Java集合系列总结
ArrayList
- 参考地址:java提高篇(二一)—–ArrayList
- 数据结构:数组
- 初始容量:10
- 扩容方式:拷贝扩容
- 同步方式:非线程同步
底层使用数组
transient Object[] elementData;- non-private: simplify nested class access—即简化嵌套类的访问
- transient : 当一个对象序列化时,transient修饰的变量将不被包含在内
- Object[] elementData:ArrayList使用的容器
构造函数
- ArrayList():默认构造函数,提供初始容量为10的空列表。
- ArrayList(int initialCapacity):构造一个具有指定初始容量的空列表。
- ArrayList(Collection < ? extends E> c):构造一个包含指定 collection 的元素的列表,这些元素是按照该 collection 的迭代器返回它们的顺序排列的。
新增
ArrayList提供了add(E e)、add(int index, E element)、addAll(Collection < ? extends E> c)、addAll(int index, Collection < ? extends E> c)、set(int index, E element)这个五个方法来实现ArrayList增加。
- add(E e):将指定的元素添加到此列表的尾部。
- add(int index, E element):将指定的元素插入此列表中的指定位置。
- addAll(Collection < ? extends E> c):按照指定 collection 的迭代器所返回的元素顺序,将该 collection 中的所有元素添加到此列表的尾部。
- addAll(int index, Collection < ? extends E> c):从指定的位置开始,将指定 collection 中的所有元素插入到此列表中。
- set(int index, E element):用指定的元素替代此列表中指定位置上的元素。
删除
ArrayList提供了remove(int index)、remove(Object o)、removeRange(int fromIndex, int toIndex)、removeAll()四个方法进行元素的删除。
- remove(int index):移除此列表中指定位置上的元素。
- remove(Object o):移除此列表中首次出现的指定元素(如果存在)。
- removeRange(int fromIndex, int toIndex):移除列表中索引在 fromIndex(包括)和 toIndex(不包括)之间的所有元素。
- removeAll(Collection< ?> c):是继承自AbstractCollection的方法,ArrayList本身并没有提供实现。jdk1.8提供了实现。。。。
查找
ArrayList提供了get(int index)用读取ArrayList中的元素。由于ArrayList是动态数组,所以我们完全可以根据下标来获取ArrayList中的元素,而且速度还比较快,故ArrayList长于随机访问。
扩容
在上面的新增方法的源码中我们发现每个方法中都存在这个方法:ensureCapacity(),该方法就是ArrayList的扩容方法。在前面就提过ArrayList每次新增元素时都会需要进行容量检测判断,若新增元素后元素的个数会超过ArrayList的容量,就会进行扩容操作来满足新增元素的需求。所以当我们清楚知道业务数据量或者需要插入大量元素前,我可以使用ensureCapacity来手动增加ArrayList实例的容量,以减少递增式再分配的数量。
public void ensureCapacity(int minCapacity) {
int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
// any size if not default element table
? 0
// larger than default for default empty table. It's already
// supposed to be at default size.
: DEFAULT_CAPACITY;
if (minCapacity > minExpand) {
ensureExplicitCapacity(minCapacity);
}
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}在这里有一个疑问,为什么每次扩容处理会是1.5倍,而不是2.5、3、4倍呢?通过google查找,发现1.5倍的扩容是最好的倍数。因为一次性扩容太大(例如2.5倍)可能会浪费更多的内存(1.5倍最多浪费33%,而2.5被最多会浪费60%,3.5倍则会浪费71%……)。但是一次性扩容太小,需要多次对数组重新分配内存,对性能消耗比较严重。所以1.5倍刚刚好,既能满足性能需求,也不会造成很大的内存消耗。
处理这个ensureCapacity()这个扩容数组外,ArrayList还给我们提供了将底层数组的容量调整为当前列表保存的实际元素的大小的功能。它可以通过trimToSize()方法来实现。该方法可以最小化ArrayList实例的存储量。
LinkedList
- 参考地址:java提高篇(二二)—–LinkedList
JDK1.8源码分析之LinkedList(七) - 数据结构:链表
- 初始容量:null
- 扩容方式:无需扩容
- 同步方式:非线程同步
数据结构
LinkedList的核心部分:数据结构,其数据结构如下:

说明:如上图所示,LinkedList底层使用的双向链表结构,有一个头结点和一个尾结点,双向链表意味着我们可以从头开始正向遍历,或者是从尾开始逆向遍历,并且可以针对头部和尾部进行相应的操作。
类的继承关系
