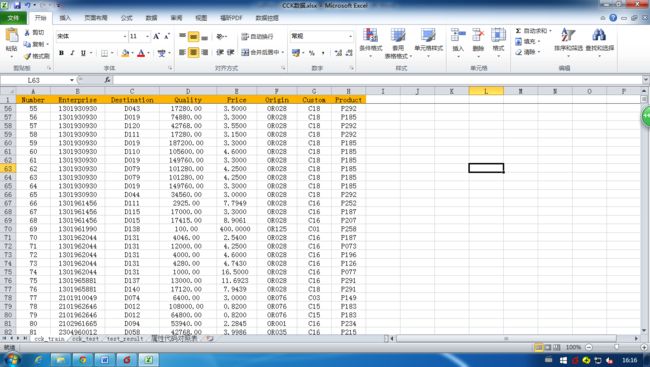
未分类的验证样本提供在比赛题目下 Excel 附件中的 cck_test 表中。验证样本的信息如下,表格中的每条记录包含 5 个已知属性字段,其中表中属性内容与 cck_表 略有不同,具体属性字段的含义请参考下节描述。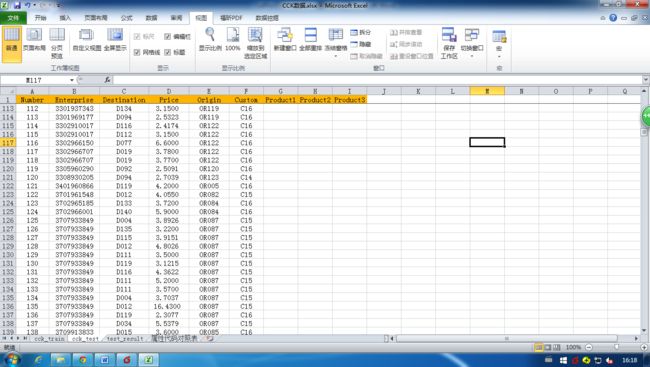
2) 属性描述
本次任务提供的样本数据包含 7 个基础属性字段,其中有 2 个连续型数值类属性字段为:Quality and Price,5 个离散型数值类属性字段为:Enterprise(560)、Destination(144)、Origin(131)、Custom(20)、Product(364)。各字段具体含义如下:
Quality:表示每条交易记录中交易产品的数量,可忽略单位。
Price:表示每条交易记录中交易产品的平均价格,单位为元。
Enterprise(560):表示每条交易记录中交易产品的供应商编码。
Destination(144):表示每条交易记录中交易产品的买方国家编码。
Origin(131): 表示每条交易记录中交易产品的原产地编码。
Custom(20): 表示每条交易记录中交易产品通关海关编码。
Product(364): 表示每条交易记录中交易产品的名称类别。
在验证样本中的字段 Product1 ,Product2 ,Product3 为参赛者进行分类预测后概率由大到小排名
前 3 名的产品类别,字段编码同 Product 字段。
3) 样本描述
不论是在训练样本还是验证样本中,我们可以看到,一条交易记录数据包括 Enterprise(560)、
Destination(144)、Origin(131)、Custom(20)、Product(364)5 个基本属性字段,括
号内为每个属性下包含的所有特征值个数,而这些属性将是我们学习训练样本得到分类模型的关
键,根据一条交易记录的每个属性的特征值的出现情况,利用模型对验证样本的交易产品类别进
行分类预测。
2. 结果评价
在整个验证样本预测结果中,参赛者在第 i 条记录的产品类别预测值与实际类别完全一致时可得
10 分,即预测结果字段 Product1 为实际产品类别。产品类别预测值与实际类别不一致时,其中
如果预测结果 Product2 为实际产品类别的,参赛者在该条验证样本可得 2 分;如果预测结果
Product3 为实际产品类别的,该条验证样本可得 1 分,对整个 767 条验证样本预测结果加总得
到一个总分 S:(本实验采用期中的20个样本)。
取 F=S/P*100%
(其中 P 为所有验证样本类别预测结果均与实际结果相一致的总成绩,即 P=7670)为每位参与者的模型评价得分,各位参与者模型得分由高到低依次排列。
四、实验要求
1. 写出摘要,即简要阐述任务的完成情况。
在处理数据时遇到了些麻烦,使用LabelEncoder对字符型数据进行了编码转换得以解决。通过对DataFrame的操作,最终实现了数据的处理,并将预测的产品类别保存在了excel表格中。
2. 给出任务完成方案。可以用框图等方式。
使用sklearn的KNeighborsClassifier()函数进行knn预测。
3. 给出具体的任务实现步骤。
1.导入excel中的数据
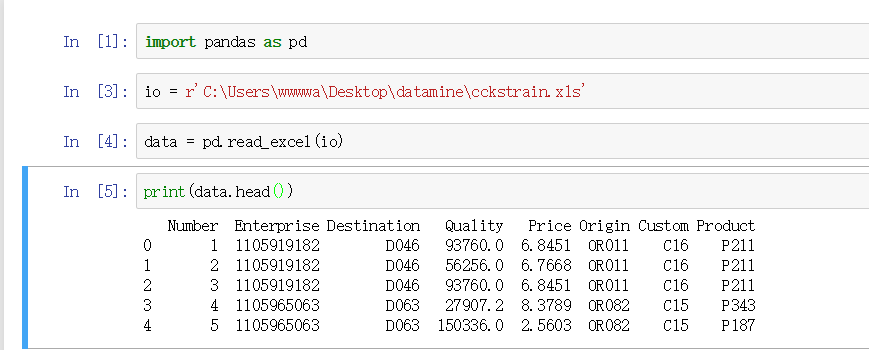
2.将数据划分为X_train 和结果Product:y_train

