Hadoop整体框架
大数据框架

目录
大数据框架
一、Hodoop
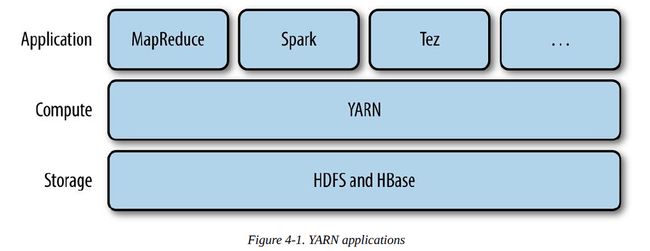
四大组件:HDFS/MapReduce/YARN/Common
二、Zookeeper
三、Hive
四、Spark
五、ETL
六、ngnix
七、Redis
八、Oracle
十一、Jsp/node.js/JQueryEcharts
一、hadoop
http://blog.csdn.net/huanglong8/article/details/63695488
视频教学来源:
http://www.imooc.com/learn/391
hadoop 的四大组件:
HDFS:分布式存储系统
MapReduce:分布式计算系统
YARN: hadoop 的资源调度系统
Common: 以上三大组件的底层支撑组件,主要提供基础工具包和 RPC 框架等
1. Hadoop的核心-HDFS简介(Hadoop分布式文件系统HDFS)
HDFS的文件都被分块存储,并且是固定比例的。默认大小是64MB。块是作为处理的逻辑单元。
有两个节点概念:
1. NameNode是管理节点,存放文件元数据
主要包括 文件和数据块的映射表,数据块与数据节点的映射表。
2. DataNode是工作节点,存放的是真正的数据块。 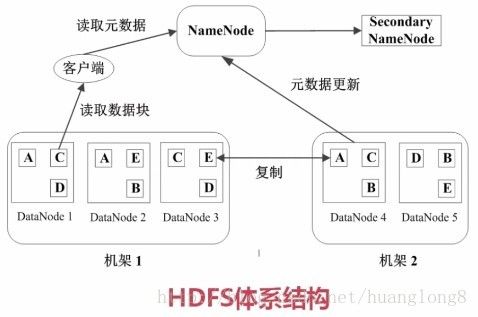
基本可以理解为,当有 一个 大小为 1GB的文件 进行存储时,HD会将其划分为 64MB * 16 。也就是 会将这个文件拆成 16个块,将每块分别存储到指定位置,通过映射表来进行管理。
快速存放,副本三份。容错处理。

存放三份,基本上遵照 2份在同一机架上,另外一份在另外一个机架上。这样可以快速的进行备份补位。当一个节点出现故障时,可以从另外一个节点拿数据。这也就是说,为什么要用64MB的大小来存储,为了快速。
那么这里会有一个心跳检测 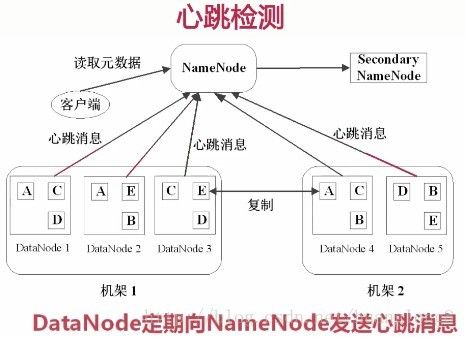
心跳很好理解,就是实时的去检查管理当前所有节点的状态。
在NameNode的右边是 Secondary NameNode,可以理解为NameNode的备份,当此部分发生故障时,这个二级名字节点就会转正,替代保证整个分布式系统循环可用。这个二级节点也定期会做一些同步或修改等操作。
Hadoop的读文件流程
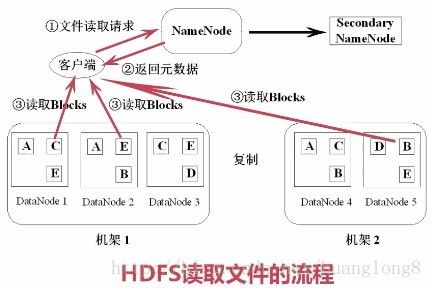
客户端请求NameNode,NameNode会返回元数据,元数据内容主要包括哪些数据块,这些数据块都存放在哪些节点上。
客户端收到NameNode后,去这些节点取数据块,然后拼接起来。
过程描述:
(1)客户端调用FileSyste对象的open()方法在分布式文件系统中打开要读取的文件。
(2)分布式文件系统通过使用RPC(远程过程调用)来调用namenode,确定文件起始块的位置。
(3)分布式文件系统的DistributedFileSystem类返回一个支持文件定位的输入流FSDataInputStream对象,FSDataInputStream对象接着封装DFSInputStream对象(存储着文件起始几个块的datanode地址),客户端对这个输入流调用read()方法。
(4)DFSInputStream连接距离最近的datanode,通过反复调用read方法,将数据从datanode传输到客户端。
(5) 到达块的末端时,DFSInputStream关闭与该datanode的连接,寻找下一个块的最佳datanode。
(6)客户端完成读取,对FSDataInputStream调用close()方法关闭连接。
Hadoop写文件流程

客户端先将文件拆分成ABC。。。等几组数据块,然后请求NameNode存储功能,NameNode寻找可存放的区域并返回给客户端。
客户端按照NameNode返回的数据区域进行存储,先存A,存完A,系统进行流水线复制,备份其副本到其他区域上,最后发送请求给NameNode,对元数据进行更新,保证映射表都是最新的。
A的过程整个存完,客户端才会继续寸B,依次类推。
写文件过程分析:
(1) 客户端通过对DistributedFileSystem对象调用create()函数来新建文件。
(2) 分布式文件系统对namenod创建一个RPC调用,在文件系统的命名空间中新建一个文件。
(3)Namenode对新建文件进行检查无误后,分布式文件系统返回给客户端一个FSDataOutputStream对象,FSDataOutputStream对象封装一个DFSoutPutstream对象,负责处理namenode和datanode之间的通信,客户端开始写入数据。
(4)FSDataOutputStream将数据分成一个一个的数据包,写入内部队列“数据队列”,DataStreamer负责将数据包依次流式传输到由一组namenode构成的管线中。
(5)DFSOutputStream维护着确认队列来等待datanode收到确认回执,收到管道中所有datanode确认后,数据包从确认队列删除。
(6)客户端完成数据的写入,对数据流调用close()方法。
(7)namenode确认完成。
HDFS的特点
1. 数据冗余,硬件容错。
2. 流式的数据访问
3. 存储大文件
适用性和局限性
适合数据批量读写,吞吐量高
不适合交互式应用,低延迟很难满足
适合一次写入多次读取,顺序读写
不支持多用户并发写相同文件
HDFS命令行操作演示
hadoop fs -ls /
打印读写文件夹
hadoop fs -put [file] input/
将file放到input/这个目录下
hadoop fs -mkdir input
建立一个input目录
hadoop fs -cat input/[file]
查看文件
hadoop fs -get input/[file] [newfile]
下载文件
hadoop dfsadmin -report
打印hadoop使用状态和信息
2. Hadoop核心—MapReduce(分布式计算系统)
MapReduce的原理
Mapreduce 是一个分布式运算程序的编程框架,是用户开发“基于 hadoop 的数据分析 应用”的核心框架;
Mapreduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的 分布式运算程序,并发运行在一个 hadoop 集群上。
为什么需要 MapReduce?
(1) 海量数据在单机上处理因为硬件资源限制,无法胜任;
(2) 而一旦将单机版程序扩展到集群来分布式运行,将极大增加程序的复杂度和开发难度;
(3) 引入 MapReduce 框架后,开发人员可以将绝大部分工作集中在业务逻辑的开发上,而将 分布式计算中的复杂性交由框架来处理。
分而治之,就是将一个大任务拆分成多个小任务,小任务执行完后,合并整个结果。

MapReduce的运行流程
- Job & Task
1个Job分成多个Task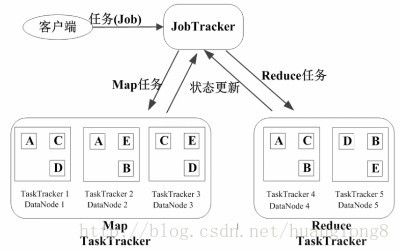
-
JobTracker的角色
作业调度,分配任务、监控任务执行进度,监控TaskTracker的状态。 -
TaskTracker的角色
执行任务,汇报任务状态

MapReduce的容错机制
1. 任务出错话,尝试重复执行。如果重复4次都失败,则放弃。
2. 推测执行,如果某一个TaskTracker计算过程中很慢或者有异于其他Task的状态时,系统会重新启动一个TaskTracker做同样的事情,如果OK了,则保证整个系统不会因为一个Task的异常而导致整个系统性能的下降或错误。
mapreduce的核心程序运行机制
1、概述
一个完整的 mapreduce 程序在分布式运行时有两类实例进程:
(1) MRAppMaster:负责整个程序的过程调度及状态协调 (该进程在yarn节点上)
(2) Yarnchild:负责 map 阶段的整个数据处理流程
(3) Yarnchild:负责 reduce 阶段的整个数据处理流程
以上两个阶段 maptask 和 reducetask 的进程都是 yarnchild,并不是说这 maptask 和 reducetask 就跑在同一个 yarnchild 进行里
(Yarnchild进程在运行该命令的节点上)
2、mapreduce程序的运行流程(经典面试题)
(1) 一个 mr 程序启动的时候,最先启动的是 MRAppMaster, MRAppMaster 启动后根据本次 job 的描述信息,计算出需要的 maptask 实例数量,然后向集群申请机器启动相应数量的 maptask 进程
(2) maptask 进程启动之后,根据给定的数据切片(哪个文件的哪个偏移量范围)范围进行数 据处理,主体流程为:
A、 利用客户指定的 inputformat 来获取 RecordReader 读取数据,形成输入 KV 对
B、 将输入 KV 对传递给客户定义的 map()方法,做逻辑运算,并将 map()方法输出的 KV 对收 集到缓存
C、 将缓存中的 KV 对按照 K 分区排序后不断溢写到磁盘文件 (超过缓存内存写到磁盘临时文件,最后都写到该文件,ruduce 获取该文件后,删除 )
(3) MRAppMaster 监控到所有 maptask 进程任务完成之后(真实情况是,某些 maptask 进 程处理完成后,就会开始启动 reducetask 去已完成的 maptask 处 fetch 数据),会根据客户指 定的参数启动相应数量的 reducetask 进程,并告知 reducetask 进程要处理的数据范围(数据
分区)
(4) Reducetask 进程启动之后,根据 MRAppMaster 告知的待处理数据所在位置,从若干台 maptask 运行所在机器上获取到若干个 maptask 输出结果文件,并在本地进行重新归并排序, 然后按照相同 key 的 KV 为一个组,调用客户定义的 reduce()方法进行逻辑运算,并收集运
算输出的结果 KV,然后调用客户指定的 outputformat 将结果数据输出到外部存储
3、maptask并行度决定机制
maptask 的并行度决定 map 阶段的任务处理并发度,进而影响到整个 job 的处理速度 那么, mapTask 并行实例是否越多越好呢?其并行度又是如何决定呢?
一个 job 的 map 阶段并行度由客户端在提交 job 时决定, 客户端对 map 阶段并行度的规划
的基本逻辑为:
将待处理数据执行逻辑切片(即按照一个特定切片大小,将待处理数据划分成逻辑上的多 个 split),然后每一个 split 分配一个 mapTask 并行实例处理
这段逻辑及形成的切片规划描述文件,是由 FileInputFormat实现类的 getSplits()方法完成的。
该方法返回的是 List
4、切片机制

