Rocket MQ 学习
RocketMQ学习笔记
rocketmq 是一款分布式,队列模型的开源消息件 。
一、RocketMQ 的特性
-
原生分布式
-
俩种消息拉取
-
严格消息顺序
-
特有的分布式协调器
-
亿级消息堆积
-
组(group)
RocketMQ的基本概念
Producer : 消息生产者,负责产生消息,一般由业务系统负责产生消息。
Consumer:消息消费者,负责消费消息,一般是后台异步系统负责异步消费。
Push Consumer:封装消息拉取,消费进程和内部
Pull Consumer: 主动拉取消息,一旦拉取到消息,应用的消费进程初始化。
Producer Group : 一类producer的集合名称,这类producer通常发送一类消息,且发送逻辑一致。
Consumer Group : 一类consumer的集合名称,这类consumer通常消费一类消息,且消费逻辑一致。
Broker : 消息中转角色,负责存储消息,转发消息,这里指RocatMQ Server;
Topic: 消息的主题,用于定义并且在服务端进行配置,消费者可以按照主题进行订阅,也就是消息分类,通 常一个系统一个主题(Topic)。
Message: 在生产者,消费者,服务器之间传递的消息,一个Message必须属于一个Topic;
Namesrv: 一个无状态的名称服务,可以集群部署,每一个broker启动的时候都会向名称服务器注册,主要是接收broker的注册,接收客户端的路由请求并且返回路由信息。
Offset: 偏移量,消费者拉取信息时需要知道上一次消费到了什么位置,这一次从哪里开始消费。
Partition: 分区,Topic物理上的分片,一个topic 可以 分为多个分区,每一个分区都是一个有序的队列,分区中的每条消息都会分配一个有序的ID,也就是偏移量。
Tag : 用于对消息进行过滤,理解为message的标记,同一个业务不同目的的message可以使用相同的topic但是可以用不同的tag来区分。
KEY:消息的key字段是为了唯一标识消息的,方便查询问题,设置为了方便开发和运维定位问题。
二、RocketMQ架构方案及角色详解
三个目标学习。
-
Rocket MQ 角色介绍
-
Rocket MQ 架构方案
-
Rocket MQ 集群部署配置
(一)Rocket MQ 角色介绍
有四个角色组成。
Producer :消息生产者(产生数据的系统)
Consumer :消息消费者(去处理产生的数据的角色)
Broker :MQ服务,负责接收,分发消息(数据存储在broker 也就是mq服务器上,主要负责MQ的内部存储,数据推拉)。
NameServer : 负责MQ服务之间的协调。
(二)Rocket MQ 架构方案
架构图:
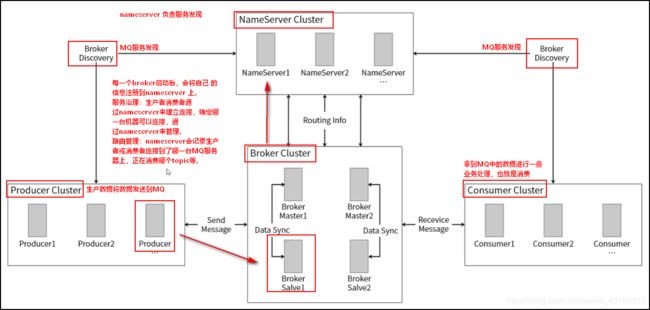
NameServer 提供一个轻量级的服务发现和路由功能。
每一个名称服务器都会记录完整的路由信息,提供相应的读写服务,并支持快速存储扩展。
三、Rocket MQ有序消息
从四个方向学习Rocket MQ的有序消息,由浅入深慢慢消化。
1、有序消息的基本概念。
2、如何保证消息顺序。
3、Rocket MQ的有序消息原理。
4、Rocket MQ的有序消息的使用。
(一)有序消息的基本概念
有序消息即指顺序消息,是指消息的消费顺序和产生顺序相同,在一些特定的业务逻辑下,必须保证顺序。
例如:银行取钱发短信,必须是在取钱后才能给用户发短信。
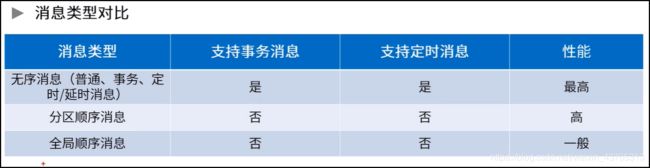
顺序消息分为全局顺序和分区(queue)顺序。
全局顺序:
一个Rocket MQ中只有一个topic,一个topic内所有的消息都发布到同一个queue中,按照先进先出的顺序进行发布和消费。

适用场景:性能要求不高,所有消息严格按照先进先出进行消息发布和消费的场景。
分区顺序(queue):
在Rocket MQ中,并不是所有的消息都需要顺序,将有需要顺序的消息放入到指定一个queue中,所有的消息根据sharding key 进行分区(queue),在同一个queue中是严格的先进先出特性。
sharding key是顺序消息中用来区分不同分区的关键字段,和普通消息的key是完全不同的概念。
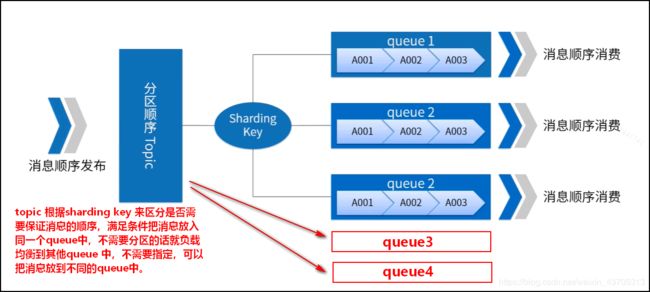
适用场景:性能要求高,根据消息中的sharding key 去决定消息发送到哪一个queue。
