python读取micaps资料并可视化(scatter+contourf)介绍
文章目录
- 1 micaps资料类型
- 1.1 micaps介绍
- 1.2 micaps资料类型
- 2 micaps资料读取
- 2.1 数据预处理
- 2.2 地面填图
- 2.3 physic资料
- 2.4 ecmwf-thin资料
1 micaps资料类型
1.1 micaps介绍
micaps(Meteorology Information Comprehensive Analysis Process System)是气象上业务分析常用的软件。

大体这样的一个界面。借助这样的软件,可以综合系统的进行地面、高空、卫星等等各种气象数据的查看。
micaps下载链接
1.2 micaps资料类型
micaps4帮助文档

以第一类数据格式:地面全要素填图数据 为例:

我们使用记事本打开一个文件:

凡是记事本能打开的数据,我们都能用python来进行读取。
下面将介绍几种常用的micaps气象数据的python读取方法
2 micaps资料读取
2.1 数据预处理
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.interpolate import griddata
import os
from mpl_toolkits.basemap import Basemap
import numpy.ma as ma
f=open(filename,mode='r')
#此时每行的都为 字符格式
str_data = f.readlines()
data = []
for i in range(len(str_data)):
#将每行的字符类型的数字转为float型,如果某一行存在非数字字符,则跳过该行
try:
#依次读取每一行数据
line_data = str_data[i]
#如果该行为空(只有换行符),则跳过;否则,将其转换为数值型
if len(line_data)>1:
#去除换行符并将每个字符数据分开
line_data = line_data.strip().split()
#将数据类型由str转换为float型
line_data=[float(line_data[i]) for i in range(len(line_data))]
#将每一行变成 (1,n)的array数组
line_data = np.array(line_data).reshape(1,-1)
data.append(line_data)
except Exception as e:
print('第{:}行含有非数字字符 '.format(i))
print(e)
print()
pass
我们选取一个 micaps/surface/plot/18080405.000 文件为例:
- 先用记事本打开,部门内容如下:

- 用上述代码打开: filename = ‘/micaps/surface/plot/18080405.000’

-
可以看到,第一个str_data 每一行和记事本打开的一样,但都是 str即字符 类型。
-
变成 data后,每一行依然内容不变,但是格式变成了float 的数组。点开第二行,数值和txt的第三行完全一致;-
-
变成数组之后,就可以很方便的进行后续操作。eg: 由数据说明可知:每一个站点 是一个长度为26的数组,也就是说 data列表中,data[1] + data[2] 才是一个站点的 完整观测信息;
后续大多micaps类型的数据读取,都需要先进行这样的操作。
2.2 地面填图
- 数据读取
一般在surface/plot这个路径下。
def get_station_data(filename):
'''
func: 获取站点观测数据
inputs:
filename: 文件名
file_type : 'plot'
surface/plot类型的数据存储方式为:
第0行:数据的时间信息
之后,每一个站点的信息占据两行: 站台号 经纬度 观测要素 等信息;
return:
station_data 每一行都是一个站点的信息
'''
f=open(filename,mode='r')
#此时每行的都为 字符格式
str_data = f.readlines()
data = []
for i in range(len(str_data)):
#将每行的字符类型的数字转为float型,如果某一行存在非数字字符,则跳过该行
try:
#依次读取每一行数据
line_data = str_data[i]
#如果该行为空(只有换行符),则跳过;否则,将其转换为数值型
if len(line_data)>1:
#去除换行符并将每个字符数据分开
line_data = line_data.strip().split()
#将数据类型由str转换为float型
line_data=[float(line_data[i]) for i in range(len(line_data))]
# line_data = np.array(line_data).reshape(1,-1)
data.append(line_data)
except Exception as e:
print('第{:}行含有非数字字符 '.format(i))
print(e)
print()
pass
#第一行表示时间信息
# T = data[0]
station_data = []
for i in range(len(data[1::2])):
station_data.append(data[i*2+1]+data[i*2+2])
station_data = [np.array(station_data[i]).reshape(1,-1) for i in range(len(station_data))]