三、 hadoop 的资源调度系统——YARN
1.Yarn产生的背景
hadoop1.0不能满足多系统集成的背景孕育了yarn的产生。由于多分布式系统可以很好的集成,因此yarn的出现使得整个集群的运维成本大大降低。同时,yarn可以很好的利用集群资源,避免资源的浪费,除此之外,yarn的出现实现了集群的数据共享问题,不同的分布式计算框架可以实现数据的共享。总结来说为以下两点:
-
直接源于MR在几个方面的缺陷
-扩展性受限
-单点故障
-难以支持MR之外的计算 -
多计算框架各自为战,数据共享困难
-MR:离线计算框架
-Storm:实时计算框架
-Spark:内存计算框架
2.Yarn的基本构成
我们通过Yarn的工作流程图来了解Yarn的组织架构,如下图:
(1)Client向ResourceManager发送请求
(2)ResourceManager指定一个NodeManager启动起ApplicationMaster
(3)ApplicationMaster将计算任务反馈给ResourceManager
(4)ApplicationMaster将任务分割分发到不同的NodeManager
(5)NodeManager启动Task执行work
接着需要了解的是Yarn的每个节点的详细功能:
-
ResourceManager
整个集群中只有一个,负责集群资源的统一管理和调度
详细功能:
-处理客户端请求
-启动/监控ApplicationMaster
-监控NodeManager
-资源分配与调度 -
NodeManager
整个集群有多个,负责单节点资源管理和使用
详细功能:
-单个节点上的资源管理和任务管理
-处理来自ResourceManager的命令
-处理来自ApplicationMaster的命令 -
ApplicationMaster
每个应用只有一个,负责应用程序的管理
详细功能:
-数据切分
-为应用程序申请资源,并进一步分配给内部任务
-任务监控与容错 -
Container
对任务运行环境的抽象
详细信息:
-任务运行资源(节点,内存,CPU)
-任务启动命令
-任务运行环境
下面给出Yarn的运行剖析图: 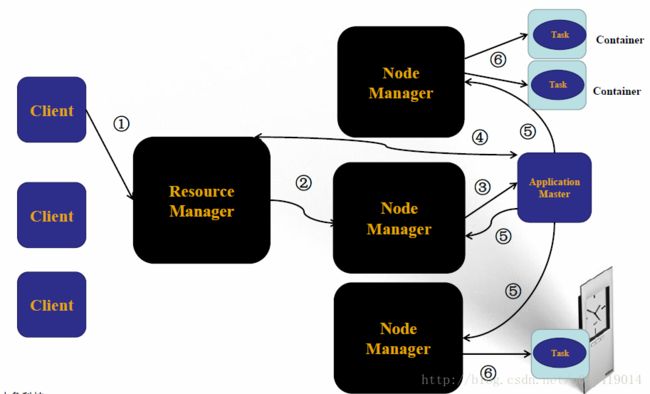
-
Yarn具有双层调度策略
ResourceManager将资源分配给ApplicationMaster,ApplicationMaster再将资源分配给NodeManager。此外,Yarn具有预留的调度策略,资源不够时,会为Task预留资源直到资源积累充足。 -
Yarn具有较好的容错机制
当任务失败时,ResourceManager将失败任务告诉ApplicationMaster。由ApplicationMaster处理失败任务,ApplicationMaster会保存已经执行的Task,重启不会重新执行。 -
Yarn支持内存和CPU两种资源隔离。
内存是一种决定生死的资源,CPU是一种影响快慢的资源,其中,内存隔离包括基于线程监控的方案和基于Cgroups的方案,而CPU隔离包括默认不对CPU资源进行隔离和基于Cgroups的方案。 -
Yarn支持的调度语义
yarn支持的语义有请求某个特定节点/机架上的特定资源量和将某些节点加入(或移除)黑名单,不再为自己分配这些节点上的资源,请求归还某些资源。
Yarn不支持的语义有请求任意节点/机架上的特定资源量;请求一组或几组符合某种特质的资源;超细粒度资源;动态调整Container资源。
3.
YARN基本组成结构
YARN总体上仍然是Master/Slave结构,在整个资源管理框架中,ResourceManager为Master,NodeManager为Slave,ResourceManager负责对各个NodeManager上的资源进行统一管理和调度。当用户提交一个应用程序时,需要提供一个用以跟踪和管理这个程序的ApplicationMaster,它负责向ResourceManager申请资源,并要求NodeManger启动可以占用一定资源的任务。由于不同的ApplicationMaster被分布到不同的节点上,因此它们之间不会相互影响。在本小节中,我们将对YARN的基本组成结构进行介绍。
图2-9描述了YARN的基本组成结构,YARN主要由ResourceManager、NodeManager、ApplicationMaster(图中给出了MapReduce和MPI两种计算框架的ApplicationMaster,分别为MR AppMstr和MPI AppMstr)和Container等几个组件构成。
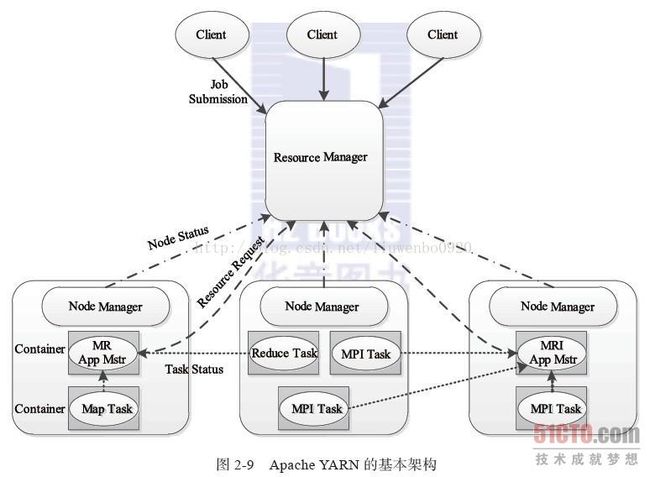
1.ResourceManager(RM)
RM是一个全局的资源管理器,负责整个系统的资源管理和分配。它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(Applications Manager,ASM)。
(1)调度器
调度器根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用程序。
需要注意的是,该调度器是一个“纯调度器”,它不再从事任何与具体应用程序相关的工作,比如不负责监控或者跟踪应用的执行状态等,也不负责重新启动因应用执行失败或者硬件故障而产生的失败任务,这些均交由应用程序相关的ApplicationMaster完成。调度器仅根据各个应用程序的资源需求进行资源分配,而资源分配单位用一个抽象概念“资源容器”(Resource Container,简称Container)表示,Container是一个动态资源分配单位,它将内存、CPU、磁盘、网络等资源封装在一起,从而限定每个任务使用的资源量。此外,该调度器是一个可插拔的组件,用户可根据自己的需要设计新的调度器,YARN提供了多种直接可用的调度器,比如Fair Scheduler和Capacity Scheduler等。
(2) 应用程序管理器
应用程序管理器负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动它等。
2. ApplicationMaster(AM)
用户提交的每个应用程序均包含1个AM,主要功能包括:
与RM调度器协商以获取资源(用Container表示);
将得到的任务进一步分配给内部的任务;
与NM通信以启动/停止任务;
监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务。
当前YARN自带了两个AM实现,一个是用于演示AM编写方法的实例程序distributedshell,它可以申请一定数目的Container以并行运行一个Shell命令或者Shell脚本;另一个是运行MapReduce应用程序的AM—MRAppMaster,我们将在第8章对其进行介绍。此外,一些其他的计算框架对应的AM正在开发中,比如Open MPI、Spark等。
3. NodeManager(NM)
NM是每个节点上的资源和任务管理器,一方面,它会定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态;另一方面,它接收并处理来自AM的Container启动/停止等各种请求。
4. Container
Container是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示的。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。
需要注意的是,Container不同于MRv1中的slot,它是一个动态资源划分单位,是根据应用程序的需求动态生成的。截至本书完成时,YARN仅支持CPU和内存两种资源,且使用了轻量级资源隔离机制Cgroups进行资源隔离。
1.3 YARN工作流程
当用户向YARN中提交一个应用程序后,YARN将分两个阶段运行该应用程序:
第一个阶段是启动ApplicationMaster;
第二个阶段是由ApplicationMaster创建应用程序,为它申请资源,并监控它的整个运行过程,直到运行完成。
如图2-11所示,YARN的工作流程分为以下几个步骤:

步骤1 用户向YARN中提交应用程序,其中包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等。
步骤2 ResourceManager为该应用程序分配第一个Container,并与对应的Node-Manager通信,要求它在这个Container中启动应用程序的ApplicationMaster。
步骤3 ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManager查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4~7。
步骤4 ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源。
步骤5 一旦ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它启动任务。
步骤6 NodeManager为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
步骤7 各个任务通过某个RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。
在应用程序运行过程中,用户可随时通过RPC向ApplicationMaster查询应用程序的当前运行状态。
步骤8 应用程序运行完成后,ApplicationMaster向ResourceManager注销并关闭自己。
1.4 多角度理解YARN
可将YARN看做一个云操作系统,它负责为应用程序启动ApplicationMaster(相当于主线程),然后再由ApplicationMaster负责数据切分、任务分配、启动和监控等工作,而由ApplicationMaster启动的各个Task(相当于子线程)仅负责自己的计算任务。当所有任务计算完成后,ApplicationMaster认为应用程序运行完成,然后退出。

二、Zookeeper
1.ZooKeeper是什么?
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,它是集群的管理者,监视着集群中各个节点的状态根据节点提交的反馈进行下一步合理操作。最终,将简单易用的接口和性能高效、功能稳定的系统提供给用户
2.ZooKeeper提供了什么?
1)文件系统
2)通知机制
3.Zookeeper文件系统
每个子目录项如 NameService 都被称作为znode,和文件系统一样,我们能够自由的增加、删除znode,在一个znode下增加、删除子znode,唯一的不同在于znode是可以存储数据的。
有四种类型的znode:
1、PERSISTENT-持久化目录节点
客户端与zookeeper断开连接后,该节点依旧存在
2、PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
3、EPHEMERAL-临时目录节点
客户端与zookeeper断开连接后,该节点被删除
4、EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
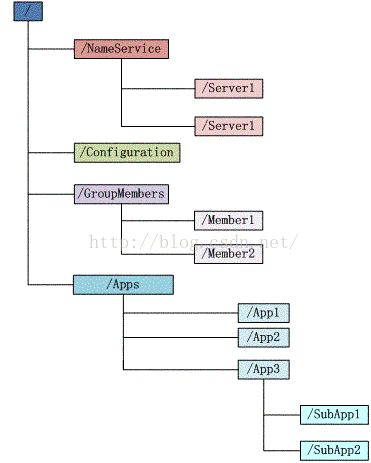
4.Zookeeper通知机制
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点增加删除)时,zookeeper会通知客户端。
5.Zookeeper做了什么?
1.命名服务 2.配置管理 3.集群管理 4.分布式锁 5.队列管理
6.Zookeeper命名服务
在zookeeper的文件系统里创建一个目录,即有唯一的path。在我们使用tborg无法确定上游程序的部署机器时即可与下游程序约定好path,通过path即能互相探索发现。
7.Zookeeper的配置管理
程序总是需要配置的,如果程序分散部署在多台机器上,要逐个改变配置就变得困难。现在把这些配置全部放到zookeeper上去,保存在 Zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中就好

8.Zookeeper集群管理
所谓集群管理无在乎两点:是否有机器退出和加入、选举master。
对于第一点,所有机器约定在父目录GroupMembers下创建临时目录节点,然后监听父目录节点的子节点变化消息。一旦有机器挂掉,该机器与 zookeeper的连接断开,其所创建的临时目录节点被删除,所有其他机器都收到通知:某个兄弟目录被删除,于是,所有人都知道:它上船了。
新机器加入也是类似,所有机器收到通知:新兄弟目录加入,highcount又有了,对于第二点,我们稍微改变一下,所有机器创建临时顺序编号目录节点,每次选取编号最小的机器作为master就好。

9.Zookeeper分布式锁
有了zookeeper的一致性文件系统,锁的问题变得容易。锁服务可以分为两类,一个是保持独占,另一个是控制时序。
对于第一类,我们将zookeeper上的一个znode看作是一把锁,通过createznode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。用完删除掉自己创建的distribute_lock 节点就释放出锁。
对于第二类, /distribute_lock 已经预先存在,所有客户端在它下面创建临时顺序编号目录节点,和选master一样,编号最小的获得锁,用完删除,依次方便。
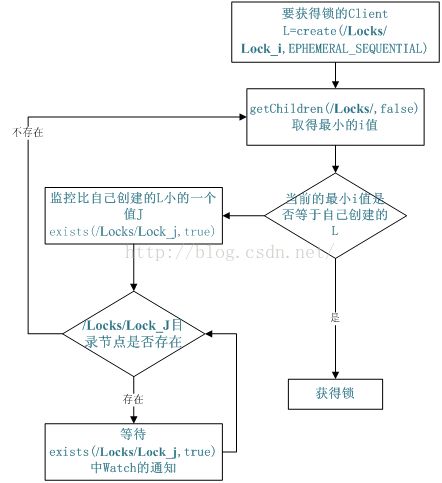
10.Zookeeper队列管理
两种类型的队列:
1、同步队列,当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达。
2、队列按照 FIFO 方式进行入队和出队操作。
第一类,在约定目录下创建临时目录节点,监听节点数目是否是我们要求的数目。
第二类,和分布式锁服务中的控制时序场景基本原理一致,入列有编号,出列按编号。
11.分布式与数据复制
Zookeeper作为一个集群提供一致的数据服务,自然,它要在所有机器间做数据复制。数据复制的好处:
1、容错:一个节点出错,不致于让整个系统停止工作,别的节点可以接管它的工作;
2、提高系统的扩展能力 :把负载分布到多个节点上,或者增加节点来提高系统的负载能力;
3、提高性能:让客户端本地访问就近的节点,提高用户访问速度。
从客户端读写访问的透明度来看,数据复制集群系统分下面两种:
1、写主(WriteMaster) :对数据的修改提交给指定的节点。读无此限制,可以读取任何一个节点。这种情况下客户端需要对读与写进行区别,俗称读写分离;
2、写任意(Write Any):对数据的修改可提交给任意的节点,跟读一样。这种情况下,客户端对集群节点的角色与变化透明。
对zookeeper来说,它采用的方式是写任意。通过增加机器,它的读吞吐能力和响应能力扩展性非常好,而写,随着机器的增多吞吐能力肯定下降(这也是它建立observer的原因),而响应能力则取决于具体实现方式,是延迟复制保持最终一致性,还是立即复制快速响应。
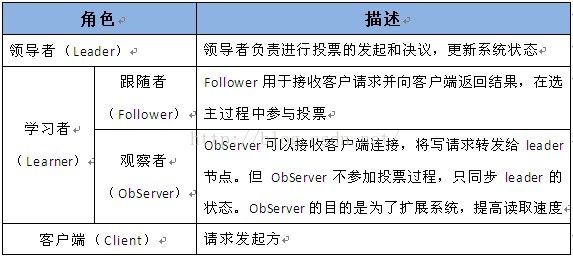
12.Zookeeper角色描述
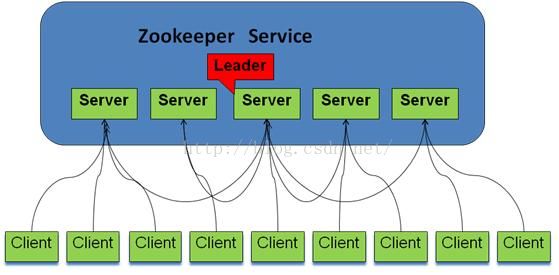
13.Zookeeper与客户端
14.Zookeeper设计目的
1.最终一致性:client不论连接到哪个Server,展示给它都是同一个视图,这是zookeeper最重要的性能。
2.可靠性:具有简单、健壮、良好的性能,如果消息被到一台服务器接受,那么它将被所有的服务器接受。
3.实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。
4.等待无关(wait-free):慢的或者失效的client不得干预快速的client的请求,使得每个client都能有效的等待。
5.原子性:更新只能成功或者失败,没有中间状态。
6.顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息a在消息b前发布,则在所有Server上消息a都将在消息b前被发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。
15.Zookeeper工作原理
Zookeeper 的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和 leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数。
16.Zookeeper 下 Server工作状态
每个Server在工作过程中有三种状态:
LOOKING:当前Server不知道leader是谁,正在搜寻
LEADING:当前Server即为选举出来的leader
FOLLOWING:leader已经选举出来,当前Server与之同步
17.Zookeeper选主流程(basic paxos)
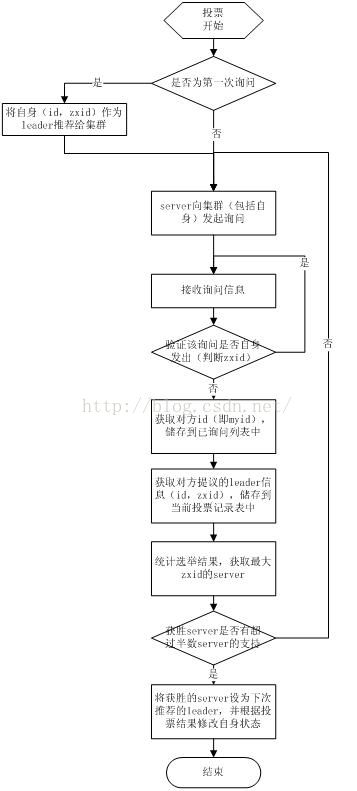
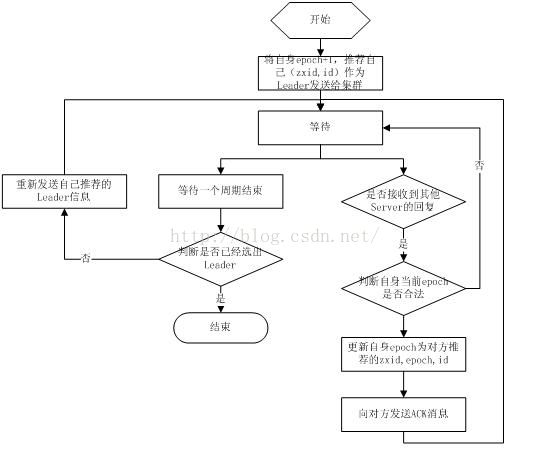
当leader崩溃或者leader失去大多数的follower,这时候zk进入恢复模式,恢复模式需要重新选举出一个新的leader,让所有的Server都恢复到一个正确的状态。Zk的选举算法有两种:一种是基于basic paxos实现的,另外一种是基于fast paxos算法实现的。系统默认的选举算法为fast paxos。
1.选举线程由当前Server发起选举的线程担任,其主要功能是对投票结果进行统计,并选出推荐的Server;
2.选举线程首先向所有Server发起一次询问(包括自己);
3.选举线程收到回复后,验证是否是自己发起的询问(验证zxid是否一致),然后获取对方的id(myid),并存储到当前询问对象列表中,最后获取对方提议的leader相关信息(id,zxid),并将这些信息存储到当次选举的投票记录表中;
4.收到所有Server回复以后,就计算出zxid最大的那个Server,并将这个Server相关信息设置成下一次要投票的Server;
5.线程将当前zxid最大的Server设置为当前Server要推荐的Leader,如果此时获胜的Server获得n/2 + 1的Server票数,设置当前推荐的leader为获胜的Server,将根据获胜的Server相关信息设置自己的状态,否则,继续这个过程,直到leader被选举出来。 通过流程分析我们可以得出:要使Leader获得多数Server的支持,则Server总数必须是奇数2n+1,且存活的Server的数目不得少于n+1. 每个Server启动后都会重复以上流程。在恢复模式下,如果是刚从崩溃状态恢复的或者刚启动的server还会从磁盘快照中恢复数据和会话信息,zk会记录事务日志并定期进行快照,方便在恢复时进行状态恢复。选主的具体流程图所示:
18.Zookeeper选主流程(fast paxos)
fast paxos流程是在选举过程中,某Server首先向所有Server提议自己要成为leader,当其它Server收到提议以后,解决epoch和 zxid的冲突,并接受对方的提议,然后向对方发送接受提议完成的消息,重复这个流程,最后一定能选举出Leader。
19.Zookeeper同步流程
选完Leader以后,zk就进入状态同步过程。
1. Leader等待server连接;
2 .Follower连接leader,将最大的zxid发送给leader;
3 .Leader根据follower的zxid确定同步点;
4 .完成同步后通知follower 已经成为uptodate状态;
5 .Follower收到uptodate消息后,又可以重新接受client的请求进行服务了。