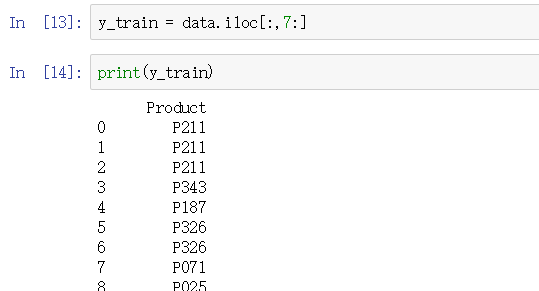

4.声明knn训练模型

结果却出现了类型转换错误: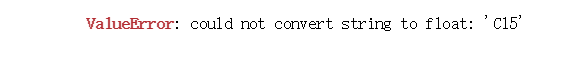
解决方案:LabelEncoder 用 0 到 n_classes-1 之间的值对标签进行编码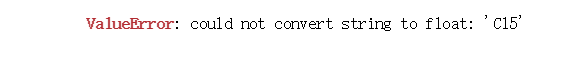
使用代码:
for col in X_test.columns.values: if X_test [ col ] .dtypes=='object': le.fit(X_test[col]) X_test[col]=le.transform(X_test[col])
报错:
经测试,Enterprise被识别成float,但事实上数据中夹杂着ABPE等字符
于是进行了类型转换处理
编码后的数据效果如下图: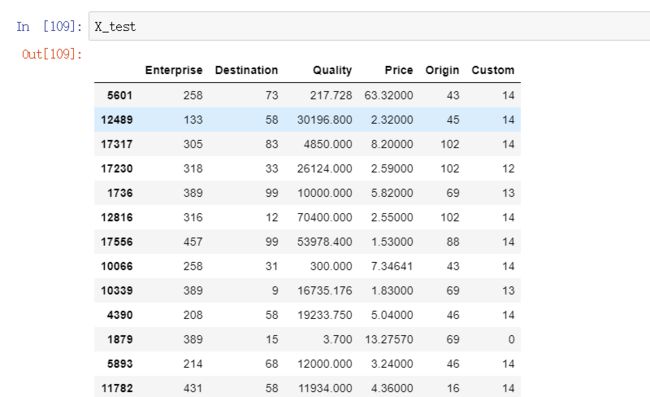
最终得出预测结果:
导入给定的测试样本,并对前20个数据进行预测判断Product
knn.predict得到预测结果

4. 给出任务完成结果,结果写到实验报告系统中,用表格的形式。