- Python中Pyttsx3库实现文本转化成语音MP3格式文件
定星照空
python
Pyttsx3库介绍pyttsx3库是一个功能强大且使用方便的Python本地文本转语音库。它不仅能在离线下将文本转换为语音MP3格式文件,也能在Windows、MacOS和Linux等多个操作系统上实现语音播报。同时,还可以调整语音播报的语速、音量和音色。安装与基本使用安装:cmd命令行中执行pipinstallpyttsx3。基本使用示例:importpyttsx3#初始化语音引擎engine
- Node.js 包与 npm 详解:使用 npm 的重要注意事项与最佳实践
还是鼠鼠
node.jsnode.jsjavascriptvscode前端
目录Node.js包与npm:使用npm的其它注意点详解1.package.json与package-lock.json的作用什么是package.json?什么是package-lock.json?示例:package-lock.json片段2.语义化版本(SemVer)与依赖版本管理3.全局安装vs.本地安装本地安装(默认)全局安装4.npm缓存管理与优化清理npm缓存5.依赖冲突与node_
- Adb与monkey命令学习总结
你醉牛啤
手机测试adb软件测试
主要内容adb构成和工作原理adb常用命令查看当前连接设备安装apk文件卸载APP获取包名和界面名adbshellam/pmadb文件传输其他常用命令monkey常用命令事件数频率–throttle(毫秒),延时操作指定执行的应用–p日志-v调试选项完整应用monkey命令进行稳定性测试adb构成和工作原理全称:AndroidDebugBridge就是起到调试桥的作用。顾名思义,adb就是一个de
- 使用PyTorch搭建Transformer神经网络:入门篇
DASA13
pytorchtransformer神经网络
1.简介Transformer是一种强大的神经网络架构,在自然语言处理等多个领域取得了巨大成功。本教程将指导您使用PyTorch框架从头开始构建一个Transformer模型。我们将逐步解释每个组件,并提供详细的代码实现。2.环境设置首先,确保您的系统中已安装Python(推荐3.7+版本)。然后,安装PyTorch和其他必要的库:pipinstalltorchnumpymatplotlib3.P
- 【Docker】搭建实用的内网穿透工具 - FRP
UPToZ
群晖Dockerdocker容器运维
前言本教程基于群晖的NAS设备DS423+的docker功能进行搭建FRP的客户端,DSM版本为7.2.1-69057Update5。采用香港机Debian12系统的服务器来安装FRP的服务端作为演示。服务器购买地址:https://www.crash.work/aff/AQXGDNKY简介FRP(FastReverseProxy)是一个高性能的反向代理应用,它可以帮助您将内网服务通过反向代理暴露
- Windows 和 MacOS 上安装配置ADB(安卓调试桥)
网络安全苏柒
windowsmacosadb网络安全pythonweb安全数据库
一、Android调试桥(ADB)Android调试桥(ADB)是一款多功能命令行工具,它让你能够更便捷地访问和管理Android设备。使用ADB命令,你可以轻松执行以下操作网络安全重磅福利:入门&进阶全套282G学习资源包免费分享!在设备上安装、复制和删除文件;安装应用程序;录制设备屏幕或截图;对设备进行调试,以便排查问题;检查手机上的日志文件;更新应用程序和系统组件的固件;完整地访问有关操作系
- Ubuntu使用Docker部署Nginx并结合内网穿透实现公网远程访问
鸭鸭渗透
eureka云原生
目录1.安装Docker2.使用Docker拉取Nginx镜像3.创建并启动Nginx容器4.本地连接测试5.公网远程访问本地Nginx5.1内网穿透工具安装5.2创建远程连接公网地址5.3使用固定公网地址远程访问在开发人员的工作中,公网远程访问内网是其必备的技术需求之一。对于运维人员和开发者来说,能够通过公网远程访问内部的服务和应用,能够极大地提升工作效率和便利性。本文将介绍如何利用Ubuntu
- Python 向量检索库Faiss使用
懒大王爱吃狼
pythonpython开发语言自动化Python基础python教程
