数据结构-用C语言描述耿国华版总结笔记(下篇)
第六章 树与二叉树
(一)二叉树
1.1树相关术语:
度(一个结点的子树个数);结点的层次(从该结点开始往下有多少层);树的度(树中所有结点的度的最大值);树的高度(树中所有结点的层次的最大值)。
1.2二叉树的性质:
1.二叉树的第i层上最多有2^(i-1)个结点;
2.深度为k的二叉树最多有2^k-1个结点;
3.当任意一颗二叉树T,若终端结点数为n0,而其度为2的结点为n2,则n0 = n2+1;证明:n=n0+n1+n2=B+1=n1+2n2;则n0=n2+1;(n为结点总数,B为二叉树分支数目)
4.对具有n个结点的完全二叉树的深度是log2n+1;
5.若为完全二叉树:任意序号为i的结点,从1开始编号。(1)若i=1,则序号为i的结点是根结点;若i>1;则序号为i的结点的双亲结点序号为[i/2]向下取整。(2)若2i>n,则无左孩子,若n>=2i,则有左孩子,右孩子+1即可。
1.3二叉树的存储结构
1.顺序存储,将二叉树部位完全二叉树,从左向右存储每一个结点,用性质5计算结点之间关系;
2.链式存储:用二叉链表来表示,n个结点二叉树,含有2n个指针域,共有n+1个空域,n-1个分支。(自己拿只有三个结点的二叉树举例即可)
1.4二叉树的常见操作:
1.先序遍历(根左右)、中序遍历(左根右)、后序遍历(左右根)
2.按树状打印二叉树,实现二叉树的横向显示问题:将该树向左旋转90度,逆中序(RDL)打印。
3.二叉树的线索化(感觉没啥用):中序找前驱:跟着线索树方向亦或是找左子树最右下端的顶点。
4.先序+中序亦或是后序+中序可唯一确定二叉树(先序+后序不可以)
5.二叉树的层次遍历。
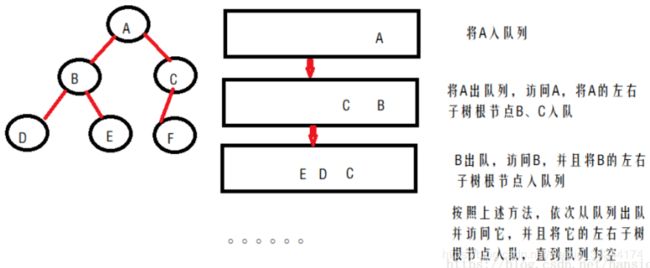
(二)树、森林与二叉树的关系
1.存储结构:
双亲表示法(每个结点是Data+Parent的结点结构)、孩子表示法(每个结点是Data+Child的格式)、孩子兄弟表示法(两个链域,分别指向该结点的第一个孩子结点和自己的下一个兄弟结点)
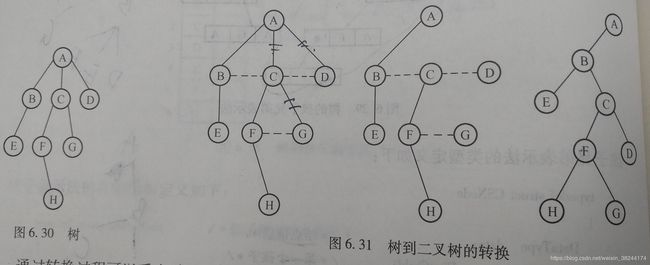
2.树转换为二叉树
(1)树的所有相邻兄弟结点之间加一个连线;
(2)对树中的每一个结点,只保留其与第一个孩子结点之间的连线,删去与其他孩子节点之间的连线;
(3)以树的根节点为轴心,将整个树以顺时针旋转一定角度,使之结构层次分明。
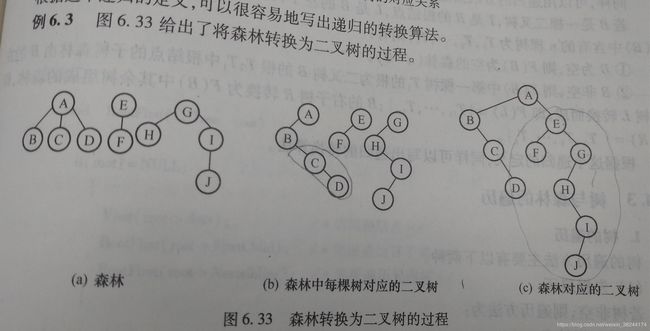
3.森林转换为二叉树
(1)每棵树按照如上要求转换为二叉树;
(2)第一棵二叉树不动,从第二棵二叉树开始,依次把后一棵二叉树的根节点作为前一棵二叉树根节点的右孩子。
4.二叉树还原为树或者森林
