浅谈B+Tree的演化以及在MySQL索引中的应用
对索引的简单理解
之前在学习索引的时候,就在思考为什么通过索引查询会减少查询的时间,解决查询时可能一直存在的效率问题(偶尔效率慢可能是因为锁表或者脏页等问题)。后来主要去研究了MySQL底层索引的实现原理,即对B+Tree结构的使用。
一般来说从数据库查询数据是内存对磁盘进行I/O操作的过程,而对磁盘读取的次数往往决定了查询速度的快慢。因此索引的目的就是更好优化存储结构,从而使用空间换取时间的方法增加查询的效率。当然如果创建了糟糕的索引不仅不会加快查询的效率,反而增加不必要的储存消耗。
B+Tree的演化
B+Tree最早是从平衡二叉树演化过来,但是其中的B不是二叉(binary),而是(balance),这主要依赖于磁盘的存储原理(局部性原理与磁盘预读)。在讲B+Tree之前要先了解二叉查找树,平衡二叉树(AVLTree),平衡多路查找树(B-Tree),B+Tree是从这些结构演化而来的。
二叉查找树
二叉树具有以下性质:左子树的键值小于根的键值,右子树的键值大于根的键值。
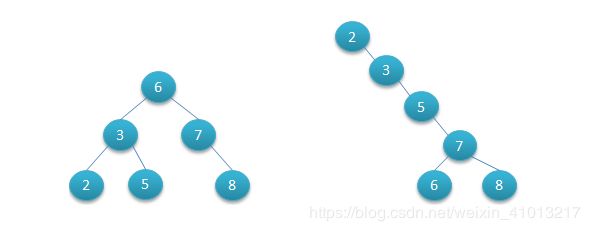
如上图所示就是两棵二叉查找树,对二叉查找树的节点进行查找发现深度为1的节点的查找次数为1,深度为2的查找次数为2,深度为n的节点的查找次数为n,因此上图左一其平均查找次数为 (1+2+2+3+3+3) / 6 = 2.3次。二叉查找树可以任意地构造,同样是2,3,5,6,7,8这六个数字,也可以按照上图右一的方式来构造,它的查找次数为(1+2+3+4+5+5)/6=3.33次,但是这样的话查询效率就会变低,因此引入了平衡二叉树的概念。
平衡二叉树
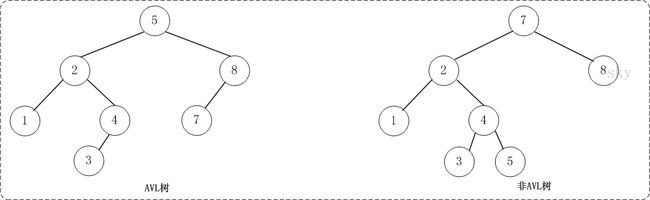
平衡二叉树(AVL树)在符合二叉查找树的条件下,还满足任何节点的两个子树的高度最大差为1。下面的两张图片,左边是AVL树,它的任何节点的两个子树的高度差<=1;右边的不是AVL树,其根节点的左子树高度为3,而右子树高度为1;
平衡多路查找树(B-Tree)
平衡多路查找树不同于平衡二叉树主要在于他允许一个节点的子节点有多个。这主要是因为这样的结构可以更好的服务于磁盘等外存储设备。
一棵m阶的B-Tree有如下特性:
- 每个节点最多有m个孩子。
- 除了根节点和叶子节点外,其它每个节点至少有Ceil(m/2)个孩子。
- 若根节点不是叶子节点,则至少有2个孩子
- 所有叶子节点都在同一层,且不包含其它关键字信息
- 每个非终端节点包含n个关键字信息(P0,P1,…Pn, k1,…kn)
- 关键字的个数n满足:ceil(m/2)-1 <= n <= m-1
- ki(i=1,…n)为关键字,且关键字升序排序。
- Pi(i=1,…n)为指向子树根节点的指针。P(i-1)指向的子树的所有节点关键字均小于ki,但都大于k(i-1)
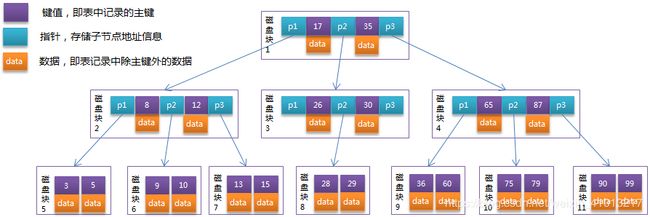
每个节点占用一个盘块的磁盘空间,一个节点上有两个升序排序的关键字和三个指向子树根节点的指针,指针存储的是子节点所在磁盘块的地址。两个关键词划分成的三个范围域对应三个指针指向的子树的数据的范围域。以根节点为例,关键字为17和35,P1指针指向的子树的数据范围为小于17,P2指针指向的子树的数据范围为17~35,P3指针指向的子树的数据范围为大于35。
模拟查找关键字29的过程:
根据根节点找到磁盘块1,读入内存。【磁盘I/O操作第1次】