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable说明:LinkedList的类继承结构很有意思,我们着重要看是Deque接口,Deque接口表示是一个双端队列,那么也意味着LinkedList是双端队列的一种实现,所以,基于双端队列的操作在LinkedList中全部有效。
类的内部类
private static class Node<E> {
E item; // 结点元素
Node next; // 前一个结点
Node prev; // 后一个结点
// 构造函数,赋值前驱后继
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
} 类的属性
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
// 实际元素个数
transient int size = 0;
// 头结点
transient Node first;
// 尾结点
transient Node last;
} 说明:LinkedList的属性非常简单,一个头结点、一个尾结点、一个表示链表中实际元素个数的变量。注意,头结点、尾结点都有transient关键字修饰,这也意味着在序列化时该域是不会序列化的。
构造函数
- LinkedList()
- LinkedList(Collection < ? extends E>)
核心函数分析
- add(E e):添加一个元素
public boolean add(E e) {
linkLast(e); // 将元素添加至链表尾
return true;
}
void linkLast(E e) {
// 保存尾结点,l为final类型,不可更改
final Node l = last;
// 新生成结点的前驱为l,后继为null
final Node newNode = new Node<>(l, e, null);
// 重新赋值尾结点
last = newNode;
if (l == null) // 尾结点为空
first = newNode; // 赋值头结点
else // 尾结点不为空
l.next = newNode; // 尾结点的后继为新生成的结点
// 大小加1
size++;
// 结构性修改加1
modCount++;
} 对于添加一个元素至链表中会调用add方法 -> linkLast方法。对于添加元素的情况我们使用如下示例进行说明。
List list = new LinkedList<>();
list.add(1);
list.add(2); 首先调用无参构造函数,之后添加元素5,之后再添加元素6。具体的示意图如下:

- addAll(Collection< ? extends E> c):添加一个集合
addAll有两个重载函数,addAll(Collection< ? extends E>)型和addAll(int, Collection< ? extends E>)型,我们平时习惯调用的addAll(Collection< ? extends E>)型会转化为addAll(int, Collection< ? extends E>)型,所以我们着重分析此函数即可。
// 添加一个集合
public boolean addAll(int index, Collection c) {
// 检查插入的的位置是否合法
checkPositionIndex(index);
// 将集合转化为数组
Object[] a = c.toArray();
// 保存集合大小
int numNew = a.length;
if (numNew == 0) // 集合为空,直接返回
return false;
Node pred, succ; // 前驱,后继
if (index == size) { // 如果插入位置为链表末尾,则后继为null,前驱为尾结点
succ = null;
pred = last;
} else { // 插入位置为其他某个位置
succ = node(index); // 寻找到该结点
pred = succ.prev; // 保存该结点的前驱
}
for (Object o : a) { // 遍历数组
@SuppressWarnings("unchecked") E e = (E) o; // 向下转型
// 生成新结点
Node newNode = new Node<>(pred, e, null);
if (pred == null) // 表示在第一个元素之前插入(索引为0的结点)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) { // 表示在最后一个元素之后插入
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
// 修改实际元素个数
size += numNew;
// 结构性修改加1
modCount++;
return true;
} 说明:参数中的index表示在索引下标为index的结点(实际上是第index + 1个结点)的前面插入。在addAll函数中,addAll函数中还会调用到node函数,get函数也会调用到node函数,此函数是根据索引下标找到该结点并返回,具体代码如下
Node node(int index) {
// 判断插入的位置在链表前半段或者是后半段
if (index < (size >> 1)) { // 插入位置在前半段
Node x = first;
for (int i = 0; i < index; i++) // 从头结点开始正向遍历
x = x.next;
return x; // 返回该结点
} else { // 插入位置在后半段
Node x = last;
for (int i = size - 1; i > index; i--) // 从尾结点开始反向遍历
x = x.prev;
return x; // 返回该结点
}
} 说明:在根据索引查找结点时,会有一个小优化,结点在前半段则从头开始遍历,在后半段则从尾开始遍历,这样就保证了只需要遍历最多一半结点就可以找到指定索引的结点。