//producer
public static void main(String[] args) throws MQClientException, InterruptedException, RemotingException, MQBrokerException, UnsupportedEncodingException {
// 1:创建生产者对象,并指定组名
DefaultMQProducer producer = new DefaultMQProducer("GROUP_TEST");
// 2:指定NameServer地址
producer.setNamesrvAddr(NAME_SERVER_ADDR);
// 3:启动生产者
producer.start();
producer.setRetryTimesWhenSendAsyncFailed(0); // 设置异步发送失败重试次数,默认为2
// 4:定义消息队列选择器
MessageQueueSelector messageQueueSelector = new MessageQueueSelector() {
/**
* 消息队列选择器,保证同一条业务数据的消息在同一个队列
* @param mqs topic中所有队列的集合
* @param msg 发送的消息
* @param arg 此参数是本示例中producer.send的第三个参数
* @return
*/
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
Integer id = (Integer) arg;
// id == 1001
int index = id % mqs.size();
// 分区顺序:同一个模值的消息在同一个队列中
return mqs.get(index);
// 全局顺序:所有的消息都在同一个队列中
// return mqs.get(mqs.size() - 1);
}
};
String[] tags = new String[]{"TagA", "TagB", "TagC"};
List<Map> bizDatas = getBizDatas();
// 5:循环发送消息
for (int i = 0; i < bizDatas.size(); i++) {
Map bizData = bizDatas.get(i);
// keys:业务数据的ID,比如用户ID、订单编号等等
Message msg = new Message("TopicTest", tags[i % tags.length], "" + bizData.get("msgType"), bizData.toString().getBytes(RemotingHelper.DEFAULT_CHARSET));
// 发送有序消息
SendResult sendResult = producer.send(msg, messageQueueSelector, bizData.get("msgType"));
System.out.printf("%s, body:%s%n", sendResult, bizData);
}
// 6:关闭生产者
producer.shutdown();
}//consumer
public static void main(String[] args) throws Exception {
// 1. 创建消费者(Push)对象
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("GROUP_TEST");
// 2. 设置NameServer的地址,如果设置了环境变量NAMESRV_ADDR,可以省略此步
consumer.setNamesrvAddr(NAME_SERVER_ADDR);
/**
* 设置Consumer第一次启动是从队列头部开始消费还是队列尾部开始消费
* 如果非第一次启动,那么按照上次消费的位置继续消费
*/
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
// 3. 订阅对应的主题和Tag
consumer.subscribe("TopicTest", "TagA || TagB || TagC");
// 4. 注册消息接收到Broker消息后的处理接口
// 注1:普通消息消费 [[
