层级聚类(Hierarchical Cluster)python实现
前言
今天试了下用python实现层级聚类,感觉还是有不少问题。转专业的一只小菜鸡,初学代码,写的很简陋,希望各位大牛能指出不足之处。
代码
输入是一个长度可选的列表。这里用random随机生成,10个数据,并把数据用字母'a'、'b'等依次标记。
算法实现中用树结构存储数据。树的每一个节点都是一个数据集,它的左右子树代表该节点包含的两个数据集。计算所有数据相互的距离(x1.value - x2.value),将距离最小的两个数据合并成一个节点,再重新计算各个数据间的距离,直到生成一个包含所有数据的节点。
import queue
import math
import copy
import numpy as np
import matplotlib.pyplot as plt
class clusterNode:
def __init__(self, value, id=[],left=None, right=None, distance=-1, count=-1, check = 0):
'''
value: 该节点的数值,合并节点时等于原来节点值的平均值
id:节点的id,包含该节点下的所有单个元素
left和right:合并得到该节点的两个子节点
distance:两个子节点的距离
count:该节点所包含的单个元素个数
check:标识符,用于遍历时记录该节点是否被遍历过
'''
self.value = value
self.id = id
self.left = left
self.right = right
self.distance = distance
self.count = count
self.check = check
def show(self):
#显示节点相关属性
print(self.value,' ',self.left.id if self.left!=None else None,' ',\
self.right.id if self.right!=None else None,' ',self.distance,' ',self.count)
class hcluster:
def distance(self,x,y):
#计算两个节点的距离,可以换成别的距离
return math.sqrt(pow((x.value-y.value),2))
def minDist(self,dataset):
#计算所有节点中距离最小的节点对
mindist = 1000
for i in range(len(dataset)-1):
if dataset[i].check == 1:
#略过合并过的节点
continue
for j in range(i+1,len(dataset)):
if dataset[j].check == 1:
continue
dist = self.distance(dataset[i],dataset[j])
if dist < mindist:
mindist = dist
x, y = i, j
return mindist, x, y
#返回最小距离、距离最小的两个节点的索引
def fit(self,data):
dataset = [clusterNode(value=item,id=[(chr(ord('a')+i))],count=1) for i,item in enumerate(data)]
#将输入的数据元素转化成节点,并存入节点的列表
length = len(dataset)
Backup = copy.deepcopy(dataset)
#备份数据
while(True):
mindist, x, y = self.minDist(dataset)
dataset[x].check = 1
dataset[y].check = 1
tmpid = copy.deepcopy(dataset[x].id)
tmpid.extend(dataset[y].id)
dataset.append(clusterNode(value=(dataset[x].value+dataset[y].value)/2,id=tmpid,\
left=dataset[x],right=dataset[y],distance=mindist,count=dataset[x].count+dataset[y].count))
#生成新节点
if len(tmpid) == length:
#当新生成的节点已经包含所有元素时,退出循环,完成聚类
break
for item in dataset:
item.show()
return dataset
def show(self,dataset,num):
plt.figure(1)
showqueue = queue.Queue()
#存放节点信息的队列
showqueue.put(dataset[len(dataset) - 1])
#存入根节点
showqueue.put(num)
#存入根节点的中心横坐标
while not showqueue.empty():
index = showqueue.get()
#当前绘制的节点
i = showqueue.get()
#当前绘制节点中心的横坐标
left = i - (index.count)/2
right = i + (index.count)/2
if index.left != None:
x = [left,right]
y = [index.distance,index.distance]
plt.plot(x,y)
x = [left,left]
y = [index.distance,index.left.distance]
plt.plot(x,y)
showqueue.put(index.left)
showqueue.put(left)
if index.right != None:
x = [right,right]
y = [index.distance,index.right.distance]
plt.plot(x,y)
showqueue.put(index.right)
showqueue.put(right)
plt.show()
def setData(num):
#生成num个随机数据
Data = list(np.random.randint(1,100,size=num))
return Data
if __name__ == '__main__':
num = 20
dataset = setData(num)
h = hcluster()
resultset = h.fit(dataset)
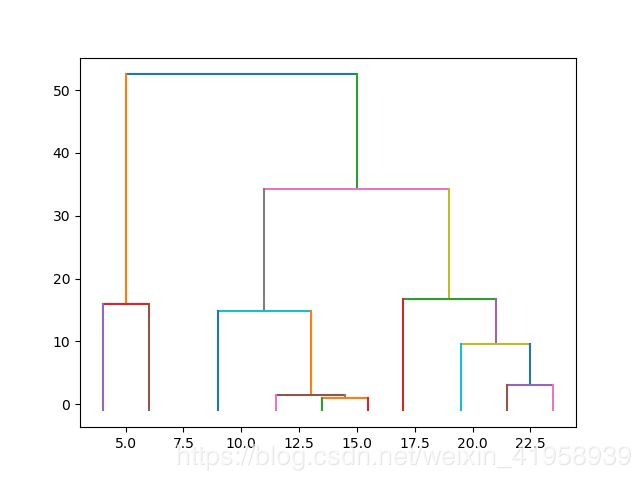
h.show(resultset,num)结果
数据集
#数值 左子节点 右子节点 高度 包含元素个数
27 None None -1 1
63 None None -1 1
85 None None -1 1
74 None None -1 1
47 None None -1 1
77 None None -1 1
11 None None -1 1
61 None None -1 1
62 None None -1 1
97 None None -1 1输出
#数值 左子节点id 右子节点id 高度 包含元素个数
62.5 ['b'] ['i'] 1.0 2
61.75 ['h'] ['b', 'i'] 1.5 3
75.5 ['d'] ['f'] 3.0 2
80.25 ['c'] ['d', 'f'] 9.5 3
54.375 ['e'] ['h', 'b', 'i'] 14.75 4
19.0 ['a'] ['g'] 16.0 2
88.625 ['j'] ['c', 'd', 'f'] 16.75 4
71.5 ['e', 'h', 'b', 'i'] ['j', 'c', 'd', 'f'] 34.25 8
45.25 ['a', 'g'] ['e', 'h', 'b', 'i', 'j', 'c', 'd', 'f'] 52.5 10Dendrogram
高度代表左右子节点的距离