(1)若某结点是双亲的左孩子,则把该节点的右孩子、右孩子的右孩子都与该结点的双亲结点连接起来。
(2)删掉原二叉树中所有双亲结点与右孩子结点的连线。
(3)整理(1)(2)得到的树或者森林,使之层次分明。
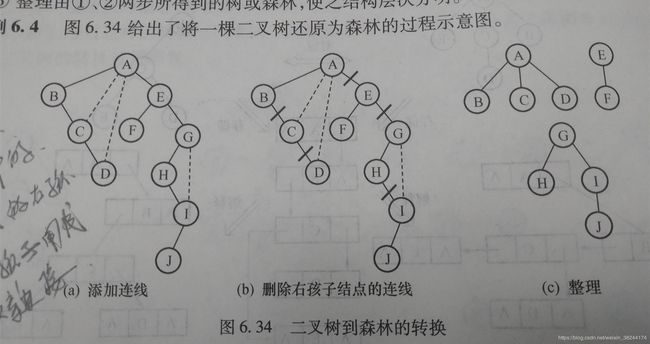
5.树/森林的遍历
树的先序遍历:根左右;树的后序遍历:左右根。树的遍历结果同由树转换而得的二叉树的对应关系如下:树的先根遍历等价于转换后二叉树的前序遍历;树的后根遍历等同于转换后二叉树的中序遍历。
森林的遍历:和树的差不多。
6.哈夫曼树及其应用(带权路径长度最小的二叉树)
(1)基础概念:
路径长度:一结点到另一结点所经历过得分支数目;
树的带权路径长度:从树根到所有结点的各个带权路径长度的总和。WPL = wi*li(i从1到n),wi为叶子的权值,li为第i个节点的路径长度。
(2)哈夫曼树的实现步骤(步骤及实现)
1.初始化:给定n个权值,构造由单棵树组成的森林。
2.找最小树:在森林中选两棵权值最小的二叉树,作为新一棵二叉树的左右子树,标记新二叉树的根节点权值为左右子树的权值之和;
3.删除和加入:从森林中删除被选中的二叉树,同时将其放入森林中;
4.判断:重复步骤2、3,直至只有一棵树为止。
(3)使用哈夫曼树构造哈夫曼编码
数据压缩技术:为了缩短数据文件长度,可以采用不定长编码。基本思想是使用频度较高的字符编以较短的编码。
前缀编码:在编码系统中,任一编码都不是其他任何编码的前缀(最左子串),则称该编码系统的编码是前缀编码。譬如:一组编码01,001,010,110,100不是前缀编码。因为01是010的前缀。若去掉两者中一个便是。
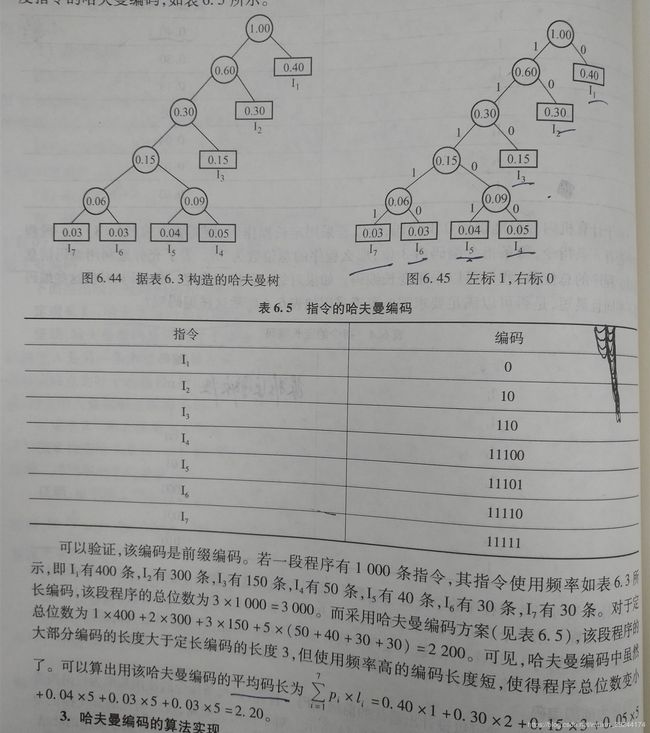
哈夫曼编码:对一棵具有n个叶子的哈夫曼树,若对树中每个左分支赋1,右分支赋0.则由此得到的分支的赋值分别构成一个二进制串。该串被称为哈夫曼编码。
举例:假设:一台模型机,有七种指令,其使用频率分别是:0.4、0.3、0.15、0.05、0.04、0.03、0.03.则其前缀编码是多少。
(三)满、完全二叉树、堆以及二叉查找树
1.满二叉树
深度为k且有2^k-1个节点的二叉树,每层结点都是满的;或者说:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。
2.完全二叉树
如果其结点1-n的位置序号分别与满二叉树的1-n个位置一一对应,则它是完全二叉树。参考:https://baike.baidu.com/item/完全二叉树
2.1特点:
(1)所有的叶结点都出现在第k层或k-l层(层次最大的两层);对任一结点,如果其右子树的最大层次为L,则其左子树的最大层次为L或L+l。
