RNN之seq2seq模型
1.RNN模型概述
RNN大致可以分为4种,输出和输入序列不同数量rnn可以有多种不同的结构,不同结构自然就有不同的引用场合。
如下图所示:

one to one 结构: 仅仅只是简单的给一个输入得到一个输出,此处并未体现序列的特征,例如图像分类场景。
one to many 结构:给一个输入得到一系列输出,这种结构可用于生产图片描述的场景。
many to one 结构: 给一系列输入得到一个输出,这种结构可用于文本情感分析,对一些列的文本输入进行分类,看是消极还是积 极情感。
many to many 结构: 给一些列输入得到一系列输出,这种结构可用于翻译或聊天对话场景,对输入的文本转换成另外一些列文本。
同步 many to many 结构: 它是经典的rnn结构,前一输入的状态会带到下一个状态中,而且每个输入都会对应一个输出,我们最熟悉的就是用于字符预测了,同样也可以用于视频分类,对视频的帧打标签。
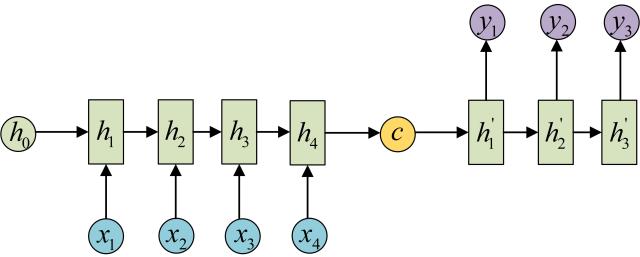
2.seq2seq 简介
seq2seq是一个重要的RNN变种,属于many to many。同时这种结构又叫Encoder-Decoder模型。原始的N vs N RNN要求序列等长,然而我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。
为此,我们先用Encoder 将输入编码映射到语义空间(下图左侧部分),得到一个个固定维数的向量(下图C),这个向量就表示输入的语义。然后我们使用Decoder进行解码,便获得所需的输出。
它的特点很明显,就是不限制输入输出,故有很广泛的应用。如机器翻译,智能对话等。
3. seq2seq预测股票
我们利用seq2seq对股票收盘价进行了预测,关于代码的详细说明,参见注释,需要数据的同学可以加我qq,请备注csdn_seq2seq。
# -*- coding: utf-8 -*-
"""
seq2seq stock
"""
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
'''
1.样本数据产生
'''
#pandas 链式赋值警告:a=b=c=1,凡事出现链式赋值的情况,
#pandas都是不能够确定到底返回的是一个引用还是一个拷贝。 所以遇到这种情况就干脆报warning
pd.options.mode.chained_assignment = None # default='warn'
def loadstock(window_size):
names = ['date', #日期
'code', #股票代码
'name', #名字
'Close', # 收盘价
'top_price', #最高价
'low_price', #最低价
'opening_price', #开盘价
'bef_price',
'floor_price',
'floor',
'exchange',
'Volume',
'amount',
'总市值',
'流通市值']
data = pd.read_csv('600000.csv', names=names, header=None,encoding = "gbk")
#predictor_names = ["Close",'top_price',"low_price","opening_price"]
predictor_names = ["Close"] #预测收盘价,当然可以用来预测多个
training_features = np.asarray(data[predictor_names], dtype = "float32")#asarray,不占内存等同于array
kept_values = training_features[1000:] #取1000以后的
X = [] ## x ;前window_size天,输入数据
Y = [] #y后window_size天 作为标注结果
for i in range(len(kept_values) - window_size * 2):
X.append(kept_values[i:i + window_size]) #每一组40个
Y.append(kept_values[i + window_size:i + window_size * 2])
X = np.reshape(X,[-1,window_size,len(predictor_names)]) #len(predictor 可能是要预测多个时候有用
Y = np.reshape(Y,[-1,window_size,len(predictor_names)])
print(np.shape(X))
return X, Y
X_train = []
Y_train = []
X_test = []
Y_test = []
def generate_data(isTrain, batch_size):
# 生成40个样本,预测后40个样本
seq_length = 40 #window_size
seq_length_test = 80
global Y_train
global X_train
global X_test
global Y_test
# 训练集
if len(Y_train) == 0:
X, Y= loadstock( window_size=seq_length)
#X, Y = normalizestock(X, Y)
# Split 80-20:
X_train = X[:int(len(X) * 0.8)]
Y_train = Y[:int(len(Y) * 0.8)]
#测试集
if len(Y_test) == 0:
X, Y = loadstock( window_size=seq_length_test) #测试集为什么用80?
