场景
`假设有这样一个使用场景,依次执行下面的5条命令
命令1:hset mall:sale:freq:ctrl:860000000000001 599055114591 1(hash结构,field表示购买的商品ID,value表示购买次数)
简单说明: mall:sale:freq:ctrl:860000000000001是一个hash表;599055114591表示key;1表示key对应的value
命令2:hset mall:sale:freq:ctrl:860000000000001 599055114592 2
命令3:expire mall:sale:freq:ctrl:860000000000001 3127(设置过期时间)
简单说明:给hash表mall:mall:sale:freq:ctrl:860000000000001设置过期时间
命令4:set mall:total:freq:ctrl:860000000000001 3
简单说明:set key vlaue
命令5:expire mall:total:freq:ctrl:860000000000001 3127(设置过期时间)
简单说明: set key 过期时间`
优化缘由
执行一条命令 经历的过程
- 发送命令网络传输时间
- 命令在Redis服务端队列中等待的时间
- 命令执行的时间(Redis中的slowlog只是检测这一步骤的时间)
- 结果返回的Redis客户端的时间

`执行一条命令 就需要经过上面的过程,发送命令-〉命令排队-〉命令执行-〉返回结果
那么执行5条命令,可想而知,性能优化的空间还是蛮大的,
下面咱们来进行优化一下吧`
优化
第一次优化:利用hmset命令将两条hmset命令合二为一
`命令1和命令2 合二为一
hmset mall:sale:freq:ctrl:860000000000001 599055114591 1 599055114592 2
expire mall:sale:freq:ctrl:860000000000001 3127
set mall:total:freq:ctrl:860000000000001 3
expire mall:total:freq:ctrl:860000000000001 3127`
第二次优化:将set和expire命令合二为一
`将命令4和命令5合二为一
命令a: hmset mall:sale:freq:ctrl:860000000000001 599055114591 1 599055114592 2
命令b: expire mall:sale:freq:ctrl:860000000000001 3127
命令c: setex mall:total:freq:ctrl:860000000000001 3127 3`
第三次优化:使用pipeline
需要注意:RedisCluster中使用pipeline时必须满足pipeline打包的所有命令key在RedisCluster的同一个slot上
分析下是否在同一个slot上
slot原理简介
`Redis 集群使用数据分片(sharding)而非一致性哈希(consistency hashing)来实现: 一个 Redis 集群包含 16384 个哈希槽(hash slot), 数据库中的每个键都属于这 16384 个哈希槽的其中一个, 集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽, 其中 CRC16(key) 语句用于计算键 key 的 CRC16 校验和 。
集群中的每个节点负责处理一部分哈希槽。
举个例子, 一个集群可以有三个哈希槽, 其中:
节点 A 负责处理 0 号至 5500 号哈希槽。
节点 B 负责处理 5501 号至 11000 号哈希槽。
节点 C 负责处理 11001 号至 16384 号哈希槽。
这种将哈希槽分布到不同节点的做法使得用户可以很容易地向集群中添加或者删除节点。 比如说:
如果用户将新节点 D 添加到集群中, 那么集群只需要将节点 A 、B 、 C 中的某些槽移动到节点 D 就可以了。
与此类似, 如果用户要从集群中移除节点 A , 那么集群只需要将节点 A 中的所有哈希槽移动到节点 B 和节点 C , 然后再移除空白(不包含任何哈希槽)的节点 A 就可以了。
因为将一个哈希槽从一个节点移动到另一个节点不会造成节点阻塞, 所以无论是添加新节点还是移除已存在节点, 又或者改变某个节点包含的哈希槽数量, 都不会造成集群下线。`
结论
`由此可知 命令a和命令b在同一个slot上,命令c在另外一个slot上
所以命令a和命令b用pipline来处理`
如何使用pipline
- 先创建一个txt文件
`vim pipeline.txt
hmset mall:sale:freq:ctrl:860000000000001 599055114591 1 599055114592 2
expire mall:sale:freq:ctrl:860000000000001 3127`
- 格式化 使得 这个文本文件中每一行都必须以\r\n而不是\n结束
需要安装下dos2unix
a、brew install dos2unix

b、unix2dos pipeline.txt
- 命令执行
cat pipeline.txt | redis-cli --pipe

第四次优化 使用 高级特性:hashtag
由 CRC16(key) % 16384 来计算键 key 属于哪个槽 可知,key决定了存储在哪个slot上,那么使用hashtag可以使得 满足部分key一致的所有key都存储在同一个slot上
比如
mall:sale:freq:ctrl:{860000000000001} 只要key中有{860000000000001}这一部分,就一定落在同一个slot上
**注意:使用hashtag特性 不能把key的离散性变得非常差 **
- 离散性好
mall:sale:freq:ctrl:{860000000000001} 这种key还是与用户相关
- 离散性差
`mall:{sale:freq:ctrl}:860000000000001
所有的key都会落在同一个slot上,导致整个Redis集群出现严重的倾斜问题`
经过这4次优化 perfect ==> 5条Redis命令压缩到3条Redis命令,并且3条Redis命令只需要发送一次,并且结果也一次就能全部返回
pipline
- 未使用pipline
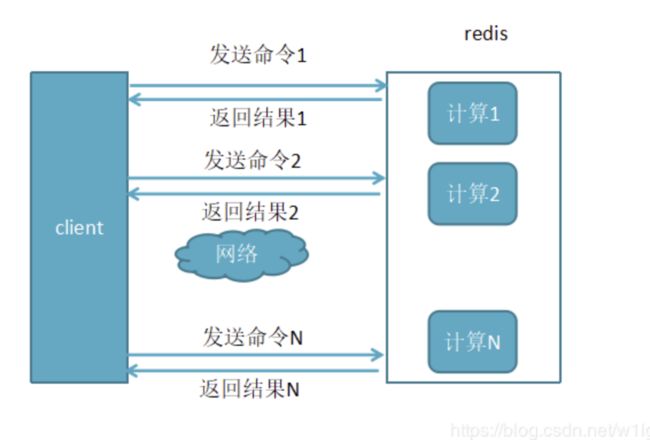
- 使用了pipline