(2)对于一颗完全二叉树,n0=n/2,其中n为奇数时(n1=0)向上取整;n为偶数时(n1=1)。可根据完全二叉树的结点总数计算出叶子结点数。(n0为叶子节点为0的结点总数,n为所有叶子节点总数)
2.2判断一棵树是二叉查找树的思路:
1>如果树为空,则直接返回错
2>如果树不为空:层序遍历二叉树
2.1>如果一个结点左右孩子都不为空,则pop该节点,将其左右孩子入队列;
2.1>如果遇到一个结点,左孩子为空,右孩子不为空,则该树一定不是完全二叉树;
2.2>如果遇到一个结点,左孩子不为空,右孩子为空;或者左右孩子都为空;则该节点之后的队列中的结点都为叶子节点;该树才是完全二叉树,否则就不是完全二叉树
3.堆
堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆。左为最大堆、右为最小堆。
添加新节点,删除新节点之后的重建堆参见我的博客(多记录真是有好处滴):https://blog.csdn.net/weixin_38244174/article/details/88552709
4.二叉查找树(BST)
4.1二叉查找树的特点:
1.若任意节点的左子树不空,则左子树上所有结点的值均小于或等于它的根结点的值;
2.若任意节点的右子树不空,则右子树上所有结点的值均大于或等于它的根结点的值;
3.任意节点的左、右子树也分别为二叉查找树。
4.2在二叉查找树中查找/添加/删除元素:
查找有递归实现和迭代实现两种,相对都比较简单。但添加和删除略难一些。
参考:http://www.cnblogs.com/yangecnu/p/Introduce-Binary-Search-Tree.html
(四)平衡二叉树(选读)
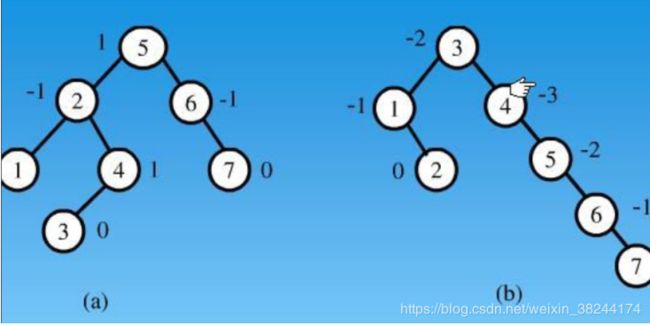
AVL树本质还是一棵二叉查找树,只是在其基础上增加了“平衡”的要求。它是一棵空树或它的左右两个子树(左子树-右子树)的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。常用实现方法有红黑树、AVL、替罪羊树、Treap、伸展树等。(a)是平衡二叉书,(b)是不平衡二叉树。AVL的高度就始终能保持O(logn)级别。
第七章 树与二叉树
(一)相关定义
1.有向图:边有方向;无向图:边无方向;有向完全图:有n*(n-1)条边的有向图;无向完全图:有n*(n-1)/2条边的图。
2.入度:以顶点v为弧头(终端点)的弧的数目称为该点的入度;出度:以顶点v为弧尾(起始点)的弧的数目称为该点的出度。
3.简单路径:若表示路径的顶点序列中的顶点各不相同;简单回路:除了第一个和最后一个节点外,其余顶点均不重复出现的回路。
