学习File API用于前端读取文件
1. File API简介
File API对于某些专门的网站的不可或缺的。现在常用它实现对文件的预览等功能。
File API规定怎么从硬盘上提取文件,直接交给在网页中运行中的Javascript代码。然后代码可以打开文件探究数据,无论是本地文件还是其他文件。注意,关键在于文件会被直接交给JavaScript代码,它并不能修改文件,也不能创建新文件,想要保存任何数据,需要将数据发送到服务器或者保存在本地存储空间中。
2. 读取文件
在通过File API操作文件之前,首先必须取得文件。使用File API可以直接读取文本文件的内容。
例如:
<html>
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<title>文件上传title>
<style>
#fileOutput {
border:1px grey solid;
width: 500px;
}
style>
head>
<body>
<input type="file" id="fileInput" onChange="processFiles(this.files)">
<div id="fileOutput">div>
<script>
function processFiles(files) {
//每个文件对象都有三个有用的属性:name属性保存文件名,size属性保存文件的字节大小,type保存文件的MEMI类型
var file = files[0];
//创建FileReader对象,
var reader = new FileReader();
//FileReader用来提取文件内容,但是这个方法是异步的,要提取文件,首先要处理onLoad事件
reader.onload = function(e) {
//这个事件发生了,意味着数据准备好了,
//把它复制到页面的div元素中
var output = document.getElementById("fileOutput");
//将文件内容转换成一个长字符串,保存在onload事件的e.target.result中
output.textContent = e.target.result;
};
//调用FileReader的readAsText()方法
reader.readAsText(file);
}
script>
body>
html>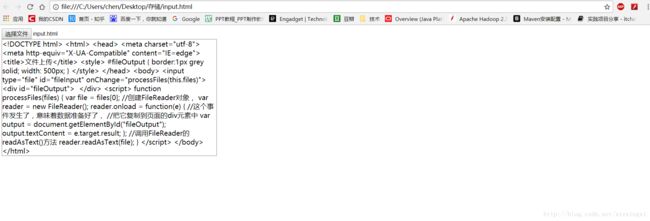
上图中,选择一个文件,无需上传,网页中的javascript代码就能取得文本文件,把内容复制到页面中。
readAsText()方法只能处理文本内容的文件,如CSV格式,XML格式,.docx格式和.xlsx格式的文件。
readAsText()方法只是众多读取文件的方法之一,还有readAsBinaryStrng(),readAsDataURL()和readAsArrayBuffer().
- readAsBinaryStrng()方法可以让应用处理二进制编码的数据,但基本上就是把数据保存在一个文本字符串中,效率不高。
- readAsArrayBuffer()是对于做数据处理较好的选择,这个方法将数据读到一个数组中,每个数组项代表一字节数据。这套方案的优势是可以用来创建大块数据,然后切分成更小的二进制数据块,以便逐块处理。
- readAsDataURL()方法则让我们能方便地取到图片数据。
2.1 一次读取多个文件
HTML5也支持一次提交多个文件,只要为元素添加multiple属性即可:
"file" id="Files" name="files[]" multiple />
<div id="Lists">div> function fileSelect(e) {
e = e || window.event;
var files = e.target.files; //FileList Objects
var output = [];
for(var i = 0, f; f = files[i]; i++) {
output.push('' + f.name + '(' + f.type + ') - ' + f.size +' bytes');
}
document.getElementById('Lists').innerHTML = ''
+ output.join('') + '';
}
