最小生成树之普里姆(Prim)算法和克鲁斯卡尔(Kruskal)算法
作者:STzen
链接:https://www.jianshu.com/p/683ffde4f3a3
来源:简书
最小生成树
列子引入

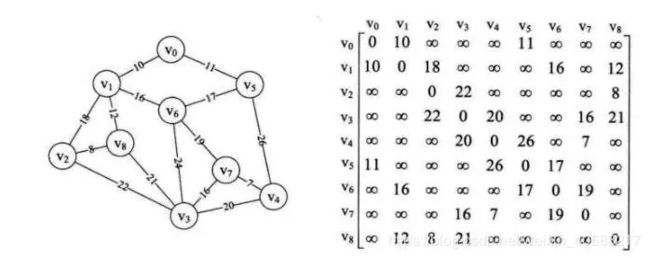
如图假设v0到v8表示9个村庄,现在需要在这9个村庄假设通信网络。村庄之间的数字代表村庄之间的直线距离,求用最小成本完成这9个村庄的通信网络建设。
分析
这幅图是一个带权值的图,即网结构。
所谓最小成本,就是n个顶点,用n-1条边把一个连通图连接起来,并且使权值的和最小。
最小生成树
如果无向连通图是一个网图,那么它的所有生成树中必有一颗是边的权值总和最小的生成树,即最小生成树。
找到连通图的最小生成树,有两种经典的算法:普里姆(Prim)算法和克鲁斯卡尔(Kruskal)算法
一、普里姆(Prim)算法
普利姆算法步骤
从图中某一个顶点出发(这里选V0),寻找它相连的所有结点,比较这些结点的权值大小,然后连接权值最小的那个结点。(这里是V1)
然后将寻找这两个结点相连的所有结点,找到权值最小的连接。(这里是V5).
重复上一步,知道所有结点都连接上。
实现代码
#include
#include
#define MAXEDGE 20
#define MAXVEX 20
#define INIFINTY 65535
typedef struct {
int arc[MAXVEX][MAXVEX];
int numVertexes, numEdges;
}MGraph;
/**
* 构建图
*/
void CreateMGraph(MGraph * G){
int i, j;
G->numVertexes = 9; // 9个顶点
G->numEdges = 15; // 15条边
for (i = 0; i < G->numVertexes; i++) { // 初始化图
for (j = 0; j < G->numVertexes; j++) {
if (i == j)
G->arc[i][j] = 0;
else
G->arc[i][j] = G->arc[j][i] = INIFINTY;
}
}
G->arc[0][1] = 10;
G->arc[0][5] = 11;
G->arc[1][2] = 18;
G->arc[1][8] = 12;
G->arc[1][6] = 16;
G->arc[2][3] = 22;
G->arc[2][8] = 8;
G->arc[3][4] = 20;
G->arc[3][7] = 16;
G->arc[3][6] = 24;
G->arc[3][8] = 21;
G->arc[4][5] = 26;
G->arc[4][7] = 7;
G->arc[5][6] = 17;
G->arc[6][7] = 19;
// 利用邻接矩阵的对称性
for (i = 0; i < G->numVertexes; i++)
for (j = 0; j < G->numVertexes; j++)
G->arc[j][i] = G->arc[i][j];
}
/**
* Prime算法生成最小生成树
*/
void MiniSpanTree_Prim(MGraph G){
int min,i,j,k;
int adjvex[MAXVEX]; // 保存相关顶点的下标
int lowcost[MAXVEX]; // 保存相关顶点间边的权值
lowcost[0] = 0; // 初始化第一个权值为0,即v0加入生成树
adjvex[0] = 0; // 初始化第一个顶点下标为0
for (i = 1; i < G.numVertexes; i++) { // 循环除下标为0外的全部顶点
lowcost[i] = G.arc[0][i]; // 将v0顶点与之右边的权值存入数组
adjvex[i] = 0; // 初始化都为v0的下标
}
for (i = 1; i < G.numVertexes; i++) {
min = INIFINTY; //初始化最小权值
j = 1;
k = 0;