4.连通图:仅需要调用一次,搜索过程中从任意一点出发,即可遍历无向图中各个顶点。连通分量:无向图中的极大连通子图;若对有向图中每一个节点,从vi到vj和从vj到vi都存在路径,被称为强连通图。有向图的极大强连通图被称为有向图的强连通分量。
(二)图的存储结构:
1.邻接矩阵:
适合稠密图,存储图中顶点之间关联关系的二维数组。这个关联关系数组被称为邻接矩阵。特点:(1)存储空间:有向图需要n(n-1)/2个存储空间;无向图需要n^2个存储空间。(2)便于计算:有向图而言,第i行元素之和就是第i个顶点的出度。第i列元素之和就是第i个顶点的入度。
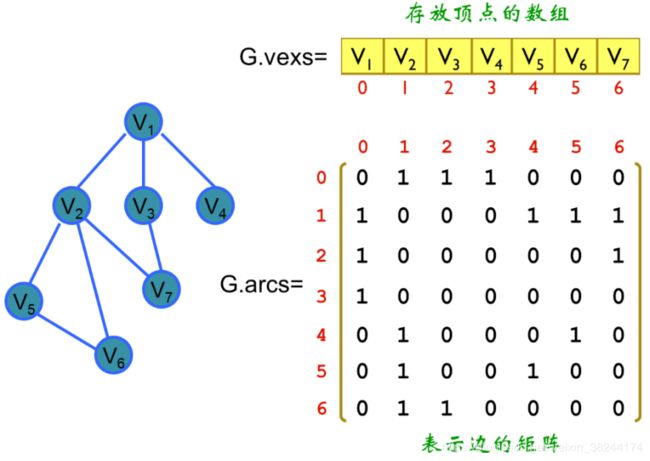
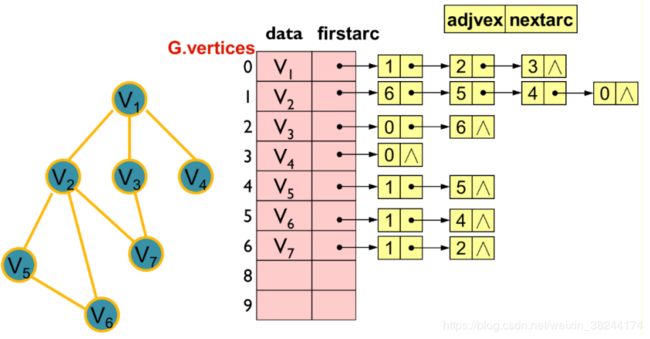
2.邻接表:
适合稀疏图,只存储相关联的信息,对于图中存在的边信息进行存储,而不相邻的节点则不保留信息。空间复杂度为O(n+e)。
(三)图的遍历
1.深度优先搜索遍历
使用递归+堆栈即可实现。
2.广度优先遍历
使用队列技术实现即可。这部分代码及示例图可参照我之前的博客:
https://blog.csdn.net/weixin_38244174/article/details/88814946
(四)图的应用
1.图的连通性问题:
1.1.无向图的连通分量:对图进行遍历时,对于连通图,则无论深度搜索或广度搜索,仅需要调用一次搜索过程,即从任一顶点出发,便可遍历图中的所有顶点;对于非连通图,需要多次调用搜索过程,而每次得到的顶点访问序列恰为个连通分量的定点集。
1.2.图中两个顶点之间的简单路径:从顶点u到另一个顶点v的简单路径即为路径中的顶点各不相同。深度/广度即可,做好是否访问的标记即可。
1.3.生成树
连通图的极小连通子图,含有n个顶点和n-1条边,假设在生成树上加上一条边,则构成环。换而言之:一棵n个顶点的生成树必有且仅有n-1条边。
1.4最小生成树
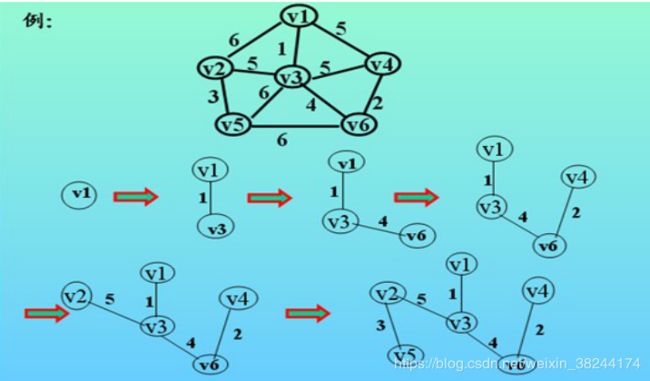
1.4.1 普利姆算法(“加点法”)
N=(v,{E})是连通图,TE是最小生成树边的集合。(1)初始u={u0},TE=空;(2)在集合所有的边中选择代价最小的边(u0,v0)并入集合TE,并将v0并入u;(3)重复(2),直到u=v为止。
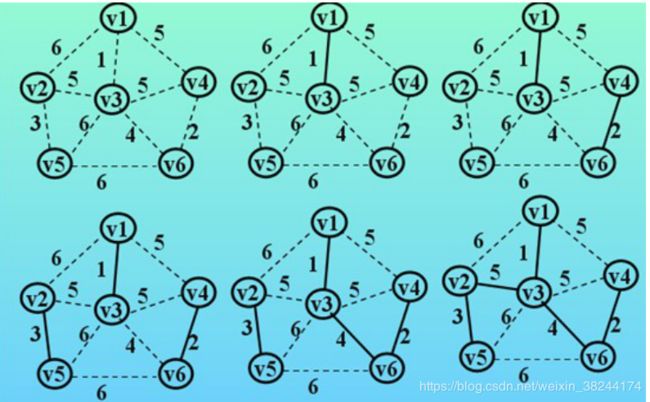
1.4.2 克鲁斯卡尔算法(“加边法”)
新建图G,G中拥有原图中相同的节点,但没有边;将原图中所有的边按权值从小到大排序;从权值最小的边开始,如果这条边连接的两个节点于图G中不在同一个连通分量中,则添加这条边到图G中;重复3,直至图G中所有的节点都在同一个连通分量中。
2.有向无环图的应用:
2.1拓扑排序(AOV网)