// consumer.registerMessageListener(new MessageListenerConcurrently() {
// AtomicInteger count = new AtomicInteger(0);
//
// public ConsumeConcurrentlyStatus consumeMessage(List list, ConsumeConcurrentlyContext consumeConcurrentlyContext) {
// doBiz(list.get(0));
// return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
// }
// });
// ]] 注1:普通消息消费
// consumer
consumer.setMaxReconsumeTimes(-1);
// 延时 level 3
// 注2:顺序消息消费 [[
consumer.registerMessageListener(new MessageListenerOrderly() {
public ConsumeOrderlyStatus consumeMessage(List<MessageExt> msgs,
ConsumeOrderlyContext context) {
context.setAutoCommit(true);
doBiz(msgs.get(0));
return ConsumeOrderlyStatus.SUCCESS;
}
});
// ]] 注2:顺序消息消费
// 5. 启动消费者(必须在注册完消息监听器后启动,否则会报错)
consumer.start();
System.out.println("已启动消费者");
}
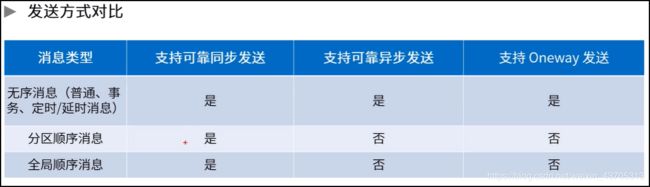
(二)如何保证有序消息
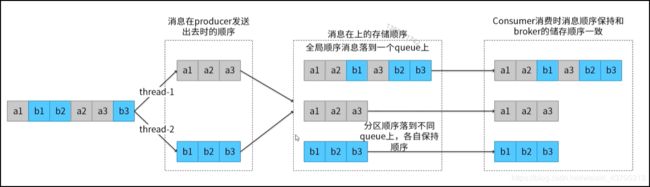
在MQ中顺序消息需要三个阶段步骤去满足:
- 消息被发送时保持顺序。
- 消息被存储时保持和发送的顺序一致。
- 消息被消费时保持和存储的顺序一致。
图解顺序消息:
(三)Rocket MQ的有序消息原理
Rocket MQ顺序消息的实现
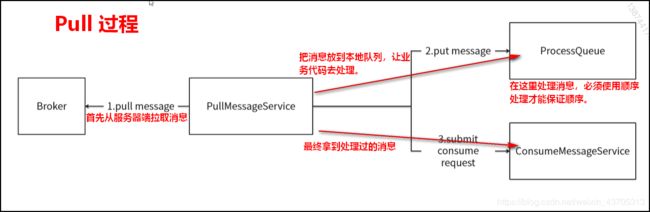
Rocket MQ 消费端有2种类型:MQPullConsumer 和 MQPushConsumer
MQPullConsumer 由用户控制线程,主动从服务端获取消息。每次获取到的都是一个MessageQueue中的消息。
PullResult 中的消息肯定和存储时数据顺序一致,此时需要用户拿到这批消息后自己保证消费的顺序。
MQPushConsumer 底层也是pull机制,是一种API封装,由用户注册MessageListener来消费消息,在客户端需要保证调用MessageListener的时序性。
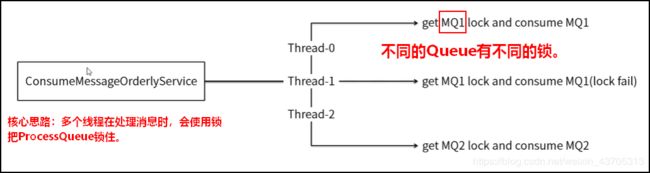
核心思路:多个线程在处理消息时,会使用锁把ProcessQueue锁住。
有序消息的缺陷
- 发送顺序消息无法利用集群的Failover特性,因为不能更换MessageQueue进行重试。
- 由于发送的路由策略导致的热点问题,可能会导致某一些MessageQueue的数据量特别大。
- 消息的并行读取依赖于queue的数量,一个queue对应一个消费者,上限是queue的数量。
- 消息失败无法跳过去,由于是顺序处理,例如第一条处理失败,第二条也会无法处理。
总体来说适应场景不是特别多。
四、Rocket MQ 订阅机制和定时信息
学习路线,由浅入深。
- 发布订阅的基本概念。
- RocketMQ 订阅模式的实现原理。
- 如何使用订阅模式。
- 定时消息的基本概念。
- Broker 定时消息的发送逻辑。
- 如何使用定时消息。
(一)发布订阅的基本概念
发布订阅模式又被称为观察者模式,它定义的是对象间一种 一对多 的依赖关系,当一个对象的状态发生改变 时,所有依赖它的对象都将得到通知。
(二)RocketMQ 订阅模式的实现原理
Rocket MQ的消息订阅模式分为2种模式:
- pull 模式:消费者在需要消息时,主动到服务端Broker拉取。
- push 模式:服务器Broker主动向消费者推送消息。
