28天自制你的AlphaGo(三):对策略网络的深入分析以及它的弱点所在
一、神经网络在围棋中的历史
再次回顾 AlphaGo v13 的三大组件:
MCTS(蒙特卡洛树搜索)
CNN (卷积神经网络,包括:策略网络 policy network、快速走子网络 playout network、价值网络 value network)
RL (强化学习)
在上世纪90年代初期,大家就已经开始实验将神经网络(当时是浅层的)与强化学习应用于棋类游戏。最著名的例子是西洋双陆棋 Backgammon 的 TD-Gammon,它在自我对弈了150万局后,就达到了相当强的棋力,摘选 Wikipedia 中的一段:
Backgammon expert Kit Woolsey found that TD-Gammon's positional judgement, especially its weighing of risk against safety, was superior to his own or any human's.
TD-Gammon's excellent positional play was undercut by occasional poor endgame play. The endgame requires a more analytic approach, sometimes with extensive lookahead. TD-Gammon's limitation to two-ply lookahead put a ceiling on what it could achieve in this part of the game. TD-Gammon's strengths and weaknesses were the opposite of symbolic artificial intelligence programs and most computer software in general: it was good at matters that require an intuitive "feel", but bad at systematic analysis.

简单地说,就是"大局观"特别强(比当时所有人类都强,不过,后来人也学习它的招法,人也进步了!),但是"官子弱"。这恰好和许多围棋 AI 给人的感觉完全一致。
然而神经网络(浅层的)在围棋中的应用却遇到很大的困难。例如90年代就有一个神经网络围棋叫 NeuroGo:The Integration of A Priori Knowledge into a Go Playing Neural Network 它的架构(如下图)也经过不少考虑,但棋力很低,10K的水平:
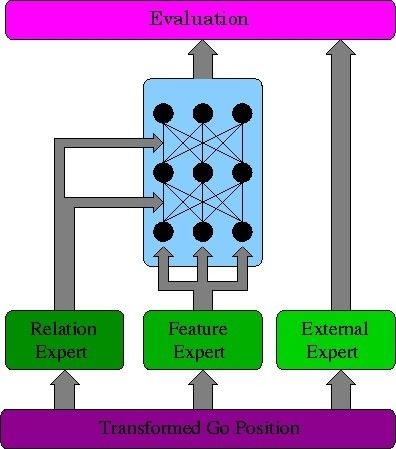
二、策略网络的工作原理
究其原因,我们看策略网络的输入(很多年来大家使用的输入都大同小异,最重要的是把棋子按气的口数分类,如1口气的,2口气的,3口气的,4口和更多气的):

策略网络的目的,简单说是快速预测双方的下一手的位置,类似于棋手的第一感。实际上,策略网络的第一层是类似于这样的规则的集合(为方便非程序员理解,这里举一个特别的例子):
"如果这个位置的上面有一个1口气的对方棋子,左下区域的2口气以上的本方棋子密度为某某某,右边某某区域本方的棋子密度按气加权为某某某,......,那么将以上事实加权算出有xx%的几率在这里落子"
