Python编程期末总结
该博客目的为期末复习和知识分享
因笔者能力有限,部分知识点总结不全,还请大家多多包涵,也欢迎大家提供宝贵意见。
Python基本数据类型
1. 数字类型
2. 字符串类型
3. 布尔类型
4. 数据类型转换
数字类型
1. 整数
int() 函数用于将一个字符串或数字转换为整型。
2. 浮点数
float() 函数用于将整数和字符串转换成浮点数。
3.复数
复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型
字符串类型
Python中的字符串用单引号 ’ 或双引号 " 括起来,同时使用反斜杠 \ 转义特殊字符。

布尔类型
True 和 False ,它们的值为 1 和 0,它们可以和数字相加。
数据类型转化
有时候,我们需要对数据内置的类型进行转换,数据类型的转换,你只需要将数据类型作为函数名即可。
以下几个内置的函数可以执行数据类型之间的转换。这些函数返回一个新的对象,表示转换的值。
| 函数 | 描述 |
|---|---|
| int(x [,base]) | 将x转换为一个整数 |
| float(x) | 将x转换到一个浮点数 |
| complex(real [,imag]) | 创建一个复数 |
| str(x) | 将对象 x 转换为字符串 |
| repr(x) | 将对象 x 转换为表达式字符串 |
| eval(str) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s) | 将序列 s 转换为一个元组 |
| list(s) | 将序列 s 转换为一个列表 |
| set(s) | 转换为可变集合 |
| dict(d) | 创建一个字典。d 必须是一个 (key, value)元组序列。 |
| frozenset(s) | 转换为不可变集合 |
| chr(x) | 将一个整数转换为一个字符 |
| ord(x) | 将一个字符转换为它的整数值 |
| hex(x) | 将一个整数转换为一个十六进制字符串 |
| oct(x) | 将一个整数转换为一个八进制字符串 |
Python 条件语句
Python条件语句是通过一条或多条语句的执行结果(True或者False)来决定执行的代码块。
基本形式:
if 判断条件:
执行语句……
else:
执行语句……
当"判断条件"成立时(非零),执行后面的语句,执行内容可以多行,以缩进来区分表示同一范围。
else 为可选语句,当需要在条件不成立时执行内容则可以执行相关语句。
当判断条件为多个值时,可以使用以下形式:
if 判断条件1:
执行语句1……
elif 判断条件2:
执行语句2……
elif 判断条件3:
执行语句3……
else:
执行语句4……
示例:
num = 5
if num == 3: # 判断num的值
print 'boss'
elif num == 2:
print 'user'
elif num == 1:
print 'worker'
elif num < 0: # 值小于零时输出
print 'error'
else:
print 'roadman' # 条件均不成立时输出
输出结果:
roadman # 输出结果
条件判断及组合
常用的操作运算符:
| 操作符 | 描述 |
|---|---|
| < | 小于 |
| <= | 小于或等于 |
| > | 大于 |
| >= | 大于或等于 |
| == | 等于,比较两个值是否相等 |
| != | 不等于 |
用于条件组合的三个保留字:
Python循环语句
Python 提供了 for 循环和 while 循环
| 循环类型 | 描述 |
|---|---|
| while 循环 | 在给定的判断条件为 true 时执行循环体,否则退出循环体。 |
| for 循环 | 重复执行语句 |
| 嵌套循环 | 你可以在while循环体中嵌套for循环 |
示例:
while 判断条件(condition):
执行语句(statements)……
for iterating_var in sequence:
statements(s)
Python循环控制语句
循环控制语句可以更改语句执行的顺序。
Python支持以下循环控制语句:
break 语句可以跳出 for 和 while 的循环体。如果你从 for 或 while 循环中终止,任何对应的循环 else 块将不执行。
continue 语句被用来告诉 Python 跳过当前循环块中的剩余语句,然后继续进行下一轮循环。
pass是空语句,是为了保持程序结构的完整性。一般用做占位语句。
示例:
n = 5
while n > 0:
n -= 1
if n == 2:
break
print(n)
print('循环结束。')
n = 5
while n > 0:
n -= 1
if n == 2:
continue
print(n)
print('循环结束。')
for letter in 'Python':
if letter == 'o':
pass
print ('执行 pass 块')
print ('当前字母 :', letter)
print ("Good bye!")