结论:在Rocket MQ中具体实现,无论是push还是pull 都是采用消费端主动从服务器broker 拉取消息。
push 模式

pull 模式

(三)如何使用RocketMQ 订阅模式
public static void main(String[] args) throws MQClientException {
// 1. 创建消费者(Push)对象
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("GROUP_TEST");
// 2. 设置NameServer的地址,如果设置了环境变量NAMESRV_ADDR,可以省略此步
consumer.setNamesrvAddr("192.168.100.242:9876");
/**
* 设置Consumer第一次启动是从队列头部开始消费还是队列尾部开始消费
* 如果非第一次启动,那么按照上次消费的位置继续消费
*/
consumer.setConsumeFromWhere(ConsumeFromWhere.CONSUME_FROM_FIRST_OFFSET);
/**
* 3. 设置消息模式,默认是CLUSTERING
* MessageModel.BROADCASTING 广播消费模式
* MessageModel.CLUSTERING 集群消费模式
*/
consumer.setMessageModel(MessageModel.BROADCASTING);
// 4. 订阅对应的主题和Tag
consumer.subscribe("TopicTest", "TagA || TagB || TagC");
// 5. 注册消息接收到Broker消息后的处理接口
consumer.registerMessageListener(new MessageListenerConcurrently() {
public ConsumeConcurrentlyStatus consumeMessage(List list, ConsumeConcurrentlyContext consumeConcurrentlyContext) {
MessageExt messageExt = list.get(0);
try {
System.out.printf("线程:%-25s 接收到新消息 %s --- %s %n", Thread.currentThread().getName(), messageExt.getTags(), new String(messageExt.getBody(), RemotingHelper.DEFAULT_CHARSET));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
// 6. 启动消费者(必须在注册完消息监听器后启动,否则会报错)
consumer.start();
System.out.println("已启动消费者");
}
public static void main(String[] args) throws MQClientException, InterruptedException, RemotingException, MQBrokerException, UnsupportedEncodingException {
// 1. 创建生产者对象
DefaultMQProducer producer = new DefaultMQProducer("GROUP_TEST");
// 2. 设置NameServer的地址,如果设置了环境变量NAMESRV_ADDR,可以省略此步
producer.setNamesrvAddr("192.168.100.242:9876");
// 3. 启动生产者
producer.start();
// 4. 生产者发送消息
for (int i = 0; i < 10; i++) {
Message message = new Message("TopicTest", "TagA", "OrderID_" + i, ("Hello Broadcast:" + i).getBytes(RemotingHelper.DEFAULT_CHARSET));
SendResult result = producer.send(message);
System.out.printf("发送结果:%s%n", result);
}
// 5. 停止生产者