- remove(Object o):删除元素
public boolean remove(Object o) {
if (o == null) {
for (Node x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
E unlink(Node x) {
// 保存结点的元素
final E element = x.item;
// 保存x的后继
final Node next = x.next;
// 保存x的前驱
final Node prev = x.prev;
if (prev == null) { // 前驱为空,表示删除的结点为头结点
first = next; // 重新赋值头结点
} else { // 删除的结点不为头结点
prev.next = next; // 赋值前驱结点的后继
x.prev = null; // 结点的前驱为空,切断结点的前驱指针
}
if (next == null) { // 后继为空,表示删除的结点为尾结点
last = prev; // 重新赋值尾结点
} else { // 删除的结点不为尾结点
next.prev = prev; // 赋值后继结点的前驱
x.next = null; // 结点的后继为空,切断结点的后继指针
}
x.item = null; // 结点元素赋值为空
// 减少元素实际个数
size--;
// 结构性修改加1
modCount++;
// 返回结点的旧元素
return element;
} 思考
在addAll函数中,传入一个集合参数和插入位置,然后将集合转化为数组,然后再遍历数组,挨个添加数组的元素,但是问题来了,为什么要先转化为数组再进行遍历,而不是直接遍历集合呢?从效果上两者是完全等价的,都可以达到遍历的效果。关于为什么要转化为数组的问题,我的思考如下:1. 如果直接遍历集合的话,那么在遍历过程中需要插入元素,在堆上分配内存空间,修改指针域,这个过程中就会一直占用着这个集合,考虑正确同步的话,其他线程只能一直等待。2. 如果转化为数组,只需要遍历集合,而遍历集合过程中不需要额外的操作,所以占用的时间相对是较短的,这样就利于其他线程尽快的使用这个集合。说白了,就是有利于提高多线程访问该集合的效率,尽可能短时间的阻塞。总结
分析完了LinkedList源码,其实很简单,值得注意的是LinkedList可以作为双端队列使用,这也是队列结构在Java中一种实现,当需要使用队列结构时,可以考虑LinkedList
HashMap
Java8的HashMap对之前做了较大的优化,其中最重要的一个优化就是桶中的元素不再唯一按照链表组合,也可以使用红黑树进行存储,总之,目标只有一个,那就是在安全和功能性完备的情况下让其速度更快,提升性能。
参考资料
JDK1.8源码分析之HashMap(一)
HashMap源码注解
Java HashMap工作原理及实现
数据结构

由上图可知,HashMap的基本数据结构是数组+链表+红黑树。红黑树的引入是为了进一步提高效率。
类的继承关系
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable 可以看到HashMap继承自父类(AbstractMap),实现了Map、Cloneable、Serializable接口。其中,Map接口定义了一组通用的操作;Cloneable接口则表示可以进行拷贝,在HashMap中,实现的是浅层次拷贝,即对拷贝对象的改变会影响被拷贝的对象;Serializable接口表示HashMap实现了序列化,即可以将HashMap对象保存至本地,之后可以恢复状态。
类的属性
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
// 序列号
private static final long serialVersionUID = 362498820763181265L;
// 默认的初始容量是16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认的填充因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 当桶(bucket)上的结点数大于这个值时会转成红黑树
static final int TREEIFY_THRESHOLD = 8;
// 当桶(bucket)上的结点数小于这个值时树转链表
static final int UNTREEIFY_THRESHOLD = 6;
// 桶中结构转化为红黑树对应的table的最小大小
static final int MIN_TREEIFY_CAPACITY = 64;
// 存储元素的数组,总是2的幂次倍
transient Node[] table;
// 存放具体元素的集
transient Set> entrySet;
// 存放元素的个数,注意这个不等于数组的长度。
transient int size;
// 每次扩容和更改map结构的计数器
transient int modCount;
// 临界值 当实际大小(容量*填充因子)超过临界值时,会进行扩容
int threshold;
// 填充因子
final float loadFactor;
} 构造函数
- HashMap()
/**
* Constructs an empty HashMap with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}- HashMap(int initialCapacity)
/**
* Constructs an empty HashMap with the specified initial
* capacity and the default load factor (0.75).
*
* @param initialCapacity the initial capacity.
* @throws IllegalArgumentException if the initial capacity is negative.