station_data = np.concatenate(station_data,axis=0)
return station_data
还是以 filename = '/micaps/surface/plot/18080405.000’为例:
![]()

即每一行就是一个站点的完备观测信息:
-
站点数据绘制
def scatter_station_on_map(station_lon,station_lat,station_value, fill_value=9999, loc_range = [18,54,73,135],det = 5): ''' func: 将站点位置,根据站点要素值大小,scatter到地图底图上 inputs: station_lon: 站点的经度 station_lat: 站点的纬度 station_value: 对应站点的要素值 上述三个数据类型 可以是 数组,也可以是 列表 fill_value : 缺测填充值.默认为 9999; loc_range: scatter区域范围。默认范围为中国大陆区域 [18,54,73,135] = [lat_min,lat_max,lon_min,lon_max] ''' #step1: 先将station数据转换一下格式 station_lon = np.array(station_lon).reshape(-1,1).ravel() station_lat = np.array(station_lat).reshape(-1,1).ravel() #使用mask数组;将value=fill_value的值跳过; #mask数组的好处在于:在后续数值运算或者画图中,会自动跳过fille_value值 station_value = np.array(station_value).reshape(-1,1).ravel() mask = station_value == fill_value station_value = ma.array(station_value,mask=mask) lat_min = loc_range[0] lat_max = loc_range[1] lon_min = loc_range[2] lon_max = loc_range[3] fig = plt.figure(figsize=(14,8)) ax1 = fig.add_axes([0.1,0.1,0.8,0.8]) m=Basemap(projection='cyl',llcrnrlat=lat_min,llcrnrlon=lon_min, urcrnrlat=lat_max,urcrnrlon=lon_max,resolution='l',ax=ax1) #读取省界数据。下载省界数据链接为:https://blog.csdn.net/weixin_36677127/article/details/83314583 m.readshapefile('D:/geo_data/gadm36_CHN_shp/gadm36_CHN_1','states', drawbounds=True) h = m.scatter(station_lon,station_lat, s = station_value, #marker大小与数值相关 c = station_value, #颜色深浅与数值大小相关 cmap = plt.cm.rainbow, ) cb = m.colorbar(h,size = '4%') cb.set_label('',fontsize = 20) cb.ax.tick_params(labelsize=16) x_grid = np.arange(lon_min,lon_max+1,det) y_grid = np.arange(lat_min,lat_max+1,det) m.drawparallels(x_grid) m.drawmeridians(y_grid) plt.grid() plt.xticks(x_grid,x_grid,fontsize = 16) plt.yticks(y_grid,y_grid,fontsize = 16) plt.xlabel('longitude: °E',fontsize = 16) plt.ylabel('latitude: °N',fontsize = 16) # plt.title(u'中国站点分布',fontsize = 20) #画出海岸线和国境线 m.drawcoastlines() m.drawcounties() m.drawcountries() return None
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.interpolate import griddata
import os
from mpl_toolkits.basemap import Basemap
import numpy.ma as ma
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
#有中文出现的情况,需要u'内容'
f2 = 'surface/plot/18080405.000'
plot_p = get_station_data(f2)
scatter_station_on_map(station_lon = plot_p[:,1],station_lat = plot_p[:,2],
station_value = plot_p[:,19]) #plot_p[:,19]为地面温度
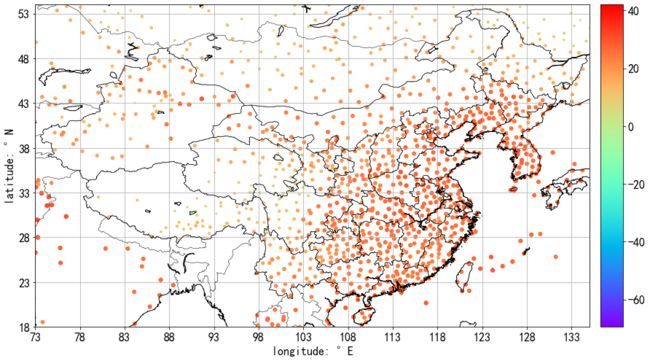

在这里插入图片描述
由这段代码可知,温度越高,颜色越深,小圆圈越大。从这张图可以大概看出中国测站的分布密集程度,与经济和人口是息息相关的 。另外,还可以看出,黑龙江、西藏、兰州、云南都是避暑胜地啊!