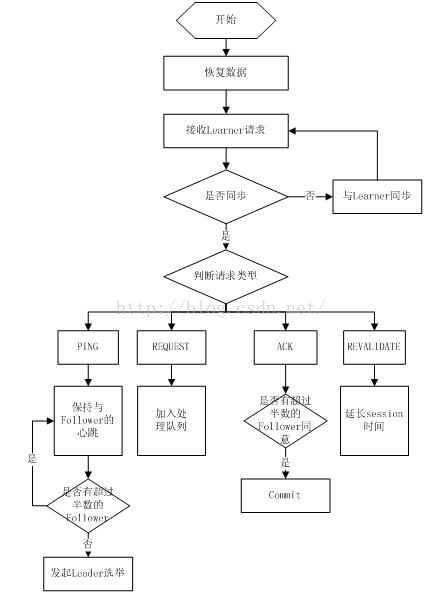
20.Zookeeper工作流程-Leader
1 .恢复数据;
2 .维持与Learner的心跳,接收Learner请求并判断Learner的请求消息类型;
3 .Learner的消息类型主要有PING消息、REQUEST消息、ACK消息、REVALIDATE消息,根据不同的消息类型,进行不同的处理。
PING 消息是指Learner的心跳信息;
REQUEST消息是Follower发送的提议信息,包括写请求及同步请求;
ACK消息是 Follower的对提议的回复,超过半数的Follower通过,则commit该提议;
REVALIDATE消息是用来延长SESSION有效时间。
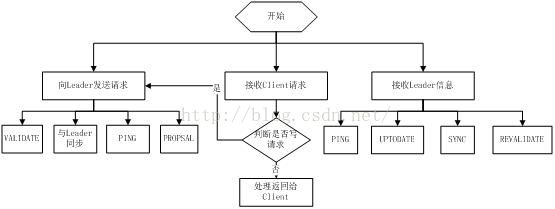
21.Zookeeper工作流程-Follower
Follower主要有四个功能:
1.向Leader发送请求(PING消息、REQUEST消息、ACK消息、REVALIDATE消息);
2.接收Leader消息并进行处理;
3.接收Client的请求,如果为写请求,发送给Leader进行投票;
4.返回Client结果。
Follower的消息循环处理如下几种来自Leader的消息:
1 .PING消息: 心跳消息;
2 .PROPOSAL消息:Leader发起的提案,要求Follower投票;
3 .COMMIT消息:服务器端最新一次提案的信息;
4 .UPTODATE消息:表明同步完成;
5 .REVALIDATE消息:根据Leader的REVALIDATE结果,关闭待revalidate的session还是允许其接受消息;
6 .SYNC消息:返回SYNC结果到客户端,这个消息最初由客户端发起,用来强制得到最新的更新。
三、Hive
Hive是构建在hdfs上的一个数据仓库,本质上就是数据库,用来存储数据
数据仓库是一个面向主题的、集成的、不可更新的、随时间不变化的数据集合,用于支持企业或组织的决策分析处理。
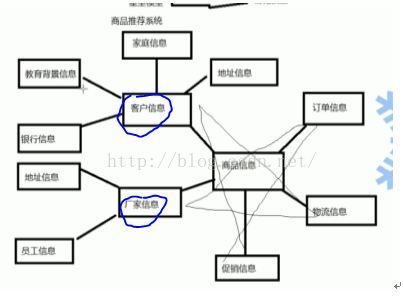
1. 面向主题:数据仓库的主题是按照一定得主题进行组织的,即用户所关注的重点对象,比如商品推荐系统。
2. 集成的:将分散的数据(文本文件,oracle数据,mysql数据。。。)进行加工处理才能够成为数据仓库的存储对象。
3. 不可更新的:数据仓库中的数据起主要用途是用于决策分析,所以主要的数据操作主要是查询操作。
4. 随时间不变化:
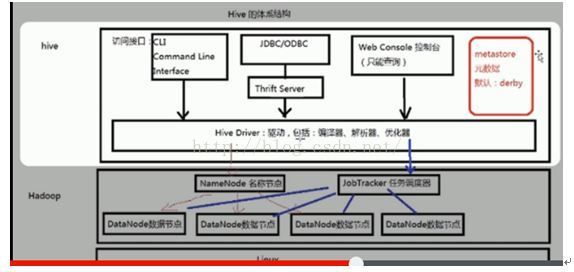
Hive体系结构:
1. 数据源:业务数据系统,文档资料,其他数据
2. 数据存储及管理:(ETL过程),[按一定的格式]对数据进行抽取(extract),转换(transform),装载(load)。经过etl操作的数据存放在数据仓库中。
3. 数据仓库引擎:包含服务器(不同服务器用不同的服务,如数据查询,数据报表,数据分析,应用等)。
OLTP应用:联机事务处理过程(面向交易的处理过程),面向事务操作,比如银行转账。
Oltp数据库旨在使事务应用程序仅写入所需的数据,以便尽快处理单个事务。
Oltp特征(百度):
支持大量并发用户定期添加和修改数据。
反映随时变化的单位状态,但不保存其历史记录。
包含大量数据,其中包括用于验证事务的大量数据。
结构复杂。
可以进行优化以对事务活动做出响应。
提供用于支持单位日常运营的技术基础结构。
个别事务能够很快地完成,并且只需访问相对较少的数据。OLTP 旨在处理同时输入的成百上千的事务。
实时性要求高。
数据量不是很大。
交易一般是确定的,所以OLTP是对确定性的数据进行存取。(比如存取款都有一个特定的金额)
并发性要求高并且严格的要求事务的完整、安全性。(比如这种情况:有可能你和你的家人同时在不同的银行取同一个帐号的款)
OLAP应用:联机分析处理过程,用于支持复杂的分析操作,侧重于对决策人员和高层管理人员的决策支持。针对历史数据操作,主要面向查询,比如商品推荐系统
数据模型:
1. 星型模型:以商品信息为主题的星型数据模型