Faiss(FacebookAISimilaritySearch)是一个由FacebookAIResearch开发的库,它专门用于高效地搜索和聚类大量向量。Faiss能够在几毫秒内搜索数亿个向量,这使得它非常适合于实现近似最近邻(ANN)搜索,这在许多应用中都非常有用,比如图像检索、推荐系统和自然语言处理。以下是如何使用Faiss的基本步骤和示例:1.安装Faiss首先,你需要安装Faiss。你可
- kafka生产消息失败 ...has passed since batch creation plus linger time
Lichenpar
#记录BUG解决kafka网络安全java
背景:公司要使用华为云的kafka服务,我负责进行技术预研,后期要封装kafka组件。从华为云下载了demo,完全按照开发者文档来进行配置文件配置,但是会报以下错误。org.apache.kafka.common.errors.TimeoutException:Expiring10record(s)fortopic-0:30015mshaspassedsincebatchcreationplusl
- linux环境下安装Redis后却找不到./src/redis-server
Lichenpar
redis#记录BUG解决redis
原因是因为在执行make命令的时候失败了。失败的原因大概率是环境没有安装gcc命令。先安装gcc命令yum-yinstallgcc然后再进入到redis安装目录下执行makedistclean然后重新编译一遍make这次的编译过程时间就会长一些了。然后启动./src/redis-server
- 探索数据安全新境界:Apache Spark SQL Ranger Security插件深度揭秘
乌昱有Melanie
探索数据安全新境界:ApacheSparkSQLRangerSecurity插件深度揭秘项目地址:https://gitcode.com/gh_mirrors/sp/spark-ranger随着大数据的爆炸性增长,数据安全性成为了企业不可忽视的核心议题。在这一背景下,【ApacheSparkSQLRangerSecurityPlugin】以其强大的数据访问控制能力脱颖而出,成为数据处理领域的明星级
- 新书速览|云原生Kubernetes自动化运维实践
全栈开发圈
云原生运维kubernetes
《云原生Kubernetes自动化运维实践》本书内容:《云原生Kubernetes自动化运维实践》以一名大型企业集群运维工程师的实战经验为基础,全面系统地阐述Kubernetes(K8s)在自动化运维领域的技术应用。《云原生Kubernetes自动化运维实践》共16章,内容由浅入深,逐步揭示K8s的原理及实际操作技巧。第1章引领读者踏入Kubernetes的世界,详细介绍其起源、核心组件的概念以及
- ModuleNotFoundError: No module named ‘h5py‘
Hardess-god
python
到ModuleNotFoundError:Nomodulenamed'h5py'错误表明Python环境中没有安装h5py模块。h5py是一个用于处理HDF5二进制数据格式的Python接口,广泛用于大规模存储和操纵数据。解决方案:安装h5py要解决这个问题,你需要在你的Python环境中安装h5py。以下是如何在不同环境中安装h5py的步骤:使用pip安装如果你使用的是pip包管理器,可以通过以
- 使用Ollama部署开源大模型
好好学习 666
开源
Ollama是一个简明易用的本地大模型运行框架,可以一键启动启动并运行Llama3、Mistral、Gemma和其他大型语言模型。安装MacOS,Windows用户直接在官网下载页下载安装包即可。Linux系统运行如下命令安装curl-fsSLhttps://ollama.com/install.sh|sh使用Usage:ollama[flags]ollama[command]AvailableC
- 分析K8S中Node状态为`NotReady`问题
网络飞鸥
Kuberneteskubernetes容器云原生
在Kubernetes(k8s)集群中,Node状态为NotReady通常意味着节点上存在某些问题,下面为你分析正常情况下节点应运行的容器以及解决NotReady状态的方法。正常情况下Node节点应运行的容器1.kubeletkubelet是节点上的核心组件,它负责与控制平面通信,管理节点上的容器生命周期。它通常作为系统服务运行,而不是以容器形式存在,但也有使用容器化部署的情况。2.kube-pr