2.3 physic资料
- 获取physic资料,路径在 /micaps/physic路径下:
def get_physic_data(filename,plot = True,label_gap = 10):
'''
doc: physic类型的数据,只有08时和20时有;空间分辨率为 2*2°
fun: 获取micaps/physic的数据,转换为矩阵形式
physic类型的数据存储形式为:
第0行为时间信息
第1行为 经纬度网格信息
第2行为 网格shape
从第2行开始,现实中的每一行数据(纬向方向)由 6行组成;
#eg: shape为 29*53,每一行数据有53个数据;而在存储时,每10个数据占据一行,
# 剩下3个数据独占一行,因此 6行对应1行;
input:
file: 文件名
plot: 默认True,数据可视化
label_gap: Plot中,x和y label的坐标经纬度间隔;默认为10
return:
lon_grid : 经度网格信息
lat_grid : 纬度网格信息
rain_grid:数值
以list形式返回
[lon_grid,lat_grid,physic_data]
'''
f=open(filename,mode='r')
#此时每行的都为 字符格式
str_data = f.readlines()
data = []
for i in range(len(str_data)):
#将每行的字符类型的数字转为float型,如果某一行存在非数字字符,则跳过该行
try:
#依次读取每一行数据
line_data = str_data[i]
#如果该行为空(只有换行符),则跳过;否则,将其转换为数值型
if len(line_data)>1:
#去除换行符并将每个字符数据分开
line_data = line_data.strip().split()
#将数据类型由str转换为float型
line_data=[float(line_data[i]) for i in range(len(line_data))]
# line_data = np.array(line_data).reshape(1,-1)
data.append(line_data)
except Exception as e:
print('第{:}行含有非数字字符 '.format(i))
print(e)
print()
pass
#第0行为时间信息
#第1行为 经纬度网格信息
# T = data[0]
loc_info = data[1]
det_lat = abs(loc_info[0])
det_lon = abs(loc_info[1])
lon_max = loc_info[3]
lon_min = loc_info[2]
lat_max = loc_info[4]
lat_min = loc_info[5]
lat_range = np.arange(lat_min,lat_max+det_lat,det_lat)
lon_range = np.arange(lon_min,lon_max+det_lon,det_lon)
lon_grid,lat_grid = np.meshgrid(lon_range,lat_range)
#使得高纬度在上(0行为最高纬度)
lat_grid = lat_grid[-1::-1,:]
#获取每行的最大数据序列长度,一般为 10
length = len(data[3])
#一个完整序列,对应多少行,这里为6
k = int(np.ceil(len(lon_range)/length))
physic_data = []
for i in range(len(lat_range)):
a = []
for j in range(k):
a = a+data[i*k+3+j]
a = np.array(a).reshape(1,-1)
physic_data.append(a)
physic_data = np.concatenate(physic_data,axis = 0)
if plot:
plt.figure(figsize = (12,8))
cs = plt.contourf(physic_data[-1::-1], #Plt.contourf默认将第一行画在最底部
extend='both') #extend参数使得colorbar两端变尖
