大数据实习笔记
#2018-07-19#
1.同步集群时间
2.数据导入flume
使用 flume 收集 nginx 服务器的日志到 hdfs
(1)配置代理
[root@master1 ~]# vim /etc/flume/conf/flume.conf
添加:
# #配置Agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# # 配置Source
a1.sources.r1.type = exec
a1.sources.r1.channels = c1
a1.sources.r1.deserializer.outputCharset = UTF-8
# # 配置需要监控的日志输出目录
a1.sources.r1.command = tail -F /var/log/nginx/access.log
# # 配置Sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.path = hdfs://master1:8020/user/hdfs/flume/collector1
a1.sinks.k1.hdfs.filePrefix = %Y-%m-%d-%H
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.minBlockReplicas = 1
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 86400
a1.sinks.k1.hdfs.rollSize = 1000000
a1.sinks.k1.hdfs.rollCount = 10000
a1.sinks.k1.hdfs.idleTimeout = 0
# # 配置Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# # 将三者连接
a1.sources.r1.channel = c1
a1.sinks.k1.channel = c1
(2)准备实验环境
--1---挂载光盘,并且安装 nginx 服务
[root@master1 mnt]# mkdir cdrom
[root@master1 mnt]# ls
cdrom
[root@master1 ~]# mount /dev/sr0 /mnt/cdrom
mount: /dev/sr0 写保护,将以只读方式挂载
[root@master1 ~]# yum install nginx
已加载插件:fastestmirror
There are no enabled repos.
Run "yum repolist all" to see the repos you have.
To enable Red Hat Subscription Management repositories:
subscription-manager repos --enable
To enable custom repositories:
yum-config-manager --enable
---2----安装repos,输入命令“cd /etc/yum.repos.d/”如图命令操作
[root@master1 ~]# cd /etc/yum.repos.d/
[root@master1 yum.repos.d]# ls
hanwate_cdrom.repo online_repos
[root@master1 yum.repos.d]# vim hanwate_cdrom.repo
[hanwate_install]
name=hanwate install cdrom
baseurl=file:///mnt/cdrom/
path=/
enabled=1
gpgcheck=1
gpgkey=file:///mnt/cdrom/RPM-GPG-KEY-HanWate
----3----测试ok
[root@master1 ~]# yum install nginx
已加载插件:fastestmirror
hanwate_install | 3.7 kB 00:00:00
(1/2): hanwate_install/group_gz | 2.1 kB 00:00:01
(2/2): hanwate_install/primary_db | 917 kB 00:00:01
-----4------
准备 web 服务器日志,开启 nginx 服务
[root@master1 ~]# systemctl start nginx
----5-----
开启服务后可以通过查看 /var/log/flume/flume.log 来
看到运行日志。
先开启权限chmod 777
---6---
创建日志导入 hdfs 的目录
[root@master1 ~]# su - hdfs
上一次登录:三 7月 18 08:21:40 CST 2018pts/1 上
-bash-4.2$ hadoop fs -mkdir /user/hdfs/
-bash-4.2$ hadoop fs -mkdir /user/hdfs/flume/
-bash-4.2$ hadoop fs -mkdir /user/hdfs/flume/collector1
-bash-4.2$ hadoop fs -chmod 777 /user/hdfs/flume
----7-----在地址栏输入开了 nginx 服务的机器IP即可
打开NGINX web界面
(3)启动代理:
[root@master1 ~]# flume-ng agent --conf /etc/flume/conf/ --conf-file /etc/flume/conf/flume.conf --name a1 -Dflume.root.logger=INFO,console
(4)查看
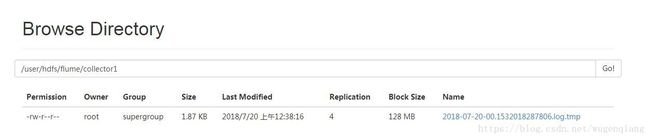
#2018-07-18#
取消权限验证
若出现权限问题则可采取下面策略解决:
取消权限验证:
可以考虑把 hdfs 的权限验证给去掉。在 hdfs-site.xml 中添加一个配置项:
#2018-07-17#
一、hadoop集群
1.节点
master:
master1: ip:192.168.75.137
master2: ip:192.168.75.138
slave:
slave1: ip:192.168.75.139
slave2: ip:192.168.75.140
操作:
(1)查看ip
ifconfig