- 【2017-2025】Adobe Photoshop【PS】软件下载安装
adkjcbqvblq
adobephotoshopui
获取安装包https://pan.baidu.com/s/1NLUthiAyC2chlSEwbf1LRQ?pwd=4ppq1.起源与发展1.1初试啼声AdobePhotoshop的历史可以追溯到1987年,当时由托马斯·诺尔(ThomasKnoll)和他的兄弟约翰·诺尔(JohnKnoll)共同开发。托马斯在父亲的帮助下,开始了图像处理的编程尝试。他们的初始产品是一个用于Mac系统的程序,最初名为
- WebGL开发:BabylonJS从入门到精通(下卷)
莲华君
前端权威教程合集WebGL系统化学习webgl
全书卷目:WebGL开发:BabylonJS从入门到精通(上卷)WebGL开发:BabylonJS从入门到精通(下卷)目录第一部分:基础篇——构建3D世界的基石第一章:BabylonJS概述与环境搭建什么是BabylonJS:WebGL宇宙的创世引擎BabylonJS的历史与优势:开源利剑的进化史安装与配置开发环境:3D工匠的工坊搭建术使用BabylonJSPlayground与本地开发环境浏览器
- 如何使用YOLOv8在AI-TOD数据集上进行遥感目标检测,从安装依赖项、准备数据集、配置YOLOv8、训练和评估模型以及构建GUI应用程序展示检测
计算机C9硕士_算法工程师
人工智能YOLO目标检测遥感
如何使用YOLOv8在AI-TOD数据集上进行遥感目标检测,从安装依赖项、准备数据集、配置YOLOv8、训练和评估模型以及构建GUI应用程序展示检测文章目录1.安装依赖2.数据准备3.配置YOLOv83.1加载预训练模型或自定义模型4.训练模型5.评估模型6.构建GUI应用程序(可选)以下文字及代码仅供参考。遥感目标检测,AI-TOD数据集aitod,训练集11214张,测试集集14018,验证集
- 【RabbitMQ】超详细Windows系统下RabbitMQ的安装配置
m0_74825074
面试学习路线阿里巴巴rabbitmqwindows分布式
RabbitMQ是一个开源的消息队列中间件,广泛用于分布式系统中的异步消息传递。它支持多种消息协议,易于扩展,功能强大。本文将详细介绍如何在Windows系统下安装和配置RabbitMQ,包括所需的依赖项、安装步骤、基本配置和常见问题解决方案。目录什么是RabbitMQ?安装前的准备2.1系统要求2.2安装ErlangRabbitMQ的安装步骤3.1下载RabbitMQ3.2安装RabbitMQ配
- 不用再当“技术宅“!这个AI神器让我5分钟变身人工智能达人
阳光永恒736
AI工具人工智能deepseek一键包本地部署AI资源
最近我在朋友圈刷到好多朋友都在玩AI画图、AI写诗,看得我心痒痒。可每次想自己试试,打开教程就被满屏的代码吓退——"Python环境配置"、"CUDA驱动安装"这些词比数学作业还让人头疼。直到我发现了一个叫DeepSeek本地部署一键包的神器,我的AI探索之旅终于变得像搭乐高一样简单!夸克网盘分享一、原来AI离我们这么近上周三放学路上,我看见隔壁班的小美用AI给自己照片生成古风造型,这让我突然意识
- 2025.03.22【读书笔记】| fastq-multx:高效barcode拆分数据解决工具
穆易青
读书笔记数据处理读书笔记linux运维服务器
文章目录1.工具介绍为什么需要`fastq-multx`?`fastq-multx`的特点2.安装方式通过源代码编译安装使用包管理器安装3.使用命令基本命令高级参数设置结语1.工具介绍在生物信息学的世界里,工具的选择至关重要。今天,我们要介绍的这个工具,就是fastq-multx,一个用于高效barcode去复用和demultiplex的解决方案。fastq-multx是一个专门设计用于处理高通量
- PXE系统
惟贤箬溪
运维运维服务器
PXE(PrebootExecutionEnvironment)系统PXE(PrebootExecutionEnvironment)是一种基于网络启动的技术,可以通过网络从远程服务器加载操作系统并进行安装或运行。通常,PXE用于企业环境,尤其是大规模部署操作系统时,能够实现无盘工作站的启动以及批量系统安装。通过PXE,用户无需使用U盘、光盘等物理媒介,只需要一台支持网络启动的计算机和一个配置好的P
- java工程师常用开发工具