producer.shutdown();
}
(四)定时消息的概念
定时消息:指消息发送到Broker后,不可以被consumer立刻消费,要到特定的时间或者等待特定的时间后才能被消费。
如果业务场景需要任意的时间精度,Rocket MQ 服务器Broker层,需要做好消息排序,如果再涉及到持久化,那么消息排序要不可避免的产生巨大的性能开销。
(五)定时消息使用
Rocket MQ支持定时消息,但是不支持任意时间精度,**支持特定的level(延迟级别),比如定时5秒、10秒、1m等。
延迟级别 : 每个级别对应一定的时间,参考下图:

延时消息的使用
public static final String NAME_SERVER_ADDR = "192.168.100.242:9876";
public static void main(String[] args) throws MQClientException, InterruptedException, RemotingException, MQBrokerException, UnsupportedEncodingException {
// 1. 创建生产者对象
DefaultMQProducer producer = new DefaultMQProducer("GROUP_TEST");
// 2. 设置NameServer的地址,如果设置了环境变量NAMESRV_ADDR,可以省略此步
producer.setNamesrvAddr(NAME_SERVER_ADDR);
// 3. 启动生产者
producer.start();
for (int i = 0; i < 10; i++) {
String content = "Hello scheduled message " + new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SS").format(new Date());
Message message = new Message("TopicTest", content.getBytes(RemotingHelper.DEFAULT_CHARSET));
// 4. 设置延时等级,此消息将在10秒后传递给消费者
// 可以在broker服务器端自行配置messageDelayLevel=1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h
message.setDelayTimeLevel(3);
// 5. 发送消息
SendResult result = producer.send(message);
System.out.printf("发送结果:%s%n", result);
TimeUnit.MILLISECONDS.sleep(RandomUtils.nextInt(300, 800));
}
// 6. 停止生产者
producer.shutdown();
}(六)Broker 发送定时消息的逻辑
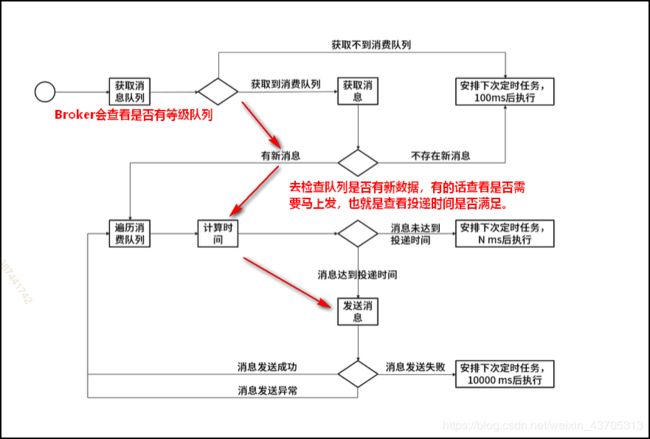
字面理解:这里有一个逻辑的调整,在以前是根据topic来指定queue,但是在定时消息时每一个级别都会对应一个特定的延时queue,有延时消息时会把数据发送到指定级别的延时queue中,在Rocket MQ 中每个延时queue都会维护一份topic的关系,会告诉消费者此延时queue会对应到哪个topic.
五、Rocket MQ 的批量消息和事务消息
(一)批量消息
为什么使用批量消息?
当数据量特别大的时候,为了追求性能,会进行批量处理数据。
使用批量消息的限制:
- 同一个批次的消息应该具有相同的主题,相同的消息配置。
- 不支持延时消息。
- 建议一个批量消息大小最好不要超过1MB。(官方建议)
(二)事务消息
什么是事务消息?
Rocket MQ的事务消息,是指Produce端消息发送事件和本地事务事件,同时成功或同时失败。
举例:创建一个用户,会向用户系统发送信息,先发送消息到mqserver,mqserver接收消息成功,此时ma发送方会关联本地事务也就是数据进表,当插入数据失败,整个事务回滚。插入数据成功,commit ,mq事务提交,Mq.如果长时间没有提交,mq broker会主动向发送方发起查询, 查看事务状态,检查本地事务状态。完成的话再去提交commit 或者没有完成就Rollback.