(2)更改hostname主机名
hostnamectl set-hostname 主机名
(3)添加域名映射
vim /etc/hosts
(4)查看是否存在.sh
[root@master1 ~]# ls -a
如果有则输入:rm -rf /root/.ssh卸载
(5)生成ssh
ssh-keygen -t rsa
(6)给钥匙
master上执行
scp id_rsa.pub root@master1:/root/
scp id_rsa.pub root@slave1:/root/
等等等
(7)加保险
master和slave上都需要
cat id_rsa.pub>>.ssh/authorized_keys
(8)测试
[root@master1 ~]# ssh slave1
Last login: Tue Jul 17 09:52:38 2018 from 192.168.75.1
[root@slave1 ~]#
2.配置java环境变量
(1)vim /etc/profile
末尾添加:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.151-1.b12.el7_4.x86_64/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin
(2)执行source /etc/profile生效
(3)查看
$PATH
3.集群搭建
(1)配置文件路径:
配置集群的配置文件目录:cd $HADOOP_HOME/etc/hadoop/conf
(2)增加slave节点
[root@master1 conf]# vim /etc/hadoop/conf/slaves
添加
master1
master2
slave1
slave2
(3)配置集群core-site.xml
[root@master2 ~]# vim /etc/hadoop/conf/core-site.xml
添加:
(4)配置集群hdfs-site.xml
[root@master1 conf]# vim hdfs-site.xml
添加:
(5)创建hdfs需要用的文件目录
[root@master1 ~]# mkdir /usr/hdp/tmp -p
[root@master1 ~]# mkdir /hadoop/hdfs/{data,name} -p
[root@master1 ~]# chown -R hdfs:hadoop /hadoop
[root@master1 ~]# chown -R hdfs:hadoop /usr/hdp/tmp
(6)初始化hdfs文件系统
在master1上操作:
[root@master1 ~]# sudo -E -u hdfs hdfs namenode -format
(7)启动hdfs文件系统
启动master1节点上的服务:
[root@master1 ~]# systemctl start hadoop-hdfs-namenode
[root@master1 ~]# systemctl start hadoop-hdfs-datanode
启动master2节点上的服务:
[root@master2 ~]# systemctl start hadoop-hdfs-datanode
[root@master2 ~]# systemctl start hadoop-hdfs-secondarynamenode
启动slave1、slave2节点上的服务:
[root@slave1 ~]# systemctl start hadoop-hdfs-datanode
[root@slave2 ~]# systemctl start hadoop-hdfs-datanode
(8)使用jps命令查看
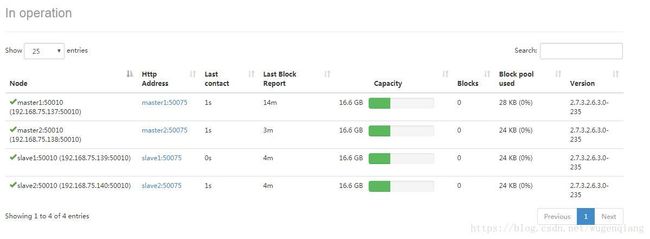
4.网址查看
192.168.75.137:50070
二、大数据开发环境
1.准备程序运行目录
[root@master1 ~]# su - hdfs
-bash-4.2$ hadoop fs -mkdir /tmp
-bash-4.2$ hadoop fs -chmod -R 1777 /tmp
-bash-4.2$ hadoop fs -mkdir -p /var/log/hadoop-yarn
-bash-4.2$ hadoop fs -chown yarn:mapred /var/log/hadoop-yarn
-bash-4.2$ hadoop fs -mkdir /user
-bash-4.2$ hadoop fs -mkdir /user/hadoop
-bash-4.2$ hadoop fs -mkdir /user/history
-bash-4.2$ hadoop fs -chmod 1777 /user/history
-bash-4.2$ hadoop fs -chown mapred:hadoop /user/history
2.配置yarn-site.xml
[root@master1 conf]# vim yarn-site.xml
添加:
/usr/hdp/2.6.3.0-235/hadoop/*,
/usr/hdp/2.6.3.0-235/hadoop/lib/*,
/usr/hdp/2.6.3.0-235/hadoop-hdfs/*,
/usr/hdp/2.6.3.0-235/hadoop-hdfs/lib/*,
/usr/hdp/2.6.3.0-235/hadoop-yarn/*,
/usr/hdp/2.6.3.0-235/hadoop-yarn/lib/*,
/usr/hdp/2.6.3.0-235/hadoop-mapreduce/*,
/usr/hdp/2.6.3.0-235/hadoop-mapreduce/lib/*,
/usr/hdp/2.6.3.0-235/hadoop-httpfs/*,
/usr/hdp/2.6.3.0-235/hadoop-httpfs/lib/*
3.配置mapred-site.xml
[root@master1 conf]# vim mapred-site.xml
添加:
/etc/hadoop/conf/*,
/usr/hdp/2.6.3.0-235/hadoop/*,
/usr/hdp/2.6.3.0-235/hadoop-hdfs/*,
/usr/hdp/2.6.3.0-235/hadoop-yarn/*,
/usr/hdp/2.6.3.0-235/hadoop-mapreduce/*,