Monika Zhang
开发工具java
背景:最近换新电脑,记录下本岗位需要安装的软件,也顺便给大家参考,欢迎各位留言补充1JDK(JavaDevelopmentKit)JDK是Java程序员开发Java应用程序所必需的软件包。下载地址:JavaDownloads|Oracle安装配置教程:window下win10jdk8安装与环境变量的配置(超级详细)_jdk8环境变量配置-CSDN博客目前主流的JDK版本还是JAVA8查看版本命令:
- DeepSeek 部署指南 (使用 vLLM 本地部署)
AGI大模型资料分享员
人工智能语言模型学习chatgpt深度学习大模型deepseek
DeepSeek部署指南(使用vLLM本地部署)本文档将指导您如何使用vLLM在本地部署DeepSeek语言模型。我们以deepseek-ai/DeepSeek-R1-Distill-Qwen-7B模型为例进行演示。1、安装Python环境首先,您需要安装Python环境。访问Python官网:https://www.python.org/根据您的操作系统选择安装包:Python官网提供Windo
- sudo apt-get install package时出现E:无法定位软件包
God.v
ubuntulinuxcentos
sudoapt-getinstallpackage时出现E:无法定位软件包在Ubuntu上安装openssl-devel时遇到无法定位软件包的问题,查阅文章,大多是换源和在“软件和更新”中更换下载地址的方法,而我尝试过后并无卵用,如果接下来的方法不适用你的情况,你也不妨考虑以上两种办法。其实很简单,区分centos和Ubuntu等在安装文件时的名称差别,对于这两种图形界面来说,将openssl-d
- 山西中考计算机评分软件
SuRuiYuan1
山西信息技术中考评分软件
访问网址:https://www.123865.com/s/cPmDjv-mSeBd提取码:zkds下载安装后具体步骤请访问:https://www.123865.com/s/cPmDjv-1SeBd提取码:zkds满分操作步骤:https://www.123865.com/s/cPmDjv-4SeBd提取码:zkds
- ROS开发疑难杂症持续更新
流浪的567
ROS机器人c++
一、Eigen相关1、fatalerror:Eigen/Dense:没有那个文件或目录4|#include|^~~~~~~~~~~~~1.1、安装Eigensudoapt-getinstalllibeigen3-dev1.2、检查Eigen头文件是否存在于/usr/include/eigen3/或/usr/local/include/目录下ls/usr/include/eigen3/Eigen#应
- HDFS相关的面试题
努力的搬砖人.
java面试hdfs
以下是150道HDFS相关的面试题,涵盖了HDFS的基本概念、架构、操作、数据存储、高可用性、权限管理、性能优化、容错机制、与MapReduce的结合、安全性、数据压缩、监控与管理、与YARN的关系、数据一致性、数据备份与恢复等方面,希望对你有所帮助。HDFS基本概念1.HDFS是什么?它的设计目标是什么?•HDFS是Hadoop分布式文件系统,设计目标是实现对大规模数据的高吞吐量访问,适用于一次
- 基于Azure云平台构建实时数据仓库
weixin_30777913
云计算azure开发语言sparkpython
设计Azure云架构方案实现AzureDeltaLake和AzureDatabricks,结合电商网站的流数据,构建实时数据仓库,支持T+0报表(如电商订单分析),具以及具体实现的详细步骤和关键PySpark代码。一、架构设计[电商网站]→[AzureEventHubs]→[AzureDatabricksStreaming]↓[AzureDeltaLake]←→[DatabricksSQLAnal
- shell 脚本搭建apache
好多知识都想学
apache
#!/bin/bash#SetApacheversiontoinstall##author:yuan#检查外网连接echo"检查外网连接..."pingwww.baidu.com-c3>/dev/null2>&1if[$?-eq0];then echo"外网通讯良好!"else echo"网络连接失败,请检查你的网络设置!" exit1fisleep5#检查并安装APR库echo"检查并安装