2. 雪花模型:基于星型模型所发展起来的更复杂的数据模型。
Hive:由于Hive是构建在hdfs上的一个数据仓库,所以hive数据保存在hdfs上的。
Hive可以通过etl方式对数据进行操作。他提供hql(类似于sql)方便用户查询数据。
Hive允许udf用户自定义函数操作(比如用户自定义mapper和reducer)。
Hive本质上是SQL解析引擎,是将SQL语句转换为MR Job,然后在Hadoop上执行。
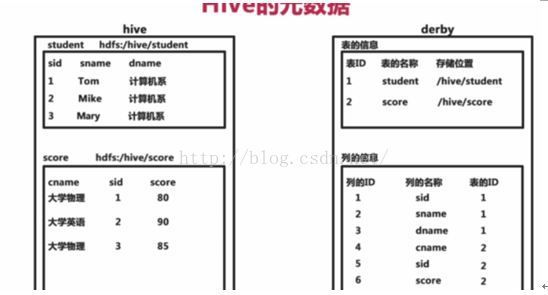
Hive的表就是hdfs的目录/文件:表—目录,数据—文件
Hive的元数据:
Hive 将元数据(metastore)存在默认数据库derby中,支持myql,derby等数据库;
Hive的元数据包括表名,表的列和分区机器属性,表的属性(是否为外部表等),表的数据所在目录等。
Hql语句的执行过程:
解释器,编译器,优化器完成hql查询语句从词法分析,语法分析,编译,优化以及查询计划的生成。生成的查询计划存储在hdfs上,以供MR电泳执行。
HQL à解析器(词优化器法分析)à编译器(生成HQL的执行计划javac命令)à优化器(生成最优的执行计划)à执行
| sqlplus 数据库名/密码@ip:1521/orcl --打开 oracle explain plan for select * from emp where depid=10;--执行解释计划 select * from table(dbms_xplan.display); --查看select的执行计划 create index myindex on emp(deptno); --创建索引 |
Archive.apache.org下载旧版本
Hive的安装模式:
1. 嵌入模式:
元数据信息被存储在hive自带的derby数据库中。
只允许创建一个连接:相同时间下只能有一个用户操作。
多用于Demo演示
2. 本地模式
元数据信息存储在Mysql数据库中
Mysql数据库与hive运行在同一台物理机器上
多用于开发与测试
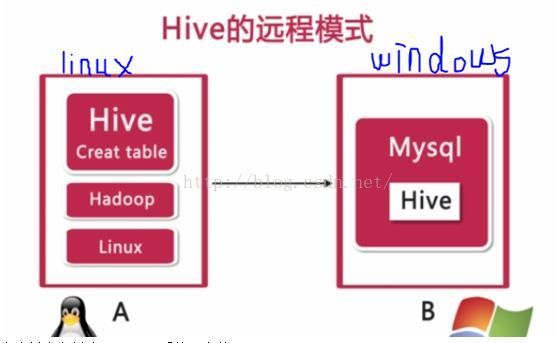
3. 远程模式
元数据信息存储在mysql数据库中
Mysql数据库和Hive数据仓库不在同一台物理机器上
用于生产环境,允许创建多个连接
嵌入式安装:
安装之前要确保Hadoop运行启动(jps命令查看);
tar –zxvf xxx.tar.gz --解压tar包
cd bin
./hive –创建hive数据仓库
可以将hive的目录加到系统path路径中,vi ~/.bash_profiles
HIVE_HOME =/home/soft/apache-hive-0.13.0-bin
export PATH =$HIVE_HOME/bin:$PATH
source~/.bash_profiles
在任何目录下执行:hive,都可以进入hive数据仓库(初次浸入式会在当前目录下创建一个metastore_db)
远程模式安装:
在虚拟中在创建wondows系统,安装mysql
mysql –uroot –p–进入mysql
create databasehive --创建hive数据库
mysql图形化工具:mysql-Frent
在linux中:
,首先进行解包:tar –zxvfxxx.tar.gz
由于元数据信息保存在mysql中,所以我们必须在hive中访问mysql数据库,必须见mysql驱动jar包加载到hive/lib中
创建并编辑hive-site.Xml文件(可以参考hive-default.xml)。
https://cwiki.apache.org/confluence/display/Hive/AdminManual+MetastoreAdmin#AdminManualMetastoreAdmin-RemoteMetastoreDatabase
|
***如果使用root权限,要设置mysql可以远程连接 |
启动bin/hive命令(必要时将hive添加到系统PATH中去)。
Hql语句
| create table test( id int, tname string ); --创建表 |
本地模式基本和本地安装基本一致,区别是
/dabasename(hive)
Hive的管理—CLI方式
Hive管理方式:
1. CLI命令行方式
1.1 输入#
1.2 CTRL+L或 !clear ---清屏
1.3 show tables; ---查看所有表
1.4 show functions; ---查看数据仓库内置的函数
1.5 desc 表名 ----查看表结构
1.6 dfs -ls 目录 --查看hdfs上的文件 dfs –lsr 目录 ---递归方式查看
1.7 ! 命令 ---执行操作系统的命令 !pwd !ls
1.8 select * from test ; 查询语句,除了这条语句外,其他select语句会将sql转换为Mapreduce作业查询。
1.9 source 文件 ----使用source命令执行sql语句。 创建my.sql文件。写入select* from test;保存; 在hive命令中输入source/root/my.sql 执行sql语句
1.10 hive –S --使用静默模式操作cli,即不打印日志只打印输出结果
1.11 hive –e sql语句 --直接执行sql语句 hive –e ‘show tables’;
2. Web界面
2.1 #hive –service hwi ---web启动方式,默认端口9999. URl:http://[IP]:9999/hwi/
该命令会加载hive的war包,即源码包,所以我们必须下载源码包并解压,并将hwi/web目录打包:jar cvfM0 hive-hwi-0.13.0.war –C web/ . ,然后将war包拷贝到$HIVE_HOME/lib下:cphive-hwi-0.13.0.war ~/$HIVE_HOME/lib/,修改conf/hive-site.xml,添加:
| |
1.2 拷贝$JAVA_HOME/lib/tools.jar到$HIVE_HOME/lib/
1.3 重新启动,打开网页,web上只能做查询操作,create session执行查询操作
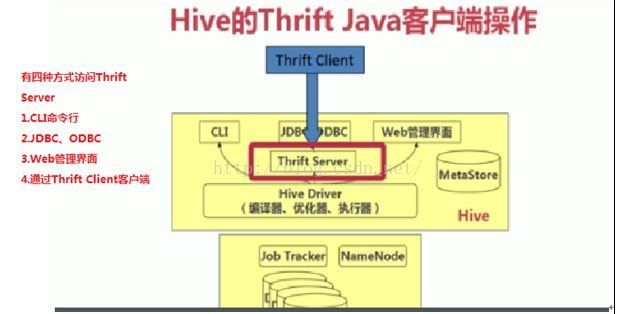
3. 远程服务启动方式
3.1 #hive –service hiveserver ----启动远程服务 port:10000
**如果以jdbc或odbc的程序登录到hive中操作数据时,必须用远程服务启动方式
该命令启动hive ThriftServer
Hive数据类型:
基本数据类型:
tinyint/smallint/int/bigint:整型
float/double:浮点数类型
string/varchar/char:字符串类型
varchar(20),最大字符串为20;char(20),固定长度为20
复杂数据类型:
array:数组类型,有一系列相同数据类型的元素组成
map:集合类型,包含
struct:结构类型(他妈的不会是泛型吧),包含不同数据类型的元素,通过“点语法”方式获得。
时间类型:
data:hive0.12.0版本后
timeStamp:hive0.8.0后
| create table person( pid tinyint, pname string, married Boolean, salary double );
复杂数据类型: create table student( sid int, sname string, grade array ); 存储的格式为:{1,’Tom’,[90,90,75]}
create table student1( sid int, sname string, grade map ); 存储格式:{2,’Mike’,<’语文’,50>}
create table student2( sid int, sname string, grade array ); 存储格式:{1,’Tom’,[<’语文’,83>,<’数学’,90>]}
create table student( sid int, info struct ); 存储格式:{1,{‘Tom’,30,’男’}} |
时间数据类型:
timestamp 与时区无关的:selectunix_timestamp();---查看当前系统时间戳的偏移量
date描述的是一个特定的时间(年,月,日YYYY-MM-DD)
Hive 的数据存储:
进入50070NN节点网页:查看hdfs的目录文件系统
Hive中没有专门的数据存储格式,默认下一制表符为分隔符
hive存储结构主要包括:数据库,文件,表,视图
hive可以直接加载文本文件
在创建表时,可以指定hive数据的列分隔符与行分隔符
表:
1. Table内部表
每一个Table在hive中都有一个响应的目录存储数据,所有Table数据都保存在该目录中。
删除表时,元数据和数据都会被删除。
| create table t1( tid int,tname string,age int );
create table t2( tid int,tname string,age int )location ‘/mytable/hive/t2’ ---指定文件存储在hdfs上的文件路径 row format delimited fields terminated by ‘|’ ----指定分隔符;
create table t4 row format delimited fields terminated by ‘|’ as select * from test; -----利用test表数据创建t4 hdfs dfs –cat /…/00000.0 ---查看hdfs文件系统内容
alter table t1 add columns(English int); ---添加数据 drop table t1;删除表 |
2. Partition分区表
Partition对应于数据库的partition列的密集索引
在hive中,表中的partition对应于表下的一个目录,所有的partition数据都存储在对应的目录中
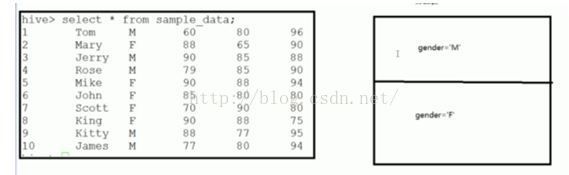
| create table patition_1( sid int,sname string )partitioned by (gender string) row format delimited fields terminated by ‘,’; eg.insert into table partition_1 partition(gender=’M’) select sid,sname from test where gender=’M’; insert into table partition_1 partition(gender=’F’) select sid,sname from test where gender=’F’; 会在hdfs中生成/user/hive/warhourse/partition_1/gender=M和gender=F两个目录 通过sql执行计划来查看查询效率 |
3. External Table 外部表
外部表指向已经在HDFS中存在的数据,可以创建partition
他和内部表在元数据的组织上是相同的,而实际数据的存储则有较大的差异;
外部表只有一个过程,加载数据和创建表同时完成,并不会移动到数据仓库目录中只是与外部数据建立一个链接。当删除外部表时,仅删除该链接。
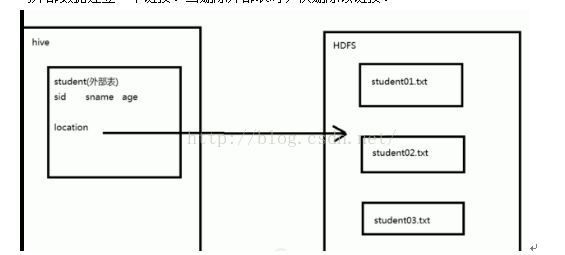
创建student01.txt,student02.txt,student03.txt并插入数据
student01.txt:Tom,23..
student02.txt:Mike,33..
student03.txt:Jams,49..
| hdfs dfs –put student01.txt /input hdfs dfs –put student02.txt /input hdfs dfs –put student03.txt /input create external table ext_student( sid int, sname string, age int )location ‘/input’ row format delimited fileds terminated by ‘|’; |
创建完成后使用select * from ext_student;可以看到ext_student表中插入了/input中的三个文件数据。
当使用hdfs dfs –rm /input/student03.txt删除某一个文件后,在使用select查询,可以看到03.txt的数据没有了,如此验证了删除了文件代表删除了链接,从而不能获取数据。
1. Bucket Table桶表
桶表是对数据进行哈希取值,然后放到不同的文件中存储。
| create table bucket_table( sid int, sname string, age int; )clustered by(sname) into 5 buckets; |
视图:
视图是一种虚表,是一种逻辑概念;
可以跨越多张表;
视图建立在已有表的基础上,视图赖以建立的这些表称为基表。
建立视图其好处是可以简化复杂的查询
| 这里有两张表: emp :empno,ename,sal,age,sex,deptno dept:deptno,dname 多表查询:查找员工信息:empno,ename,sal,dname 使用视图: create view empinfo as select e.empno,e.ename,e.sal*12 sal,d.dname from emp e,dept d where e.deptno = d.deptno; 执行select语句查询视图 |
Hive数据导入—load命令/sqoop组件
load:
| lOAD DATA [LOCAL] INPATH ‘filepath’ [OVERWRITE] INTO TABLE tablename [PARTITION (partcoll=val1, partool2=val2 …)] --导入本地文件系统的文件 load data local inpath ‘/root/data/stu01.txt’ into table t2; load data local inpath ‘root/data/’ overwrite into table t2; --导入hdfs中的文件: load data inpath ‘/input/stu01.txt’ overwrite into table t2; --导入分区表 load data local inpath ‘/input/data01.txt’ into table partition_tab partition (gender=’M’); load data local inpath ‘/root/data02.txt’ into table partition_tab partition (gender=’F’); |
批量数据导入导出:sqoop:http://sqoop.apache.org
| tar –zxvf sqoop-1.4.5.bin_hadoop-0.23.tar.gz 设置环境变量: export HADOOP_COMMON_HOME=~/training/hadoop-2.4.1/ --指明Hadoop的安装目录 export HADOOP_MAPRED_HOME=~/training/hadoop-2.4.1/ ---指明Mapreduce的家目录,使sqoop将作业转换为Mapreduce 使用sqoop-1.4.5.bin_hadoop-0.23/bin/sqoop关键字进行数据的导入和导出: Sqoop是基于jdbc的。 将oracle的驱动ojdbc14.jar导入到sqoop-1.4.5.bin_hadoop-0.23/lib中 1. 使用sqoop导入Oracle数据到HDFS中: ./sqoop import --connect jdbc:oracle:thin:@192.168.56.101:1521:orcl --username zq --password zq123 --table emp --columns ‘empno,ename,job,sal,deptno’ -m 1 --target-dir ‘/sqoop/emp’ -m 开启的mapreduce进程数。 2. 使用sqoop导入Oracle数据到hive中: |
./sqoop import --hive-import --connectjdbc:oracle:thin:@192.168.56.101:1521:orcl --username zq --password zq123--table emp –m 1 --columns ‘empno,ename,sal’
3. 使用sqoop导入oracle数据到hive中,并指定表名
./sqoop import--hive-import --connect jdbc:oracle:thin:@192.168.56.101:1521:orcl --usernamezq --password zq123 --table emp –m 1 --columns ‘empno,ename,sal’--hive-tableemp
4. 使用sqoop导入oracle数据到hive中,并使用where条件
./sqoop import--hive-import --connect jdbc:oracle:thin:@192.168.56.101:1521:orcl --usernamezq --password zq123 --table emp –m 1 --columns ‘empno,ename,job,sal,deptno’--hive-table emp2 --where ‘deptno=10’
5. 使用sqoop导入oracle数据到hive中,并使用查询语句
./sqoop import--hive-import --connect jdbc:oracle:thin:@192.168.56.101:1521:orcl --usernamezq --password zq123 –m 1--query ‘select * from empwhere sal<2000 and $conditions ’ --target-dir ‘/sqoop/emp5’--hive-tableemp5 ---有query查询语句,则必须指定表存储路径
6. 使用sqoop导出hive数据仓库数据到oracle中:
./sqoop export --connectjdbc:oracle:thin:@192.168.56.101:1521:orcl --username zq --password zq123 –m 1--table myemp –export-dir ‘/root/data’
--要确保oracle的myemp表存在,并且属性和hive中的表属性一致 ???

简单查询和fetchtask
简单查询:
| SELECT [ALL|DISTINCT] select_expr,selec_expr,… FROM table_refrence [WHERE where_condition] [GROUP BY col_list] [CLUSTER BY col_list | [DISTRIBUTE BY col_list]] [SORT BY col_list] | [ORDER BY col_list] [LIMIT number] DISTRIBUTE BY 指定分发器 (Partitioner),多Reducer可用 查询员工的所有信息 select * from emp; 查询员工信息:select empno,ename,sal from emp; 查询员工的信息:empno,ename,sal,sal*12,comm.,sal*12+nvl(comm,0) from emp; 查询奖金为空的员工信息:select * from emp where comm is null; 查询员工号信息(不重复):select distinct empno from emp; |
Fetch Task功能:从Hive0.10.0版本开始
配置方式:
hive> set hive.fetch.task.conversion=more;
hive --hiveconfhive.fetch.task.conversion=more
修改hive-site.xml文件,永久生效
在hive仓库中使用过滤和排序:
| --查询10号部门的员工信息 select * from emp where deptno=10; 查询名为KING的员工信息: select * from emp where ename=’KING’; --区分大小写 查询部门号是10,薪水小于2000的员工: select * from emp where empno=10 and sal<2000; ---使用explain查看说明 模糊查询:名字以s大头的员工信息 select * from emp where ename like ’s%’; 查询名字中含有下划线的员工信息: select * from emp where ename like ‘%\\_%’; 排序:使用Mapreduce作业执行: select empno,ename,sal frpm emp order by sal [desc]; order by +列,表达式,别名,序号 select empno,ename,sal,sal*12 from emp order by sal*12; select empno,ename,sal,sal*12 sals from emp order by sals; hive> set hive.groupby.orderby.position.alias=true; ---设置可通过序列号进行排序操作 select empno,ename,sal,sal*12 from emp order by 4; 包含null的列在升序排列中默认被排在前面,降序被排在最后面,一般将控制转变为0或其他有意义的词语代替null |
hive数学函数:
| 1. 内置函数 round:四舍五入 select round(45.925,2); ceil向上取整: select ceil(45.9),ceil(45.3); --46 floor向下取整: select floor(45.6),floor(45.2);
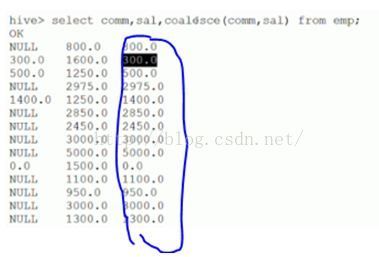
字符函数: lower,upper,length,concat,substr,trim,lpad,rpad select lower(‘HELLO’),upper(‘hello’); select length(‘hello’),concat(‘a’,’b’,’c’),concat(‘n’,4+2); select length(‘你好’) ; --在hive中为2 select length(‘你好’) from dual; --在mysql中为4,在oracle中为2 select substr(‘hello’,1); ---起始点由1开始计算 select substr(‘hello’,2,3);--ell,3指截取长度 select length(trim(‘ hello ’)); --5 select lpad(‘a’,3,’c’); --左填充 select rpad(‘a’,3,’c’); --右填充 收集函数和转换函数: size 统计map集合的个数:size(map( select size(map(1,’Tom’,2,’Mary’)); ---2 cast转换函数 select cast(1 as bigint),cast(1 as float) ; select cast(‘2016-07-13’ as date); --2016-07-13’ 日期函数: to_date,year,month,day,weekofyear,datediff,date_add,date_sub select to_date(‘2016-07-13 17:01:24’); --2016-07-13’ select year(‘2016-07-13 17:01:24’),month(‘2016-07-13 17:01:24’),day(‘2016-07-13 17:01:24’); select weekofyear(‘2015-09-14 12:23:13’); --返回该日期在一年中是第几个星期,38 select datediff(‘2015-02-12’,now()); --返回两个日期相差的天数,前面-后面= -517 select date_add(‘2015-05-10’,30); --在该日期之上增加30天 select date_add(‘2015-05-10’,interval 30 year/month/day) ---mysql语法 条件函数: coalesce:从左到右返回第一个不为null的值
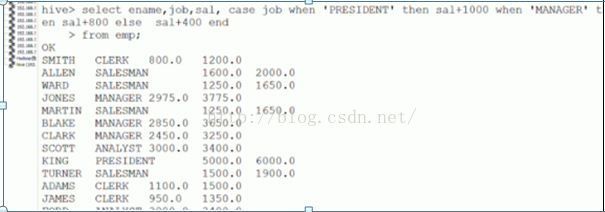
cast…when … 条件表达式 ---可实现ifelse语句 语法格式: CASE a WHEN b THEN c [WHEN d THEN e]* [ELSE f] END
聚合函数和表生成函数: count,sum,min,max,avg –-聚合函数,转换为Mapreduce作业 explode --表生成函数,可以将map集合或数组的每个元素单独生成行
2. 自定义函数 首先创建一个类,该类继承org.apache.hadoop.hive.ql.UDF,重写evaluate方法[evaluate支持重载];public Text evaluate(Text a,Text b){} 然后将程序打包放到目标机器上(hive服务器); 进入hive客户端,添加jar包:hive> add jar /root/traing/udfjar/udf_test.jar 创建临时函数:hive>create temporary function <函数名> as ‘包全名.jave类名’;
使用该函数:select 函数名 from tablename; 销毁临时函数:drop temporary function 函数名;
|


