1. 概述
本文分享分表分库路由相关的实现。涉及内容如下:
- SQL 路由器
- 路由引擎
- SQL 路由结果
SQL 路由大体流程如下:

第二个步骤其实是 SQL 的解析过程,在上一篇<
2. SQL 路由器
SQLRouter,SQL 路由器接口,共有两种实现:
- DatabaseHintSQLRouter:通过提示且仅路由至数据库的SQL路由器
- ParsingSQLRouter:需要解析的SQL路由器
它们实现 #parse() 进行 SQL 解析, #route() 进行 SQL 路由。
2.1 DatabaseHintSQLRouter
DatabaseHintSQLRouter,基于数据库提示的路由引擎。路由器工厂 SQLRouterFactory 创建路由器时,判断到使用数据库提示( Hint ) 时,创建 DatabaseHintSQLRouter。
// DatabaseHintRoutingEngine.java
public static SQLRouter createSQLRouter(final ShardingContext shardingContext) {
return HintManagerHolder.isDatabaseShardingOnly() ? new DatabaseHintSQLRouter(shardingContext) : new ParsingSQLRouter(shardingContext);
}
先来看下 HintManagerHolder、HintManager 部分相关的代码:
public final class HintManagerHolder {
public static final String DB_TABLE_NAME = "DB_TABLE_NAME";
public static final String DB_COLUMN_NAME = "DB_COLUMN_NAME";
private static final ThreadLocal HINT_MANAGER_HOLDER = new ThreadLocal<>();
/**
* 判断是否当前只分库.
*
* @return database sharding only or not
*/
public static boolean isDatabaseShardingOnly() {
return null != HINT_MANAGER_HOLDER.get() && HINT_MANAGER_HOLDER.get().isDatabaseShardingOnly();
}
/**
* 清理线索分片管理器的本地线程持有者.
*/
public static void clear() {
HINT_MANAGER_HOLDER.remove();
}
/**
* Get hint manager in current thread.
*
* @return hint manager in current thread
*/
public static HintManager get() {
return HINT_MANAGER_HOLDER.get();
}
}
public final class HintManager implements AutoCloseable {
private final Map databaseShardingValues = new HashMap<>();
@Getter
private boolean databaseShardingOnly;
/**
* 获取线索分片管理器实例.
*
* @return {@code HintManager} instance
*/
public static HintManager getInstance() {
HintManager result = new HintManager();
HintManagerHolder.setHintManager(result);
return result;
}
/**
* 设置分库分片值.
*
* 该方法适用于只分库的场景
*
* @param value sharding value
*/
public void setDatabaseShardingValue(final Comparable value) {
databaseShardingOnly = true;
addDatabaseShardingValue(HintManagerHolder.DB_TABLE_NAME, HintManagerHolder.DB_COLUMN_NAME, value);
}
}
那么如果要使用 DatabaseHintSQLRouter,我们只需要 HintManager.getInstance().setDatabaseShardingValue(库分片值) 即可。这里有两点要注意下:
- HintManager#getInstance(),每次获取到的都是新的 HintManager,多次赋值需要小心。
- HintManager#close(),使用完需要去清理,避免下个请求读到遗漏的线程变量。
Hint 方式主要使用场景:
- 分片字段不存在SQL、数据库表结构中,而存在于外部业务逻辑。
- 强制在主库进行某些数据操作。
2.2 ParsingSQLRouter
在我们平常的业务场景中,使用最多的是分片字段会在 SQL、数据库表结构中,其将采用 ParsingSQLRouter 进行 SQL 的解析和路由。
ParsingSQLRouter 使用 SQLParsingEngine 解析SQL(上篇文章已经介绍)。
ParsingSQLRouter 在路由时,会根据表情况使用 SimpleRoutingEngine 或 CartesianRoutingEngine 进行路由ParsingSQLRouter#route(parameters, sqlStatement):
private RoutingResult route(final List- 当是 DDL 语句时,采用
DDLRoutingEngine进行路由。 - 当只有一个表名或者多表互为 BindingTable 关系时,就会采用
SimpleRoutingEngine进行路由。 - 其他情况(多库多表情况)采用混合路由引擎
ComplexRoutingEngine。
BindingTable 关系在 ShardingRule 的 tableRules 配置。配置该关系 TableRule 有如下需要遵守的规则:
- 分片策略与算法相同
- 数据源配置对象相同
- 真实表数量相同
2.3 SimpleRoutingEngine
SimpleRoutingEngine,简单路由引擎。

// SimpleRoutingEngine.java
public RoutingResult route() {
// 1. 获取分表规则
TableRule tableRule = shardingRule.getTableRule(logicTableName);
// 2. 获取分库值
List databaseShardingValues = getDatabaseShardingValues(tableRule);
// 3. 获取分表值
List tableShardingValues = getTableShardingValues(tableRule);
// 4. 路由数据库
Collection routedDataSources = routeDataSources(tableRule, databaseShardingValues);
Collection routedDataNodes = new LinkedList<>();
for (String each : routedDataSources) {
// 5. 路由表
routedDataNodes.addAll(routeTables(tableRule, each, tableShardingValues));
}
// 6. 生成路由结果 RoutingResult
return generateRoutingResult(routedDataNodes);
}
第一步,根据 SQL 的逻辑表 logicTableName 获取分表规则(客户端配置的分片规则)tableRule。我们看 TableRule 的组成:
public final class TableRule {
// 逻辑表
private final String logicTable;
// 节点集合
private final List actualDataNodes;
// 数据库分片策略
private final ShardingStrategy databaseShardingStrategy;
// 表分片策略
private final ShardingStrategy tableShardingStrategy;
// 自增主键字段
private final String generateKeyColumn;
// 自增器,默认的自增器采用 snowflake
private final KeyGenerator keyGenerator;
private final String logicIndex;
}
第二步,根据 tableRule 获取分库值getDatabaseShardingValues(tableRule):
// SimpleRoutingEngine.java
private List getDatabaseShardingValues(final TableRule tableRule) {
ShardingStrategy strategy = shardingRule.getDatabaseShardingStrategy(tableRule);
return HintManagerHolder.isUseShardingHint() ? getDatabaseShardingValuesFromHint(strategy.getShardingColumns()) : getShardingValues(strategy.getShardingColumns());
}
private List getShardingValues(final Collection shardingColumns) {
List result = new ArrayList<>(shardingColumns.size());
for (String each : shardingColumns) {
Optional condition = sqlStatement.getConditions().find(new Column(each, logicTableName));
if (condition.isPresent()) {
result.add(condition.get().getShardingValue(parameters));
}
}
return result;
}
// ShardingRule.java
public ShardingStrategy getDatabaseShardingStrategy(final TableRule tableRule) {
return null == tableRule.getDatabaseShardingStrategy() ? defaultDatabaseShardingStrategy : tableRule.getDatabaseShardingStrategy();
}
该方法会从TableRule获取分库策略,如果为空,则使用默认的分库策略(需要客户端配置),如果未配置默认的分库策略,则使用NoneShardingStrategy,标明不使用任何分片策略。
关于 ShardingStrategy 的介绍,可以参考我的另一篇文章《分库分表中间件 Sharding-JDBC》。
其中两个比较重要的分片策略是 StandardShardingStrategy 和 ComplexShardingStrategy。前者针对是单个分片键,后者针对的是多个分片键。
拿到 ShardingStrategy 之后,继续判断,如果采用的时 Hint 分片方式,则从 Hint 中获取分库值;如果非 Hint 方式,则根据分片键和逻辑表找到对应的Condition,我们看到了《SQL解析》分享的Condition对象。之前我们提到过 Parser 半理解 SQL 的目的之一是:提炼分片上下文,此处即是该目的的体现。
接着,根据Condition的 ShardingOperator 属性,来创建不同的ShardingValue:
// Condition.java
public ShardingValue getShardingValue(final List分片操作为 = 或者 in 时,创建ListShardingValue对象。