- 关于旗正规则引擎规则中的上传和下载问题
何必如此
文件下载压缩jsp文件上传
文件的上传下载都是数据流的输入输出,大致流程都是一样的。
一、文件打包下载
1.文件写入压缩包
string mainPath="D:\upload\"; 下载路径
string tmpfileName=jar.zip; &n
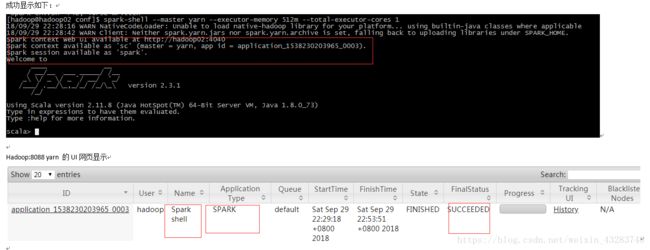
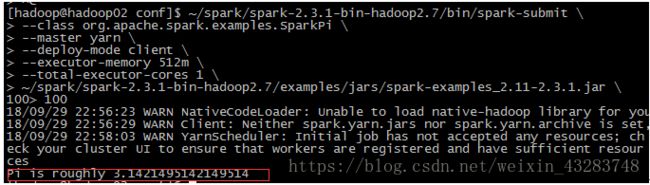
- 【Spark九十九】Spark Streaming的batch interval时间内的数据流转源码分析
bit1129
Stream
以如下代码为例(SocketInputDStream):
Spark Streaming从Socket读取数据的代码是在SocketReceiver的receive方法中,撇开异常情况不谈(Receiver有重连机制,restart方法,默认情况下在Receiver挂了之后,间隔两秒钟重新建立Socket连接),读取到的数据通过调用store(textRead)方法进行存储。数据
- spark master web ui 端口8080被占用解决方法
daizj
8080端口占用sparkmaster web ui
spark master web ui 默认端口为8080,当系统有其它程序也在使用该接口时,启动master时也不会报错,spark自己会改用其它端口,自动端口号加1,但为了可以控制到指定的端口,我们可以自行设置,修改方法:
1、cd SPARK_HOME/sbin
2、vi start-master.sh
3、定位到下面部分
- oracle_执行计划_谓词信息和数据获取
周凡杨
oracle执行计划
oracle_执行计划_谓词信息和数据获取(上)
一:简要说明
在查看执行计划的信息中,经常会看到两个谓词filter和access,它们的区别是什么,理解了这两个词对我们解读Oracle的执行计划信息会有所帮助。
简单说,执行计划如果显示是access,就表示这个谓词条件的值将会影响数据的访问路径(表还是索引),而filter表示谓词条件的值并不会影响数据访问路径,只起到
- spring中datasource配置
g21121
dataSource
datasource配置有很多种,我介绍的一种是采用c3p0的,它的百科地址是:
http://baike.baidu.com/view/920062.htm
<!-- spring加载资源文件 -->
<bean name="propertiesConfig"
class="org.springframework.b
- web报表工具FineReport使用中遇到的常见报错及解决办法(三)
老A不折腾
finereportFAQ报表软件
这里写点抛砖引玉,希望大家能把自己整理的问题及解决方法晾出来,Mark一下,利人利己。
出现问题先搜一下文档上有没有,再看看度娘有没有,再看看论坛有没有。有报错要看日志。下面简单罗列下常见的问题,大多文档上都有提到的。
1、repeated column width is largerthan paper width:
这个看这段话应该是很好理解的。比如做的模板页面宽度只能放
- mysql 用户管理
墙头上一根草
linuxmysqluser
1.新建用户 //登录MYSQL@>mysql -u root -p@>密码//创建用户mysql> insert into mysql.user(Host,User,Password) values(‘localhost’,'jeecn’,password(‘jeecn’));//刷新系统权限表mysql>flush privileges;这样就创建了一个名为:
- 关于使用Spring导致c3p0数据库死锁问题
aijuans
springSpring 入门Spring 实例Spring3Spring 教程
这个问题我实在是为整个 springsource 的员工蒙羞
如果大家使用 spring 控制事务,使用 Open Session In View 模式,
com.mchange.v2.resourcepool.TimeoutException: A client timed out while waiting to acquire a resource from com.mchange.