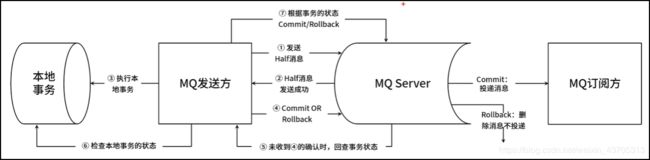
事务消息的使用约束:
事务消息不支持定时消息和批量消息。
为了避免一个消息被多次检查,导致半数队列消息堆积。默认检查15次,这个参数可以配置broker配置文件中的transactionCheckMax参数进行调整。
也可以设置特定的时间段之后才检查事务。修改配置文件参数transactionTimeOut或者用户设置CHECK_IMMUNITY_TIME_IN_SECONDS调整时间。
一个事务消息可以被多次检查或者多次消费。
提交过的消息重新放到用户目标主题可能会失败。
事务消息的生产者ID不能与其他类型消息的生产者ID共享。(生产事务消息职责单一不能混淆)
事务的消息状态
- TransactionStatus.CommitTransaction —>提交事务,允许消费者消费这个消息。
- TransactionStatus.RollbackTransaction —>回滚事务,消息不允许被消费,或者将被删除。
- TransactionStatus.Unknown —>中间状态 ,MQ需要重新检查来确定状态。
六、Rocket MQ 的高性能最佳实践
- 最佳实践之Producer
- 最佳实践之Consumer
- 最佳实践之NameServer
- JVM与Linux内核配置
(一)最佳实践之Producer
1、一个应用尽可能使用一个Topic,消息子类型使用tags来标识,tags可以由应用自由设置,降低服务器的管理复杂性。只有发送消息设置了tags,消费方才能在订阅消息时,才可以利用tags在服务器端进行消息过滤。
message.setTags("TagA");2、保证每条消息在业务层面有唯一标识码,要设置到keys字段,方便将来定位消息丢失问题。服务器会为每条消息创建一个哈希索引,应用可以通过topic,key 来查询这条消息内容,以及消息被谁消费。由于是哈希索引,一定要保证key唯一,这样可以避免潜在的哈希冲突。建议keys设置为类似订单ID之类业务层保证唯一。
message.setKeys("orderID");
3、如果有可靠性需要,消息发送成功或者失败,要打印消息日志(sendResult和key 信息)。
4、如果使用相同性质的消息量大,使用批量信息可以提升性能。
5、建议消息大小不要超过512kb。
6、send(msg)会阻塞,如果有性能要求,可以使用异步的方式:send(msg,callback)。
7、如果在一个jvm中,有多个生产者进行大数据处理建议:
- 少数生产者使用异步发送方式(3-5)
- 通过setInstanceName方法,给每一个生产者设置一个实列名称。
8、send消息方法,只要不抛异常,就代表发送成功,但是发送成功会有多个状态,在sendResult中定义。
-
SEND_OK: 消息发送成功。
-
FLUSH_DISK_TIMEOUT: 消息发送成功,但是服务器刷盘超时,消息已经进入服务器队列,只有此时服务器宕机,消息才会丢失。
-
FLUSH_SLAVE_TIMEOUT: 消息发送成功,但是服务器同步到Slave时超时,数据已经进入服务器队列,只有此时服务器宕机,消息才会丢失。
-
SLAVE_NOT_AVAILABLE: 消息发送成功,但是此时slave不可用,消息已经进入服务器队列,只有此时服务器宕机,消息才会丢失。
-
Producer 向broker发送请求后会等待响应,但是如果达到最大等待时间,没有得到响应,则客户端将抛出RemotingTimeoutException异常。默认等待时间为3 秒,如果使用send(msg,timeout); 也可以自己设定超时时间,但是超时时间不能设置太小,应该为broker留一些时间来刷盘以及和Slave同步数据。如果该值超过同步刷新超时时间(服务端进行配置),该值几乎没有作用,因为服务器可能会在超时之前返回FLUSH_DISK_TIMEOUT 和 FLUSH_SLAVE_TIMEOUT 的状态响应。
9、对于消息不可丢失应用,务必要有消息重发机制。
Producer的send方法本身支持内部重试,最多重试三次,如果发送失败,就会轮转到下一个Broker,这个方法的总耗时不能超过sendMsgTimeout设置的值,默认10S,所以如果本身向broker发送消息产生超时异常就不会再做重试。但是这些依然不能保证消息一定成功,为了保证消息一定成功,建议把消息存储到DB,由后台线程定时重试,保证消息一定到达broker。