分片操作为 Between 时,创建RangeShardingValue对象。
- ListShardingValue
public final class ListShardingValue> implements ShardingValue {
// 逻辑表
private final String logicTableName;
// 分片字段
private final String columnName;
// 分片字段的值,集合
private final Collection values;
}
- RangeShardingValue
public final class RangeShardingValue> implements ShardingValue {
private final String logicTableName;
private final String columnName;
// 分片字段的值,区间
private final Range valueRange;
}
第三步,获取表分片值。跟第二步是类似的,这里就不再赘述了。
第四步,根据数据库分片值和分片规则,进行数据库路由操作routeDataSources:
private Collection routeDataSources(final TableRule tableRule, final List databaseShardingValues) {
// 获取实际节点的数据库集合
Collection availableTargetDatabases = tableRule.getActualDatasourceNames();
if (databaseShardingValues.isEmpty()) {
return availableTargetDatabases;
}
// 根据数据库分片值进行分片操作
Collection result = shardingRule.getDatabaseShardingStrategy(tableRule).doSharding(availableTargetDatabases, databaseShardingValues);
Preconditions.checkState(!result.isEmpty(), "no database route info");
return result;
}
主要的路由操作是在ShardingStrategy#doSharding方法,这里我们以单个分片键为例,其实现类为StandardShardingStrategy:
public final class StandardShardingStrategy implements ShardingStrategy {
// 分片字段
private final String shardingColumn;
// 精确分片算法
private final PreciseShardingAlgorithm preciseShardingAlgorithm;
// 区间分片算法
private final Optional rangeShardingAlgorithm;
public StandardShardingStrategy(final String shardingColumn, final PreciseShardingAlgorithm preciseShardingAlgorithm) {
this(shardingColumn, preciseShardingAlgorithm, null);
}
public StandardShardingStrategy(final String shardingColumn, final PreciseShardingAlgorithm preciseShardingAlgorithm, final RangeShardingAlgorithm rangeShardingAlgorithm) {
this.shardingColumn = shardingColumn;
this.preciseShardingAlgorithm = preciseShardingAlgorithm;
this.rangeShardingAlgorithm = Optional.fromNullable(rangeShardingAlgorithm);
}
@Override
public Collection doSharding(final Collection availableTargetNames, final Collection shardingValues) {
// 获取分片值(就一个)
ShardingValue shardingValue = shardingValues.iterator().next();
// 分片操作
Collection shardingResult = shardingValue instanceof ListShardingValue
? doSharding(availableTargetNames, (ListShardingValue) shardingValue) : doSharding(availableTargetNames, (RangeShardingValue) shardingValue);
Collection result = new TreeSet<>(String.CASE_INSENSITIVE_ORDER);
result.addAll(shardingResult);
return result;
}
private Collection doSharding(final Collection availableTargetNames, final ListShardingValue shardingValue) {
Collection result = new LinkedList<>();
for (PreciseShardingValue each : transferToPreciseShardingValues(shardingValue)) {
// 调用分片算法(精确/区间)的分片操作
result.add(preciseShardingAlgorithm.doSharding(availableTargetNames, each));
}
return result;
}
...
