【目标追踪】python背景模型减除法原理及其实现
python基于背景模型减除法的视频目标追踪
- 帧差法的问题:
- 背景模型减除法目标追踪原理
- 1. 基本思路:
- 2. 图例讲解:
- 3. 存在的问题&如何解决:
- 4. 最终效果预览
- 第一步——调用摄像头:
- 1. 使用opencv打开视频or摄像头:
- 2. 读取逐帧图片:
- 第二步——处理图片:
- 1. 转换成灰度图:
- 3. 累加权重重构背景:
- 3. 计算像素差:
- 3. 使用中值滤波和膨胀腐蚀去噪:
- 3.1 中值滤波:
- 3.2 图像腐蚀和膨胀:
- 4. 视频处理效果:
- 第三步——框出候选区域
- 1. 找出所有目标的轮廓:
- 2. 非极大值抑制NMS:
- 完整代码:
帧差法的问题:
这是相邻帧差法的效果,运动物体有双重轮廓、空洞等现象现象影响观察;
并且不运动或者运动较小的物体,也难以检测到;
背景模型减除法目标追踪原理
1. 基本思路:
不同于帧差法前后两帧图片的像素差来确定运动物体,背景模型差法希望通过建立背景模型,然后再将每帧图片与背景模型作差,即可得到运动物体的轮廓。
2. 图例讲解:
我们使用opencv自带的测试视频来讲解:
我们希望的背景是这样的,及不包含任何目标的空背景图:

对于视频中运动目标,运动的目标区域会有相应变化,这样再与背景图作差,就可以得到运动目标的区域。
这样的话,我们只需要检测到视频中相比于背景图片像素有较大变化的区域,就可以实现一个简单的运动物体检测;
3. 存在的问题&如何解决:
当然这里还有许多问题需要解决
- 视频中并不会出现空背景图,那么将如何去重建?
- 如何将目标区域选定出来?(比如用矩形框圈出来)
- 如何去掉重叠的矩形框或者筛选出合适的矩形框?
- 以及如何用代码实现?
下面会一一讲解:
4. 最终效果预览
第一步——调用摄像头:
1. 使用opencv打开视频or摄像头:
其中video_index是摄像头编号,一般前置摄像头为0,USB摄像头为1或2,使用时会打开摄像头;如果输入的是视频路径,则会读取视频。
# open_camera.py
import cv2
def catch_video(name='my_video', video_index=0):
# cv2.namedWindow(name)
cap = cv2.VideoCapture(video_index) # 创建摄像头识别类
if not cap.isOpened():
# 如果没有检测到摄像头,报错
raise Exception('Check if the camera is on.')
while cap.isOpened():
catch, frame = cap.read() # 读取每一帧图片
# ————————————————————————————————
# 处理图片
# ————————————————————————————————
cv2.imshow(name, frame) # 在window上显示图片
key = cv2.waitKey(10)
if key & 0xFF == ord('q'):
# 按q退出
break
if cv2.getWindowProperty(name, cv2.WND_PROP_AUTOSIZE) < 1:
# 点x退出
break
# 释放摄像头
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
catch_video('./test.avi')
这样的话我们就成功地打开了视频:
2. 读取逐帧图片:
在程序运行期间,opencv会不断读取输入的每一帧图片,再将图片进行一定处理,不断显示在window上:
这里使用了read方法,返回的frame就是某一时刻视频的图片。
第二步——处理图片:
1. 转换成灰度图:
对读取到的每一帧图片,我们首先转换成灰度图:
catch, frame = cap.read() # 读取每一帧图片
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 转换成灰度图
3. 累加权重重构背景:
我们通过权重累加前面的每一帧图片,重构视频背景:
dialta = 0.9
background = background*dialta + gray*(1-dialta)dialta 参数就是前面累加背景的权重。
dialta = 0.9 的背景图:

dialta = 0.95 的背景图:

3. 计算像素差:
然后我们计算视频中这一帧图片与重构背景图像素的绝对值差:
gray_diff = cv2.absdiff(gray, background) # 计算绝对值差
# background 是上一帧图片的灰度图其中黑色区域是由于像素相同得0,灰色区域越接近白色,表示两帧图片该点的像素差越大。
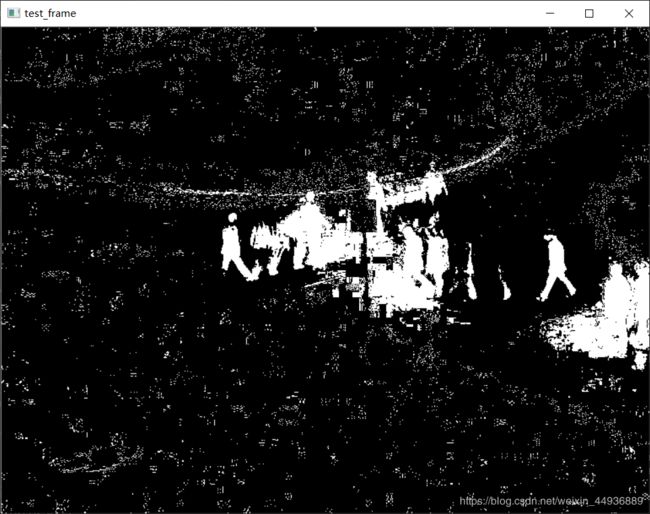
再将帧差图进行二值化,即图片像素差大于某一阙值(我们这里定为40)的标注为运动点,赋值为255(白色),其余点赋值为0(黑色):
_, mask = cv2.threshold(
gray_diff, 40, 255, cv2.THRESH_BINARY)得到的二值化图为:
3. 使用中值滤波和膨胀腐蚀去噪:
这时候我们虽然得到了帧差图的二值化图,但图中有许多干扰是我们不想要的:
在这里插入图片描述
这时候我们就需要通过一定的方法去噪;
3.1 中值滤波:
mask = cv2.medianBlur(mask, 3) # 中值滤波中值滤波是一种图像平滑处理算法,基本原理就是,测试像素周围邻域像素集中的中值代替原像素,能够有效去除孤立的噪声点或较细的噪声线;
使用中值滤波前后对比:

可以看到一部分噪声已经被去除了,图像也变得更加平滑。
3.2 图像腐蚀和膨胀:
腐蚀和膨胀具体原理可以看一下这篇博客:
数字图像处理(六)形态学处理之腐蚀、膨胀、开运算、闭运算
腐蚀和膨胀也是图片平滑处理的一种算法,一般先腐蚀再膨胀能够有效去除干扰线:
es = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (9, 4))
m = cv2.erode(median, es, iterations=2) # 膨胀
m = cv2.dilate(m, es, iterations=2) # 腐蚀处理前后对比:

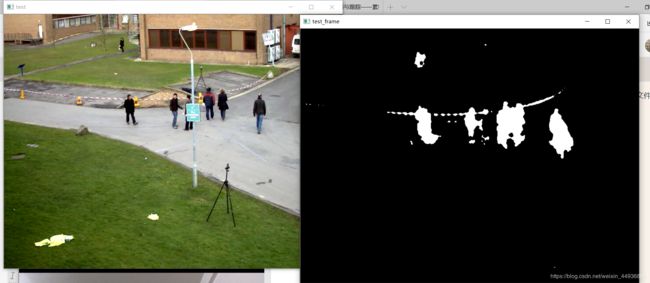
4. 视频处理效果:
完整代码:
import cv2
import numpy as np
import matplotlib.pyplot as plt
class Detector(object):
def __init__(self, name='my_video'):
self.name = name
self.threshold = 40
self.es = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (9, 4))
def catch_video(self, video_index=0):
# cv2.namedWindow(name)
cap = cv2.VideoCapture(video_index) # 创建摄像头识别类
if not cap.isOpened():
# 如果没有检测到摄像头,报错
raise Exception('Check if the camera is on.')
frame_num = 0
while cap.isOpened():
catch, frame = cap.read() # 读取每一帧图片
if not catch:
raise Exception('Error.')