输出结果:
4
3
循环结束。
4
3
1
0
循环结束。
当前字母 : P
当前字母 : y
当前字母 : t
当前字母 : h
执行 pass 块
当前字母 : o
当前字母 : n
Good bye!
Python组合数据类型
序列
序列是Python中最基本的数据结构。序列中的每个元素都分配一个数字对应它的位置或索引,第一个索引是0,第二个索引是1,依此类推。
序列通用操作符
| 操作符及应用 | 描述 |
|---|---|
| x in s | 如果x是序列s的元素,返回True,否则返回False |
| x not in s | 如果x是序列s的元素,返回False,否则返回True |
| s + t | 连接两个序列s和t |
| s*n 或 n*s | 将序列s复制n次 |
| s[i] | 索引,返回s中的第i元素 |
| s[i: j] 或 s[i: j: k] | 切片,返回序列s中第i到j-1以k为步长的元素子序列 |
列表
列表是一种序列类型,创建后可以随意被修改。使用方括号 [] 或 list() 创建,元素间用逗号 , 分隔。列表中各元素类型可以不同,无长度限制。
列表类型操作函数和方法
| 函数或方法 | 描述 |
|---|---|
| L[2] | 读取第三个元素 |
| L[-2] | 从右侧开始读取第二个元素 |
| L[1:] | 输出从第二个元素开始后的所有元素 |
| len(list) | 返回列表元素个数 |
| max(list) | 返回列表元素最大值 |
| min(list) | 返回列表元素最小值 |
| list(seq) | 将元组转换为列表 |
| del list[i] | 删除列表list中第i元素 |
| list.append(obj) | 在列表末尾添加新的对象 |
| list.count(obj) | 统计某个元素在列表中出现的次数 |
| list.clear() | 清空列表 |
| list.copy() | 复制列表 |
| list.extend(seq) | 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| list.index(obj) | 从列表中找出某个值第一个匹配项的索引位置 |
| list.insert(index, obj) | 将对象插入列表 |
| list.pop([index=-1]) | 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| list.remove(obj) | 移除列表中某个值的第一个匹配项 |
| list.reverse() | 反向列表中元素 |
| list.sort( key=None, reverse=False) | 对原列表进行排序 |
示例:
>>> ls = ["cat", "dog", "tiger", 1024]
>>> ls[1:2] = [1, 2, 3, 4]
['cat', 1, 2, 3, 4, 'tiger', 1024]
>>> del ls[::3]
[1, 2, 4, 'tiger']
>>> ls*2
[1, 2, 4, 'tiger', 1, 2, 4, 'tiger']
>>> ls = ["cat", "dog", "tiger", 1024]
>>> ls.append(1234)
['cat', 'dog', 'tiger', 1024, 1234]
>>> ls.insert(3, "human")
['cat', 'dog', 'tiger', 'human', 1024, 1234]
>>> ls.reverse()
[1234, 1024, 'human', 'tiger', 'dog', 'cat']
元组
Python 的元组与列表类似,不同之处在于元组的元素不能修改。
使用小括号 () 或 tuple() 创建。
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
| 函数或方法 | 描述 |
|---|---|
| len(tuple) | 计算元组元素个数。 |
| max(tuple) | 返回元组中元素最大值。 |
| min(tuple) | 返回元组中元素最小值。 |
| tuple(seq) | 将列表转换为元组。 |
字典
字典的每个键值(key=>value)对用冒号 : 分割,每个对之间用逗号 , 分割,整个字典包括在花括号 {} 中 ,格式如下所示:
{<键1>:<值1>, <键2>:<值2>, … , <键n>:<值n>}
