大数据【企业级360°全方位用户画像】匹配型标签累计开发
写在前面: 博主是一名软件工程系大数据应用开发专业大二的学生,昵称来源于《爱丽丝梦游仙境》中的Alice和自己的昵称。作为一名互联网小白,
写博客一方面是为了记录自己的学习历程,一方面是希望能够帮助到很多和自己一样处于起步阶段的萌新。由于水平有限,博客中难免会有一些错误,有纰漏之处恳请各位大佬不吝赐教!个人小站:http://alices.ibilibili.xyz/ , 博客主页:https://alice.blog.csdn.net/
尽管当前水平可能不及各位大佬,但我还是希望自己能够做得更好,因为一天的生活就是一生的缩影。我希望在最美的年华,做最好的自己!
在前面的博客中,博主已经为大家带来了关于大数据【用户画像】项目匹配型标签开发的一个步骤流程(大数据【企业级360°全方位用户画像】匹配型标签开发)。本篇博客带来的同样是匹配型标签的开发,不同于之前的是,本次标签开发需要将最终的结果与之前的用户标签数据进行合并,而并非是覆写!
想知道如何实现的朋友可以点个关注,我们继续往下看。

文章目录
- 匹配型标签开发
- 书写代码
- <1>创建一个sparksession
- <2>连接MySQL
- <3>读取四级标签数据
- <4> 读取五级标签数据
- <5> 读取Hbase中的数据
- <6> 标签匹配
- <7>读取hbase中历史数据,与新数据合并
- <8>将最终结果写入到Hbase(数据覆盖)
- 过程小结
- 小结
匹配型标签开发
本次我们开发的仍然是匹配型标签,以Hbase中用户表的job字段为例。我们做一个用户的job标签匹配。
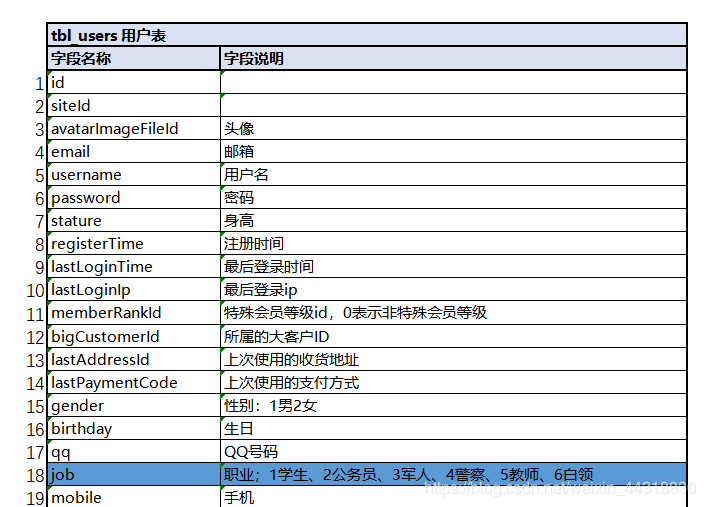
获悉需求之后,我们在web页面上通过手动添加的方式,添加了四级标签 职业,五级标签 不同的职业名称。
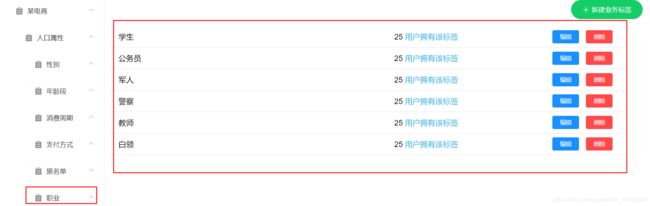
添加完毕,我们可以在MySQL数据库中找到对应的数据信息