if not frame_num:
# 这里是由于第一帧图片没有前一帧
previous = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 转换成灰度图
gray = cv2.absdiff(gray, previous) # 计算绝对值差
gray = cv2.medianBlur(gray, 3) # 中值滤波
ret, mask = cv2.threshold(
gray, self.threshold, 255, cv2.THRESH_BINARY)
mask = cv2.erode(mask, self.es, iterations=1)
mask = cv2.dilate(mask, self.es, iterations=1)
cv2.imshow(self.name, frame) # 在window上显示图片
cv2.imshow(self.name+'_frame', mask) # 边界
previous = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
frame_num += 1
key = cv2.waitKey(10)
if key & 0xFF == ord('q'):
# 按q退出
break
if cv2.getWindowProperty(self.name, cv2.WND_PROP_AUTOSIZE) < 1:
# 点x退出
break
if cv2.getWindowProperty(self.name+'_frame', cv2.WND_PROP_AUTOSIZE) < 1:
# 点x退出
break
# 释放摄像头
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
detector = Detector()
detector.catch_video()
效果如图:
第三步——框出候选区域
1. 找出所有目标的轮廓:
这里使用cv2.findContours()函数来查找检测运动目标的轮廓,并标注在原图上:
_, cnts, _ = cv2.findContours(
mask.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_TC89_L1)
for c in cnts:
if cv2.contourArea(c) < min_area:
continue
x, y, w, h = cv2.boundingRect(c)
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)cv2.findContours()参数:
- 第一个参数是寻找轮廓的图像;
- 第二个参数表示轮廓的检索模式,cv2.RETR_LIST表示检测的轮廓不建立等级关系;
- 第三个参数method为轮廓的近似办法,cv2.CHAIN_APPROX_TC89_L1使用teh-Chinl chain 近似算法;
第一步筛选我们去掉面积过小的轮廓框,效果如图:
2. 非极大值抑制NMS:
当然这里会有重叠框,我们使用非极大值抑制进行筛选;
非极大值抑制的作用是去除相同目标的重叠的多余的轮廓框,只保留得分最大的那个,例如:

在这里,我们将得分定义为运动点占轮廓框总像素点的比例;
完整代码:
# nms.py
import numpy as np
def py_cpu_nms(dets, thresh):
y1 = dets[:, 1]
x1 = dets[:, 0]
y2 = y1 + dets[:, 3]
x2 = x1 + dets[:, 2]
scores = dets[:, 4] # bbox打分
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
# 打分从大到小排列,取index
order = scores.argsort()[::-1]
# keep为最后保留的边框
keep = []
while order.size > 0:
# order[0]是当前分数最大的窗口,肯定保留
i = order[0]
keep.append(i)
# 计算窗口i与其他所有窗口的交叠部分的面积
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
# 交/并得到iou值
ovr = inter / (areas[i] + areas[order[1:]] - inter)
# inds为所有与窗口i的iou值小于threshold值的窗口的index,其他窗口此次都被窗口i吸收
inds = np.where(ovr <= thresh)[0]
# order里面只保留与窗口i交叠面积小于threshold的那些窗口,由于ovr长度比order长度少1(不包含i),所以inds+1对应到保留的窗口
order = order[inds + 1]
return keep# frame.py
import cv2
import numpy as np
from nms import py_cpu_nms
from time import sleep
class Detector(object):
def __init__(self, name='my_video', frame_num=10, k_size=7, color=(0, 255, 0)):
self.name = name
self.color = color
self.nms_threshold = 0.3
self.time = 1/frame_num # 频率
self.es = cv2.getStructuringElement(
cv2.MORPH_ELLIPSE, (k_size, k_size))
def catch_video(self, video_index=0, method='T', k_size=7, dialta=0.95,
iterations=3, threshold=20, bias_num=1,logical='or',
min_area=360, show_test=True, nms=True):
# video_index:摄像头索引(数字)或者视频路径(字符路径)
# k_size:中值滤波的滤波器大小
# dialta:背景权重
# iteration:腐蚀+膨胀的次数,0表示不进行腐蚀和膨胀操作
# threshold:二值化阙值
# bias_num:计算帧差图时的帧数差
# min_area:目标的最小面积
# show_test:是否显示二值化图片
# nms:是否进行非极大值抑制
method = method.lower()
if not bias_num > 0:
raise Exception('bias_num must > 0')
if isinstance(video_index, str):
self.is_camera = False
# 如果是视频,则需要调整帧率
else:
self.is_camera = True
cap = cv2.VideoCapture(video_index) # 创建摄像头识别类
if not cap.isOpened():
# 如果没有检测到摄像头,报错
raise Exception('Check if the camera is on.')
self.frame_num = 0
if method != 'B':
self.background = []
while cap.isOpened():
if method == 't':
mask, frame = self.temporal_difference(
cap, k_size, dialta, iterations, threshold,
bias_num, min_area, show_test, nms)
elif method == 'b':
mask, frame = self.weights_bk(
cap, k_size, dialta, iterations, threshold,
bias_num, min_area, show_test, nms)
elif method == 'tr':
mask, frame = self.tri_temporal_difference(
cap, k_size, dialta, iterations, threshold,
bias_num, min_area, show_test, nms, logical)
else:
raise Exception('method must be \'T\' or \'Tr\' or \'B\'')
_, cnts, _ = cv2.findContours(
mask.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
bounds = self.nms_cnts(cnts, mask, min_area, nms=nms)
for b in bounds:
x, y, w, h = b
thickness = (w*h)//min_area
thickness = thickness if thickness <= 3 else 3
thickness = thickness if thickness >= 1 else 1
cv2.rectangle(frame, (x, y), (x+w, y+h), self.color, thickness)
if not self.is_camera:
sleep(self.time)
# cv2.imshow(self.name+'_bk', self.background) # 在window上显示背景
cv2.imshow(self.name, frame) # 在window上显示图片
if show_test:
cv2.imshow(self.name+'_frame', mask) # 边界
cv2.waitKey(10)
if cv2.getWindowProperty(self.name, cv2.WND_PROP_AUTOSIZE) < 1:
# 点x退出
break
if show_test and cv2.getWindowProperty(self.name+'_frame', cv2.WND_PROP_AUTOSIZE) < 1:
# 点x退出
break
# 释放摄像头
cap.release()
cv2.destroyAllWindows()
def weights_bk(self, cap, k_size=7, dialta=0.95,
iterations=3, threshold=20, bias_num=1,
min_area=360, show_test=True, nms=True):
catch, frame = cap.read() # 读取每一帧图片
if not catch:
if self.is_camera:
raise Exception('Unexpected Error.')