if(window.File && window.FileList && window.FileReader && window.Blob) {
document.getElementById('Files').addEventListener('change', fileSelect, false);
} else {
document.write('您的浏览器不支持File Api');
} 由以上代码可以看到,html5为file这个dom元素新增了files接口(e.target指向了file input元素,实际上也可以用this来访问,即this.files),得到的就是FileList,通过遍历该集合,即可访问到各个已选择的文件对象。
2.2 通过拖拽读取图片文件
前面我们看到,FileReader处理文本内容只需要一步,同样,处理图片内容也这么简单,而这就要归功于readAsDataURL()方法。
下面的例子中,让用户把图片拖到页面中,然后在图片上绘制。
下面是HTML和css代码
<html lang="en">
<head>
<meta charset="UTF-8">
<title>拖拽图片title>
<style>
#dropBox {
margin: 15px;
width: 300px;
height: 300px;
border:5px dashed grey;
border-radius: 8px;
background: lightyellow;
background-size: 100%;
background-repeat: no-repeat;
text-align: center;
}
#dropBox div{
margin: 100px 70px;
color: orange;
font-size: 25px;
}
style>
head>
<body>
<div id="dropBox">
<div>将你的图片拖到此处div>
div>
body>
html>为处理放置文件的操作,需要处理三个事件:onDragEnter、onDragOver、onDrop。页面一加载完成,就会为这三个事件添加处理程序。
var dropBox;
window.onload = function() {
dropBox = document.getElementById("dropBox");
dropBox.ondragenter = ignoreDrag;
dropBox.ondragover = ignoreDrag;
dropBox.ondrop = drop;
}其中,ignoreDrag()函数同时处理onDragEnter和onDragOver事件,前者在鼠标指针进入放置区时发生,后者在拖动文件的鼠标指针位于放置区之上时发生。之所以用同一个函数处理两个事件,原因就是不必对这两个事件作出反应,只要告诉浏览器自己什么也不做即可。
function ignoreDrag(e) {
//因为我们在处理拖放,所以应该确保没有其他元素会取得这个事件
e.stopPropagation();
e.preventDefault();
}我们要响应的事件是onDrop,这个事件一发生就说明要取得和处理文件了。
function drop(e) {
//取消事件传播及默认行为
e.stopPropagation();
e.preventDefault();
//取得拖进来的文件
var data = e.dataTransfer;
var files = data.files;
//将其传给真正的处理文件的函数
processFiles(files);
}
function processFiles(files) {
var file = files[0];
//创建FileReader
var reader = new FileReader();
//告诉它准备好数据URL之后做什么
reader.onload = function(e) {
dropBox.style.backgroundImage = "url('" + e.target.result + "')";
};
//读取图片:将图片转化为数据URL
reader.readAsDataURL(file);
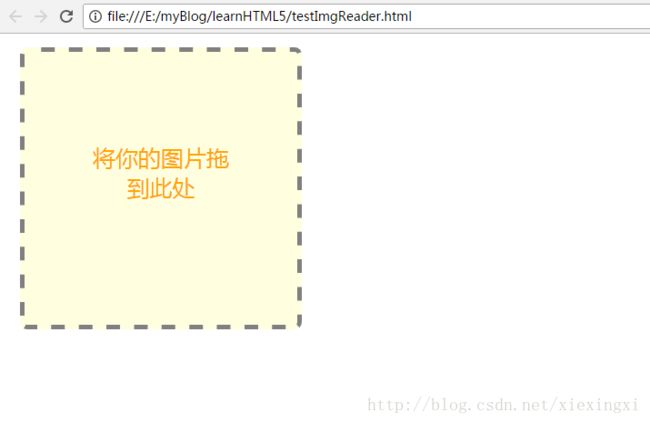
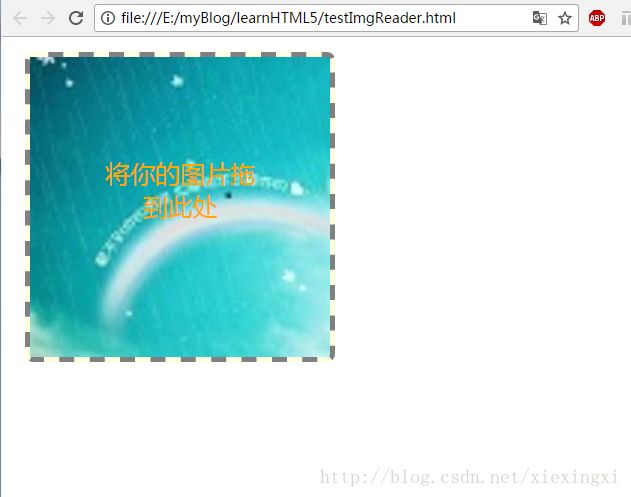
}效果图:
拖拽前:
拖拽后:
2.3 浏览器对File API的支持情况

更多内容请参考此处