*/
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}- HashMap(int initialCapacity, float loadFactor)
/**
* Constructs an empty HashMap with the specified initial
* capacity and load factor.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public HashMap(int initialCapacity, float loadFactor) {
// 初始容量不能小于0,否则报错
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// 初始容量不能大于最大值,否则为最大值
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// 填充因子不能小于或等于0,不能为非数字
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// 初始化填充因子
this.loadFactor = loadFactor;
// 初始化threshold大小
this.threshold = tableSizeFor(initialCapacity);
}- HashMap(Map< ? extends K, ? extends V> m)
public HashMap(Map m) {
// 初始化填充因子
this.loadFactor = DEFAULT_LOAD_FACTOR;
// 将m中的所有元素添加至HashMap中
putMapEntries(m, false);
}- putMapEntries(Map< ? extends K, ? extends V> m, boolean evict):函数将m的所有元素存入本HashMap实例中。
final void putMapEntries(Map m, boolean evict) {
int s = m.size();
if (s > 0) {
// 判断table是否已经初始化
if (table == null) { // pre-size
// 未初始化,s为m的实际元素个数
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
// 计算得到的t大于阈值,则初始化阈值
if (t > threshold)
threshold = tableSizeFor(t);
}
// 已初始化,并且m元素个数大于阈值,进行扩容处理
else if (s > threshold)
resize();
// 将m中的所有元素添加至HashMap中
for (Map.Entry e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}核心函数解析
- put(K key, V value)
- 对key的hashCode()做hash,然后再计算index;
- 如果没碰撞直接放到bucket里;
- 如果碰撞了,以链表的形式存在buckets后;
- 如果碰撞导致链表过长(大于等于TREEIFY_THRESHOLD),就把链表转换成红黑树;
- 如果节点已经存在就替换old value(保证key的唯一性)
- 如果bucket满了(超过load factor*current capacity),就要resize。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;
// table未初始化或者长度为0,进行扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// (n - 1) & hash 确定元素存放在哪个桶中,桶为空,新生成结点放入桶中(此时,这个结点是放在数组中)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 桶中已经存在元素
else {
Node e; K k;
// 比较桶中第一个元素(数组中的结点)的hash值相等,key相等
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// 将第一个元素赋值给e,用e来记录
e = p;
// hash值不相等,即key不相等;为红黑树结点
else if (p instanceof TreeNode)
// 放入树中
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
// 为链表结点
else {
// 在链表最末插入结点
for (int binCount = 0; ; ++binCount) {
// 到达链表的尾部
if ((e = p.next) == null) {
// 在尾部插入新结点
p.next = newNode(hash, key, value, null);
// 结点数量达到阈值,转化为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
// 跳出循环
break;
}
// 判断链表中结点的key值与插入的元素的key值是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// 相等,跳出循环
break;
// 用于遍历桶中的链表,与前面的e = p.next组合,可以遍历链表
p = e;
}
}
// 表示在桶中找到key值、hash值与插入元素相等的结点
if (e != null) {
// 记录e的value
V oldValue = e.value;
// onlyIfAbsent为false或者旧值为null
if (!onlyIfAbsent || oldValue == null)
//用新值替换旧值
e.value = value;
// 访问后回调
afterNodeAccess(e);
// 返回旧值
return oldValue;
}
}
// 结构性修改
++modCount;
// 实际大小大于阈值则扩容
if (++size > threshold)
resize();
// 插入后回调
afterNodeInsertion(evict);
return null;
} - get(Object key)
- bucket里的第一个节点,直接命中;
- 如果有冲突,则通过key.equals(k)去查找对应的entry
若为树,则在树中通过key.equals(k)查找,O(logn);
若为链表,则在链表中通过key.equals(k)查找,O(n)。
public V get(Object key) {
Node e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node getNode(int hash, Object key) {
Node[] tab; Node first, e; int n; K k;
// table已经初始化,长度大于0,根据hash寻找table中的项也不为空
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 桶中第一项(数组元素)相等
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 桶中不止一个结点
if ((e = first.next) != null) {
// 为红黑树结点
if (first instanceof TreeNode)
// 在红黑树中查找
return ((TreeNode)first).getTreeNode(hash, key);
// 否则,在链表中查找
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
} - resize()
当put时,如果发现目前的bucket占用程度已经超过了Load Factor所希望的比例,那么就会发生resize。在resize的过程,简单的说就是把bucket扩充为2倍,之后重新计算index,把节点再放到新的bucket中。resize的注释是这样描述的:
Initializes or doubles table size. If null, allocates in accord with initial capacity target held in field threshold. Otherwise, because we are using power-of-two expansion, the elements from each bin must either stay at same index, or move with a power of two offset in the new table.