比较关键字29在区间(17,35),找到磁盘块1的指针P2。
根据P2指针找到磁盘块3,读入内存。【磁盘I/O操作第2次】
比较关键字29在区间(26,30),找到磁盘块3的指针P2。
根据P2指针找到磁盘块8,读入内存。【磁盘I/O操作第3次】
在磁盘块8中的关键字列表中找到关键字29。
B-Tree存在的问题:
(1)每个节点中有key,也有data,而每一个页的存储空间是有限的,如果data数据较大时就会导致每个节点(即一个页)能存储的key的数量很小
(2)当存储的数据量很大时,同样1会导致B-Tree的深度较大,增加查询时的磁盘I/O次数,进而影响查询效率
因此B+Tree的优化主要是将非叶子节点存储的data值放到叶子结点上,而非叶子节点存储的都是key值。
B+Tree
B+Tree主要是通过上面的三种结构一步一步演化而来的。而三种结构都有自己的特点,不能说每一次都是进步,只是往最优方向的一种选择。而B+Tree对B-Tree的优化主要有以下三点。
- 非叶子节点只存储键值信息。
- 所有叶子节点之间都有一个链指针。
- 数据记录都存放在叶子节点中。
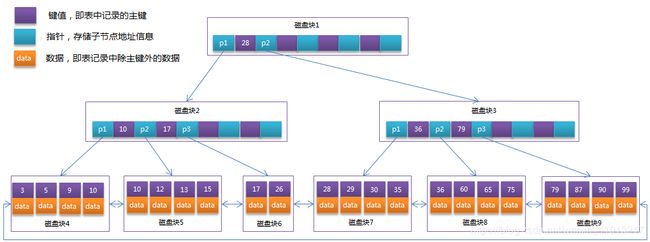
通常在B+Tree上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。因此可以对B+Tree进行两种查找运算:一种是对于主键的范围查找和分页查找,另一种是从根节点开始,进行随机查找。
可能上面例子中只有22条数据记录,看不出B+Tree的优点,下面做一个推算:
InnoDB存储引擎中页的大小为16KB,一般表的主键类型为INT(占用4个字节)或BIGINT(占用8个字节),指针类型也一般为4或8个字节,也就是说一个页(B+Tree中的一个节点)中大概存储16KB/(8B+8B)=1K个键值(因为是估值,为方便计算,这里的K取值为10 ^3)。也就是说一个深度为3的B+Tree索引可以维护10 ^3 * 10 ^3 * 10 ^3= 10亿 条记录。
实际情况中每个节点可能不能填充满,因此在数据库中,B+Tree的高度一般都在2 ~ 4层。mysql的InnoDB存储引擎在设计时是将根节点常驻内存的,也就是说查找某一键值的行记录时最多只需要1 ~ 3次磁盘I/O操作。
B+Tree在MySQL索引中的应用
InnoDB和MyISAM的索引的底层实现都是通过B+Tree来实现的
InnoDB中的B+Tree
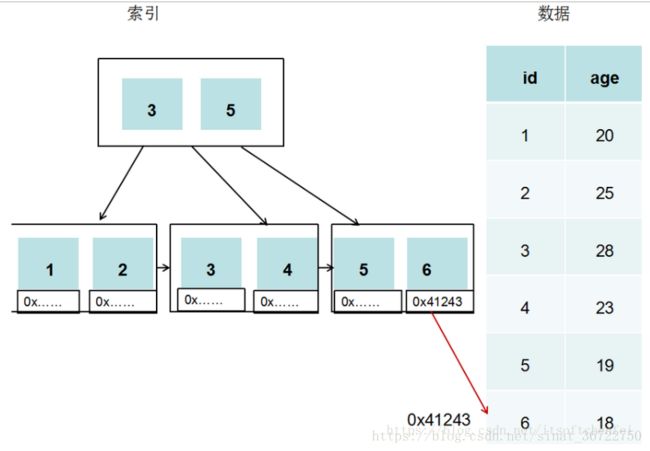
InnoDB是通过B+Tree结构对ID建索引,然后在叶子节点中存储记录,采用InnoDB引擎的数据存储文件有两个,一个定义文件,一个数据文件。若建索引的字段不是主键ID,则对该字段建索引,然后在叶子节点中存储的是该记录的主键,然后通过主键索引来找到对应的记录
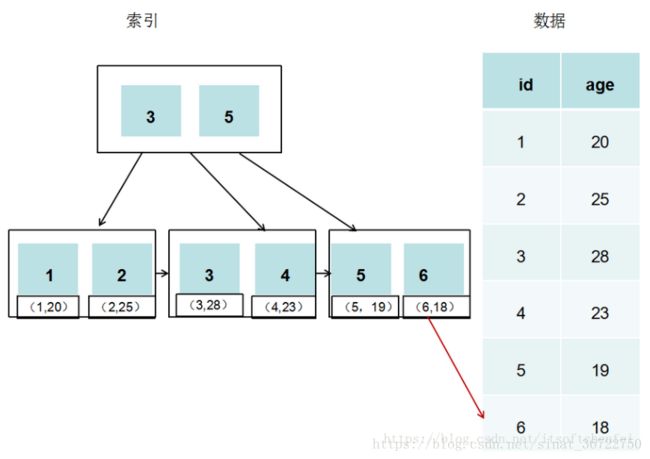
MyIsam中的索引
MyIsam中索引和数据分别存放在不同的文件,所以在索引树中的叶子节点中存放的数据是该索引对应的数据记录的地址,由于数据与索引不在一起,所以MyIsam是非聚簇索引
参考文章:
- https://blog.csdn.net/sinat_36722750/article/details/82946311
- https://blog.csdn.net/hao65103940/article/details/89032538