拉格朗日乘子法与拉格朗日对偶性
拉格朗日乘子法
摘自周志华《机器学习》
拉格朗日乘子法是一种寻找多元函数在一组约束下的极值的方法,通过引入拉格朗日乘子,可将有 d d d个变量和 k k k个约束条件的最优化问题转化为具有 d + k d+k d+k个变量的无约束优化问题求解.
先考虑一个等式约束的优化问题,假定 x \boldsymbol x x为 d d d维向量,欲寻求 x \boldsymbol x x的某个取值 x ∗ \boldsymbol x^* x∗,使目标函数 f ( x ) f(\boldsymbol x) f(x)最小且同时满足 g ( x ) = 0 g(\boldsymbol x)=0 g(x)=0的约束. 从几何角度来看,该问题的目标是在方程 g ( x ) = 0 g(\boldsymbol x)=0 g(x)=0确定的 d − 1 d-1 d−1维曲面上寻找能使目标函数 f ( x ) f(\boldsymbol x) f(x)最小化的点. 由此可以得出如下结论:
- 对于约束曲面上的任意点 x x x,该点的梯度 ∇ g ( x ) \nabla g(\boldsymbol{x}) ∇g(x)正交于约束曲面;
- 在最优点 x ∗ \boldsymbol x^* x∗,目标函数在该点的梯度 ∇ f ( x ∗ ) \nabla f(\boldsymbol{x^*}) ∇f(x∗)正交于约束曲面.
由此可知,在最优点 x ∗ \boldsymbol x^* x∗,如图1所示梯度 ∇ g ( x ) \nabla g(\boldsymbol{x}) ∇g(x)与梯度 ∇ f ( x ) \nabla f(\boldsymbol{x}) ∇f(x)的方向必相同或相反,即存在 λ ≠ 0 \lambda \neq 0 λ=0使得 ∇ f ( x ∗ ) + λ ∇ g ( x ∗ ) = 0 ( 1 ) \nabla f\left(\boldsymbol{x}^{*}\right)+\lambda \nabla g\left(\boldsymbol{x}^{*}\right)=0 \quad(1) ∇f(x∗)+λ∇g(x∗)=0(1) λ \lambda λ称为拉格朗日乘子 定义拉格朗日函数 L ( x , λ ) = f ( x ) + λ g ( x ) ( 2 ) L(\boldsymbol{x}, \lambda)=f(\boldsymbol{x})+\lambda g(\boldsymbol{x})\quad(2) L(x,λ)=f(x)+λg(x)(2)不难发现,将其对 x x x的偏导数 ∇ x L ( x , λ ) \nabla_{\boldsymbol{x}} L(\boldsymbol{x}, \lambda) ∇xL(x,λ)置零得式 ( 1 ) (1) (1),同时,将其对 λ \lambda λ的偏导数 ∇ λ L ( x , λ ) \nabla_{\boldsymbol{\lambda}} L(\boldsymbol{x}, \lambda) ∇λL(x,λ)置零的得约束条件 g ( x ) = 0 g( \boldsymbol x)=0 g(x)=0,于是原约束优化问题可转化为对拉格朗日函数 L ( x , λ ) L(\boldsymbol{x}, \lambda) L(x,λ)的无约束优化问题
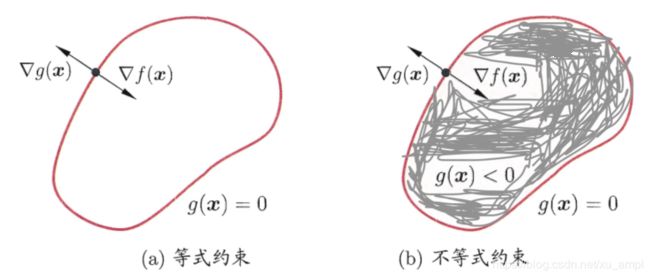
图1 拉格朗日乘子法的几何含义:在 ( a ) (a) (a)等式约束 g ( x ) = 0 g(\boldsymbol x)=0 g(x)=0或不等式约束 g ( x ) ⩽ 0 g(\boldsymbol{x}) \leqslant 0 g(x)⩽0下,最小化目标函数 f ( x ) f(x) f(x),红色曲线表示 g ( x ) = 0 g(\boldsymbol x)=0 g(x)=0构成的曲面,其围成的阴影区域表示 g ( x ) < 0 g(\boldsymbol{x}) < 0 g(x)<0
现考虑不等式约束 g ( x ) ⩽ 0 g(\boldsymbol{x}) \leqslant 0 g(x)⩽0,如图1所示,此时最优点 x ∗ \boldsymbol x^* x∗或在 g ( x ) < 0 g(\boldsymbol{x}) < 0 g(x)<0的区域中,或在边界上 g ( x ) = 0 g(\boldsymbol x)=0 g(x)=0.