大致意思就是说,当超过限制的时候会resize,然而又因为我们使用的是2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。
如图所示
怎么理解呢?例如我们从16扩展为32时,具体的变化如下所示:

因此元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:

因此,我们在扩充HashMap的时候,不需要重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”。可以看看下图为16扩充为32的resize示意图:
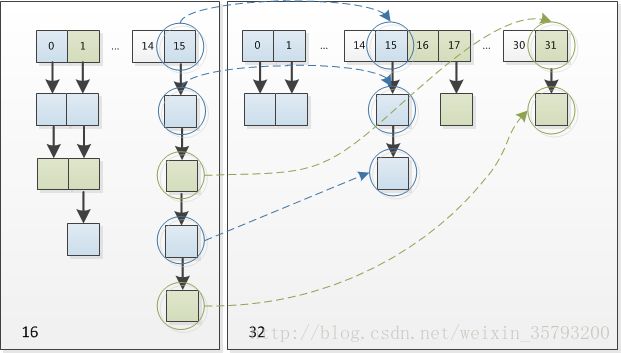
这个设计确实非常的巧妙,既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。
final Node[] resize() {
// 当前table保存
Node[] oldTab = table;
// 保存table大小
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// 保存当前阈值
int oldThr = threshold;
int newCap, newThr = 0;
// 之前table大小大于0
if (oldCap > 0) {
// 之前table大于最大容量
if (oldCap >= MAXIMUM_CAPACITY) {
// 阈值为最大整形
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 容量翻倍,使用左移,效率更高
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 阈值翻倍
newThr = oldThr << 1; // double threshold
}
// 之前阈值大于0
else if (oldThr > 0)
newCap = oldThr;
// oldCap = 0并且oldThr = 0,使用缺省值(如使用HashMap()构造函数,之后再插入一个元素会调用resize函数,会进入这一步)
else {
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 新阈值为0
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
// 初始化table
Node[] newTab = (Node[])new Node[newCap];
table = newTab;
// 之前的table已经初始化过
if (oldTab != null) {
// 复制元素,重新进行hash
for (int j = 0; j < oldCap; ++j) {
Node e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode)e).split(this, newTab, j, oldCap);
else { // preserve order
Node loHead = null, loTail = null;
Node hiHead = null, hiTail = null;
Node next;
// 将同一桶中的元素根据(e.hash & oldCap)是否为0进行分割,分成两个不同的链表,完成rehash
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
} 总结
- 什么时候会使用HashMap?他有什么特点?
是基于Map接口的实现,存储键值对时,它可以接收null的键值,是非同步的,HashMap存储着Entry(hash, key, value, next)对象。 - 你知道HashMap的工作原理吗?
通过hash的方法,通过put和get存储和获取对象。存储对象时,我们将K/V传给put方法时,它调用hashCode计算hash从而得到bucket位置,进一步存储,HashMap会根据当前bucket的占用情况自动调整容量(超过Load Facotr则resize为原来的2倍)。获取对象时,我们将K传给get,它调用hashCode计算hash从而得到bucket位置,并进一步调用equals()方法确定键值对。如果发生碰撞的时候,Hashmap通过链表将产生碰撞冲突的元素组织起来,在Java 8中,如果一个bucket中碰撞冲突的元素超过某个限制(默认是8),则使用红黑树来替换链表,从而提高速度。 - 你知道get和put的原理吗?equals()和hashCode()的都有什么作用?
通过对key的hashCode()进行hashing,并计算下标( n-1 & hash),从而获得buckets的位置。如果产生碰撞,则利用key.equals()方法去链表或树中去查找对应的节点 - 你知道hash的实现吗?为什么要这样实现?
在Java 1.8的实现中,是通过hashCode()的高16位异或低16位实现的:(h = k.hashCode()) ^ (h >>> 16),主要是从速度、功效、质量来考虑的,这么做可以在bucket的n比较小的时候,也能保证考虑到高低bit都参与到hash的计算中,同时不会有太大的开销。 - 如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?