#X, Y = normalizestock(X, Y)
X_test = X[int(len(X) * 0.8):]
Y_test = Y[int(len(Y) * 0.8):]
if isTrain:
return do_generate_x_y(X_train, Y_train, batch_size)
else:
return do_generate_x_y(X_test, Y_test, batch_size)
def do_generate_x_y(X, Y, batch_size):
#在没完善一个程序之前,我们不知道程序在哪里会出错,与其让它在运行最崩溃,
#不如在出现错误条件时就崩溃,这时候就需要assert断言的帮助。能起到提前报错的作用
assert X.shape == Y.shape, (X.shape, Y.shape) #如果这里不等于,则直接报错就不执行下去了
idxes = np.random.randint(X.shape[0], size=batch_size) #产生随机整数,不相等的
X_out = np.array(X[idxes]).transpose((1, 0, 2)) #0,1,列互换,输出数据:[batch_size,windows_size,value]
Y_out = np.array(Y[idxes]).transpose((1, 0, 2)) # ------->[windows_size,batch_szie,value ]
return X_out, Y_out #是训练需要吗?
sample_now, sample_f = generate_data(isTrain=True, batch_size=3)
print("training examples : ")
print(sample_now.shape)
print("(seq_length, batch_size, output_dim)")
'''
2. 定义模型框架
'''
seq_length = sample_now.shape[0]
batch_size = 100
output_dim = input_dim = sample_now.shape[-1] #decoder输出维度,需要预测一个就输出一个就好了,需要预测的就一个
hidden_dim = 12 #每一层有12个gru
layers_num = 2 #两层
#Optmizer:
learning_rate =0.04
nb_iters = 10000
lambda_l2_reg = 0.003 # L2正则化系数
tf.reset_default_graph()
encoder_input = [] #encoder 输入
expected_output = [] #中间,在feed_dict中间输入进去
decode_input =[] #decode输出
#占位符,encoder,middle,decode
for i in range(seq_length):#windows_size个占位符,每个占位符里面是数据
encoder_input.append( tf.placeholder(tf.float32, shape=( None, input_dim))) #[40,bacht_size,1]的占位符
expected_output.append( tf.placeholder(tf.float32, shape=( None, output_dim)) )
decode_input.append( tf.placeholder(tf.float32, shape=( None, input_dim)) )
#定义网络结构 ,seq2seq
tcells = [] #定义了两层循环网络,每层12个GRUcell
for i in range(layers_num):
tcells.append(tf.contrib.rnn.GRUCell(hidden_dim))
#多层RNN实现
Mcell = tf.contrib.rnn.MultiRNNCell(tcells)
dec_outputs, dec_memory = tf.contrib.legacy_seq2seq.basic_rnn_seq2seq(encoder_input,decode_input,Mcell)
#最后结果全连接输出???? 没看太懂
reshaped_outputs = []
for ii in dec_outputs :
reshaped_outputs.append( tf.contrib.layers.fully_connected(ii,output_dim,activation_fn=None))
#损失函数计算,均方差(x-y)^2
output_loss = 0
for _y, _Y in zip(reshaped_outputs, expected_output):
output_loss += tf.reduce_mean( tf.pow(_y - _Y, 2) )
# 正则项,l2正则项
reg_loss = 0
for tf_var in tf.trainable_variables():
if not ("fully_connected" in tf_var.name ):
#print(tf_var.name)
reg_loss += tf.reduce_mean(tf.nn.l2_loss(tf_var))
loss = output_loss + lambda_l2_reg * reg_loss
train_op = tf.train.AdamOptimizer(learning_rate).minimize(loss)
'''
3.训练模型,可视化loss
'''
#seq_2_seq的输入是一个list,需要构建一个list(encoder_input,except_input,decode_input),
#按照这个时间顺序放入,可以不抢位置
sess = tf.InteractiveSession()
def train_batch(batch_size):
X, Y = generate_data(isTrain=True, batch_size=batch_size) #[40,100.1]
#这里是赋值操作
feed_dict = {encoder_input[t]: X[t] for t in range(len(encoder_input))} # 40 组 每一组长100个
feed_dict.update({expected_output[t]: Y[t] for t in range(len(expected_output))}) #80组
#dict.update(dict2) dict.update(dict) 用法
#decode_input的输入重要说明,将其第一列输入变为零,做为初始输入的标记,接上未来序列。
#Y的最后一列并没有作为decoder的输入
c =np.concatenate(( [np.zeros_like(Y[0])],Y[:-1]),axis = 0)#c [40,100,1]
feed_dict.update({decode_input[t]: c[t] for t in range(len(c))}) #decoder数据喂入 #100组