- 对于 g ( x ) < 0 g(\boldsymbol{x}) < 0 g(x)<0的情形,约束 g ( x ) ⩽ 0 g(\boldsymbol{x}) \leqslant 0 g(x)⩽0不起作用,可直接通过 ∇ f ( x ) = 0 \nabla f(\boldsymbol{x})=0 ∇f(x)=0
来获取最优点;这等价于将 λ \lambda λ置零然后对 ∇ x L ( x , λ ) \nabla_{\boldsymbol{x}} L(\boldsymbol{x}, \lambda) ∇xL(x,λ)置零得到最优点. - g ( x ) = 0 g(\boldsymbol x)=0 g(x)=0的情形类似于上面等式约束的分析,需注意的是,此时 ∇ f ( x ∗ ) = 0 \nabla f(\boldsymbol{x^*})=0 ∇f(x∗)=0的方向必与 ∇ g ( x ∗ ) = 0 \nabla g(\boldsymbol{x^*})=0 ∇g(x∗)=0相反,即存在常数 λ > 0 \lambda >0 λ>0使得 ∇ f ( x ∗ ) + λ ∇ g ( x ∗ ) = 0 \nabla f\left(\boldsymbol{x}^{*}\right)+\lambda \nabla g\left(\boldsymbol{x}^{*}\right)=0 ∇f(x∗)+λ∇g(x∗)=0.
整合这两种情形,必满足 λ g ( x ) = 0 \lambda g(\boldsymbol x)=0 λg(x)=0因此在约束 g ( x ) < 0 g(\boldsymbol{x}) < 0 g(x)<0下最小化 f ( x ) f(\boldsymbol x) f(x),可转化为在约束下最小化式 ( 2 ) (2) (2)的拉格朗日函数:
{ g ( x ) ⩽ 0 λ ⩾ 0 ( 3 ) λ g ( x ) = 0 \left\{\begin{array}{l}{g(\boldsymbol{x}) \leqslant 0} \\ {\lambda \geqslant 0} \qquad\qquad(3)\\ {\lambda g(\boldsymbol{x})=0}\end{array}\right. ⎩⎨⎧g(x)⩽0λ⩾0(3)λg(x)=0式 ( 3 ) (3) (3)称为 k a r u s h − K u h n − T u c k e r karush-Kuhn-Tucker karush−Kuhn−Tucker (KKT)条件.