Hive的表连接:
等值连接[=],不等值连接[between and] ---mapreduce
| 查询员工信息:empno,ename,sal,d.depno select e.empno,e.ename,e.sal,d.depno from emp e,dept d where e.deptno=d.deptno; |
外连接:可以将对于连接条件不成立的记录包含在最后的结果中。分为左外连接和右外连接
| 查询员工信息:部门号,部门,员工总数 select d.depno,d.dname,count(e.empno) from emp e,dept d where e.deptno=d.deptno group by d.deptno,d.dname; --hql语句中select没有包含聚合函数的列都要写在group by之后 左外连接:连接条件左边的表会包含在左边,left outer join on 左外连接是将左表作为主表,右表作为从表,结果集中全部显示主表(左表)的信息。 右外连接:连接条件右边的表会包含在右边,right outer join on 右外连接是将右表作为主表,左表作为从表,结果集中全部显示主表(右表)的信息。 select d.depno,d.dname,count(e.empno) from emp e right outer join dept d on (e.deptno=d.deptno) group by d.deptno,d.dname; |
内连接:自连接,通过表的别名将同一张表视为多张表
| 查询员工姓名和员工老板姓名 select e.ename,b.ename from emp e,emp b where e.mgr=b.empno; |
Hive子查询:只支持from和where的子查询
| select e.ename from emp e where e.deptno in (select d.deptno from dept d where d.dname=’SALES’ or d.dname=’ACCOURING’); --where后一对多 空值问题null: select * from emp e where e.empno not in (select e1.mgr from emp e1 where e1.mgr is not null); |
Hive的JDBC客户端操作:
| # hive –service hiveserver --启动服务器 Jdbc程序访问:eclipse—java工程—添加hive驱动jar包[hive-jdbc-0.13.0.jar]及其他相关的hive包:[$HIVE_HOME/lib/] 步骤: driver = “org.apache.hadoop.hive.jdbc.HiveDriver”; url = “jdbc:hive://192.168.56.31:10000/default”; 1. 获取连接
2. 创建运行环境 Statement stat = conn.createStatement(); 3. 执行HQL ResultSet rs = stat.executeQuery(“select * from emp”); 4. 处理结果集 while(rs.next()) { String name = rs.getString(2); double sal = rs.getDouble(6); System.out.println(name+”\t”+sal); } 5. 释放资源
Thrift Client 访问
步骤: 1. 创建Socket服务器连接 final TSocket tSocket = new TSocket(“192.168.56.22”,10000); 2. 创建协议 final TProtocal tProtcal = new TBinaryProtocol(tSocket); 3. 创建Hive Client final HiveClient client = new HiveClient(tProtcal); 4. 打开Socket tSocket.open(); 5. 执行HQL语句 client.execute(“desc emp”); ----hql语句 6. 处理结果集 List for(String col:columns) { System.out.println(col); } 7. 关闭服务器 tSocket.close(); |
Hive采用元数据对表进行管理。元数据的存储方式为嵌入模式,本地模式和远程模式
四、Spark
spark定义 spark是今年来发展较快的分布式并行数据处理框架,和hadoop联合使用,增强hadoop性能,增加内存缓存,流数据处理,图数据处理等更为高级的数据处理能力,
mapreduce是属于hadoop生态体系之一,spark属于bdas生态体系之一,hadoop包含mapreduce hdfs hbase hive zookeeper pig sgoop等 hdas包含spark shark相当于hive blinkdb sparkstreaming 消息实时处理框架,类似storm等等
mapreduce通常将中间结果放在hdfs上,spark是基于内存并行大数据框架,中间结果放在内存,对于迭代数据spark效率更高,
mapreduce总是小号大量时间排序,而有些场景不需要排序,spark可以避免不必要的排序所带来的开销,spark是一张有向无环图,
spark支持api,支持scala,python。java等
spark运行模式,local模型用于测试开发,standlone 独立集群模式,spark on yarn spark在yarn上 ,spark on mesos spark在mesos上。
spark缓存策咯;
spark通过userdisk,usememory deserialized rplication 4个参数组成11种缓存策略
spark提交方式
spark-submit 常用的提交方式,或者java-jar方式
大数据平台 1,ioe 平台2 hadoop平台
集群部署,数据管理,任务调度,集群监控在大数据操作中我几个步骤。
hadoop 分1.0时代和2.0时代,
2.0时代 hdfs hbase mapreduce模型等变化不大 mapreduce云顶在yarn系统上,
yarn : resourceManager ,nodeManager
impala: stateStore catalog impala中session 就是一个任务 application运行在impala的工作进程中,
spark: 2.0时代很火,有代替mapreduce的趋势,
spark中 master 有web端口 8080 默认 worker web默认8081端口 application web端口4040 多个任务时端口是递增的,
spark 3种编程接口 我们常用java
企业大数据应用: 1,count 平均值 2.分类,对比 3.趋势,统计分析 4,精准预测 人工智能
行业大数据案例:电商,传媒,能源,交通
大数据需要哪些技能:
spark : 启动方式1.启动参数: spark_mem=8g spark-shell -c 24 每个任务8g内存 -c24 总共最多24个任务
启动方式2. 默认是全部的机器cpu内核,内存512mb
学点 scala 类型这样的集合 {1,(type1,ts1)} key value结构 通过reducebykey groupbykey 获得ts最大值
通过函数把数据类型转换 spark中函数
spark 可以通过yarn 资源调度器来运行,spark jar 环境变量 spark class yarn。client来提交一个文件
spark 1.0 发布 看起来很美,spark 主要运行在yarn上 spark-assembly。jar 传hdfs中 yarn来启动spark
spark on yarn 俩启动的区别。
1. cluster模式中 所有的操作在yarn中运行的。
2.client模式中 client中启动spark derver
spark shell只能在client的模式中运行,在cluster模式中不用启动spark shell来操作spark命令
spark on yarn 启动参数:
hadoop-conf-dir 就够了
./bin/spark-shell +设置参数 内存 机器内核等
./bin/spark-submit 提交java jar包
scala 就是用spark 函数的形式来操作数据,例如进行求值,排序等
scala 函数编译 spark mvn +参数
scala maven项目 提交 ./bin/spark-submint +参数
scala maven项目 写法大多是调用scala函数
spark sql来实现 处理parquet文件 和 读取csv文件 或者hbase 相似 批量读取 一个表 读取一次 每个表一个parkConext对象
直接读取 自动分好列 自动生成 编程k-value对
最后写入一个文件里 parquet文件一般比csv文件小很多的 csv是一次多好多表 parquet文件是一次多一个表
读取文件在spark中创建表 和列 然后用spark sql 查询数据存取成 map 形式读取出来
什么是spark:
spark是开源的类hadoop mapreduce的通用的并行计算框架,spark基于mapreduce算法实现的分布式计算,拥有hadopp
mapreduce所具有的有点,但不同于mapreduce的job中间输出和结果 可以保存在内存中,从而不在需要读写hdfs,因此spark更好的
适用于数据挖掘与机器学习等需要迭代mapreduce的算法,
spark和hadoop的对比:
spark的中间数据放在内存中,对于迭代运行效率更高,spark更适合于迭代云端比较多的ml和dm运算,因为spark里面有rdd的抽象概念,spark比hadoop更通用,spark提供的数据集操作类型有很多,不像hadoop只提供map和reduce俩种操作,比如map,filter,flatmapt,sample,groupbykey,reducebykey,union,join,cogroup,mapvalues,sort,partionby等多种操作类型,spark
把这些操作称为tarnnsformations,同时还提供count,collect,reduce,lookup,save等多种action操作。这些多种多样的数据集操作类型,给开发上层应用的用户提供了方便,各个处理节点之间的通信模型不在像hadoop那样就是唯一的data shuffle一种模式,用户可以明明,物化,控制中间结果的存储,分区等,可以说编程模型比hadoop更灵活。不过由于rdd的特性,spark不适用那种一部细粒度更新状态
的应用,例如web服务的存储或者增量的web爬虫和索引,就是对于那种增量修改的应用模型不合适。
容错性:
在分布式数据集计算时通过checkpoint来实现容错,而checkpoint又俩种方式,一个是checkpoint data,一个是logging the updates。用户可以控制采用哪种方式来实现容错。
可用性:
spark通过提供丰富的scala,java,python api及交互式shell来提高可用性。
spark和hadoop的结合:
spark可以直接对hdfs进行数据的读写,同样支持spark on yarn。spark可以与mapreduce运行于同集群中,共享存储资源与计算,数据
仓库shark'实现上借用hive,几乎和hive完全兼容。
spark的使用的场景:
spark是基于内存的迭代计算框架,使用与需要多次操作特定数据集的应用场合,需要反复操作的次数越多,所需要读取的数据量越大,
受益越大,数据量小但是计算密集度较大的场合,受益就相对较小:::注::这是大数据库架构中是否考虑使用spark的重要因素。
用于rdd的特性,spark不适用那种一部细粒度更新状态的应用。例如web服务的存储或者增量的web爬虫和索引,就是对于那种增量修改的应用模型不合适,总的来说,spark的使用面比较广泛且比较通用。
spark生态系统介绍:
shark介绍:
shark基本上就是spark的框架基础上提供和hive一样的hivesql命令接口,为了最大程度的保持和hive的兼容性,shark使用hive的api来实现query parsing和logic plan generation,最后的physicalplan execution阶段用spark代替hadoop mapreduce,用过配置shark参数,shark可以自动在内存中缓存特定的rdd,实现数据重用,进而加快特定数据集的检索,同时,shark通过udf用户自定义函数实现特定的数据分析学习算法,是的sql数据查询和运算分析能结合在一起,最大化rdd的重复使用。
spark streaming介绍:
构建在spark上处理stream数据的框架,基本的原理是将stream数据分成小的时间片段,以类似batch批量处理的方式来处理这些小部分数据
。spark streaming构建在spark上,一方面是因为spark的低延迟执行引擎可以用于实时计算,此外小批量的处理方式是的他可以同时兼容批量和实时数据处理的逻辑和算法,方便了一些需要历史数据和实时数据联合分析的特定应用场景。
bagel介绍:
pregel on spark,可以哟个spark进行图计算,着是个非常有用的小项目,bagel自带了一个例子,实现了google的pagerank算法
什么是rdd:
rdd是spark最基本,也是最根本的数据抽象,rdd也就是弹性分布式数据集,rdd是只读的,分区记录的集合,rdd只能基于在稳定物理存储中的数据集和其他已有的rdd上执行确定性操作来创建,者些确定性操作称之为转换,如map,filter,groupby,join。rdd不需要物化,rdd含有如何从其他rdd衍生出本rdd的相关信息,据此可以从物理存储的数据计算出相应的rdd分区,rdd支持两种操作,1,转换从现有的数据集创建一个新的数据集,2,动作 在数据集上运行计算后,返回一个值给驱动程序,例如,map就是一种转换,他将数据集每一个元素都传递给函数,并返回一个新的分布数据集表示结果,另一个方面,reduce是一个动作,通过一些函数将所有的元组叠加起来,并将结果返回给driver程序,spark中的所有转换都有惰性的,也就是说,他们并不会直接计算结果,相反的,他们只是记住应用哦个到基础数据集上的这些转换动作,例如,我们可以实现,通过map创建的一个新数据集,并在reduce使用,最终只返回reduce的结果给driver,而不是整个大的新数据集。默认情况下,每个转换过的rdd都会在你在他之上执行一个动作时被重新计算,不过,你也可以使用persist方法,之久话一个rdd在内存中,在这种情况下,spark将会在集群中,保存相关元素,下次你查询这个rdd是,他将能更快访问,在磁盘上持久化数据集,或在集群间赋值数据集也是支持的。除了这些操作外,用户还可以请求将rdd缓存起来,而且,用户还可以通过partitioner类获取rdd的分区顺序,然后将另一个rdd按照同样的方式分区,
--------------------------------------------------------------------------------------------------------------
rdd使用详解
是不是spark基于内存所以这么快呢,不是的,不只这些,还有spark是一个整体的计算,spark不排序,hadoop没次计算都排序,
spark程序分俩部分,
如何操作rdd?
如何获取rdd 1,从共享的文件系统获取,hdfs,2.通过已存在的rdd转换 3.将已存在的scala集合并行化,通过调用sparkcontext的parallelize方法实现 4.改变现有rdd的之久性,rdd是懒散,短暂的
操作rdd的俩个动作,1,actions:对数据集计算后返回一个数值value给驱动程序,例如redue将数据集的所有元素用某个函数聚合后,将最终结果返回给程序,2.transformation 根据数据集创建一个新的数据集,计算后返回一个新rdd;例如map将数据的每个元素讲过某个函数计算后,返回一个姓的分布式数据集。
actions具体内容:
reduce(func)通过函数func聚集数据集中所有元素,func函数接受2个参数,返回一个值,这个函数必须是关联性的,确保可以被正确的并发执行。
collect() 在driver的程序中,以数组的形式,返回数据集的所有元素,这通常会在使用filter或者其他操作后,返回一个纵沟小的数据自己在使用,直接将整个rdd集coloect返回,很可能会让driver程序oom。
count() 返回数据集的元素个数
take(n) 返回一个数组,用数据集的前n个元素组成,注意,这个操作目前并非在多个节点上,并行执行,而是driver程序所在机制,单机计算所有的元素:注;gateway的内存压力会增大,需要谨慎使用
first()返回数据集的第一个元素
saveAsTextFile(path) 将数据集的元素,以txtfile的形式,保存到本地文件系统,hdfs或者其他hadoop支持的文件系统,spark将会调用每个元素的tostring方法,并将他转换成文件中一行文本。
saveAsSequenceFile(path)将数据集的元素,以sequencefile的格式,把偶你到指定的目录下,本地系统,hdfs或者其他hadoop支持的文件系统,rdd的元组必须有key-value对组成,并都实现了hadoop的writable接口或隐式可以转换为wirtable
foreach(func)在数据集的每个元素上,运行函数func,这通常用于更新一个累加器变量,或者和外部存储系统做交互。
transformation具体内容:
map(func) 返回一个新的分布式数据集,有每个原元素经过func函数转换后组成
filter(func) 返回一个新的数据集,有经过func函数后返回值为true的原元素组成
flatmap(func)类似于map 但是每一个输入元素,会被银蛇为0到多个输出元素,因此func函数的返回值是一个seq,而不是单一元素
sample(withReplacement,frac,seed) 根绝给定的随机种子seed,随机抽样出数量为frac的数据
union(otherdataset)返回一个新的数据集,有缘数据集和参数联合而成
groupbykey(【num tasks】)在一个有kv对组成的数据集上调用,返回一个k,seq【v】对的数据集,注意,默认情况下,使用8个并行任务进行分组,你可以传入num task可选参数,根绝数据量设置不同数目的task
reducebykey(func,【num tasks】)在一个kv对的数据集上使用,返回一个kv的数据集,key相同的值都被使用指定的reduce函数聚合在一起,和groupbykey类似,任务个数是第二个参数来配置
join(otherdataset,【num tasks】)在类型kev和kw类型的数据集上调用,返回一个k(v w)对,每个key中所有元素都在一起的数据集
groupwith(otherdataset,【num tasks】)在类型为kv和kw类型的数据集上调用,返回一个数据集,组成元组为k seq【v】seq[w]tuples ,这个奥做在其他框架成为cogroup
cartesian(otherdataset) 笛卡儿积,但在数据集t和u调用是,返回一个tu对的数据集,所有元素交互进行笛卡儿积。
flatmap(func)类似map,但是每一个数据元素,会被映射为0到多个输出元素
五、ETL——数据抽取、转换、装载的过程
ETL即数据抽取(Extract)、转换(Transform)、装载(Load)的过程,它是构建数据仓库的重要环节。
ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。ETL是BI项目重要的一个环节。通常情况下,在BI项目中ETL会花掉整个项目的1/3的时间,ETL设计的好坏直接关接到BI项目的成败。
ETL的设计分三部分:数据抽取、数据的清洗转换、数据的加载。在设计ETL的时候我们也是从这三部分出发。数据的抽取是从各个不同的数据源抽取到ODS(OperationalDataStore,操作型数据存储)中——这个过程也可以做一些数据的清洗和转换),在抽取的过程中需要挑选不同的抽取方法,尽可能的提高ETL的运行效率。ETL三个部分中,花费时间最长的是“T”(Transform,清洗、转换)的部分,一般情况下这部分工作量是整个ETL的2/3。数据的加载一般在数据清洗完了之后直接写入DW(DataWarehousing,数据仓库)中去。
ETL的实现有多种方法,常用的有三种。一种是借助ETL工具(如Oracle的OWB、SQLServer2000的DTS、SQLServer2005的SSIS服务、Informatic等)实现,一种是SQL方式实现,另外一种是ETL工具和SQL相结合。前两种方法各有各的优缺点,借助工具可以快速的建立起ETL工程,屏蔽了复杂的编码任务,提高了速度,降低了难度,但是缺少灵活性。SQL的方法优点是灵活,提高ETL运行效率,但是编码复杂,对技术要求比较高。第三种是综合了前面二种的优点,会极大地提高ETL的开发速度和效率。
一、数据的抽取
这一部分需要在调研阶段做大量的工作,首先要搞清楚数据是从几个业务系统中来,各个业务系统的数据库服务器运行什么DBMS,是否存在手工数据,手工数据量有多大,是否存在非结构化的数据等等,当收集完这些信息之后才可以进行数据抽取的设计。
1、对于与存放DW的数据库系统相同的数据源处理方法
这一类数据源在设计上比较容易。一般情况下,DBMS(SQLServer、Oracle)都会提供数据库链接功能,在DW数据库服务器和原业务系统之间建立直接的链接关系就可以写Select语句直接访问。
2、对于与DW数据库系统不同的数据源的处理方法
对于这一类数据源,一般情况下也可以通过ODBC的方式建立数据库链接——如SQLServer和Oracle之间。如果不能建立数据库链接,可以有两种方式完成,一种是通过工具将源数据导出成.txt或者是.xls文件,然后再将这些源系统文件导入到ODS中。另外一种方法是通过程序接口来完成。
3、对于文件类型数据源(.txt,.xls),可以培训业务人员利用数据库工具将这些数据导入到指定的数据库,然后从指定的数据库中抽取。或者还可以借助工具实现,如SQLServer2005的SSIS服务的平面数据源和平面目标等组件导入ODS中去。
4、增量更新的问题
对于数据量大的系统,必须考虑增量抽取。一般情况下,业务系统会记录业务发生的时间,我们可以用来做增量的标志,每次抽取之前首先判断ODS中记录最大的时间,然后根据这个时间去业务系统取大于这个时间所有的记录。利用业务系统的时间戳,一般情况下,业务系统没有或者部分有时间戳。
二、数据的清洗转换
一般情况下,数据仓库分为ODS、DW两部分。通常的做法是从业务系统到ODS做清洗,将脏数据和不完整数据过滤掉,在从ODS到DW的过程中转换,进行一些业务规则的计算和聚合。
1、数据清洗
数据清洗的任务是过滤那些不符合要求的数据,将过滤的结果交给业务主管部门,确认是否过滤掉还是由业务单位修正之后再进行抽取。不符合要求的数据主要是有不完整的数据、错误的数据、重复的数据三大类。
(1)不完整的数据:这一类数据主要是一些应该有的信息缺失,如供应商的名称、分公司的名称、客户的区域信息缺失、业务系统中主表与明细表不能匹配等。对于这一类数据过滤出来,按缺失的内容分别写入不同Excel文件向客户提交,要求在规定的时间内补全。补全后才写入数据仓库。
(2)错误的数据:这一类错误产生的原因是业务系统不够健全,在接收输入后没有进行判断直接写入后台数据库造成的,比如数值数据输成全角数字字符、字符串数据后面有一个回车操作、日期格式不正确、日期越界等。这一类数据也要分类,对于类似于全角字符、数据前后有不可见字符的问题,只能通过写SQL语句的方式找出来,然后要求客户在业务系统修正之后抽取。日期格式不正确的或者是日期越界的这一类错误会导致ETL运行失败,这一类错误需要去业务系统数据库用SQL的方式挑出来,交给业务主管部门要求限期修正,修正之后再抽取。
(3)重复的数据:对于这一类数据——特别是维表中会出现这种情况——将重复数据记录的所有字段导出来,让客户确认并整理。
数据清洗是一个反复的过程,不可能在几天内完成,只有不断的发现问题,解决问题。对于是否过滤,是否修正一般要求客户确认,对于过滤掉的数据,写入Excel文件或者将过滤数据写入数据表,在ETL开发的初期可以每天向业务单位发送过滤数据的邮件,促使他们尽快地修正错误,同时也可以做为将来验证数据的依据。数据清洗需要注意的是不要将有用的数据过滤掉,对于每个过滤规则认真进行验证,并要用户确认。
2、数据转换
数据转换的任务主要进行不一致的数据转换、数据粒度的转换,以及一些商务规则的计算。
(1)不一致数据转换:这个过程是一个整合的过程,将不同业务系统的相同类型的数据统一,比如同一个供应商在结算系统的编码是XX0001,而在CRM中编码是YY0001,这样在抽取过来之后统一转换成一个编码。
(2)数据粒度的转换:业务系统一般存储非常明细的数据,而数据仓库中数据是用来分析的,不需要非常明细的数据。一般情况下,会将业务系统数据按照数据仓库粒度进行聚合。
(3)商务规则的计算:不同的企业有不同的业务规则、不同的数据指标,这些指标有的时候不是简单的加加减减就能完成,这个时候需要在ETL中将这些数据指标计算好了之后存储在数据仓库中,以供分析使用。
三、ETL日志、警告发送
1、ETL日志
ETL日志分为三类。一类是执行过程日志,这一部分日志是在ETL执行过程中每执行一步的记录,记录每次运行每一步骤的起始时间,影响了多少行数据,流水账形式。一类是错误日志,当某个模块出错的时候写错误日志,记录每次出错的时间、出错的模块以及出错的信息等。第三类日志是总体日志,只记录ETL开始时间、结束时间是否成功信息。如果使用ETL工具,ETL工具会自动产生一些日志,这一类日志也可以作为ETL日志的一部分。记录日志的目的是随时可以知道ETL运行情况,如果出错了,可以知道哪里出错。
2、警告发送
如果ETL出错了,不仅要形成ETL出错日志,而且要向系统管理员发送警告。发送警告的方式多种,一般常用的就是给系统管理员发送邮件,并附上出错的信息,方便管理员排查错误。
ETL是BI项目的关键部分,也是一个长期的过程,只有不断的发现问题并解决问题,才能使ETL运行效率更高,为BI项目后期开发提供准确的数据。
六、ngnix——负载均衡
Nginx版本:1.9.1
我的博客:http://blog.csdn.net/zhangskd
什么是负载均衡
我们知道单台服务器的性能是有上限的,当流量很大时,就需要使用多台服务器来共同提供服务,这就是所谓的集群。
负载均衡服务器,就是用来把经过它的流量,按照某种方法,分配到集群中的各台服务器上。这样一来不仅可以承担
更大的流量、降低服务的延迟,还可以避免单点故障造成服务不可用。一般的反向代理服务器,都具备负载均衡的功能。
负载均衡功能可以由硬件来提供,比如以前的F5设备。也可以由软件来提供,LVS可以提供四层的负载均衡(利用IP和端口),
Haproxy和Nginx可以提供七层的负载均衡(利用应用层信息)。
来看一个最简单的Nginx负载均衡配置。
-
http { -
upstream cluster { -
server srv1; -
server srv2; -
server srv3; -
} -
server { -
listen 80; -
location / { -
proxy_pass http://cluster; -
} -
} -
}
通过上述配置,Nginx会作为HTTP反向代理,把访问本机的HTTP请求,均分到后端集群的3台服务器上。
此时使用的HTTP反向代理模块是ngx_http_proxy_module。
一般在upstream配置块中要指明使用的负载均衡算法,比如hash、ip_hash、least_conn。
这里没有指定,所以使用了默认的HTTP负载均衡算法 - 加权轮询。
负载均衡流程图
在描述负载均衡模块的具体实现前,先来看下它的大致流程:
负载均衡模块
Nginx目前提供的负载均衡模块:
ngx_http_upstream_round_robin,加权轮询,可均分请求,是默认的HTTP负载均衡算法,集成在框架中。
ngx_http_upstream_ip_hash_module,IP哈希,可保持会话。
ngx_http_upstream_least_conn_module,最少连接数,可均分连接。
ngx_http_upstream_hash_module,一致性哈希,可减少缓存数据的失效。
以上负载均衡模块的实现,基本上都遵循一套相似的流程。
1. 指令的解析函数
比如least_conn、ip_hash、hash指令的解析函数。
这些函数在解析配置文件时调用,主要用于:
检查指令参数的合法性
指定peer.init_upstream函数指针的值,此函数用于初始化upstream块。
2. 初始化upstream块
在执行完指令的解析函数后,紧接着会调用所有HTTP模块的init main conf函数。
在执行ngx_http_upstream_module的init main conf函数时,会调用所有upstream块的初始化函数,
即在第一步中指定的peer.init_upstream,主要用于:
创建和初始化后端集群,保存该upstream块的数据
指定peer.init,此函数用于初始化请求的负载均衡数据
来看下ngx_http_upstream_module。
-
ngx_http_module_t ngx_http_upstream_module_ctx = { -
... -
ngx_http_upstream_init_main_conf, /* init main configuration */ -
... -
};
-
static char *ngx_http_upstream_init_main_conf(ngx_conf_t *cf, void *conf) -
{ -
... -
/* 数组的元素类型是ngx_http_upstream_srv_conf_t */ -
for (i = 0; i < umcf->upstreams.nelts; i++) { -
/* 如果没有指定upstream块的初始化函数,默认使用round robin的 */ -
init = uscfp[i]->peer.init_upstream ? uscfp[i]->peer.init_upstream : -
ngx_http_upstream_init_round_robin; -
if (init(cf, uscfp[i] != NGX_OK) { -
return NGX_CONF_ERROR; -
} -
} -
... -
}
3. 初始化请求的负载均衡数据块
当收到一个请求后,一般使用的反向代理模块(upstream模块)为ngx_http_proxy_module,
其NGX_HTTP_CONTENT_PHASE阶段的处理函数为ngx_http_proxy_handler,在初始化upstream机制的
函数ngx_http_upstream_init_request中,调用在第二步中指定的peer.init,主要用于:
创建和初始化该请求的负载均衡数据块
指定r->upstream->peer.get,用于从集群中选取一台后端服务器(这是我们最为关心的)
指定r->upstream->peer.free,当不用该后端时,进行数据的更新(不管成功或失败都调用)
请求的负载均衡数据块中,一般会有一个成员指向对应upstream块的数据,除此之外还会有自己独有的成员。
"The peer initialization function is called once per request.
It sets up a data structure that the module will use as it tries to find an appropriate
backend server to service that request; this structure is persistent across backend re-tries,
so it's a convenient place to keep track of the number of connection failures, or a computed
hash value. By convention, this struct is called ngx_http_upstream_
4. 选取一台后端服务器
一般upstream块中会有多台后端,那么对于本次请求,要选定哪一台后端呢?
这时候第三步中r->upstream->peer.get指向的函数就派上用场了:
采用特定的算法,比如加权轮询或一致性哈希,从集群中选出一台后端,处理本次请求。
选定后端的地址保存在pc->sockaddr,pc为主动连接。
函数的返回值:
NGX_DONE:选定一个后端,和该后端的连接已经建立。之后会直接发送请求。
NGX_OK:选定一个后端,和该后端的连接尚未建立。之后会和后端建立连接。
NGX_BUSY:所有的后端(包括备份集群)都不可用。之后会给客户端发送502(Bad Gateway)。
5. 释放一台后端服务器
当不再使用一台后端时,需要进行收尾处理,比如统计失败的次数。
这时候会调用第三步中r->upstream->peer.free指向的函数。
函数参数state的取值:
0,请求被成功处理
NGX_PEER_FAILED,连接失败
NGX_PEER_NEXT,连接失败,或者连接成功但后端未能成功处理请求
一个请求允许尝试的后端数为pc->tries,在第三步中指定。当state为后两个值时:
如果pc->tries不为0,需要重新选取一个后端,继续尝试,此后会重复调用r->upstream->peer.get。
如果pc->tries为0,便不再尝试,给客户端返回502错误码(Bad Gateway)。
在upstream模块的回调
负载均衡模块的功能是从后端集群中选取一台后端服务器,而具体的反向代理功能是由upstream模块实现的,
比如和后端服务器建立连接、向后端服务器发送请求、处理后端服务器的响应等。
我们来看下负载均衡模块提供的几个钩子函数,是在upstream模块的什么地方回调的。
Nginx的HTTP反向代理模块为ngx_http_proxy_module,其NGX_HTTP_CONTENT_PHASE阶段的处理函数为
ngx_http_proxy_handler,每个请求的upstream机制是从这里开始的。
-
ngx_http_proxy_handler -
ngx_http_upstream_create /* 创建请求的upstream实例 */ -
ngx_http_upstream_init /* 启动upstream机制 */ -
ngx_htp_upstream_init_request /* 负载均衡模块的入口 */ -
uscf->peer.init(r, uscf) /* 第三步,初始化请求的负载均衡数据块 */ -
... -
ngx_http_upstream_connect /* 可能会被ngx_http_upstream_next重复调用 */ -
ngx_event_connect_peer(&u->peer); /* 连接后端 */ -
pc->get(pc, pc->data); /* 第四步,从集群中选取一台后端 */ -
... -
/* 和后端建连成功后 */ -
c = u->peer.connection; -
c->data = r; -
c->write->handler = ngx_http_upstream_handler; /* 注册的连接的读事件处理函数 */ -
c->read->handler = ngx_http_upstream_handler; /* 注册的连接的写事件处理函数 */ -
u->write_event_handler = ngx_http_upstream_send_request_handler; /* 写事件的真正处理函数 */ -
u->read_event_handler = ngx_http_upstream_process_header; /* 读事件的真正处理函数 */
选定后端之后,在和后端通信的过程中如果发生了错误,会调用ngx_http_upstream_next来继续尝试其它的后端。
-
ngx_http_upstream_next -
if (u->peer.sockaddr) { -
if (ft_type == NGX_HTTP_UPSTREAM_FT_HTTP_403 || -
ft_type == NGX_HTTP_UPSTREAM_FT_HTTP_404) -
state = NGX_PEER_NEXT; -
else -
state = NGX_PEER_FAILED; -
/* 第五步,释放后端服务器 */ -
u->peer.free(&u->peer, u->peer.data, state); -
u->peer.sockaddr = NULL; -
}
Reference
[1]. http://www.evanmiller.org/nginx-modules-guide.html#proxying
[2]. http://tengine.taobao.org/book/chapter_05.html#id5
七、Redis
http://oldblog.csdn.net/column/details/24019.html
- 1. Redis是什么、特点、优势
- 2. redis安装(Linux)、启动、退出、设置密码、远程连接
- 3. Reis key
- 4. Redis数据类型
- 5. Redis HyperLogLog
- 6. Redis 发布订阅
- 7. Redis事务
- 8. Redis脚本
- 9. 数据备份与恢复
- 10. 数据库操作
- 11. 实际小应用
- 12. 关闭持久化
回到顶部
1. Redis是什么、特点、优势
Redis是一个开源的使用C语言编写、开源、支持网络、可基于内存亦可持久化的日志型、高性能的Key-Value数据库,并提供多种语言的API。
它通常被称为数据结构服务器,因为值(value)可以是 字符串(String)、哈希(Map)、 列表(list)、集合(sets) 和 有序集合(sorted sets)等类型。
Redis 与其他 key - value 缓存产品有以下三个特点:
- Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
Redis优势
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
回到顶部
2. redis安装(Linux)、启动、退出、设置密码、远程连接
2.1 安装redis
下载redis安装包(如:redis-2.8.17.tar.gz)
tar -zxvf redis-2.8.17.tar.gz
cd redis-2.8.17
make
sudo make install2.2 后台启动服务端
nohup redis-server &注:redis-server默认启动端口是6379,没有密码
如果不使用默认配置文件,启动时可以加上配置文件
nohup redis-server ~/soft/redis-2.8.17/redis.conf &
2.3 启动客户端、验证