结论:如果状态为 FLUSH_DISK_TIMEOUT 和 FLUSH_SLAVE_TIMEOUT,并且服务器broker正好关闭,此时可以丢弃这条消息,或者重发。一般建议重发,由消费端进行处理去重。
(二)最佳实践之Consumer
消费者组和订阅:
不同的消费群体(group)可以独立的消费同样的主题,并且每一个消费者都会有自己的消费偏移量(offset)
顺序消息:
消费者将锁定每一个messageQueue,以确保每一个消息被按照顺序使用,这将导致性能损耗。
如果关心消息的顺序,不建议返回异常,可以返回状态码。ConsumerOrderlyStatus.SUSPEND_CURRENT_QUEUE_A_MOMENT
消费状况:
对于MessageListenerConcurrently,可以返回RECONSUME_LATER告诉消费者,当前不能消费它并且希望以后重新消费。
可以返回ConsumerOrderlyStatus.SUSPEND_CURRENT_QUEUE_A_MOMENT状态码,让当前的queue稍等一下再重发数据。
线程数:
在消费者端,使用一个ThreadPoolExecuter来处理内部的消费,因此可以设置setConsumerThreadMin和setConsumerThreadMax来改变线程数。
偏移量:
当建立一个消费者group时,需要决定是否需要消费broker中已经存在的历史消息。
设置CONSUMER_FROM_LAST_OFFSET将会忽略历史消息,并消费此后生成的任何内容。
CONSUMER_FROM_LAST_OFFSET将消耗broker中存在的所有消息,可以使用CONSUMER_FROM_TIMESTAMP来消费指定时间戳之后生成的消息。
重复消息:
RocketMQ 无法避免消息重复,如果业务对重复消息敏感,务必在业务层做去重。可以使用记录消息的唯一键去重,也可以在业务层使用状态机制去重。
(三)最佳实践之NameServer
在RocketMQ 中,nameServer用于协调分布式系统的每一个组件,主要通过管理主题路由信息来实现协调。
管理有俩部分组成:
- Broker会定期更新保存在每一个名称服务器中的元数据。
- 名称服务器为客户端提供最新路由信息服务,包括生产者、消费者、命令行客户端。
结论:在启动broker和client之前,我们需要提供一个nameServer服务器。供他们访问。名称服务器之间是不会交互数据的,只会和broker以及client交互。
四种方式完成:

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BW8oeP8E-1589700702363)(C:\Users\10674\AppData\Roaming\Typora\typora-user-images\1589694001886.png)]](http://img.e-com-net.com/image/info8/fc6ba60915f6488c882b291e580b5d37.jpg)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ESZuoQZd-1589700702365)(C:\Users\10674\AppData\Roaming\Typora\typora-user-images\1589694028267.png)]](http://img.e-com-net.com/image/info8/f0a4d6f21ab548b6ae1d427d69edf676.jpg)

优先级顺序:代码 > java参数 > 环境变量 > HTTP
(四)最佳实践之JVM 和 Linux 内核配置
jvm 的配置
1、推荐使用jdk1.8,使用服务器编译器和8G堆,设置相同的Xms和Xmx,防止JVM调整 堆大小,来获得更好的性能。
-server -Xms8g -Xmx8g -Xmn4g
2、如果不关心Broker的启动时间,可以预先触摸java堆,以确保jvm初始化期间分配页是更好的选择。
-XX : + AlwaysPreTouch
3、禁用偏向锁 可能会减少JVM的暂停
-XX:UserBiasedLocking
4、对于垃圾回收建议使用G1收集器
![]()
这样设置在生产环境中具有良好的作用。
-XX : MaxGCPauseMills不可以设置太小的值,否则jvm会产生一个小的新生代,这会导致非常频繁的新生代GC.
5、推荐使用滚动GC日志文件
![]()
6、如果写入GC文件会增加代理的延迟,请将重定向GC日志文件考虑在内存文件系统中。
![]()
Linux 内核配置