看上去,这种规则更像是能预测某些局部的棋形情况,不像能准确地预测下一手。现代的围棋策略网络为何取得大的进展,是因为使用了 卷积神经网络 + 深度神经网络 的思想。
如果我们只看 AlphaGo v13 的第一层和最后一层神经网络,那么它的运作是:
1. 使用了 192 条类似的规则(由棋谱自动训练出来)(规则的数量太少固然不行,太多也会慢同时容易走入误区),然后在全棋盘扫描每个点(这就是卷积神经网络的思想),计算由所有规则综合得到的权值。
2. 再输入“1x1卷积核”网络(通俗地说,就是将每个点的上面算出的 192 种模式权值综合考虑,得出最终的落子几率),算出棋盘每个点作为走子的几率。如果也举个特别的例子,这类似于:
"如果要判断是否在这里走一个子,就会将【这里符合 A模式的程度】*0.8,【这里符合 B模式的程度】*0.4,【这里符合 C模式的程度】*(-0.2),等等等等,综合考虑,得出一个落子机率。"
3. 上述具体的训练过程,就是每见到一个情况就加强这个情况的权值。因此越经常出现的情况就会越被加强。
三、深度神经网络为何有效
如果只有两层网络,在看棋谱时,对于对弈者的下一手的位置,只能达到 35% 左右的正确率:cs.utoronto.ca/
但是,通过使用深度神经网络,也就是多层的网络,AlphaGo v13 可以达到 55% 左右的预测正确率。这有两个原因:
一,是概念层面的。举例,人在选点时,会考虑附近的双方棋子的"厚薄",但"厚薄"是个高级概念,大致可以认为是棋块的"安定性"与"棋形"的结合。那么我们可以想象,如果第一层的规则,包括一部分专门负责"安定性"的规则,和一部分专门负责"棋形"的规则,再往上一层就可以通过加权考虑这两种规则的结果,得出类似"厚薄"的概念。然后再往上一层,就可以再运用之前得出的棋盘每个位置的"厚薄"情况,进行进一步的决策。
深度神经网络的最有趣之处在于,并不需要特别告诉它存在这样的概念的层次,它会自动从数据中形成这样的层次。
二,与棋盘和卷积神经网络的性质有关。第一层的规则,最好是局部的规则,因为这样的规则的泛化能力较高。譬如 AlphaGo v13 第一层使用的是 5x5 的局部,然后在第二层中再考虑 3x3 个 5x5 的局部,由于这些 5x5 的局部之间有重叠部分,就会形成一个 7x7 的局部。通过一层层往上加,最终可覆盖整个 19x19 的棋盘(如果你喜欢,可以继续往上加)。这符合我们的一种直觉:棋形会从里向外辐射一层层的影响,先看 5x5 ,然后看看周边的棋子就是 7x7 的情况,然后继续看下去。
四、新发展:残差网络
自然的问题是,如果这么说,是不是层越多就越好?
从前大家认为不是,因为太多层后很难训练,有时在训练集上的准确度已经会变差。
但是,如果仔细想想,这有点问题。我们不妨假设新加的一层就是一个不变变换,就是什么都不改变,就把上一层的输入做为输出。那么,此时的模型不会变好也不会变差。换而言之,增加层数,是永远不应该变差的!(这里的意思是,在训练集上的准确度不应该下降。在测试集上的准确度可能会由于过拟合而下降)
这就是 ResNet 残差网络的思想: 通过使用它,网络可以加到上千层也没有问题,几乎是一个免费的午餐:

通过运用残差网络和少量 MCTS 模拟,策略网络的准确度可达 58% 以上:https://openreview.net/pdf?id=Bk67W4Yxl 。这近乎于理论最高值了,因为人的走棋不完美,同样的局面可以有不同的走法。
五、策略网络的弱点