/usr/hdp/2.6.3.0-235/hadoop/lib/*,
/usr/hdp/2.6.3.0-235/hadoop-hdfs/lib/*,
/usr/hdp/2.6.3.0-235/hadoop-yarn/lib/*,
/usr/hdp/2.6.3.0-235/hadoop-mapreduce/lib/*
4.配置yarn的本地目录
[root@master1 ~]# touch /etc/hadoop/conf/yarn-env.sh
[root@master1 ~]# mkdir -p /hadoop/yarn/local
[root@master1 ~]# chown yarn:yarn -R /hadoop/yarn/local
5.启动服务
在master2上开启resourcemanager:
[root@master2 ~]# systemctl start hadoop-yarn-resourcemanager
访问web后台master2:8088
在slave1、slave2上开启historyserver
[root@slave1 ~]# systemctl start hadoop-mapreduce-historyserver
[root@slave2 ~]# systemctl start hadoop-mapreduce-historyserver
在所有启动datanode的节点上开nodemanager
[root@slave2 ~]# systemctl start hadoop-yarn-nodemanager
6.验证
master2:8088
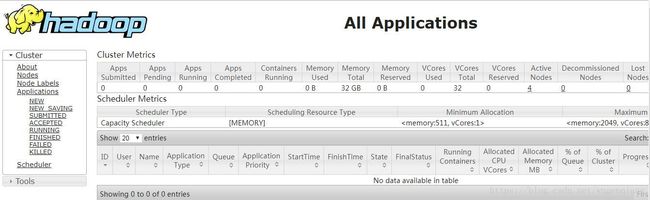
slave1:19888

vim 的简单快捷键
在命令模式下,
dd 删除一行
yy 复制一行
y3 复制此行下面的三行(共四行)
3yy 复制包括此行的三行(共三行)
u 恢复上一步(后退)
r 替换
x 删除
p 粘贴
#2018-07-16#
ip:192.168.75.213
cd $HADOOP_HOME/etc/hadoop
systemctl start hadoop-hdfs-namenode
cd /var/log/
more hadoop-hdfs-namenode-wugenqiang.bigdata.log
[root@wugenqiang /]# mkdir -p /hdfs/{name,data}
[root@wugenqiang /]# chown -R hdfs:hadoop /hdfs
使用“hdfs dfsadmin -report”命令查看节点的报告信息
#2018-07-13#
db
use wgq
show tables
gte大于等于
lte小于等于
创建root用户
db.createUser({user:"root",pwd:"123456",roles:["root"]})
mongod -shutdown -dbpath=/usr/local/mongodb/data
mongod --auth --dbpath=/usr/local/mongodb/data --journal
mongo
> use admin
switched to db admin
> db.auth("root","123456")
#2018-07-12#
10.10.12.213 wugenqiang.bigdata weigion
192.168.35.241 yuc.hanwate yuc
192.168.35.226 lxj.jit lxj
/usr/local/mongodb/bin/mongod --dbpath=/usr/local/mongodb/data --logpath=/usr/local/mongodb/mongodb.log --logappend --auth --port=27017 --fork
设置监听
mongod --dbpath=/usr/local/mongodb/data --journal
查看开启服务
netstat -ntlp
db.students.find().pretty()
#2018-07-11#
别名:alias
eg:alias tom='ls -la'
unalias 删除别名
unalias tom
vi /etc/bashrc
export PATH="/home/weigion/study":$PATH
source /etc/bashrc
env |grrep PATH
vi .bashrc
44
du -sh *
按文件大小查看文件
du -sh *|grep k |sort
reboot重启
分磁盘查看
fdisk -l
ls /dev/sda
fdisk /etc/sdb
分区 n
打印 p
删除 d
退出 q
写入 w
修改类型 t
查看ls /dev/sdb*
mkfs
格式化
mkfs.ext4 /dev/sdb1
挂载磁盘
建立挂载点
mkdir /mnt/sdb1
mount /dev/sdb1 /mnt/sdb1
df |grep sdb
cd /mnt/sdb1
查看挂载点df -h
umount /home
文件更改挂载点
vim /etc/fstab
软链接
ln -s hello.sh hello
ps ax
ps axu
top -d
uptime
free -h
vim /etc/sysconfig/network-scripts/ifcfg-ens33
重启网络systemctl restart network
ip:192.168.52.174
ip:10.10.12.213
老师 10.10.10.217
192.168.35.241
ping dev.mysql.com
ps
fg
fg 命令使用最近在后台被暂挂的作业,或者作为后台作业运行
#2018-07-10#
1. dev中设备
创建文件夹 mkdir
删除 rmdir 或 rm
更名/移动 mv
设置行号:set number
查找文件 find /usr/sbin -name ssh*
locate sshd
使用命令iconv对文件内容编码进行转换。
例如我有一个文件"pos.txt"在windows下打开正常,
而在linux下打开则会乱码,办法为在终端输入:
iconv -f gbk -tutf8 pos.txt > pos.txt.utf8
tcpdump抓取包
scp拷贝
scp a [email protected]:~/a2
chmod 改权限
rwx:4 2 1 可读可写可执行
/etc/group