上述做法可推广到多个约束
min x f ( x ) \min _{\boldsymbol{x}} f(\boldsymbol{x}) xminf(x) s.t. g j ( x ) ⩽ 0 ( j = 1 , … , n ) ( 4 ) \text { s.t. } \quad g_{j}(\boldsymbol{x}) \leqslant 0 \quad(j=1, \ldots, n) \qquad(4) s.t. gj(x)⩽0(j=1,…,n)(4) h i ( x ) = 0 ( i = 1 , … , m ) h_{i}(\boldsymbol{x})=0 \quad(i=1, \ldots, m) hi(x)=0(i=1,…,m)引入拉格朗日乘子 λ = ( λ 1 , λ 2 , … , λ m ) T \boldsymbol{\lambda}=\left(\lambda_{1}, \lambda_{2}, \ldots, \lambda_{m}\right)^{\mathrm{T}} λ=(λ1,λ2,…,λm)T和 μ = ( μ 1 , μ 2 , … , μ n ) T \boldsymbol{\mu}=\left(\mu_{1}, \mu_{2}, \ldots, \mu_{n}\right)^{\mathrm{T}} μ=(μ1,μ2,…,μn)T,相应的拉格朗日函数为
L ( x , λ , μ ) = f ( x ) + ∑ j = 1 n μ j g j ( x ) + ∑ i = 1 m λ i h i ( x ) ( 5 ) L(\boldsymbol{x}, \boldsymbol{\lambda}, \boldsymbol{\mu})=f(\boldsymbol{x})+\sum_{j=1}^{n} \mu_{j} g_{j}(\boldsymbol{x})+\sum_{i=1}^{m} \lambda_{i} h_{i}(\boldsymbol{x}) \qquad(5) L(x,λ,μ)=f(x)+j=1∑nμjgj(x)+i=1∑mλihi(x)(5)由不等式约束引入的 K K T KKT KKT由不等式约束引入的条件 ( j = 1 , 2 , … , n ) (j=1,2, \dots, n) (j=1,2,…,n)为
{ g j ( x ) ⩽ 0 μ j ⩾ 0 ( 6 ) μ j g j ( x ) = 0 \left\{\begin{array}{l}{g_{j}(\boldsymbol{x}) \leqslant 0} \\ {\mu_{j} \geqslant 0}\qquad\qquad (6) \\ {\mu_{j} g_{j}(\boldsymbol{x})=0}\end{array}\right. ⎩⎨⎧gj(x)⩽0μj⩾0(6)μjgj(x)=0
拉格朗日对偶性
摘自李航《统计学习方法》
约束优化问题中,常常利用拉格朗日对偶性将原始问题转换为对偶问题,通过解对对偶问题而得到原始问题。该方法应用在许多统计学习方法中,例如最大熵模型和支持向量机。
1 原始问题
假设 f ( x ) , c i ( x ) , h j ( x ) f(x), c_{i}(x),h_{j}(x) f(x),ci(x),hj(x)是定义在 R n R^n Rn上的连续可微函数。考虑约束最优化问题.
min x ∈ R n f ( x ) ( 1 ) s.t. c i ( x ) ⩽ 0 , i = 1 , 2 , ⋯ , k ( 2 ) h j ( x ) = 0 , j = 1 , 2 , ⋯ , l ( 3 ) \min _{x \in R^{n}} f(x) \qquad (1) \\ \text { s.t. } \quad c_{i}(x) \leqslant 0, \quad i=1,2, \cdots, k \qquad (2)\\ h_{j}(x)=0, \quad j=1,2, \cdots, l \qquad(3) x∈Rnminf(x)(1) s.t. ci(x)⩽0,i=1,2,⋯,k(2)hj(x)=0,j=1,2,⋯,l(3)称此约束最优化问题为原始最优化问题或原始问题
首先,引进广义拉格朗日函数 ( g e n e r a l i z e d L a g r a n g e f u n c t i o n generalized\, Lagrange \, function generalizedLagrangefunction)