再去查看Hbase表中是否存在job列的数据
scan "tbl_users",{COLUMNS => "detail:job",LIMIT => 5}

确认了MySQL和Hbase中都有job的数据后,我们就可以愉快地写代码了~

书写代码
<1>创建一个sparksession
为了后面我们好通过观察控制台,分析数据的变化过程,我们还可以设置日志级别,减少程序运行时不必要冗余信息出现在控制台。
// 1. 创建SparkSQL
// 用于读取mysql , hbase等数据
val spark: SparkSession = SparkSession.builder().appName("JobTag").master("local[*]").getOrCreate()
// 设置日志级别
spark.sparkContext.setLogLevel("WARN")
<2>连接MySQL
我们肯定是需要先读取MySQL中的四级和五级的标签数据的,这里我们先进行MySQL数据库的连接。
// 设置Spark连接MySQL所需要的字段
var url: String ="jdbc:mysql://bd001:3306/tags_new2?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC&user=root&password=123456"
var table: String ="tbl_basic_tag" //mysql数据表的表名
var properties:Properties = new Properties
// 连接MySQL
val mysqlConn: DataFrame = spark.read.jdbc(url,table,properties)
<3>读取四级标签数据
这一步,我们正式开始读取MySQL中的四级标签数据,为了方便在其他地方调用,这里我们还创建了一个方法,用于将MySQL中的数据存入Map后又用样例类进行封装。
需要注意的是,在进行DataSet转换成Map,或者List的时候,需导入隐式转换,不然程序会报错
// 引入隐式转换
import spark.implicits._
//引入java 和scala相互转换
import scala.collection.JavaConverters._
//引入sparkSQL的内置函数
import org.apache.spark.sql.functions._
// 3. 读取MySQL数据库的四级标签
val fourTagsDS: Dataset[Row] = mysqlConn.select("id","rule").where("id=65")
val KVMaps: Map[String, String] = fourTagsDS.map(row => {
// 获取到rule值
val RuleValue: String = row.getAs("rule").toString
// 使用“##”对数据进行切分
val KVMaps: Array[(String, String)] = RuleValue.split("##").map(kv => {
val arr: Array[String] = kv.split("=")
(arr(0), arr(1))
})
KVMaps
}).collectAsList().get(0).toMap
println(KVMaps)
var hbaseMeta:HBaseMeta=toHBaseMeta(KVMaps)
其中样例类代码为
//将mysql中的四级标签的rule 封装成HBaseMeta
//方便后续使用的时候方便调用
def toHBaseMeta(KVMap: Map[String, String]): HBaseMeta = {
//开始封装
HBaseMeta(KVMap.getOrElse("inType",""),
KVMap.getOrElse(HBaseMeta.ZKHOSTS,""),
KVMap.getOrElse(HBaseMeta.ZKPORT,""),
KVMap.getOrElse(HBaseMeta.HBASETABLE,""),
KVMap.getOrElse(HBaseMeta.FAMILY,""),
KVMap.getOrElse(HBaseMeta.SELECTFIELDS,""),
KVMap.getOrElse(HBaseMeta.ROWKEY,"")
)
}
<4> 读取五级标签数据
这一步,我们通过手动添加的标签值对应的pid,将该标签下的5级标签全部获取。并将返回的每条数据封装成样例类,所有结果保存在了一个List中。
//4. 读取mysql数据库的五级标签
// 匹配职业
val fiveTagsDS: Dataset[Row] = mysqlConn.select("id","rule").where("pid=65")
// 将FiveTagsDS 封装成样例类TagRule
val fiveTageList: List[TagRule] = fiveTagsDS.map(row => {
// row 是一条数据
// 获取出id 和 rule
val id: Int = row.getAs("id").toString.toInt
val rule: String = row.getAs("rule").toString
// 封装样例类
TagRule(id,rule)
}).collectAsList() // 将DataSet转换成util.List[TagRule] 这个类型遍历时无法获取id,rule数据
.asScala.toList // 将util.List转换成list 需要隐式转换 import scala.collection.JavaConverters._
for(a<- fiveTageList){
println(a.id+" "+a.rule)
}
<5> 读取Hbase中的数据
基于第三步我们读取的四级标签的数据,我们可以通过配置信息从Hbase中读取数据,只不过跟之前一样,为了加快读取Hbase的时间,我们将其作为一个数据源来读取,而并非传统的客户端进行读取。
// 读取hbase中的数据,这里将hbase作为数据源进行读取
val hbaseDatas: DataFrame = spark.read.format("com.czxy.tools.HBaseDataSource")
// hbaseMeta.zkHosts 就是 192.168.10.20 和 下面是两种不同的写法
.option("zkHosts",hbaseMeta.zkHosts)
.option(HBaseMeta.ZKPORT, hbaseMeta.zkPort)
.option(HBaseMeta.HBASETABLE, hbaseMeta.hbaseTable)
.option(HBaseMeta.FAMILY, hbaseMeta.family)
.option(HBaseMeta.SELECTFIELDS, hbaseMeta.selectFields)
.load()
// 展示一些数据
hbaseDatas.show(5)
//| id|job|
//+---+---+
//| 1| 3|
//| 10| 5|
//|100| 3|
//|101| 1|
//|102| 1|
//+---+---+
<6> 标签匹配
这一步我们需要根据hbase数据和五级标签的数据进行标签匹配。
需要注意的是,匹配的时候需要使用到udf函数。
// 需要自定义UDF函数
val getUserTags: UserDefinedFunction = udf((rule: String) => {
// 设置标签的默认值
var tagId: Int = 0
// 遍历每一个五级标签的rule
for (tagRule <- fiveTageList) {
if (tagRule.rule == rule) {
tagId = tagRule.id
}
}
tagId
})
// 6、使用五级标签与Hbase的数据进行匹配获取标签
val jobNewTags : DataFrame = hbaseDatas.select('id.as ("userId"),getUserTags('job).as("tagsId"))
jobNewTags.show(5)
//+------+------+
//|userId|tagsId|
//+------+------+
//| 1| 68|
//| 10| 70|
//| 100| 68|
//| 101| 66|
//| 102| 66|
//+------+------+
<7>读取hbase中历史数据,与新数据合并
从这一步开始,真正与之前匹配完就完事的程序不同。我们需要将Hbase中的历史数据读取出来,与新计算的指标进行一个join合并。
其中也需要编写udf对标签进行拼接,并对拼接后的数据进行去重处理。
/* 定义一个udf,用于处理旧数据和新数据中的数据 */
val getAllTages: UserDefinedFunction = udf((genderOldDatas: String, jobNewTags: String) => {
if (genderOldDatas == "") {
jobNewTags
} else if (jobNewTags == "") {
genderOldDatas
} else if (genderOldDatas == "" && jobNewTags == "") {
""
} else {
val alltages: String = genderOldDatas + "," + jobNewTags //可能会出现 83,94,94
// 对重复数据去重
alltages.split(",").distinct // 83 94
// 使用逗号分隔,返回字符串类型
.mkString(",") // 83,84
}
})
// 7、解决数据覆盖的问题
// 读取test,追加标签后覆盖写入
// 标签去重
val genderOldDatas: DataFrame = spark.read.format("com.czxy.tools.HBaseDataSource")
// hbaseMeta.zkHosts 就是 192.168.10.20 和 下面是两种不同的写法
.option("zkHosts","192.168.10.20")
.option(HBaseMeta.ZKPORT, "2181")
.option(HBaseMeta.HBASETABLE, "test")
.option(HBaseMeta.FAMILY, "detail")
.option(HBaseMeta.SELECTFIELDS, "userId,tagsId")
.load()
genderOldDatas.show(5)
//+------+------+
//|userId|tagsId|
//+------+------+
//| 1| 6,68|
//| 10| 6,70|
//| 100| 6,68|
//| 101| 5,66|
//| 102| 6,66|
//+------+------+
// 新表和旧表进行join
val joinTags: DataFrame = genderOldDatas.join(jobNewTags, genderOldDatas("userId") === jobNewTags("userId"))
val allTags: DataFrame = joinTags.select(
// 处理第一个字段
when((genderOldDatas.col("userId").isNotNull), (genderOldDatas.col("userId")))
.when((jobNewTags.col("userId").isNotNull), (jobNewTags.col("userId")))
.as("userId"),
getAllTages(genderOldDatas.col("tagsId"), jobNewTags.col("tagsId")).as("tagsId")
)
allTags.show()
//+------+------+
//|userId|tagsId|
//+------+------+
//| 296| 5,71|
//| 467| 6,71|
//| 675| 6,68|
//| 691| 5,66|
//| 829| 5,70|
<8>将最终结果写入到Hbase(数据覆盖)
经过第七步数据的合并之后,我们只需将最终的结果写入到Hbase中即可。
// 将最终结果进行覆盖
allTags.write.format("com.czxy.tools.HBaseDataSource")
.option("zkHosts", hbaseMeta.zkHosts)
.option(HBaseMeta.ZKPORT, hbaseMeta.zkPort)
.option(HBaseMeta.HBASETABLE,"test")
.option(HBaseMeta.FAMILY, "detail")
.option(HBaseMeta.SELECTFIELDS, "userId,tagsId")
.save()
这个时候我们再去查询Hbase中test表的数据。
scan "test",{LIMIT => 5}