_, loss_t = sess.run([train_op, loss], feed_dict)
return loss_t
def test_batch(batch_size):
X, Y = generate_data(isTrain=True, batch_size=batch_size)
feed_dict = {encoder_input[t]: X[t] for t in range(len(encoder_input))} #encoder_input
feed_dict.update({expected_output[t]: Y[t] for t in range(len(expected_output))})#实际值
#[np.zeros_like(Y[0])],100个0,其他Y分别往后面移动一位,构成新的c
c =np.concatenate(( [np.zeros_like(Y[0])],Y[:-1]),axis = 0)
feed_dict.update({decode_input[t]: c[t] for t in range(len(c))})
output_lossv,reg_lossv,loss_t = sess.run([output_loss,reg_loss,loss], feed_dict)
print("-----------------")
print(output_lossv,reg_lossv)
return loss_t
# Training
train_losses = []
test_losses = []
sess.run(tf.global_variables_initializer())
for t in range(nb_iters + 1):
train_loss = train_batch(batch_size)
train_losses.append(train_loss)
if t % 200 == 0:
test_loss = test_batch(batch_size)
test_losses.append(test_loss)
print("Step {}/{}, train loss: {}, \tTEST loss: {}".format(t,nb_iters, train_loss, test_loss))
print("Fin. train loss: {}, \tTEST loss: {}".format(train_loss, test_loss)) #最终结果
# 画损失函数
#test 损失
plt.figure(figsize=(12, 6))#画布大小
plt.plot(np.array(range(0, len(test_losses))) /
float(len(test_losses) - 1) * (len(train_losses) - 1),
#应为test_loss并不是每次都进行了计算,整200的计算,故把横坐标映射到那么长去
np.log(test_losses),label="Test loss")
#训练损失,随着时间迭代
plt.plot(np.log(train_losses),label="Train loss")
plt.title("Training errors over time (on a logarithmic scale)")
plt.xlabel('Iteration')#横坐标迭代次数
plt.ylabel('log(Loss)')#纵坐标对数误差
plt.legend(loc='best')
plt.show()
'''
#4.用训练好的模型, 随机选取5次进行预测,并且可视化结果
'''
nb_predictions = 5
print("visualize {} predictions data:".format(nb_predictions))
preout =[]
X, Y = generate_data(isTrain=False, batch_size=nb_predictions)
print(np.shape(X),np.shape(Y))
for tt in range(seq_length):
feed_dict = {encoder_input[t]: X[t+tt] for t in range(seq_length)}
feed_dict.update({expected_output[t]: Y[t+tt] for t in range(len(expected_output))})
c =np.concatenate(( [np.zeros_like(Y[0])],Y[tt:seq_length+tt-1]),axis = 0) #从前15个的最后一个开始预测
feed_dict.update({decode_input[t]: c[t] for t in range(len(c))})
outputs = np.array(sess.run([reshaped_outputs], feed_dict)[0])
preout.append(outputs[-1])
print(np.shape(preout)) #将每个未知预测值收集起来准备显示出来。
preout =np.reshape(preout,[seq_length,nb_predictions,output_dim])
for j in range(nb_predictions):
plt.figure(figsize=(12, 3))
for k in range(output_dim):
past = X[:, j, k]
expected = Y[seq_length-1:, j, k]#对应预测值的打印
pred = preout[:, j, k]
label1 = "past" if k == 0 else "_nolegend_"
label2 = "future" if k == 0 else "_nolegend_"
label3 = "Pred" if k == 0 else "_nolegend_"
plt.plot(range(len(past)), past, "o--b", label=label1)
plt.plot(range(len(past), len(expected) + len(past)),
expected, "x--b", label=label2)
plt.plot(range(len(past), len(pred) + len(past)),
pred, "o--y", label=label3)
plt.legend(loc='best')
plt.title("Predictions vs. future")
plt.show()
4.结果展示
图 一
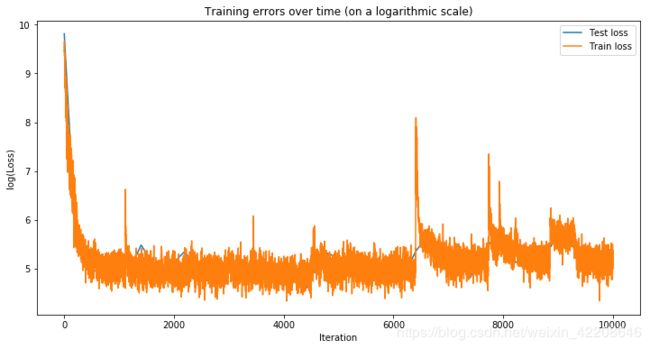
图1为训练中loss值的变化,当然,在可视化时,我们取了对数。
图二

图二,我们使用训练好的模型,随机抽取了一部分数据,用来它的预测股票收盘价,并了相关对比。发现预测还是相对准确的。
在上面代码中,我们画了5张图,这里只上传了一张。