如果超过了负载因子(默认0.75),则会重新resize一个原来长度两倍的HashMap,并且重新调用hash方法。
以Entry[]数组实现的哈希桶数组,用Key的哈希值取模桶数组的大小可得到数组下标。
插入元素时,如果两条Key落在同一个桶(比如哈希值1和17取模16后都属于第一个哈希桶),我们称之为哈希冲突。
JDK的做法是链表法,Entry用一个next属性实现多个Entry以单向链表存放。查找哈希值为17的key时,先定位到哈希桶,然后链表遍历桶里所有元素,逐个比较其Hash值然后key值。
在JDK8里,新增默认为8的阈值,当一个桶里的Entry超过閥值,就不以单向链表而以红黑树来存放以加快Key的查找速度。
当然,最好还是桶里只有一个元素,不用去比较。所以默认当Entry数量达到桶数量的75%时,哈希冲突已比较严重,就会成倍扩容桶数组,并重新分配所有原来的Entry。扩容成本不低,所以也最好有个预估值。
取模用与操作(hash & (arrayLength-1))会比较快,所以数组的大小永远是2的N次方, 你随便给一个初始值比如17会转为32。默认第一次放入元素时的初始值是16。
iterator()时顺着哈希桶数组来遍历,看起来是个乱序。
LinkedHashMap
参考资料
[Java LinkedHashMap工作原理及实现](https://yikun.github.io/2015/04/02/Java-LinkedHashMap%E5%B7%A5%E4%BD%9C%E5%8E%9F%E7%90%86%E5%8F%8A%E5%AE%9E%E7%8E%B0/) [JDK1.8源码分析之LinkedHashMap(二)](http://www.cnblogs.com/leesf456/p/5248868.html)用法
public class LinkedHashMapTest {
public static void main(String[] args) {
LinkedHashMap lmap = new LinkedHashMap();
lmap.put("语文", 1);
lmap.put("数学", 2);
lmap.put("英语", 3);
lmap.put("历史", 4);
lmap.put("政治", 5);
lmap.put("地理", 6);
lmap.put("生物", 7);
lmap.put("化学", 8);
for(Map.Entry entry : lmap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
// 输出:
// 语文: 1
// 数学: 2
// 英语: 3
// 历史: 4
// 政治: 5
// 地理: 6
// 生物: 7
// 化学: 8
}
} 数据结构
 LinkedHashMap会将元素串起来,形成一个双链表结构。可以看到,其结构在HashMap结构上增加了链表结构。数据结构为(数组 + 单链表 + 红黑树 + 双链表),图中的标号是结点插入的顺序。类的继承
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>类的属性
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> {
static class Entry extends HashMap.Node {
Entry before, after;
Entry(int hash, K key, V value, Node next) {
super(hash, key, value, next);
}
}
// 版本序列号
private static final long serialVersionUID = 3801124242820219131L;
// 链表头结点
transient LinkedHashMap.Entry head;
// 链表尾结点
transient LinkedHashMap.Entry tail;
// 访问顺序
final boolean accessOrder;
} 构造函数
- LinkedHashMap():
/**
* Constructs an empty insertion-ordered LinkedHashMap instance
* with the default initial capacity (16) and load factor (0.75).
*/
public LinkedHashMap() {
super();
accessOrder = false;
}- LinkedHashMap(int initialCapacity):
/**
* Constructs an empty insertion-ordered LinkedHashMap instance
* with the specified initial capacity and a default load factor (0.75).
*
* @param initialCapacity the initial capacity
* @throws IllegalArgumentException if the initial capacity is negative
*/
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}- LinkedHashMap(int initialCapacity, float loadFactor):
/**
* Constructs an empty insertion-ordered LinkedHashMap instance
* with the specified initial capacity and load factor.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}- LinkedHashMap(Map< ? extends K, ? extends V>):
/**
* Constructs an insertion-ordered LinkedHashMap instance with
* the same mappings as the specified map. The LinkedHashMap
* instance is created with a default load factor (0.75) and an initial
* capacity sufficient to hold the mappings in the specified map.