while (j < G.numVertexes) { // 循环全部顶点
if (lowcost[j] != 0 && lowcost[j] < min) {
min = lowcost[j]; // 让当前权值变为最小值
k = j; // 将当前最小值的下标存入k
}
j++;
}
printf("(%d, %d)\n", adjvex[k], k); // 打印当前顶点中权值最小的边
lowcost[k] = 0; // 将当前顶点的权值设置为0,表示此顶点已经完成任务
for (j = 1; j < G.numVertexes; j++) { // 循环所有顶点
if (lowcost[j]!= 0 && G.arc[k][j] < lowcost[j]) { // 如果下标为k顶点各边权值小于当前这些顶点未被加入生成树权值
lowcost[j] = G.arc[k][j]; // 将较小的权值存入lowcost相应的位置
adjvex[j] = k; // 将下标为k的顶点存入adjvex
}
}
}
}
int main(int argc, const char * argv[]) {
MGraph G;
CreateMGraph(&G);
MiniSpanTree_Prim(G);
return 0;
}
代码解释
- 创建了两个数组adjvex和lowcost。adjvex[0] = 0意思就是从V0开始,lowcost[0] =
0表示V0已经被纳入到最小生成树中。之后凡是lowcost数组中的值被设置为0就是表示此下标的顶点被纳入最小生成树。 - 普里姆算法的时间复杂度为O(n^2),因为是两层循环嵌套。
代码运行结果

二、克鲁斯卡尔(Kruskal)算法
普里姆算法是从某一顶点为起点,逐步找各个顶点最小权值的边来构成最小生成树。那我们也可以直接从边出发,寻找权值最小的边来构建最小生成树。不过在构建的过程中要考虑是否会形成环的情况
边集数组存储图
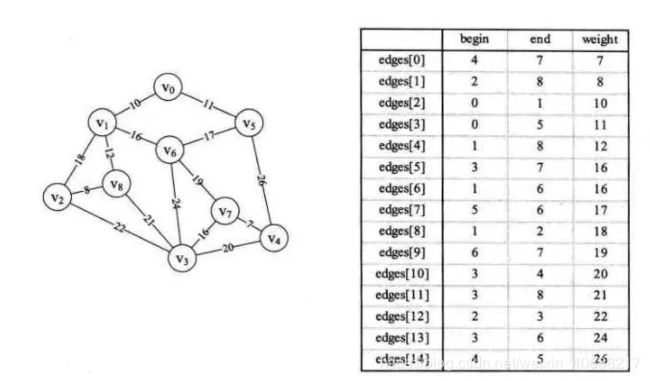
在直接用边来构建最小生成树的时候,需要用到边集数组结构,代码为:
typedef struct { // 边集数组
int begin;
int end;
int weight;
}Edge;
代码实现
#include
#include
#define MAXEDGE 20
#define MAXVEX 20
#define INIFINTY 65535
typedef struct {
int arc[MAXVEX][MAXVEX];
int numVertexes, numEdges;
}MGraph;
typedef struct { // 边集数组
int begin;
int end;
int weight;
}Edge;
/**
* 构建图
*/
void CreateMGraph(MGraph * G){
int i, j;
G->numVertexes = 9; // 9个顶点
G->numEdges = 15; // 15条边
for (i = 0; i < G->numVertexes; i++) { // 初始化图
for (j = 0; j < G->numVertexes; j++) {
if (i == j)
G->arc[i][j] = 0;
else
G->arc[i][j] = G->arc[j][i] = INIFINTY;
}
}
G->arc[0][1] = 10;
G->arc[0][5] = 11;
G->arc[1][2] = 18;
G->arc[1][8] = 12;
G->arc[1][6] = 16;
G->arc[2][3] = 22;
G->arc[2][8] = 8;
G->arc[3][4] = 20;
G->arc[3][7] = 16;
G->arc[3][6] = 24;
G->arc[3][8] = 21;
G->arc[4][5] = 26;
G->arc[4][7] = 7;
G->arc[5][6] = 17;
G->arc[6][7] = 19;
// 利用邻接矩阵的对称性
for (i = 0; i < G->numVertexes; i++)