- 性能对比
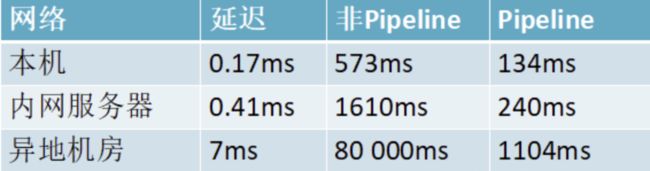
这是一组统计数据出来的数据,使用Pipeline执行速度比逐条执行要快,特别是客户端与服务端的网络延迟越大,性能体能越明显
性能测试代码

pipeline 实现 mdel
redis提供了mset、mget方法 但没有提供mdel方法 可以借助pipeline实现

将不同类型的操作命令合并提交
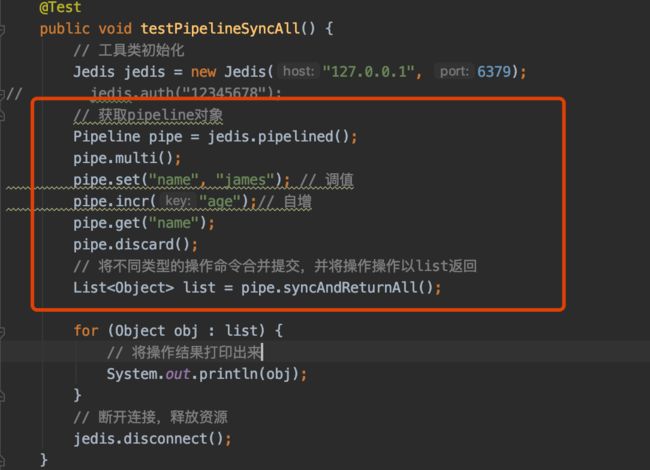
原生批命令(mset, mget)与Pipeline对比
- 原生批命令是原子性,pipeline是非原子性
(原子性概念:一个事务是一个不可分割的最小工作单位,要么都成功要么都失败。原子操作是指你的一个业务逻辑必须是不可拆分的. 处理一件事情要么都成功,要么都失败,原子不可拆分)
- 原生批命令一命令多个key, 但pipeline支持多命令(存在事务),非原子性
- 原生批命令是服务端实现,而pipeline需要服务端与客户端共同完成
使用pipeline组装的命令个数不能太多,不然数据量过大,增加客户端的等待时间,还可能造成网络阻塞,可以将大量命令的拆分多个小的pipeline命令完成
事务
- redsi事务
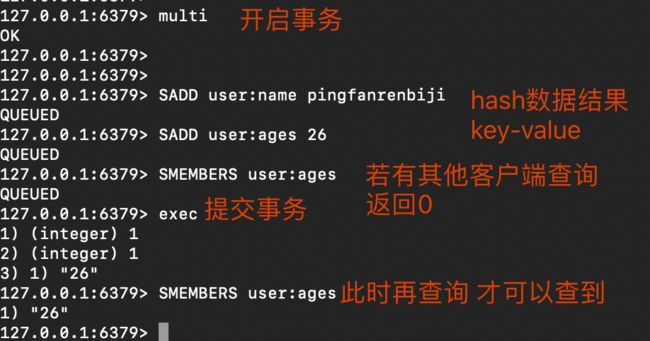
- discard事务
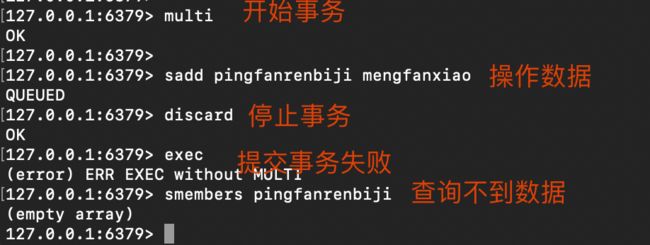
- 命令错误,语法不正确,导致事务不能正常结束
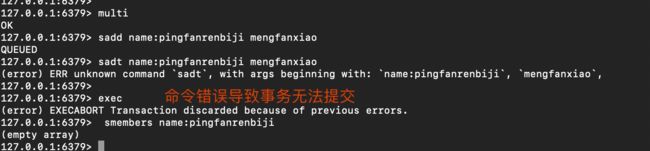
- 运行错误,语法正确,但类型错误,事务可以正常结束

- watch命令
`使用watch后, multi失效,事务失效
WATCH的机制是:
在事务EXEC命令执行时,Redis会检查被WATCH的key,
只有被WATCH的key从WATCH起始时至今没有发生过变更,EXEC才会被执行。
如果WATCH的key在WATCH命令到EXEC命令之间发生过变化,则EXEC命令会返回失败。`
源码地址
https://gitee.com/pingfanrenbiji/springboot-jedisCluster/blob/master/demo/src/main/java/com/example/pipline/PipelineTest.java
参考文档
`https://www.jianshu.com/p/884...
http://www.gxlcms.com/redis-3...
https://blog.csdn.net/huangba...
https://blog.csdn.net/w1lgy/a...
官方文档 :
http://redisdoc.com/topic/clu...`
本文使用 mdnice 排版