#cs.cmap.set_over('red')
#cs.cmap.set_under('blue')
#cs.changed()
cb = plt.colorbar(cs)
cb.ax.tick_params(labelsize=16) #设置色标刻度字体大小。
plt.xticks(fontsize=16)
plt.yticks(fontsize=16)
font = {'family' : 'serif',
'color' : 'darkred',
'weight' : 'normal',
'size' : 20,
}
cb.set_label('',fontdict=font) #设置colorbar的标签字体及其大小
#确定横纵坐标轴的gap
#label_gap = label_gap
label_gap = 10
plt.xticks(np.arange(0,len(lon_range),label_gap/det_lon), np.arange(lon_min,lon_max+1,label_gap,dtype = int),fontsize = 16)
plt.yticks(np.arange(0,len(lat_range),label_gap/det_lat), np.arange(lat_min,lat_max+1,label_gap,dtype = int),fontsize = 16)
plt.xlabel("longitude°E",fontsize = 20)
plt.ylabel("latitude°N",fontsize = 20)
plt.title(filename,fontsize = 20)
return [lon_grid,lat_grid,physic_data]
-
数据可视化,叠加在 地图底图上
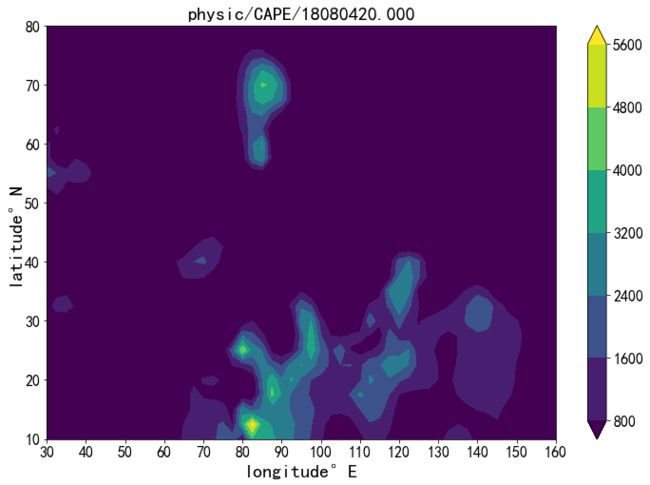
def contourf_data_on_map(data,lon_grid,lat_grid,gap = 5): ''' func: 传入数据和对应的经纬范围,将数据叠加在地图底图上 inputs: data: 网格数据 lon_grid : 网格经度 lat_grid :网格纬度 gap : 地图上横纵坐标显示的经纬度数值间隔。即tick_gap return 输出一张图 return None ''' lat_min = np.min(lat_grid) lat_max = np.max(lat_grid) lon_min = np.min(lon_grid) lon_max = np.max(lon_grid) # det_grid = lon_grid[0,1]-lon_grid[0,2] fig = plt.figure(figsize=(14,8)) ax1 = fig.add_axes([0.1,0.1,0.8,0.8]) m=Basemap(projection='cyl',llcrnrlat=lat_min,llcrnrlon=lon_min, urcrnrlat=lat_max,urcrnrlon=lon_max,resolution='l',ax=ax1) m.readshapefile('D:/geo_data/gadm36_CHN_shp/gadm36_CHN_1','states', drawbounds=True) #若lat_grid高纬度值在最上面,则将数据做对应行数反转; #因为使用m.contourf时,默认低纬在上 if lat_grid[0,0] == lat_max: lat_grid = lat_grid[-1::-1] data = data[-1::-1] h = m.contourf(lon_grid,lat_grid,data, # levels= np.arange(0,32+1,4), extend='both', cmap = plt.cm.rainbow) cb = m.colorbar(h,size = '4%') cb.set_label('',fontsize = 20) cb.ax.tick_params(labelsize=16) x_grid = np.arange(lon_min,lon_max+gap,gap,dtype = int) y_grid = np.arange(lat_min,lat_max+gap,gap,dtype = int) m.drawparallels(x_grid) m.drawmeridians(y_grid) plt.grid() plt.xticks(x_grid,x_grid,fontsize = 18) plt.yticks(y_grid,y_grid,fontsize = 18) plt.xlabel('longitude: °E',fontsize = 20) plt.ylabel('latitude: °N',fontsize = 20) # plt.title(filename,fontsize = 20) # plt.title(u'中国站点分布',fontsize = 20) #画出海岸线和国境线 m.drawcoastlines() m.drawcounties() m.drawcountries() plt.show() return Nonef3 = 'physic/CAPE/18080420.000' physic_data = get_physic_data(f3,plot = True) contourf_data_on_map(physic_data[2],physic_data[0],physic_data[1],gap=10)
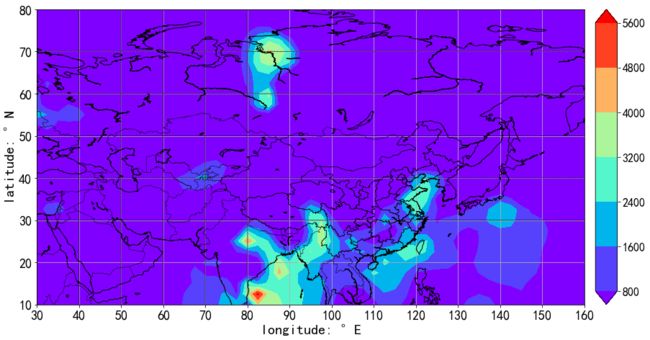
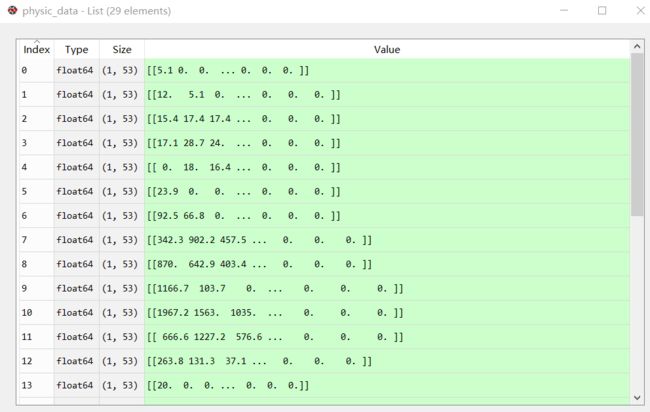
2.4 ecmwf-thin资料
-
读取数据
def get_EC_thin_physic_data(filename,plot = True,label_gap = 2): ''' func:获取EC_thin/physic 或者 EC_thin路径下的物理量,默认EC_thin的数据是 等经纬网格的; doc: 空间分辨率为 0.125*0.125 或者 0.25*0.25 ; 时间分辨率为3小时 physic类型的数据存储形式为: 第0行为时间信息 第1行为 经纬度网格信息,包括场数据的shape, 从第2行开始,现实中的每一行数据(纬向方向)由 9行组成; #eg: shape为 81*81,每一行数据有81个数据;而在存储时,每10个数据占据一行, # 剩下1个数据独占一行,因此 9行对应1行; input: filename: 文件名 plot: 默认True,绘制物理量场 label_gap: Plot中,x和y label的坐标经纬度间隔 return: lon_grid : 场对应的经度信息 lat_grid : 场对应的纬度信息 rain_grid:场数值 以list形式返回 [lon_grid,lat_grid,rain_grid] ''' f=open(filename,mode='r') #此时每行的都为 字符格式 str_data = f.readlines() data = [] for i in range(len(str_data)): #将每行的字符类型的数字转为float型,如果某一行存在非数字字符,则跳过该行 try: #依次读取每一行数据 line_data = str_data[i] #如果该行为空(只有换行符),则跳过;否则,将其转换为数值型 if len(line_data)>1: #去除换行符并将每个字符数据分开 line_data = line_data.strip().split() #将数据类型由str转换为float型 line_data=[float(line_data[i]) for i in range(len(line_data))] line_data = np.array(line_data).reshape(1,-1) data.append(line_data) except Exception as e: print('第{:}行含有非数字字符 '.format(i)) print(e) print() pass #第0行为时间信息 #第1行为 经纬度网格信息 # T = data[0] loc_info = data[1] det_lat = abs(loc_info[0,0]) det_lon = abs(loc_info[0,1]) lon_max = loc_info[0,3] lon_min = loc_info[0,2] lat_max = loc_info[0,4] lat_min = loc_info[0,5] lat_range = np.arange(lat_min,lat_max+det_lat,det_lat) lon_range = np.arange(lon_min,lon_max+det_lon,det_lon) lon_grid,lat_grid = np.meshgrid(lon_range,lat_range) lat_grid = lat_grid[-1::-1,:] #获取等经纬度场数据,并可视化; #从第二行开始 length = data[2].shape[1] #判断每一行存储的数据个数(一般是 10), #而一般的场的shape是 81*81,因此需要 int(np.ceil(81/10)) = 9 行 #来表示真实场的一行数据 k = int(np.ceil(lat_grid.shape[1]/length)) tp = [] for i in range(lat_grid.shape[0]): tp_line = [] for j in range(k): tp_line = tp_line+list(data[i*k+2+j].ravel()) tp_line = np.array(tp_line).reshape(1,-1) tp.append(tp_line) tp = np.concatenate(tp,axis = 0) #将降水场可视化出来 if plot: plt.figure(figsize = (16,10)) cs = plt.contourf(tp[-1::-1], # levels= np.arange(0,32+1,4), extend='both', cmap = plt.cm.rainbow) #extend参数使得colorbar两端变尖 #cs.cmap.set_over('red') #cs.cmap.set_under('blue') #cs.changed() cb = plt.colorbar(cs) cb.ax.tick_params(labelsize=16) #设置色标刻度字体大小。 plt.xticks(fontsize=16) plt.yticks(fontsize=16) font = {'family' : 'serif', 'color' : 'darkred', 'weight' : 'normal', 'size' : 20, } cb.set_label('',fontdict=font) #设置colorbar的标签字体及其大小 #确定横纵坐标轴的gap label_gap = label_gap plt.xticks(np.arange(0,len(lon_range),label_gap/det_lon), np.arange(lon_min,lon_max+1,label_gap,dtype = int),fontsize = 16) plt.yticks(np.arange(0,len(lat_range),label_gap/det_lat), np.arange(lat_min,lat_max+1,label_gap,dtype = int),fontsize = 16) plt.xlabel("longitude°E",fontsize = 20) plt.ylabel("latitude°N",fontsize = 20) plt.title(filename,fontsize = 20) physic_info = [lon_grid,lat_grid,tp] return physic_info运行代码:
f4 = 'ecmwf_thin/T/1000/18080408.006' ec_T = get_EC_thin_physic_data(f4,plot=True) contourf_data_on_map(ec_T[2],ec_T[0],ec_T[1])
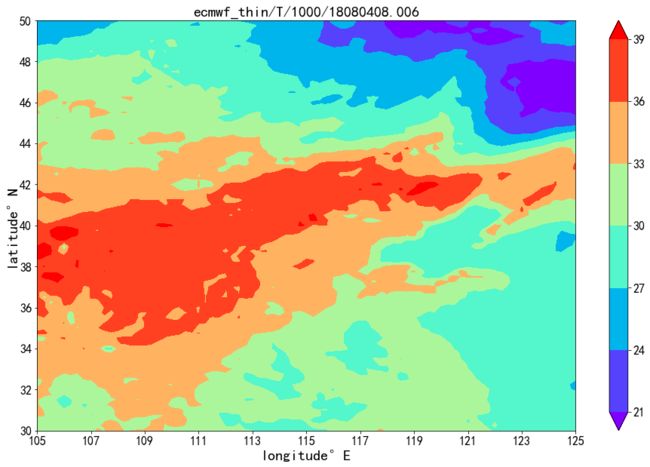
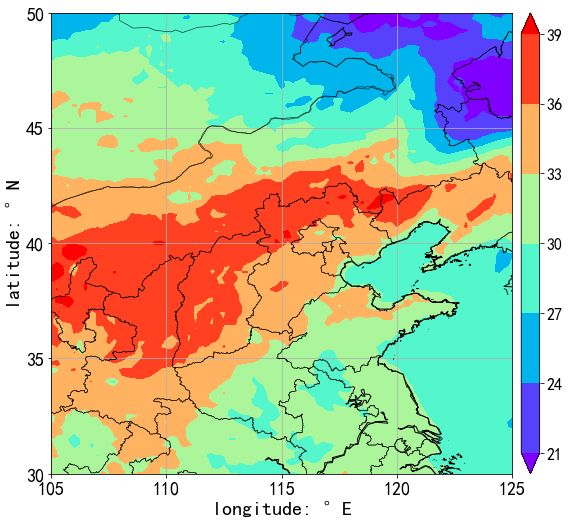

右边三个数组是左边列表的展开:依次为:等经度网格、等纬度网格、网格数值场
其他类型的micaps数据,读取方法大同小异。最重要的是理解这个数据是什么,有什么意义,怎么存储的!