}
StandardShardingStrategy 分片的时候,是调用其PreciseShardingAlgorithm 或者 RangeShardingAlgorithm 对象的 doSharding方法进行分片的。而我们客户端配置分片算法的时候,就是实现了以上算法接口的。
第五步,遍历数据库路由结果,对每一个数据库进行表的分片路由routeTables:
// SimpleRoutingEngine.java
private Collection routeTables(final TableRule tableRule, final String routedDataSource, final List tableShardingValues) {
Collection availableTargetTables = tableRule.getActualTableNames(routedDataSource);
Collection routedTables = tableShardingValues.isEmpty() ? availableTargetTables
: shardingRule.getTableShardingStrategy(tableRule).doSharding(availableTargetTables, tableShardingValues);
Preconditions.checkState(!routedTables.isEmpty(), "no table route info");
Collection result = new LinkedList<>();
for (String each : routedTables) {
result.add(new DataNode(routedDataSource, each));
}
return result;
}
表的分片和数据库的分片的逻辑是一样的,分片完成之后,将每个分片结果封装在DataNode对象中:
public class DataNode {
private static final String DELIMITER = ".";
// 数据库
private final String dataSourceName;
// 表
private final String tableName;
}
第六步,将 DataNode 集合封装成路由结果RoutingResult:
private RoutingResult generateRoutingResult(final Collection routedDataNodes) {
RoutingResult result = new RoutingResult();
for (DataNode each : routedDataNodes) {
result.getTableUnits().getTableUnits().add(new TableUnit(each.getDataSourceName(), logicTableName, each.getTableName()));
}
return result;
}
RoutingResult 存放了TableUnits,其是TableUnit的集合对象。该方法将分片出来的数据库信息和表信息存入在TableUnit中,供后续改写 SQL 用。
2.4 ComplexRoutingEngine
ComplexRoutingEngine,混合多库多表路由引擎。
public final class ComplexRoutingEngine implements RoutingEngine {
private final ShardingRule shardingRule;
private final List-
ComplexRoutingEngine 计算每个逻辑表的简单路由分片,路由结果交给 CartesianRoutingEngine 继续路由形成笛卡尔积结果。
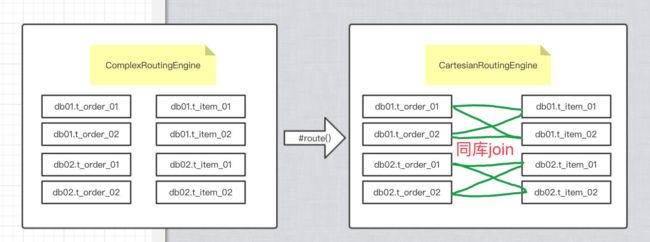
由于在 ComplexRoutingEngine 路由前已经判断全部表互为 BindingTable 关系,因而不会出现 result.size == 1,属于防御性编程。
部分表互为 BindingTable 关系时,ComplexRoutingEngine 不重复计算分片。
2.5 CartesianRoutingEngine
CartesianRoutingEngine,笛卡尔积的库表路由。
public CartesianRoutingResult route() {
CartesianRoutingResult result = new CartesianRoutingResult();
// 根据路由结果获取 dataSourceLogicTablesMap:key 为 数据库名,value 为表名集合
for (Entry> entry : getDataSourceLogicTablesMap().entrySet()) {
// 获得当前数据源(库)的实际表分组
List> actualTableGroups = getActualTableGroups(entry.getKey(), entry.getValue());
// 获得当前数据源(库)的路由表单元分组
List> tableUnitGroups = toTableUnitGroups(entry.getKey(), actualTableGroups);
// 对路由表单元分组进行笛卡尔积,并合并到路由结果
result.merge(entry.getKey(), getCartesianTableReferences(Sets.cartesianProduct(tableUnitGroups)));
}
log.trace("cartesian tables sharding result: {}", result);
return result;
}
第一步,获得同库对应的逻辑表集合,即 Entry<数据源(库), Set<逻辑表>> entry。
第二步,遍历数据源(库),获得当前数据源(库)的路由表单元分组。
第三步,对路由表单元分组进行笛卡尔积,并合并到路由结果。
注意:同库才可以进行笛卡尔积。
3. 结语
由于篇幅关系,本文并未对笛卡尔积的路由展开说,感兴趣的同学可以自行去了解。
经过路由之后,得到的RoutingResult对象,会在下一篇文章 SQL 改写中用到它,尽请关注~