然而策略网络是有弱点的。我在此更具体地说明几种情况。
第一,学习的棋谱数量有限,因此会有未见过的局面;同时,有时会知其然而不知其所以然,只学到了表面。这个问题很有趣,譬如,很多人发现 Zen6 (包括 DeepZenGo)有时会在征子上短路。下图是 2016/11/27 07:43 日 EWZGDXFEZ 与 Zen19L 在 KGS 的对局,黑棋是 Zen19L,走出了惊世骇俗的一步 M4,并认为自己的胜率高达 70% 以上:

结果被白棋直接在 N4 征死(同时胜率立刻掉到17%...)。这到底是为什么?我们可以打开 Zen6 的策略网络显示(Hotspots 菜单):
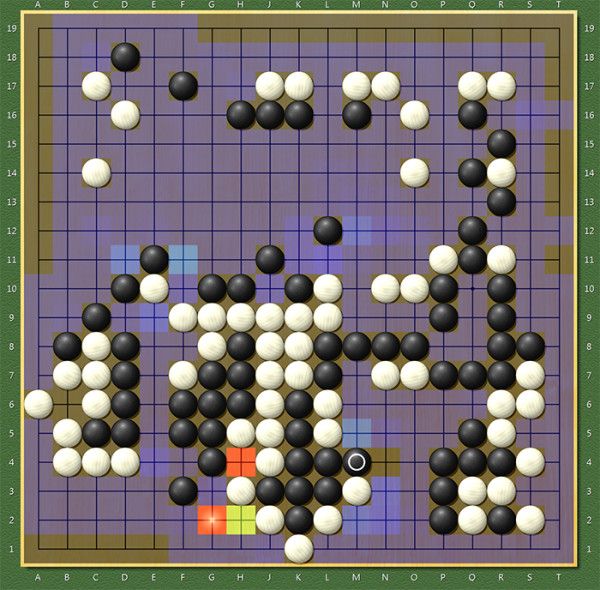
非常有趣。Zen6 认为白棋最可能的下一步是在 G2(概率大小是按红橙黄绿蓝紫排列,最不可能的是无色),而 N4 是它眼中白棋最不可能下的棋。它根本想不到白棋会走 N4。这个问题的成因是明显的:
在人类高手的对弈中,很少出现一方对另一方进行征子,因为另一方会预先避免对方征子成功。而策略网络在学习中,却不可能看到如此高的概念,它只能看到,如果有一方走出看似可以被征的棋形,另一方不会去征,于是,它所学到的,就是大家都不会去征对方的子。
著名的第 78 手与此也有类似的原因(区别是隐蔽得多)。同样,机器很难理解人为什么会"保留",因为人"保留"的原因是另一个层次的(例如作为劫材)。当然,人的"保留"也不见得都对。
解决这个现象,初级的办法是加入手动的处理,更好的办法是通过自我对弈学习更多的局面。AlphaGo 比其它各路狗强大的重要原因,在于经过了上亿盘的左右互搏学习,见过的局面太多了。
第二,由于输入中缺乏对于多口气的精确区分(请思考为什么没有精确区分),可以说它不会精确数气,对于对杀和死活容易犯晕。这一般可以被蒙特卡洛树搜索纠正,但总会有纠正不了的情况。不过,虽然其它各路狗在此都经常会犯错,但 Master 却还没有被人抓到,有可能在于它已经学会有意避免这种局面,就像传说它会有意避免某些大型变化。
第三,靠感觉是不会精确收官和打劫,因此许多狗的官子和打劫有缺陷(换而言之,人可以靠官子和打劫逆转)。不过目前看来 AlphaGo 的新版已经专门为此做过额外处理,不会让人抓到这么明显的漏洞。我的一个猜测是,新版 AlphaGo 可能也建立了一个以"赢的子数"作为目标的价值网络,并且在适当的时候会参考它的结果。
许多人可能会很好奇,为什么各路狗都是用"胜率"而不是"赢的子数"作为目标。这是因为大家发现以"胜率"为标准,得到的胜率更高(这看似是废话,其实不是废话)。说到这个,我见过网上有人提为什么不在稳赢的时候改变贴目,尽量赢得更多一些,棋走得更好看;这个想法其实大家早就试过了,叫 Dynamic Komi 动态贴目,后果也是会稍微降低胜率。
不过,电脑的保守,有时候可以被人类利用。譬如,在电脑的棋有潜在缺陷的时候,可以先故意不走,等到收官阶段,电脑认为必胜(并且退让了很多)的时候再走,让电脑措手不及。最近陈耀烨就通过类似的办法连赢了国产狗好几盘,而 DeepZenGo 也被某位棋手抓到了一个漏洞连赢了好几盘(而这两位狗对付其它职业棋手的胜率已经相当高了)。围棋确实很有趣。我相信人机对抗并没有结束,还会继续下去,因为双方都会不断进步。
相关阅读:
《28 天自制你的 AlphaGo(一):围棋AI基础及版本安装》
《 28 天自制你的 AlphaGo(二):训练策略网络,真正与之对弈》本文作者:彭博
本文转自雷锋网禁止二次转载,原文链接