127.0.0.1:6379> ping
PONG
127.0.0.1:6379> set var "hello world"
OK
127.0.0.1:6379> get var
"hello world"
2.4 退出
关闭redis-server
redis-cli shutdown例子
$ps -ef | grep redis
root 23422 19813 0 10:59 pts/5 00:00:08 redis-server *:6379
$sudo redis-cli shutdown
[23422] 05 Mar 12:11:29.301 # User requested shutdown...
[23422] 05 Mar 12:11:29.301 * Saving the final RDB snapshot before exiting.
[23422] 05 Mar 12:11:29.314 * DB saved on disk
[23422] 05 Mar 12:11:29.314 # Redis is now ready to exit, bye bye...
[1]+ Done sudo redis-server (wd: ~/soft/redis-2.10.3)
(wd now: ~/soft/redis-2.8.17)
$ps -ef | grep redis
jihite 30563 19813 0 12:11 pts/5 00:00:00 grep redis
注:如果设置上密码后,单纯的redis-cli是关不掉的,必须加上ip、port、passwd
sudo redis-cli -h host -p port -a passwd shutdown退出客户端
localhost:6379> QUIT
2.5 设立密码
打开redis.conf找到requirepass,去掉默认,修改
requirepass yourpassword验证密码的正确性
localhost:6379> auth jihite
OK
2.6 远程连接
需要已经安装redis,可以使用redis-cli命令
redis-cli -h host -p port -a password
2.7 查看redis-server统计信息
INFO回到顶部
3. Reis key
Redis是key-value的数据库,Redis的键用于管理Redis的键,基本语法是
COMMAND KEY_NAME例子:
localhost:6379> SET var redis
OK
localhost:6379> GET var
"redis"
localhost:6379> DEL var
(integer) 1
localhost:6379> GET var
(nil)
注:redis命令不区分大小写,所以get var和GET var是等价的
| 序号 | Redis keys命令及描述 |
|---|---|
| 1 | DEL key 该命令用于在 key 存在是删除 key。 |
| 2 | DUMP key 序列化给定 key ,并返回被序列化的值。 |
| 3 | EXISTS key 检查给定 key 是否存在。 |
| 4 | EXPIRE key seconds 为给定 key 设置过期时间。 |
| 5 | EXPIREAT key timestamp EXPIREAT 的作用和 EXPIRE 类似,都用于为 key 设置过期时间。 不同在于 EXPIREAT 命令接受的时间参数是 UNIX 时间戳(unix timestamp)。 |
| 6 | PEXPIRE key milliseconds 设置 key 的过期时间亿以毫秒计。 |
| 7 | PEXPIREAT key milliseconds-timestamp 设置 key 过期时间的时间戳(unix timestamp) 以毫秒计 |
| 8 | KEYS pattern 查找所有符合给定模式( pattern)的 key 。例如keys * 返回所有的key |
| 9 | MOVE key db 将当前数据库的 key 移动到给定的数据库 db 当中。 |
| 10 | PERSIST key 移除 key 的过期时间,key 将持久保持。 |
| 11 | PTTL key 以毫秒为单位返回 key 的剩余的过期时间。 |
| 12 | TTL key 以秒为单位,返回给定 key 的剩余生存时间(TTL, time to live)。 |
| 13 | RANDOMKEY 从当前数据库中随机返回一个 key 。 |
| 14 | RENAME key newkey 修改 key 的名称 |
| 15 | RENAMENX key newkey 仅当 newkey 不存在时,将 key 改名为 newkey 。 |
| 16 | TYPE key 返回 key 所储存的值的类型。 |
回到顶部
4. Redis数据类型
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
4.1 String(字符串)
- 是Redis最基本的数据类型,可以理解成与Memcached一模一样的类型,一个key对应一个value
- 二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或者序列化的对象
- 一个键最大能存储512MB
例子
127.0.0.1:6379> set var "String type"
OK
127.0.0.1:6379> get var
"String type"说明:利用set给变量var赋值“String type”;利用get获得变量var的值
4.2 Hash(哈希)
- 是一个键值对集合
- 是一个string类型的field和value的映射表,hash特别适合用于存储对象
hset,hget例子
127.0.0.1:6379> hget set1 name
"jihite"
127.0.0.1:6379> hget set1 score
"100"
127.0.0.1:6379> hset set2 name jihite2
(integer) 1
127.0.0.1:6379> hset set2 score 110
(integer) 1
127.0.0.1:6379> hget set1 name
"jihite"
hset&hget一次只能往哈希结构里面插入一个键值对,如果插入多个可以用hmset&hmget
hmset, hmget例子
127.0.0.1:6379> HMSET var:1 name jihite school pku
OK
127.0.0.1:6379> HGETALL var:1
1) "name"
2) "jihite"
3) "school"
4) "pku"
说明
var:1是键值,每个 hash 可以存储 232 - 1 键值对(40多亿)
HMSET用于建立hash对象,HGETALL用于获取hash对象
hset v.s. hmset操作对比
127.0.0.1:6379> hset set5 name1 jihite1 name2 jihite2 name3 jihite3
(error) ERR wrong number of arguments for 'hset' command
127.0.0.1:6379> hmset set5 name1 jihite1 name2 jihite2 name3 jihite3
OK
127.0.0.1:6379> hget set5 name1
"jihite1"
127.0.0.1:6379> hmget set5 name1
1) "jihite1"
127.0.0.1:6379> hmget set5 name1 name2
1) "jihite1"
2) "jihite2"
127.0.0.1:6379> hget set5 name1 name2
(error) ERR wrong number of arguments for 'hget' command
4.3 LIST(列表)
例子
127.0.0.1:6379> lpush lvar 1
(integer) 1
127.0.0.1:6379> lpush lvar a
(integer) 2
127.0.0.1:6379> lpush lvar ab
(integer) 3
127.0.0.1:6379> lrange lvar 0 1
1) "ab"
2) "a"
127.0.0.1:6379> lrange lvar 0 10
1) "ab"
2) "a"
3) "1"
127.0.0.1:6379> lrange lvar 2 2
1) "1"
说明
lpush往列表的前边插入;lrange后面的数字是范围(闭区间)
列表最多可存储 232 - 1 元素 (4294967295, 每个列表可存储40多亿)。
4.4 Set(集合)
Redis的Set是string类型的无序集合。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)
例子
127.0.0.1:6379> sadd setvar redis
(integer) 1
127.0.0.1:6379> sadd setvar mongodb
(integer) 1
127.0.0.1:6379> sadd setvar mongodb
(integer) 0
127.0.0.1:6379> sadd setvar rabbitmq
(integer) 1
127.0.0.1:6379> smembers setvar
1) "rabbitmq"
2) "redis"
3) "mongodb"
说明
set往集合中插入元素,smembers列举出集合中的元素
成功插入返回1;错误插入返回0,例子中mongodb第二次插入时,因已经存在,故插入失败。
4.5 zset(sorted sete:有序集合)
zset和set一样也是String类型的集合,且不允许元素重复
zset和set不同的地方在于zset关联一个double类型的分数,redis通过分数对集合中的元素排序
zset的元素是唯一的,但是分数是可以重复的
例子
127.0.0.1:6379> zadd zvar 1 redis
(integer) 1
127.0.0.1:6379> zadd zvar 1 redis
(integer) 0
127.0.0.1:6379> zadd zvar 2 redis
(integer) 0
127.0.0.1:6379>
127.0.0.1:6379> zadd zvar 2 mongo
(integer) 1
127.0.0.1:6379> zadd zvar 0 rabbitmq
(integer) 1
127.0.0.1:6379>
127.0.0.1:6379> ZRANGEBYSCORE zvar 0 1000
1) "rabbitmq"
2) "mongo"
3) "redis"
127.0.0.1:6379>
127.0.0.1:6379>
127.0.0.1:6379> zadd zvar -2 celery
(integer) 1
127.0.0.1:6379> ZRANGEBYSCORE zvar 0 1000
1) "rabbitmq"
2) "mongo"
3) "redis"
127.0.0.1:6379> ZRANGEBYSCORE zvar -3 1000
1) "celery"
2) "rabbitmq"
3) "mongo"
4) "redis"
说明
成功插入返回1,否则返回0。插入已存在元素失败--返回0
分数为float(可正、负、0)
回到顶部
5. Redis HyperLogLog
Redis HyperLogLog是用来做基数统计的算法。优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
注:因为HyperLogLog只会根据输入元素来计算基数,而不会存储输入元素本身,因此不会返回输入的各个元素。
基数是什么? 对于["abc", "abc", "2", "3"],基数是["abc", "2", "3"],个数是3.
例子
localhost:6379> pfadd jsh redis
(integer) 1
localhost:6379> pfadd jsh redis
(integer) 0
localhost:6379> pfadd jsh mongodb
(integer) 1
localhost:6379> pfadd jsh rabbitmq
(integer) 1
localhost:6379> pfcount jsh
(integer) 3
localhost:6379> pfadd jsh2 redis
(integer) 1
localhost:6379> pfadd jsh2 a
(integer) 1
localhost:6379> pfcount jsh2
(integer) 2
localhost:6379> pfmerge jsh jsh2
OK
localhost:6379> pfcount jsh
(integer) 4
localhost:6379> pfcount jsh2
(integer) 2
说明:
- pfadd key ele [ele2 ...]:添加指定元素到HyperLogLog中,
- pfcount key: 返回给定HyperLogLog的基数估算值
- pfmerge destkey srckey [srckey2....]:讲多个HyperLogLog合并到一个第一个HyperLogLog中
回到顶部
6. Redis 发布订阅
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
Redis 客户端可以订阅任意数量的频道。
原理:下图展示了三个客户端client1, client2, client5订阅了频道channel1