*
* @param m the map whose mappings are to be placed in this map
* @throws NullPointerException if the specified map is null
*/
public LinkedHashMap(Map m) {
super();
accessOrder = false;
putMapEntries(m, false);
}- LinkedHashMap(int initialCapacity,float loadFactor,boolean accessOrder):
/**
* Constructs an empty LinkedHashMap instance with the
* specified initial capacity, load factor and ordering mode.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - true for
* access-order, false for insertion-order
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}核心函数分析
- newNode(int hash, K key, V value, Node
// 当桶中结点类型为HashMap.Node类型时,调用此函数
Node newNode(int hash, K key, V value, Node e) {
// 生成Node结点
LinkedHashMap.Entry p =
new LinkedHashMap.Entry(hash, key, value, e);
// 将该结点插入双链表末尾
linkNodeLast(p);
return p;
} 说明:此函数在HashMap类中也有实现,LinkedHashMap重写了该函数,所以当实际对象为LinkedHashMap,桶中结点类型为Node时,我们调用的是LinkedHashMap的newNode函数,而非HashMap的函数,newNode函数会在调用put函数时被调用。可以看到,除了新建一个结点之外,还把这个结点链接到双链表的末尾了,这个操作维护了插入顺序。
其中LinkedHashMap.Entry继承自HashMap.Node
static class Entry extends HashMap.Node {
// 前后指针
Entry before, after;
Entry(int hash, K key, V value, Node next) {
super(hash, key, value, next);
}
} 说明:在HashMap.Node基础上增加了前后两个指针域,注意,HashMap.Node中的next域也存在。
* newTreeNode(int hash, K key, V value, Node
// 当桶中结点类型为HashMap.TreeNode时,调用此函数
TreeNode newTreeNode(int hash, K key, V value, Node next) {
// 生成TreeNode结点
TreeNode p = new TreeNode(hash, key, value, next);
// 将该结点插入双链表末尾
linkNodeLast(p);
return p;
} 说明:当桶中结点类型为TreeNode时候,插入结点时调用的此函数,也会链接到末尾。
- afterNodeAccess(Node< K,V> e):
void afterNodeAccess(Node e) { // move node to last
LinkedHashMap.Entry last;
// 若访问顺序为true,且访问的对象不是尾结点
if (accessOrder && (last = tail) != e) {
// 向下转型,记录p的前后结点
LinkedHashMap.Entry p =
(LinkedHashMap.Entry)e, b = p.before, a = p.after;
// p的后结点为空
p.after = null;
// 如果p的前结点为空
if (b == null)
// a为头结点
head = a;
else // p的前结点不为空
// b的后结点为a
b.after = a;
// p的后结点不为空
if (a != null)
// a的前结点为b
a.before = b;
else // p的后结点为空
// 后结点为最后一个结点
last = b;
// 若最后一个结点为空
if (last == null)
// 头结点为p
head = p;
else { // p链入最后一个结点后面
p.before = last;
last.after = p;
}
// 尾结点为p
tail = p;
// 增加结构性修改数量
++modCount;
}
} 说明:此函数在很多函数(如put)中都会被回调,LinkedHashMap重写了HashMap中的此函数。若访问顺序为true,且访问的对象不是尾结点,则下面的图展示了访问前和访问后的状态,假设访问的结点为结点3

说明:从图中可以看到,结点3链接到了尾结点后面。
- transferLinks(LinkedHashMap.Entry< K,V> src, LinkedHashMap.Entry< K,V> dst):
// 用dst替换src
private void transferLinks(LinkedHashMap.Entry src,
LinkedHashMap.Entry dst) {
LinkedHashMap.Entry b = dst.before = src.before;
LinkedHashMap.Entry a = dst.after = src.after;
if (b == null)
head = dst;
else
b.after = dst;
if (a == null)
tail = dst;
else
a.before = dst;
} 此函数用dst结点替换结点,示意图如下

其中只考虑了before与after域,并没有考虑next域,next会在调用tranferLinks函数中进行设定。
- containsValue(Object value):
public boolean containsValue(Object value) {
// 使用双链表结构进行遍历查找
for (LinkedHashMap.Entry e = head; e != null; e = e.after) {
V v = e.value;
if (v == value || (value != null && value.equals(v)))
return true;
}
return false;