if self.frame_num < bias_num:
value = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
self.background = value
self.frame_num += 1
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
raw = gray.copy()
gray = np.abs(gray-self.background).astype('uint8')
self.background = self.background*dialta + raw*(1-dialta)
self.background = self.background.astype('uint8')
gray = cv2.medianBlur(gray, k_size)
_, mask = cv2.threshold(
gray, threshold, 255, cv2.THRESH_BINARY)
# mask = cv2.medianBlur(mask, k_size)
mask = cv2.dilate(mask, self.es, iterations)
mask = cv2.erode(mask, self.es, iterations)
return mask, frame
def temporal_difference(self, cap, k_size=7, dialta=0.95,
iterations=3, threshold=20, bias_num=1,
min_area=360, show_test=True, nms=True):
catch, frame = cap.read() # 读取每一帧图片
if not catch:
if self.is_camera:
raise Exception('Unexpected Error.')
if self.frame_num < bias_num:
value = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
self.background.append(value)
self.frame_num += 1
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
raw = gray.copy()
gray = cv2.absdiff(gray, self.background[0])
gray = cv2.medianBlur(gray, k_size)
_, mask = cv2.threshold(
gray, threshold, 255, cv2.THRESH_BINARY)
# mask = cv2.medianBlur(mask, k_size)
mask = cv2.dilate(mask, self.es, iterations)
mask = cv2.erode(mask, self.es, iterations)
self.background = self.pop(self.background, raw)
return mask, frame
def tri_temporal_difference(self, cap, k_size=7, dialta=0.95,
iterations=3, threshold=20, bias_num=1,
min_area=360, show_test=True, nms=True,
logical='or'):
catch, frame = cap.read() # 读取每一帧图片
if not catch:
if self.is_camera:
raise Exception('Unexpected Error.')
if self.frame_num < bias_num:
value = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
self.background = [value]*bias_num
self.frame_num = bias_num
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
gray1 = cv2.absdiff(gray, self.background[0])
gray1 = cv2.medianBlur(gray1, k_size)
_, mask1 = cv2.threshold(
gray1, threshold, 255, cv2.THRESH_BINARY)
gray2 = cv2.absdiff(gray, self.background[1])
gray2 = cv2.medianBlur(gray2, k_size)
_, mask2 = cv2.threshold(
gray2, threshold, 255, cv2.THRESH_BINARY)
if logical == 'or':
mask = (np.logical_or(mask1, mask2) + 0)
elif logical == 'and':
mask = (np.logical_and(mask1, mask2) + 0)
else:
raise Exception('Logical must be \'OR\' or \'AND\'')
mask = (mask * 255).astype(np.uint8)
mask = cv2.dilate(mask, self.es, iterations)
mask = cv2.erode(mask, self.es, iterations)
self.background = self.pop(self.background, gray)
return mask, frame
def nms_cnts(self, cnts, mask, min_area, nms=True):
# 对检测到的边界框使用非极大值抑制
bounds = [cv2.boundingRect(
c) for c in cnts if cv2.contourArea(c) > min_area]
if len(bounds) == 0:
return []
if not nms:
return bounds
scores = [self.calculate(b, mask) for b in bounds]
bounds = np.array(bounds)
scores = np.expand_dims(np.array(scores), axis=-1)
keep = py_cpu_nms(np.hstack([bounds, scores]), self.nms_threshold)
return bounds[keep]
def calculate(self, bound, mask):
x, y, w, h = bound
area = mask[y:y+h, x:x+w]
pos = area > 0
pos = pos.astype(np.float)
# 得分应与检测框大小也有关系
score = np.sum(pos)/(w*h)
return score
def pop(self, l, value):
l.pop(0)
l.append(value)
return l
if __name__ == "__main__":
detector = Detector(name='test')
detector.catch_video('./test.avi', method='b', bias_num=2, iterations=2,
k_size=5, show_test=True, min_area=360,
nms=False, threshold=30, dialta=0.9)
其中method参数可选 t,tr 或者 b,分别代表相邻帧差法、三帧差法和我们这里讲的背景模型差法。
完整代码和测试视频放在了我的Github上,记得点一个⭐哦:
Sharpiless/Temporal-Difference