- 百度词库联想
annan211
百度
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>RunJS</title&g
- int数据与byte之间的相互转换实现代码
百合不是茶
位移int转bytebyte转int基本数据类型的实现
在BMP文件和文件压缩时需要用到的int与byte转换,现将理解的贴出来;
主要是要理解;位移等概念 http://baihe747.iteye.com/blog/2078029
int转byte;
byte转int;
/**
* 字节转成int,int转成字节
* @author Administrator
*
- 简单模拟实现数据库连接池
bijian1013
javathreadjava多线程简单模拟实现数据库连接池
简单模拟实现数据库连接池
实例1:
package com.bijian.thread;
public class DB {
//private static final int MAX_COUNT = 10;
private static final DB instance = new DB();
private int count = 0;
private i
- 一种基于Weblogic容器的鉴权设计
bijian1013
javaweblogic
服务器对请求的鉴权可以在请求头中加Authorization之类的key,将用户名、密码保存到此key对应的value中,当然对于用户名、密码这种高机密的信息,应该对其进行加砂加密等,最简单的方法如下:
String vuser_id = "weblogic";
String vuse
- 【RPC框架Hessian二】Hessian 对象序列化和反序列化
bit1129
hessian
任何一个对象从一个JVM传输到另一个JVM,都要经过序列化为二进制数据(或者字符串等其他格式,比如JSON),然后在反序列化为Java对象,这最后都是通过二进制的数据在不同的JVM之间传输(一般是通过Socket和二进制的数据传输),本文定义一个比较符合工作中。
1. 定义三个POJO
Person类
package com.tom.hes
- 【Hadoop十四】Hadoop提供的脚本的功能
bit1129
hadoop
1. hadoop-daemon.sh
1.1 启动HDFS
./hadoop-daemon.sh start namenode
./hadoop-daemon.sh start datanode
通过这种逐步启动的方式,比start-all.sh方式少了一个SecondaryNameNode进程,这不影响Hadoop的使用,其实在 Hadoop2.0中,SecondaryNa
- 中国互联网走在“灰度”上
ronin47
管理 灰度
中国互联网走在“灰度”上(转)
文/孕峰
第一次听说灰度这个词,是任正非说新型管理者所需要的素质。第二次听说是来自马化腾。似乎其他人包括马云也用不同的语言说过类似的意思。
灰度这个词所包含的意义和视野是广远的。要理解这个词,可能同样要用“灰度”的心态。灰度的反面,是规规矩矩,清清楚楚,泾渭分明,严谨条理,是决不妥协,不转弯,认死理。黑白分明不是灰度,像彩虹那样
- java-51-输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字。
bylijinnan
java
public class PrintMatrixClockwisely {
/**
* Q51.输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字。
例如:如果输入如下矩阵:
1 2 3 4
5 6 7 8
9
- mongoDB 用户管理
开窍的石头
mongoDB用户管理
1:添加用户
第一次设置用户需要进入admin数据库下设置超级用户(use admin)
db.addUsr({user:'useName',pwd:'111111',roles:[readWrite,dbAdmin]});
第一个参数用户的名字
第二个参数
- [游戏与生活]玩暗黑破坏神3的一些问题
comsci
生活
暗黑破坏神3是有史以来最让人激动的游戏。。。。但是有几个问题需要我们注意
玩这个游戏的时间,每天不要超过一个小时,且每次玩游戏最好在白天
结束游戏之后,最好在太阳下面来晒一下身上的暗黑气息,让自己恢复人的生气
&nb
- java 二维数组如何存入数据库
cuiyadll
java
using System;
using System.Linq;
using System.Text;
using System.Windows.Forms;
using System.Xml;
using System.Xml.Serialization;
using System.IO;
namespace WindowsFormsApplication1
{
- 本地事务和全局事务Local Transaction and Global Transaction(JTA)
darrenzhu
javaspringlocalglobaltransaction
Configuring Spring and JTA without full Java EE