for (j = 0; j < G->numVertexes; j++)
G->arc[j][i] = G->arc[i][j];
}
/**
* 交换权值、头、尾
*/
void Swapn(Edge * edges, int i, int j){
int temp;
temp = edges[i].begin;
edges[i].begin = edges[j].begin;
edges[j].begin = temp;
temp = edges[i].end;
edges[i].end = edges[j].end;
edges[j].end = temp;
temp = edges[i].weight;
edges[i].weight = edges[j].weight;
edges[j].weight = temp;
}
/**
* 对权值进行排序
*/
void sort(Edge edges[], MGraph *G){
int i,j;
for (i = 0; i < G->numEdges; i++) {
for (j = i+1; j < G->numEdges; j++) {
if (edges[i].weight > edges[j].weight)
Swapn(edges, i, j);
}
}
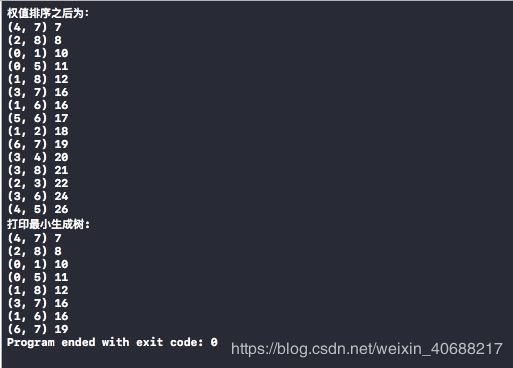
printf("权值排序之后为:\n");
for (i = 0; i < G->numEdges; i++) {
printf("(%d, %d) %d\n", edges[i].begin, edges[i].end, edges[i].weight);
}
}
/**
* 查找连线顶点的尾部下标
*/
int Find(int * parent, int f){
while (parent[f] > 0)
f = parent[f];
return f;
}
void MiniSpanTree_Kruskal(MGraph G){
int i,j,n,m;
int k = 0;
Edge edges[MAXEDGE]; // 定义边集数组
int parent[MAXVEX]; // 定义一维数组来判断边与边是否形成回路
//构建边集数组并排序
for (i = 0; i < G.numVertexes - 1; i++) {
for (j = i+1; j < G.numVertexes; j++) {
if (G.arc[i][j] < INIFINTY) {
edges[k].begin = i;
edges[k].end = j;
edges[k].weight = G.arc[i][j];
k++;
}
}
}
sort(edges, &G);
for (i = 0; i < G.numVertexes; i++) {
parent[i] = 0;
}
printf("打印最小生成树:\n");
for (i = 0; i < G.numEdges; i++) {
n = Find(parent, edges[i].begin);
m = Find(parent, edges[i].end);
if (n != m) {
parent[n] = m;
printf("(%d, %d) %d\n",edges[i].begin, edges[i].end
, edges[i].weight);
}
}
}
int main(int argc, const char * argv[]) {
MGraph G;
CreateMGraph(&G);
MiniSpanTree_Kruskal(G);
return 0;
}
代码解释
- 先构建边集数组,并排序,所以前面有对权值进行排序的方法sort。
- 克鲁斯卡尔(Kruskal)算法的时间复杂度为O(eloge)。
运行结果
对比普里姆(Prim)算法和克鲁斯卡尔(Kruskal)算法
- 克鲁斯卡尔(Kruskal)算法主要针对边来展开,边数较少时效率非常高,所以对于稀疏图有很大的优势;
- 普里姆(Prim)算法对于稠密图,边数非常多的情况更好一些。