键必须是唯一的,但值则不必。
值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组。
一个简单的字典实例:
>>> dict = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'}
>>> dict["Alice"]
'2341'
>>> dict['Tom']='4554'
>>> dict
{'Alice': '2341', 'Beth': '9102', 'Cecil': '3258', 'Tom': '4554'}
字典内置函数及方法
| 函数或方法 | 描述 |
|---|---|
| len(dict) | 计算字典元素个数,即键的总数。 |
| str(dict) | 输出字典,以可打印的字符串表示。 |
| type(variable) | 返回输入的变量类型,如果变量是字典就返回字典类型。 |
| radiansdict.clear() | 删除字典内所有元素 |
| radiansdict.copy() | 返回一个字典的浅复制 |
| radiansdict.fromkeys() | 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 |
| radiansdict.get(key, default=None) | 返回指定键的值,如果值不在字典中返回default值 |
| key in dict | 如果键在字典dict里返回true,否则返回false |
| radiansdict.items() | 以列表返回可遍历的(键, 值) 元组数组 |
| radiansdict.keys() | 返回一个迭代器,可以使用 list() 来转换为列表 |
| radiansdict.setdefault(key, default=None) | 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| radiansdict.update(dict2) | 把字典dict2的键/值对更新到dict里 |
| radiansdict.values() | 返回一个迭代器,可以使用 list() 来转换为列表 |
| pop(key[,default]) | 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 |
| popitem() | 随机返回并删除字典中的最后一对键和值。 |
示例:
>>> d = { "中国":"北京" , "美国":"华盛顿" , "法国":"巴黎" }
>>> "中国" in d
True
>>> d.keys()
dict_keys(['中国', '美国', '法国'])
>>> d.values()
dict_values(['北京', '华盛顿', '巴黎'])
>>> d = { "中国":"北京" , "美国":"华盛顿" , "法国":"巴黎" }
>>> d.get( "中国","伊斯兰堡" )
'北京'
>>> d.get( "巴基斯坦","伊斯兰堡" )
'伊斯兰堡'
>>> d.popitem()
('美国', '华盛顿')
集合
集合 set 是一个无序的不重复元素序列。可以使用大括号 { } 或者 set() 函数创建集合。(注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。)
集合内置函数及方法
| 函数或方法 | 描述 |
|---|---|
| add() | 为集合添加元素 |
| clear() | 移除集合中的所有元素 |
| copy() | 拷贝一个集合 |
| pop() | 随机移除元素 |
| remove() | 移除指定元素 |
| discard() | 删除集合中指定的元素 |
| set(x) | 将其他将其他类型变量x转变为集合类型 |

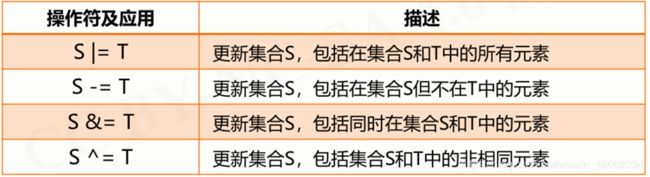
示例:
>>> A = {"p", "y" , 123}
>>> B = set("pypy123")
>>> A-B
{123}
>>> B-A
{'3', '1', '2'}
>>> A&B
{'p', 'y'}
>>> A|B
{'1', 'p', '2', 'y', '3', 123}
>>> A^B
{'2', 123, '3', '1'}
集合的应用场景:
>>> ls = ["p", "p", "y", "y", 123]