http://spring.io/blog/2011/08/15/configuring-spring-and-jta-without-full-java-ee/
Spring doc -Transaction Management
http://docs.spring.io/spri
- Linux命令之alias - 设置命令的别名,让 Linux 命令更简练
dcj3sjt126com
linuxalias
用途说明
设置命令的别名。在linux系统中如果命令太长又不符合用户的习惯,那么我们可以为它指定一个别名。虽然可以为命令建立“链接”解决长文件名的问 题,但对于带命令行参数的命令,链接就无能为力了。而指定别名则可以解决此类所有问题【1】。常用别名来简化ssh登录【见示例三】,使长命令变短,使常 用的长命令行变短,强制执行命令时询问等。
常用参数
格式:alias
格式:ali
- yii2 restful web服务[格式响应]
dcj3sjt126com
PHPyii2
响应格式
当处理一个 RESTful API 请求时, 一个应用程序通常需要如下步骤 来处理响应格式:
确定可能影响响应格式的各种因素, 例如媒介类型, 语言, 版本, 等等。 这个过程也被称为 content negotiation。
资源对象转换为数组, 如在 Resources 部分中所描述的。 通过 [[yii\rest\Serializer]]
- MongoDB索引调优(2)——[十]
eksliang
mongodbMongoDB索引优化
转载请出自出处:http://eksliang.iteye.com/blog/2178555 一、概述
上一篇文档中也说明了,MongoDB的索引几乎与关系型数据库的索引一模一样,优化关系型数据库的技巧通用适合MongoDB,所有这里只讲MongoDB需要注意的地方 二、索引内嵌文档
可以在嵌套文档的键上建立索引,方式与正常
- 当滑动到顶部和底部时,实现Item的分离效果的ListView
gundumw100
android
拉动ListView,Item之间的间距会变大,释放后恢复原样;
package cn.tangdada.tangbang.widget;
import android.annotation.TargetApi;
import android.content.Context;
import android.content.res.TypedArray;
import andr
- 程序员用HTML5制作的爱心树表白动画
ini
JavaScriptjqueryWebhtml5css
体验效果:http://keleyi.com/keleyi/phtml/html5/31.htmHTML代码如下:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml"><head><meta charset="UTF-8" >
<ti
- 预装windows 8 系统GPT模式的ThinkPad T440改装64位 windows 7旗舰版
kakajw
ThinkPad预装改装windows 7windows 8
该教程具有普遍参考性,特别适用于联想的机器,其他品牌机器的处理过程也大同小异。
该教程是个人多次尝试和总结的结果,实用性强,推荐给需要的人!
缘由
小弟最近入手笔记本ThinkPad T440,但是特别不能习惯笔记本出厂预装的Windows 8系统,而且厂商自作聪明地预装了一堆没用的应用软件,消耗不少的系统资源(本本的内存为4G,系统启动完成时,物理内存占用比
- Nginx学习笔记
mcj8089
nginx
一、安装nginx 1、在nginx官方网站下载一个包,下载地址是:
http://nginx.org/download/nginx-1.4.2.tar.gz
2、WinSCP(ftp上传工
- mongodb 聚合查询每天论坛链接点击次数
qiaolevip
每天进步一点点学习永无止境mongodb纵观千象
/* 18 */
{
"_id" : ObjectId("5596414cbe4d73a327e50274"),
"msgType" : "text",
"sendTime" : ISODate("2015-07-03T08:01:16.000Z"
- java术语(PO/POJO/VO/BO/DAO/DTO)
Luob.
DAOPOJODTOpoVO BO
PO(persistant object) 持久对象
在o/r 映射的时候出现的概念,如果没有o/r映射,就没有这个概念存在了.通常对应数据模型(数据库),本身还有部分业务逻辑的处理.可以看成是与数据库中的表相映射的java对象.最简单的PO就是对应数据库中某个表中的一条记录,多个记录可以用PO的集合.PO中应该不包含任何对数据库的操作.
VO(value object) 值对象
通
- 算法复杂度
Wuaner
Algorithm
Time Complexity & Big-O:
http://stackoverflow.com/questions/487258/plain-english-explanation-of-big-o
http://bigocheatsheet.com/
http://www.sitepoint.com/time-complexity-algorithms/