当有新消息通过PUBLISH发送给channel1时,这时候channel1就会把消息同时发布给订阅者

例子
创建订阅频道redisChat
localhost:6379> subscribe redisChat
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "redisChat"
3) (integer) 1打开几个客户端,订阅channel redisChat
localhost:6379> psubscribe redisChat
Reading messages... (press Ctrl-C to quit)
1) "psubscribe"
2) "redisChat"
3) (integer) 1然后给channel redisChat发送消息“Hello World”
localhost:6379> publish redisChat "Hello World"
(integer) 1客户端会收到消息
Reading messages... (press Ctrl-C to quit)
1) "pmessage"
2) "redisChat"
3) "redisChat"
4) "Hello World"回到顶部
7. Redis事务
事务是一个单独的操作集合,事务中的命令有顺序,是一个原子操作(事务中的命令要么全部执行,要么全部不执行),执行一个事务中的命令时不会被其他命令打断。
一个事务从开始到结束经过以下三个阶段:
- 开始事务
- 命令入队
- 执行事务
例子
localhost:6379> MULTI
OK
localhost:6379> set name jihite
QUEUED
localhost:6379> get name
QUEUED
localhost:6379> sadd language "c++" "python" "java"
QUEUED
localhost:6379> smembers language
QUEUED
localhost:6379> exec
1) OK
2) "jihite"
3) (integer) 3
4) 1) "java"
2) "python"
3) "c++"
说明:事务以MULTI开始,以EXEC结束
回到顶部
8. Redis脚本
Redis 脚本使用 Lua 解释器来执行脚本。执行脚本的常用命令为 EVAL。基本语法
EVAL script numkeys key [key ...] arg [arg ...]例子
localhost:6379> EVAL "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1 key2 first second
1) "key1"
2) "key2"
3) "first"
4) "second"回到顶部
9. 数据备份与恢复
数据备份
localhost:6379> save
OK改命令会在redis的安装目录中创建文件dump.rdb,并把数据保存在该文件中。
查看redis的安装目录
localhost:6379> config get dir
1) "dir"
2) "/home/jihite/soft/redis-2.8.17"
数据恢复
只需将备份文件dump.rdb拷贝到redis的安装目录即可。
回到顶部
10. 数据库操作
Redis中,一共有16个数据库,分别是0~15,一般情况下,进入数据库默认编号是0,如果我们要进入指定数据库,可以用select语句
切换到编号为3的数据库
localhost:6379> select 3
OK
localhost:6379[3]>查看数据库中所有的键值
localhost:6379[1]> set a 1
OK
localhost:6379[1]> set b 2
OK
localhost:6379[1]> keys *
1) "b"
2) "a"
返回当前数据库中所有key的数目: dbsize
删除当前数据库中的所有key: flushdb
清空所有数据库中的所有key: flushall
把当前数据库中的key转移到指定数据库:move a aim_db,例:
localhost:6379[1]> set z sss
OK
localhost:6379[1]> move z 0
(integer) 1
localhost:6379[1]> select 0
OK
localhost:6379> get z
"sss"
回到顶部
11. 实际小应用
http://www.aboutyun.com/thread-12613-1-1.html
回到顶部
12. 关闭持久化
数据持久化是Redis不同于其他缓存的一个特性,具有明显的有点。但如不希望持久化数据,只作为普通的缓存用,如memcache
方法:
修改配置文件,改完后重启。
#save 900 1
#save 300 10
#save 60 10000 或执行操作命令
CONFIG SET save ""执行命令后,无需重启即可生效
八、Oracle
Oracle数据库操作基本语法
创建表
SQL>create table classes(
classId number(2),
cname varchar2(40),
birthday date
);
添加一个字段
SQL>alter table student add (classId number(2));
修改字段长度
SQL>alter table student modify(xm varchar2(30));
修改字段的类型/或是名字(不能有数据)
SQL>alter table student modify(xm char(30));
删除一个字段
SQL>alter table student drop column sal;
修改表的名字
SQL>rename student to stu;
删除表
SQL>drop table student;
插入所有字段数据
SQL>insert into student values (‘001’,’salina’,’女’,’01-5月-05’,10);
修改日期输入格式
SQL>alter session set nls_date_format = ‘yyyy-mm-dd’; //临时生效,重启后不起错用
SQL>insert into student values (‘001’,’salina’,’女’,to_date(’01-5 -05’,’yyyy-mm-dd’),10);
SQL>insert into student values (‘001’,’salina’,’女’,to_date(’01/5 -05’,’yyyy/mm/dd’),10);
插入部分字段
SQL>insert into student (xh,xm,sex) values(‘001’,’lison’,’女’);
插入空值
SQL>insert into student (xh,xm,sex,birthday) values(‘021’,’BLYK’,’男’,null);
一条插入语句可以插入多行数据
SQL> insert into kkk (Myid,myname,mydept) select empno ,ename,deptno from emp where deptno=10;
查询空值/(非空)的数据
SQL>select * from student where brithday is null(/not null);
修改(更新)数据
SQL>update student set sal=sql/2 where sex =’男’;
更改多项数据
SQL> update emp set (job,sal,comm)=(select job,sal,comm from emp where ename='SMITH') where ename='SCOTT';
删除数据
- 1. 保存还原点
SQL>savepoint aa;
- 2. 删除数据
【1】 SQL>delete from student; //删除表的数据
【2】 SQL>drop table student; //删除表的结构和数据
【3】 SQL>delete from student where xh=’001’; //删除一条记录
【4】 SQL>truncate table student; //删除表中的所有记录,表结构还在,不写日志,无法扎找回的记录,速度快
查看表结构
SQL>desc student;
查询指定列
SQL>select sex,xh,xm from student;
如何取消重复
SQL>select distinct deptno,job from student;
打开显示操作时间的开关
SQL>set timing on;
为表格添加大的数据行(用于测试反应时间)
SQL>insert into users (userid,username,userpss) select * from users;
统计表内有多少条记录
SQL>select count(*) from users;
屏蔽列内相同数据
SQL>select distinct deptno,job from emp;
查询指定列的某个数据相关的数据
SQL>select deptno,job,sal from emp where ename=’smith’;
使用算数表达式
SQL>select sal*12 from emp;
使用类的别名
SQL>select ename “姓名”,sal*12 as “年收入” from emp;
处理null(空)值
SQL>select sal*13+nvl(comm,0)*13 “年工资”,ename,comm from emp;
连接字符串(||)
SQL>select ename || ‘is a’ || job from emp;
Where子句的使用
【1】SQL>select ename,sal from emp where sal>3000; //number的范围确定
【2】SQL>select ename,hiredate from emp where hiredate>’1-1月-1982’; //日期格式的范围确定
【3】SQL>select ename,sal from emp where sal>=2000 and sal<=2500; //组合条件
Like操作符:’%’、’_’
SQL>select ename,sal from emp where ename like ‘S%’; //第一个字符【名字第一个字符为S的员工的信息(工资)】
SQL>select ename,sal from emp where ename like ‘__O%’; //其它字符【名字第三个字符为O的员工的信息(工资)】
批量查询
SQL>select * from emp where in(123,456,789); //查询一个条件的多个情况的批量处理
查询某个数据行的某列为空的数据的相关数据
SQL >select * from emp where mgr is null;
条件组合查询(与、或)
SQL>select * from emp where (sal>500 or job=’MANAGER’) and ename like ‘J%’;
Order by 排序
【1】SQL>select * from emp order by sal (asc); //从低到高[默认]
【2】SQL>select * from emp order by sal desc; //从高到低
【3】SQL>select * from emp order by deptno (asc),sal desc; //组合排序
【4】SQL>select ename,sal*12 “年薪” from emp order by “年薪” (asc);
SQL> select ename,(sal+nvl(comm,0))*12 as "年薪" from emp order by "年薪";
资料分组(max、min、avg、sum、count)
SQL>select max(sal),min(sal) from emp;
SQL>select ename,sal from emp where sal=(select max(sal) from emp); //子查询,组合查询
SQL> select * from emp where sal>(select avg(sal) from emp); //子查询,组合查询
SQL> update emp set sal=sal*1.1 where sal<(select avg(sal) from emp) and hiredate<'1-1月-1982'; //将工资小于平均工资并且入职年限早于1982-1-1的人工资增加10%
Group by 和 having 子句
//group by用于对查询出的数据进行分组统计
//having 用于限制分组显示结果
SQL>select avg(sal),max(sal),deptno from emp group by deptno; //显示每个部门的平均工资和最低工资
SQL>select avg(sal),max(sal),deptno from emp group by deptno; //显示每个部门的平均工资和最低工资
SQL> select avg (sal),max(sal),deptno from emp group by deptno having avg(sal)>2000;
SQL> select avg (sal),max(sal),deptno from emp group by deptno having avg(sal)>2000 order by avg(sal);
多表查询
笛卡尔集:规定多表查询的条件是至少不能少于:表的个数-1
SQL> select a1.ename,a1.sal,a2.dname from emp a1,dept a2 where a1.deptno=a2.deptno;
SQL> select a1.dname,a2.ename,a2.sal from dept a1,emp a2 where a1.deptno=a2.deptno and a1.deptno=10; //显示部门编号为10的部门名、员工名和工资
SQL> select a1.ename,a1.sal,a2.grade from emp a1,salgrade a2 where a1.sal between a2.losal and a2.hisal;
SQL> select a1.ename,a1.sal,a2.dname from emp a1,dept a2 where a1.deptno=a2.deptno order by a1.deptno; //多表排序
SQL> select worker.ename,boss.ename from emp worker,emp boss where worker.mgr=boss.empno; // 自连接(多表查询的特殊情况)
SQL> select worker.ename,boss.ename from emp worker,emp boss where worker.mgr=boss.empno and worker.ename='FORD';
子查询
SQL> select * from emp where deptno=(select deptno from emp where ename='SMITH');
SQL> select distinct job from emp where deptno=10;
SQL> select * from emp where job in (select distinct job from emp where deptno=10);
// 如何查询和部门10的工作相同的雇员的名字、岗位、工资、部门号。
SQL> select ename ,sal,deptno from emp where sal>all (select sal from emp where deptno=30);//如何查询工资比部门30的所有员工的工资高的员工的姓名、工资和部门号
SQL> select ename ,sal,deptno from emp where sal>(select max(sal) from emp where deptno=30);
SQL> select * from emp where (deptno,job)=(select deptno,job from emp where ename='SMITH');
内嵌视图
//当在from子句中使用子查询的时候,必须给子查询指定别名
SQL>select a2.ename,a2.sal,a2.deptno,a1.mysal from emp a2,(select deptno,avg(sal) (as ) mysal from emp group by deptno) a1 where a2.deptno=a1.deptno and a2.sal>a1.mysal;
分页
SQL >select a1.*,rownum rn from (select * from emp) a1;//orcle为表分配的行号
SQL> select * from (select a1.*,rownum rn from (select * from emp) a1 where rownum<=10) where rn>=6;
//查询内容的变化
- 所有的改动(指定查询列)只需更改最里面的子查询
- (排序)只需更改最里面的子查询
子查询(用查询结果创建新表)
SQL> create table mytable (id,name,sal,job,deptno) as select empno,ename,sal,job,deptno from emp;
合并查询
union(求并集), union all , intersect(取交集), minus (差集)
SQL> select ename,sal,job from emp where sal>2500;
SQL> select ename,sal,job from emp where job='MANAGER';
SQL> select ename,sal,job from emp where sal>2500 union select ename,sal,job from emp where job='MANAGER'; // union(求并集)
Java连接数据库
事务
SQL>commit; //事务 (第一次创建,第二次提交)当退出数据库时,系统自动提交事务
SQL>savepoint a1; //创建保存点 (保存点的个数没有限制)
SQL>rollback to aa; //使用保存点回滚到aa
SQL>rollback; //回滚到事务创建开始
只读事务
SQL>set transaction read only
Java中的事务
Ct.setAutoCommit(false); //设置事务自动提交为否
Ct.commit(); //提交事务
字符函数
lower(char)将字符串转换为小写的格式
upper(char)将字符串装换为大写的格式
length(char)返回字符串的长度
substr(char,m,n)取字符串的子串
SQL>select lower(ename) from emp;
SQL>select ename from emp where length(ename)=5;
Oracle中如何获取系统当前时间
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') from dual;
ORACLE里获取一个时间的年、季、月、周、日的函数
select to_char(sysdate, 'yyyy' ) from dual; --年
select to_char(sysdate, 'MM' ) from dual; --月
select to_char(sysdate, 'dd' ) from dual; --日
select to_char(sysdate, 'Q') from dual; --季
select to_char(sysdate, 'iw') from dual; --周--按日历上的那种,每年有52或者53周
/*
hh 小时(12)
hh24 小时(24)
Mi 分
ss 秒
D 周中的星期几
ddd 年中的第几天
WW 年中的第几个星期
W 该月中第几个星期 --每年的1月1号至1月7号为第一周,以此类推,每年53周
*/
获取系统日期: SYSDATE()
格式化日期:
TO_CHAR(SYSDATE(),'YY/MM/DD HH24:MI:SS)
或 TO_DATE(SYSDATE(),'YY/MM/DD HH24:MI:SS)
select to_char(sysdate,'yyyy-MM-dd HH24:mi:ss') from dual;
select to_char(sysdate,'yyyy-MM-dd HH24:mm:ss') from dual;
select to_char(sysdate,'yy-mm-dd hh24:mi:ss') from dual
select to_date('2009-12-25 14:23:31','yyyy-mm-dd,hh24:mi:ss') from dual
而如果把上式写作:
select to_date('2009-12-25 14:23:31','yyyy-mm-dd,hh:mi:ss') from dual
则会报错,因为小时hh是12进制,14为非法输入,不能匹配。
转换的格式:
表示 year 的:
y 表示年的最后一位 、
yy 表示年的最后2位 、
yyy 表示年的最后3位 、
yyyy 用4位数表示年
表示month的:
mm 用2位数字表示月 、
mon 用简写形式, 比如11月或者nov 、
month 用全称, 比如11月或者november
表示day的:
dd 表示当月第几天 、
ddd 表示当年第几天 、
dy 当周第几天,简写, 比如星期五或者fri 、
day 当周第几天,全称, 比如星期五或者friday
表示hour的:
hh 2位数表示小时 12进制 、
hh24 2位数表示小时 24小时
表示minute的:
mi 2位数表示分钟
表示second的:
ss 2位数表示秒 60进制
表示季度的:
q 一位数 表示季度 (1-4)
另外还有ww 用来表示当年第几周 w用来表示当月第几周。
当前时间减去7分钟的时间
select sysdate,sysdate - interval '7' MINUTE from dual;
当前时间减去7小时的时间
select sysdate - interval '7' hour from dual;
当前时间减去7天的时间
select sysdate - interval '7' day from dual;
当前时间减去7月的时间
select sysdate,sysdate - interval '7' month from dual;
当前时间减去7年的时间
select sysdate,sysdate - interval '7' year from dual;
时间间隔乘以一个数字
select sysdate,sysdate - 8*interval '7' hour from dual;
select to_char(sysdate,'yyyy-mm-dd:hh24:mi:ss:pm:dy') from dual;
年 月 日 24制小时 分 秒 上/下午 星期中文;
--获取11月天数--select to_char(last_day(to_date('2010-11-1','YYYY-MM-DD')),'DD') from dual;
--获取12月天数--select to_char(last_day(to_date('2010-12-1','YYYY-MM-DD')),'DD') from dual;
显示上个礼拜一到礼拜日 SELECT to_char(SYSDATE,'yyyymmdd')-to_number(to_char(SYSDATE,'d')-1) - 6, to_char(SYSDATE,'yyyymmdd')-to_number(to_char(SYSDATE,'d')-1) from dual
九、Jsp/node.js/JQueryEcharts前端
- JavaScript是一种脚本编程语言,常用在浏览器前端页面动态效果实现,而Node.js提供一整套服务器端JavaScript运行时环境,使JavaScript语言可以实现类似PHP的服务器端编程。
- Electron是跨平台的桌面应用开发框架,编程语言是JavaScript,需要Node.js\Chrominum\V8等开源组件支持,使JavaScript能够像.net、java一样可以开发桌面应用。
- JQuery是纯粹的JavaScript类库,封装常用的JavaScript功能代码,简化原始JavaScript的前端编程,但类库距离实现应用仍需要大量的代码;
- Vue.js、Angular.js等是前端JavaScript开发框架,快速实现前端Web应用,提供更加简洁的语法,实现HTML的动态效果,对HTML5、移动设备支持较好,重点解决JavaScript通过DOM操作HTML实现动态效果的复杂性。
JavaScript语言
- JavaScript是解释性脚本语言,具备动态性、弱类型、基于原型(面向对象)等特点;
-
JavaScript重要历史,从历史看语言功能和设计初衷:
- 1995年,网景在在浏览器Netscape中首次实现,目的是实现网页前端动态效果;随后微软等浏览器厂商均采用模仿实现;
- 1996,网景提交标准组织ECMA,1997年发布ECMA-262标准,统一语言语法和基本对象;现在最新为ECMASCript 2017;
- 小插曲:1995.12,网景公司推出Server-side JavaScript,可以运行在Netscape Enterprise Server;
-
因此,可以得出结论:
- JavaScript本质上是一种脚本语言和编程语言;运行环境或者解释器是内置在浏览器中的,传统应用领域局限在前端配合网页实现动态效果的;
- 网景公司很早已经探索将JavaScript变成通用的脚本语言,并且可以用在服务器端,可惜后来在浏览器大战中被打败;
- JavaScript专注于前端网页动态交互领域,与浏览器紧密相关,脚本解释器内置在浏览器实现中;其它脚本语言提供单独的解释器;
- JavaScript作为编程语言,提供相应的运行环境(解释器或者编译器),完全可能在服务器端运行,不局限于客户端。
Node.js运行环境
- Node.js是一个基于Chrome V8引擎的JavaScript运行时环境(2009.,Chrome V8是谷歌浏览器内置的JavaScript脚本引擎(2008.9发布);
- Node.js是运行环境,提供JavaScript编写服务器程序的独立运行平台,该平台的编程语言是JavaScript;
- Node.js于2009年创建,距离网景1995年发布第一个JavaScript服务器端运行环境,时隔13年;
- Node.js平台提供服务器端编程所需要的各种编程库或模块,实现类似PHP、JSP等服务器页面编程技术功能;
Electron桌面应用开发框架
- Electron提供一整套工具用来开发跨平台的桌面应用,可以开发Windows、Mac、Linux等平台的桌面应用,类似.Net Framework、Java桌面应用开发;
- Electron平台开发语言是JavaScript,界面采用HTML+CSS实现,运行环境依赖Node.js,Chrominum,V8,Node.js和Chromium共享同一个V8脚本引擎实例;
- Node.js作为后端运行环境,可以实现网络、文件IO、GUI等系统原生功能;Chrominm+V8作为前端运行环境,可以实现网页和JavaScript脚本的运行显示;
- Electron可以使用JavaScript调用原生操作系统API来构建桌面应用,在Node.js支持下,实现在网页中直接与操作系统底层API交互。
JQuery是前端JavaScript类库
- JQuery等是JavaScript类库,本质上只是运用JavaScript编写封装的脚本文件,和我们自己的写JavaScript脚本没有区别,运行在前端,浏览器都支持,不依赖任何库或者组件;
- JQuery前端库,解决JavaScript编程繁琐等问题,直接将常用的JavaScript功能封装,另外对多版本的浏览器兼容性较好;
- 使用JQuery,可以方便实现网页的动态效果,但因为仅仅是库,仍需要手工实现大量的JS脚本自己的需求,实现层次仍然较低;
- 2006年发布。
Vue.js\Angular.js等前端开发框架
- Vue.js\Angular.js同样是JavaScript编写的前端开发框架,提供类似应用模板,开发者只需要加入自己的业务逻辑,基础的功能框架均已经实现;
- 因为是前端开发框架,不依赖第三方,只需要浏览器均可以运行;
- 框架扩展了HTML的功能,弥补HTML构建动态网页的不足,例如Angular.js只利用指令扩展HTML,实现数据与显示等绑定;
- 使用Angularjs等开发框架,利用声明式的语法(HTML标签中混合JS功能,类似JSP、PHP服务器脚本的写法)可以快速实现常用的数据与显示绑定、验证等Web应用功能;
- 支持HTML5应用,对移动设备支持效果较好;
- Angular.js 2009年发布。