>>> s = set(ls) # 利用了集合无重复元素的特点
{'p', 'y', 123}
>>> lt = list(s) # 还可以将集合转换为列表
['p', 'y', 123]
字符串类型
字符串是 Python 中最常用的数据类型。我们可以使用引号 ’ 或 " 来创建字符串。
Python转义字符
在需要在字符中使用特殊字符时,python用反斜杠 \ 转义字符。如下表:
| 转义字符 | 描述 |
|---|---|
| (在行尾时) | 续行符 |
| \ | 反斜杠符号 |
| ’ | 单引号 |
| " | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数,yy 代表的字符,例如:\o12 代表换行,其中 o 是字母,不是数字 0。 |
| \xyy | 十六进制数,yy代表的字符,例如:\x0a代表换行 |
| \other | 其它的字符以普通格式输出 |
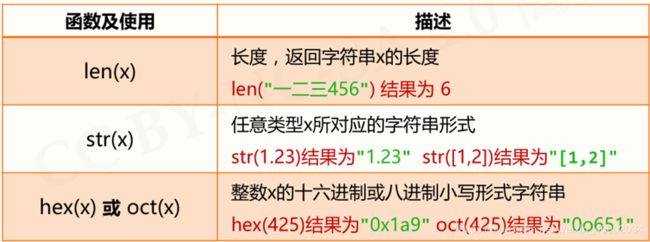
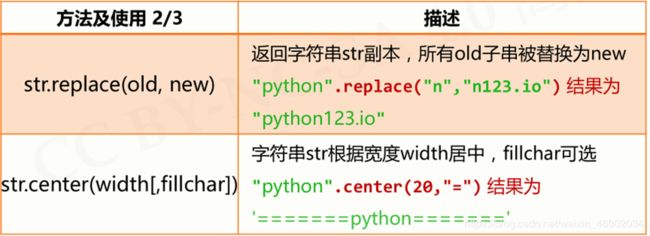
字符串处理函数


字符串格式化
| 符号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %f 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
| * | 定义宽度或者小数点精度 |
| * | 用做左对齐 |
| * | 在正数前面显示加号( + ) |
| 在正数前面显示空格 | |
| # | 在八进制数前面显示零(‘0’),在十六进制前面显示’0x’或者’0X’(取决于用的是’x’还是’X’) |
| 0 | 显示的数字前面填充’0’而不是默认的空格 |
| % | ‘%%‘输出一个单一的’%’ |
| (var) | 映射变量(字典参数) |
| m.n. | m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
Python函数
函数的定义
Python定义一个函数使用def保留字,语法形式如下: (return可有可无)
def <函数名>(<参数列表>):
<函数体>
return <返回值列表>
形参与实参
在def语句中,位于函数名后面的变量通常称为形参。
调用函数时提供的值称为实参
函数的调用
程序调用一个函数需要执行以下四个步骤:
- 调用程序在调用处暂停执行;
- 在调用时将实参复制给函数的形参;
- 执行函数体语句;
- 函数调用结束给出返回值,程序回到调用前的暂停处继续执行。
示例:
# 计算面积函数
def area(width, height):
return width * height
w = 4
h = 5
print("width =", w, " height =", h, " area =", area(w, h))
可以通过global保留字在函数内部声明全局变量:


Python模块
模块是一个包含所有你定义的函数和变量的文件,其后缀名是.py。模块可以被别的程序引入,以使用该模块中的函数等功能。
模块分为三种:
- 内置模块:如sys, os, subprocess, time, json 等等
- 自定义模块:自定义模块时要注意命名,不能和Python自带模块名称冲突。
- 开源模块:公开的第三方模块, 如 https://pypi.org,可以使用pip install 安装,类似于yum 安装软件
>>> help('modules') #查看python所有的modules
模块的使用
import 语句, 用于导入整个模块
import module
import module as name
from modname import name
文件和目录操作
使用文件之前,须首先打开文件,然后进行读、写、添加等操作。
Python打开文件使用 open 函数,其语法格式为:
f = open(file, mode='r')
- 上述语句直接打开一个指定的文件,如果文件不存在则创建该文件。
- 这里的 f 是一个文件对象,它与指定的文件建立了关联,很多文献称f为文件描述符。
- 实际上它可视为指定文件的“句柄”,所有对指定文件的后续操作都将通过这个句柄进行,直到使用后面将要介绍的 close() 函数关闭指定文件为止。
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,如果该文件不存在,创建新文件。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