2.1.1定义(顶点表示活动,边表示活动间先后关系)
对一个有向无环图G进行拓扑排序,是将G中所有顶点排成一个线性序列,使得图中任意一对顶点u和v,若边(u,v)∈E(G),则u在线性序列中出现在v之前。通常,这样的线性序列称为满足拓扑次序的序列,简称拓扑序列。简单的说,由某个集合上的一个偏序得到该集合上的一个全序,这个操作称之为拓扑排序。通常,我们把这种顶点表示活动、边表示活动间先后关系的有向图称做顶点活动网(Activity On Vertex network),简称AOV网。
2.1.2如何操作
针对基于邻接矩阵的图而言。(1)找到G中无前驱的结点,(在邻接矩阵A中找到值全为零的列,即无入度);(2)删除以i为起点的所有弧。(将矩阵i对应的列置零)
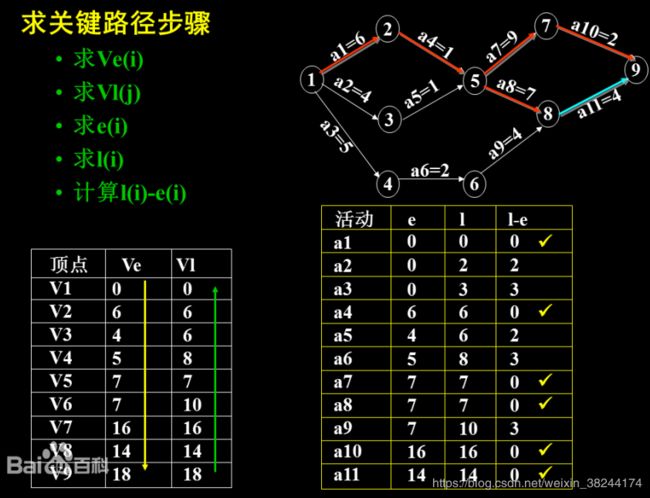
2.2关键路径
1.相关定义:
(1)AOE网(顶点表示事件,弧权表示所用时间)
用顶点表示事件,弧表示活动,弧上的权值表示活动持续的时间的有向图叫AOE(Activity On Edge Network)网。在建筑学中也称为关键路线。AOE网常用于估算工程完成时间。例如:图1 是一个网。其中有9个事件v1,v2,…,v9;11项活动a1,a2,…,a11。每个事件表示在它之前的活动已经完成,在它之后的活动可以开始。如 v1表示整个工程开始,v9 表示整个工程结束。V5表示活动a2和a3已经完成,活动a7和a8可以开始。与每个活动相联系的权表示完成该活动所需的时间。如活动a1需要6个时间单位可以完成。
一个AOE网的关键路径可以不止一条。
只有在某顶点所代表的事件发生后,从该顶点出发的各有向边所代表的活动才能开始。只有在进入某一顶点的各有向边所代表的活动都已经结束,该顶点所代表的事件才能发生。表示实际工程计划的AOE网应该是无环的,并且存在唯一的入度为0的开始顶点和唯一的出度为0的完成顶点。
(2) 时间开始的最早发生时间ve(i):从源点到顶点vi的最长的路径的长度。称为时间vi的最早发生时间。
(3) 事件开始的最晚时间vl(i):再保证汇点按其最早发生时间这一前提下,求时间vi的最晚发生时间,按照逆拓扑顺序进行计算。
(4) 活动开始的最早时间e(i):假设活动ai所对应的弧是
(5) 活动开始的最晚时间l(i) 定义e(i)=l(i)的活动叫关键活动;
2.如何求拓扑排序:
(1)对图中顶点进行拓扑排序,排序过程中计算出每个事件的最早发生时间ve(i);
(2)按逆拓扑序列求每个事件的最晚发生时间vl(i);
(3)求出每个活动ai的最早开始时间e(i)和最晚发生时间l(i);
(4)找出e(i)=l(i)的活动ai,即为关键活动。
第八章 查找
(一)基本概念