} containsValue函数根据双链表结构来查找是否包含value,是按照插入顺序进行查找的,与HashMap中的此函数查找方式不同,HashMap是使用按照桶遍历,没有考虑插入顺序。
总结
IdentityHashMap
参考资料
JDK1.8源码分析之IdentityHashMap(四)
用法介绍
public class IdentityHashMapTest {
public static void main(String[] args) {
Map hashMap = new HashMap<>();
Map identityMap = new IdentityHashMap<>();
hashMap.put(new String("a"), 1);
hashMap.put(new String("a"), 2);
identityMap.put(new String("b"), 1);
identityMap.put(new String("b"), 2);
// IdentityHashMap只有在键的引用相同是才会覆盖
for (Map.Entry entry : hashMap.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}
// a:2
for (Map.Entry entry : identityMap.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}
// b:2
// b:1
}
}
IdentityHashMap只有在key完全相等(同一个引用),才会覆盖,而HashMap则不会。
数据结构
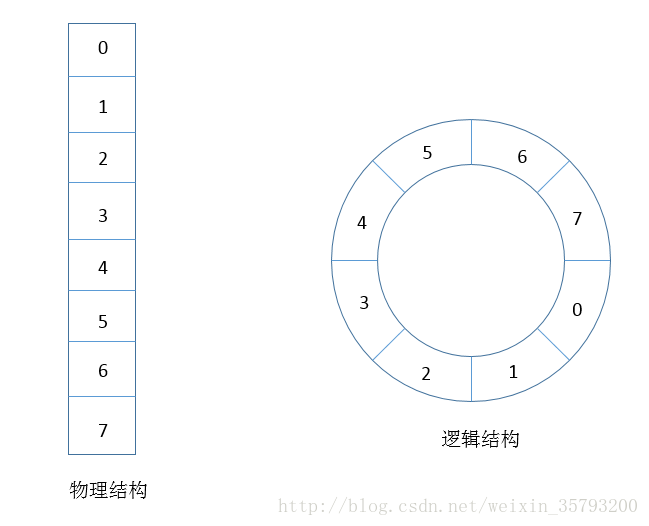
IdentityHashMap的数据很简单,底层实际就是一个Object数组,在逻辑上需要看成是一个环形的数组,解决冲突的办法是:根据计算得到散列位置,如果发现该位置上已经有元素,则往后查找,直到找到空位置,进行存放,如果没有,直接进行存放。当元素个数达到一定阈值时,Object数组会自动进行扩容处理。
类的继承关系
public class IdentityHashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, java.io.Serializable, Cloneable由类的定义可知,IdentityHashMap继承自AbstractMap,可以序列化,可以实现克隆。
类的属性
public class IdentityHashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, java.io.Serializable, Cloneable
{
// 缺省容量大小
private static final int DEFAULT_CAPACITY = 32;
// 最小容量
private static final int MINIMUM_CAPACITY = 4;
// 最大容量
private static final int MAXIMUM_CAPACITY = 1 << 29;
// 用于存储实际元素的表
transient Object[] table;
// 大小
int size;
// 对Map进行结构性修改的次数
transient int modCount;
// null key所对应的值
static final Object NULL_KEY = new Object();
}可以看到类的底层就是使用了一个Object数组来存放元素。
构造函数
- IdentityHashMap():
/**
* Constructs a new, empty identity hash map with a default expected
* maximum size (21).
*/
public IdentityHashMap() {
init(DEFAULT_CAPACITY);
}- IdentityHashMap(int expectedMaxSize):
/**
* Constructs a new, empty map with the specified expected maximum size.
* Putting more than the expected number of key-value mappings into
* the map may cause the internal data structure to grow, which may be
* somewhat time-consuming.
*
* @param expectedMaxSize the expected maximum size of the map
* @throws IllegalArgumentException if expectedMaxSize is negative
*/
public IdentityHashMap(int expectedMaxSize) {
if (expectedMaxSize < 0)
throw new IllegalArgumentException("expectedMaxSize is negative: "
+ expectedMaxSize);
init(capacity(expectedMaxSize));
}- IdentityHashMap(Map< ? extends K, ? extends V> m):
/**
* Constructs a new identity hash map containing the keys-value mappings
* in the specified map.
*
* @param m the map whose mappings are to be placed into this map
* @throws NullPointerException if the specified map is null
*/
public IdentityHashMap(Map m) {
// Allow for a bit of growth
this((int) ((1 + m.size()) * 1.1));
putAll(m);
}核心函数分析
- capacity(int expectedMaxSize):
- hash(Object x, int length):
- get(Object key):
- nextKeyIndex(int i, int len):
- put(K key, V value):
- resize(int newCapacity):
- remove(Object key):
- closeDeletion(int d):
总结
IdentityHashMap与HashMap在数据结构上很不相同,并且处理hash冲突的方法也不相同。其中,IdentityHashMap只有当key为同一个引用时才认为是相同的,而HashMap还包括equals相等,即内容相同。