在文本文件中读取数据的语法格式为:
f.read([size]) #size为读取的长度,以byte为单位
f.readline([size]) #读一行,如果定义了size,有可能返回的只是一行的一部分
f.readlines([size]) #把文件每一行作为list的一个成员,并返回这个list。
在当前目录下创建一个文本文件text.txt,可使用语句:
f = open(r'C:\Users\text.txt','a')
向文件中写入数据的函数是write()和writelines(),其语法格式为:
f.write(str) #把str写到文件中,write()并不会在str后加上一个换行符
f.writelines(seq) #把seq的内容全部写到文件中(多行一次性写入)。这个函数也只是忠实地写入,不会在每行后面加上任何东西。
seek()方法
seek() 方法用于移动文件读取指针到指定位置:
seek(offset[, whence]) #移动文件指针
- offset : 开始的偏移量,也就是代表需要移动偏移的字节数,如果是负数表示从倒数第几位开始。
- whence:可选,默认值为 0。给 offset 定义一个参数,表示要从哪个位置开始偏移;0 代表从文件开头开始算起,1 代表从当前位置开始算起,2 代表从文件末尾算起。
例:
>>> f = open('test.txt', 'w+')
>>> f.write('0123456789abcdef')
16
>>> f.seek(5)
5
>>> f.read(1)
'5'
Python异常处理
常见异常
语法错误
Python 的语法错误或称为解析错
>>> if
SyntaxError: invalid syntax
本例中,因 if 后缺少冒号 : 被检测出错误
异常
即便 Python 程序的语法是正确的,在运行它的时候,也有可能发生错误。运行期检测到的错误被称为异常。
大多数的异常都不会被程序处理,都以错误信息的形式展现
常见的异常类型:
1.AttributeError:访问对象属性时引发的异常,如属性不存在或不支持赋值等。
2.ImportError:导入模块出错引发的异常( 无法引入模块或包;基本上是路径问题或名称错误)。
3.IndexError :下标索引超出序列边界,比如当x只有三个元素,却试图访问x[5]
4.IndentationError:没使用正确缩进时引发的异常( 语法错误(的子类) ;代码没有正确对齐)。
5.TypeError :在运算或函数调用中,使用了不兼容的类型时引发的异常(传入对象类型与要求的不符合)。
6.KeyError :试图访问字典里不存在的键
7.KeyboardInterrupt: Ctrl+C被按下
8.NameError :尝试访问一个没有申明的变量
9.SyntaxError: Python代码非法,代码不能编译(个人认为这是语法错误,写错了)
10.UnboundLocalError :试图访问一个还未被设置的局部变量,基本上是由于另有一个同名的全局变量,导致你以为正在访问它
11.ValueError :传入一个调用者不期望的值,即使值的类型是正确的
异常处理
异常捕捉可以使用 try- except语句。
;
例:
while True:
try:
x = int(input("请输入一个数字: "))
break
except ValueError:
print("您输入的不是数字,请再次尝试输入!")
一个 try 语句可能包含多个except子句,分别来处理不同的特定的异常。最多只有一个分支会被执行。
一个except子句可以同时处理多个异常,这些异常将被放在一个括号里成为一个元组,例如:
except (RuntimeError, TypeError, NameError):
try …except…else 语句,当没有异常发生时,else中的语句将会被执行

try … finally
无论异常是否发生,在程序结束前,finally中的语句都会被执行


抛出异常
Python 使用 raise 语句抛出一个指定的异常。
raise语法格式如下:
raise [Exception [, args [, traceback]]]
示例:
x = 10
if x > 5:
raise Exception('x 不能大于 5。x 的值为: {}'.format(x))
返回:
Exception: x 不能大于 5。x 的值为: 10