平均查找长度:对于含有n个数据元素的查找表,查找成功的平均查找长度为:ASL=∑PiCi (i=1,2,3,…,n),可以简单以数学上的期望来这么理解。其中:Pi 为查找表中第i个数据元素的概率,Ci为找到第i个数据元素时已经比较过的次数。
(二)基于线性表的查找法:
2.1顺序查找法
算法步骤:
用所给关键字与线性表中个元素的关键字逐个比较,直到成功或失败。平均查找长度为(n+1)/2。
2.2折半查找法
折半查找特点:
对线性表有两个要求:(1)必须采用顺序存储结构;(2)关键字大小有序排列。也可适用于二叉查找树。平均查找长度约为log2(n+1)-1。
算法步骤:
(1)首先确定整个查找区间的中间位置 mid = ( left + right )/2 。
(2)用待查关键字值与中间位置的关键字值进行比较;若相等,则查找成功;若大于,则在后(右)半个区域继续进行折半查找;若小于,则在前(左)半个区域继续进行折半查找。
(3)对确定的缩小区域再按折半公式,重复上述步骤。最后,得到结果:要么查找成功, 要么查找失败。折半查找的存储结构采用一维数组存放。
代码示例:
public int binarySearch(int[] arr, int findElem) {
int low = 0;
int high = arr.length - 1;
int mid;
while (low <= high) {
mid = (low + high) / 2;
if (findElem < arr[mid]) {
high = mid - 1;
}
if (findElem > arr[mid]) {
low = mid + 1;
}
if (arr[mid] == findElem) {
return mid;
}
}
return -1;
}2.3分块查找法
分块查找特点:
折半查找和顺序查找的一种改进方法,分块查找由于只要求索引表是有序的,对块内节点没有排序要求,即块内无序、块间有序,因此特别适合于节点动态变化的情况。
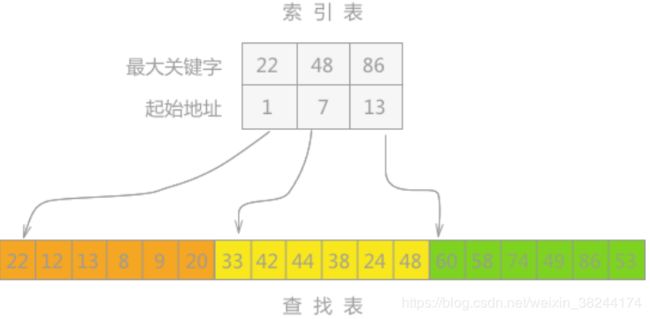
算法步骤:
step1.构造一个索引表,记录每块开始位置及各块中的最大关键字,索引表按关键字有序排列。
step2.查找分两个部分:先对索引表进行二分查找或顺序查找,以确定待查记录在哪一块中;然后,在已确定的块中用顺序法进行查找。
适用范围:
例如,学校有很多个班级,每个班级有几十个学生。给定一个学生的学号,要求查找这个学生的相关资料。显然,每个班级的学生档案是分开存放的,没有任何两个班级的学生的学号是交叉重叠的,那么最好的查找方法实现确定这个学生所在的班级,然后再在这个学生所在班级的学生档案中查找这个学生的资料。(三)基于树的查找法
3.1二叉排序树
二叉排序树特点:
要么空树,要么满足以下性质:左子树所有节点值小于根节点的值;右子树大于等于根节点;它的左右也满足上述的两条性质。
二叉树的常见操作:
插入与创建、查找、删除(删除节点为p的话有下面几种情况:(1)若p为叶节点,直接删除;(2)若p只有左子树或右子树,则直接将其改为双亲结点的左/右子树;(3)找到中序序列的直接前驱s,将p的左子树改为双亲结点的左子树,将p的右子树改为s的右子树)
3.2平衡二叉排序树
平衡二叉排序树特点:
左右子树高度之差的绝对值小于等于1;左右子树也是平衡二叉排序树。
失衡情况和调整方法: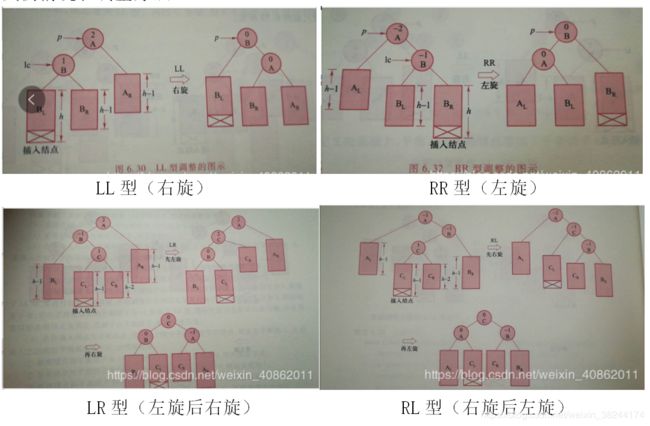
(四)计算式查找法-哈希法
哈希法基本思想:
是根据关键码值key value而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希表,函数f(key)为哈希函数。
哈希函数构造方法:
原则:函数本身便于计算;计算出来的地址分布均匀。
1.数字分析法;2.平方取中法;3.分段叠加法;4.除留取余法;5.伪随机数法等。
处理冲突的方法:
1.开放定址法:Hi=(H(key) + di) MOD m,i=1,2,…,k(k<=m-1),其中H(key)为散列函数,m为散列表长,di为增量序列,(1)线性探测再散列:di=1,2,3,…,m-1(2)二次探测再散列:di=1^2,-1^2,2^2,-2^2;(3)伪随机探测再散列:di=伪随机数序列。
2.再哈希法:Hi=RHi(key),i=1,2,…,k RHi均是不同的散列函数。若冲突,则计算。不易产生“聚集”,但增加了计算时间。
3.链地址法。
4.建立一个公共溢出区。
哈希法影响比较次数的因素:
1.哈希函数;2.处理冲突的方法;3.哈希表的装填因子α(哈希表元素个数/哈希表长度)。
构造哈希表举例:
给出一组元素,它们的关键码为:37,25,14,36,49,68,57,11,散列表为HT[12],表的大小 m=12 ,假设采用Hash(key)= key % p ;(p=11)11是最接近m的质数,此为哈希函数的取值个数。就有:
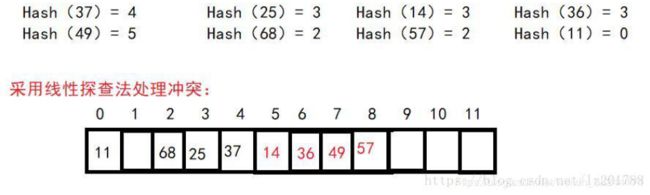
ASLsucc =1/表中置入元素个数n*(C0+C1+..+Cn)=(1*5+3+4+7)/8 = 2.375.其中,Ci为比较次数。
ASLunsucc =1/哈希函数取值个数r*(C0+C1+..+Cr-1)=1/11*(2+1+8+7+6+5+4+3+2+1+1)=3.64
第九章 排序
参考我之前的帖子,这里做简单说明:
https://blog.csdn.net/weixin_38244174/article/details/88763260