当发现每个用户都有了两个标签值时(ps:一个是上一篇文章开发的性别标签,另一个是我们本篇开发的工作标签),就说明我们标签的累计开发就成功了。
过程小结
1、为读取hbase,mysql数据,创建一个sparksession,设置appname,master
2、链接mysql数据库,设置url,tablename, properties
3、读取四级标签数据
a)通过ID读取四级数据的rule。(ID是固定死的)
b)创建四级标签时不要直接指定jar文件名和参数等。创建完四级标签后,开发代码后,再在四级标签中添加jar文件信息。
c)将读取的字符串类型数据封装成样例类,以便于后续使用
i.将字符串先按照##切分数据,再按照=切分数据
ii.将切分后的数据封装成Map
iii.最后将Map封装成样例类
4、读取五级标签数据
a)读物数据中pid=XXX的数据,查询出ID和rule
b)将id 和rule封装成样例类
c)最终返回List内部为样例类
5、基于第三步读取的hbase表、列族、字段。到相应的表中读取字段
6、根据hbase数据和五级标签的数据进行标签匹配
a)匹配时使用udf函数进行匹配
7、读取hbase中历史数据到程序中
a)将历史数据和新计算出来的指标进行join.
b)获取join后的用户ID和用户标签,编写UDF将标签进行拼接
c)拼接后的数据需要进行去重
8、将最终拼接后的数据写入hbase(数据的覆盖)
小结
本篇博客主要在前一篇的基础上,为大家带来了如何在已有标签的情况下进行累计开发。即将原有数据和新数据进行合并,并重写的技巧。
如果以上过程中出现了任何的纰漏错误,烦请大佬们指正
受益的朋友或对大数据技术感兴趣的伙伴记得点赞关注支持一波
希望我们都能在学习的道路上越走越远