(1)基础概念:
1.内部排序/外部排序:排序过程完全在内存中进行/数据量太大,内存无法容纳全部数据,排序需要借用外存。
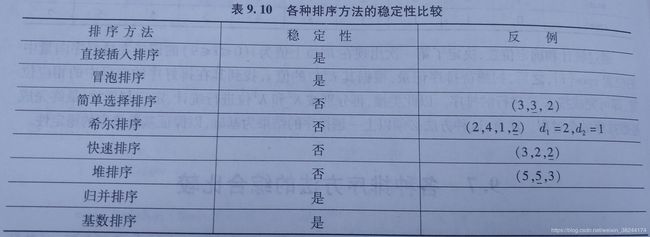
2.排序稳定性:在排序过程中,相同关键字(ki=kj,i
1.直接插入:
当插入第i(i>=1)个元素时,前面的V[0],…,V[i-1]等i-1个 元素已经有序。这时,将第i个元素与前i-1个元素V[i-1],…,V[0]依次比较,找到插入位置即将V[i]插入,同时原来位置上的元素向后顺移。在这里,插入位置的查找是顺序查找。
2.折半插入:
先折半查找,再统一往后挪一位。
3.希尔排序:
设待排序元素序列有n个元素,首先取一个整数increment(小于n)作为间隔将全部元素分为increment个子序列,所有距离为increment的元素放在同一个子序列中,在每一个子序列中分别实行直接插入排序。然后缩小间隔increment,重复上述子序列划分和排序工作。直到最后取increment=1,将所有元素放在同一个子序列中排序为止。
那么增量该如何取?一般的初次取序列的一半为增量,以后每次减半,直到增量为1。
(3)交换类排序:
1.冒泡排序:
(1)比较相邻的元素。如果第一个比第二个大,就交换他们两个。
(2)对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
(3)针对所有的元素重复以上的步骤,除了最后一个。
(4)持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
2.快速排序:
设要排序的数组是A[0]……A[N-1],首先任意选取一个数据(通常选用数组的第一个数)作为关键数据,然后将所有比它小的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一趟快速排序。值得注意的是,快速排序不是一种稳定的排序算法,也就是说,多个相同的值的相对位置也许会在算法结束时产生变动。 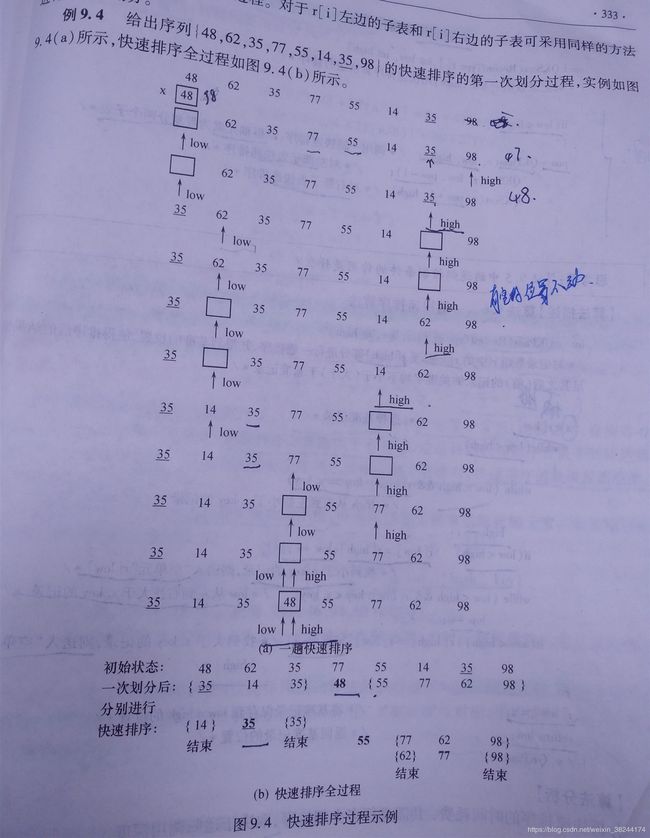
(4)选择类排序:
1.简单选择排序:
每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到全部待排序的数据元素排完。
2.堆排序:
参考链接:https://blog.csdn.net/weixin_38244174/article/details/88552709
将堆顶元素与堆尾元素交换后,进行排序,去掉堆顶最大元素,重复n步,得到排序。
(5)归并排序:
有序二元组两两归并,基于合并,将两个或两个以上的有序表合成一个新的有序表。
(6)总结:
希快简堆不稳定。