L ( x , α , β ) = f ( x ) + ∑ i = 1 k α i c i ( x ) + ∑ j = 1 l β j h j ( x ) ( 4 ) x = ( x ( 1 ) , x ( 2 ) , ⋯ , x ( n ) ) T ∈ R n , L(x, \alpha, \beta)=f(x)+\sum_{i=1}^{k} \alpha_{i} c_{i}(x)+\sum_{j=1}^{l} \beta_{j} h_{j}(x) \qquad (4) \\ x=\left(x^{(1)}, x^{(2)}, \cdots, x^{(n)}\right)^{\mathrm{T}} \in \mathbf{R}^{n}, L(x,α,β)=f(x)+i=1∑kαici(x)+j=1∑lβjhj(x)(4)x=(x(1),x(2),⋯,x(n))T∈Rn, α i , β j \alpha_{i}, \beta_{j} αi,βj是拉格朗日乘子, α i ⩾ 0 \alpha_{i} \geqslant 0 αi⩾0考虑 x x x的函数 θ P ( x ) = max α , β ; α i ⩾ 0 L ( x , α , β ) ( 5 ) \theta_{P}(x)=\max _{\alpha, \beta ; \alpha_{i} \geqslant 0} L(x, \alpha, \beta) \qquad (5) θP(x)=α,β;αi⩾0maxL(x,α,β)(5) 这里,下标 P P P表示原始问题假设给定某个 x x x,如果 x x x违反原始问题的约束条件,即存在某个 i i i,使得 c i ( x ) > 0 c_i(x)>0 ci(x)>0或者存在 j j j某个使得 h j ( x ) ≠ 0 h_{j}(x) \neq 0 hj(x)=0,那么就有 θ P ( x ) = max α , β : α i ⩾ 0 [ f ( x ) + ∑ i = 1 k α i c i ( x ) + ∑ j = 1 l β j h j ( x ) ] = + ∞ ( 6 ) \theta_{P}(x)=\max _{\alpha, \beta : \alpha_{i} \geqslant 0}\left[f(x)+\sum_{i=1}^{k} \alpha_{i} c_{i}(x)+\sum_{j=1}^{l} \beta_{j} h_{j}(x)\right]=+\infty \qquad (6) θP(x)=α,β:αi⩾0max[f(x)+i=1∑kαici(x)+j=1∑lβjhj(x)]=+∞(6)
因为若某个 i i i使约束 c i ( x ) > 0 c_i(x)>0 ci(x)>0,则可令 α i → + ∞ \alpha_i \rightarrow+\infty αi→+∞ ,若某个 j j j使得,则可令使得 h j ( x ) ≠ 0 h_{j}(x) \neq 0 hj(x)=0,而其余的 α i , β j \alpha_{i}, \beta_{j} αi,βj,均取为0.相反地,如果 x x x满足约束条件式 ( 2 ) (2) (2)和式 ( 3 ) (3) (3),则由式 ( 5 ) (5) (5)和式 ( 4 ) (4) (4)可知 θ P ( x ) = f ( x ) \theta_{P}(x)=f(x) θP(x)=f(x),因此,
θ P ( x ) = { f ( x ) , x 满 足 原 始 问 题 约 束 + ∞ , 其 他 ( 7 ) \theta_{P}(x)=\left\{\begin{array}{l}{f(x)} , x满足原始问题约束\\ {+\infty},其他\end{array}\right. \quad(7) θP(x)={f(x),x满足原始问题约束+∞,其他(7)
所以如果考虑极小化问题 min x θ P ( x ) = min x max α , β : α i ⩾ 0 L ( x , α , β ) ( 8 ) \min _{x} \theta_{P}(x)=\min _{x} \max _{\alpha, \beta : \alpha_{i} \geqslant 0} L(x, \alpha, \beta) \qquad(8) xminθP(x)=xminα,β:αi⩾0maxL(x,α,β)(8)它是与原始优化问题 ( 1 ) ∼ ( 3 ) (1)\sim(3) (1)∼(3)等价的,即它们有相同的解。问题
min x max α , β : α i ⩾ 0 L ( x , α , β ) \min _{x} \max _{\alpha, \beta : \alpha_{i} \geqslant 0} L(x, \alpha, \beta) xminα,β:αi⩾0maxL(x,α,β)称为广义拉格朗日的极小极大问题,这样把原始问题表示为广义拉格朗日函数的极小极大问题。为了方便,定义原始问题的最优解 p ∗ = min x θ P ( x ) ( 9 ) p^{*}=\min _{x} \theta_{P}(x) \qquad(9) p∗=xminθP(x)(9)为原始问题的值。
2 对偶问题
定义 θ D ( α , β ) = min x L ( x , α , β ) ( 10 ) \theta_{D}(\alpha, \beta)=\min _{x} L(x, \alpha, \beta) \qquad(10) θD(α,β)=xminL(x,α,β)(10)再考虑极大化 θ D ( α , β ) = min x L ( x , α , β ) \theta_{D}(\alpha, \beta)=\min _{x} L(x, \alpha, \beta) θD(α,β)=minxL(x,α,β),即 max α , β : α i ≥ 0 θ D ( α , β ) = max α , β ; α i ⩾ 0 min x L ( x , α , β ) ( 11 ) \max _{\alpha, \beta : \alpha_{i} \geq 0} \theta_{D}(\alpha, \beta)=\max _{\alpha, \beta ; \alpha_{i} \geqslant 0} \min _{x} L(x, \alpha, \beta) \qquad(11) α,β:αi≥0maxθD(α,β)=α,β;αi⩾0maxxminL(x,α,β)(11)问题 max α , β ; α i ⩾ 0 min x L ( x , α , β ) \max _{\alpha, \beta ; \alpha_{i} \geqslant 0} \min _{x} L(x, \alpha, \beta) α,β;αi⩾0maxxminL(x,α,β)称为广义拉格朗日函数的极大极小问题可以将广义拉格朗日的极大极小问题表示为约束最优化问题: max α , β θ D ( α , β ) = max α , β min x L ( x , α , β ) ( 12 ) \max _{\alpha, \beta} \theta_{D}(\alpha, \beta)=\max _{\alpha, \beta} \min _{x} L(x, \alpha, \beta) \qquad(12) α,βmaxθD(α,β)=α,βmaxxminL(x,α,β)(12) s.t. α i ⩾ 0 , i = 1 , 2 , ⋯ , k ( 13 ) \text { s.t. } \quad \alpha_{i} \geqslant 0, \quad i=1,2, \cdots, k \qquad(13) s.t. αi⩾0,i=1,2,⋯,k(13)称为原始问题的对偶问题。
定义对偶问题的最优值 d ∗ = max α , β : α i ⩾ 0 θ D ( α , β ) ( 14 ) d^{*}=\max _{\alpha, \beta : \alpha_{i} \geqslant 0} \theta_{D}(\alpha, \beta) \qquad(14) d∗=α,β:αi⩾0maxθD(α,β)(14)称为对偶问题的值。
3 原始问题和对偶问题的关系
定理1 \; 若原始问题和对偶问题都有最优值,则
d ∗ = max α , β : α i ⩾ 0 min x L ( x , α , β ) ⩽ min x max α , β : α i ⩾ 0 L ( x , α , β ) = p ∗ ( 15 ) d^{*}=\max _{\alpha, \beta : \alpha_{i} \geqslant 0} \min _{x} L(x, \alpha, \beta) \leqslant \min _{x} \max _{\alpha, \beta : \alpha_{i} \geqslant 0} L(x, \alpha, \beta)=p^{*} \qquad(15) d∗=α,β:αi⩾0maxxminL(x,α,β)⩽xminα,β:αi⩾0maxL(x,α,β)=p∗(15)证明:由式 ( 12 ) (12) (12)和 ( 5 ) (5) (5),对任意的 α , β \alpha,\beta α,β和 x x x,有
θ D ( α , β ) = min x L ( x , α , β ) ⩽ L ( x , α , β ) ⩽ max α , β : α i ≥ 0 L ( x , α , β ) = θ P ( x ) ( 16 ) \theta_{D}(\alpha, \beta)=\min _{x} L(x, \alpha, \beta) \leqslant L(x, \alpha, \beta) \leqslant \max _{\alpha, \beta : \alpha_{i} \geq 0} L(x, \alpha, \beta)=\theta_{P}(x) \quad(16) θD(α,β)=xminL(x,α,β)⩽L(x,α,β)⩽α,β:αi≥0maxL(x,α,β)=θP(x)(16)即 \quad θ D ( α , β ) ⩽ θ P ( x ) ( 17 ) \theta_{D}(\alpha, \beta) \leqslant \theta_{P}(x) \qquad(17) θD(α,β)⩽θP(x)(17)
由于原始问题和对偶问题均有最优解,所以,
max α , β : α i ⩾ 0 θ D ( α , β ) ⩽ min x θ P ( x ) ( 18 ) \max _{\alpha, \beta : \alpha_{i} \geqslant 0} \theta_{D}(\alpha, \beta) \leqslant \min _{x} \theta_{P}(x) \qquad(18) α,β:αi⩾0maxθD(α,β)⩽xminθP(x)(18)
即 d ∗ = max α , β : α i ⩾ 0 min x L ( x , α , β ) ⩽ min x max α , β : α i ⩾ 0 L ( x , α , β ) = p ∗ ( 19 ) d^{*}=\max _{\alpha, \beta : \alpha_{i} \geqslant 0} \min _{x} L(x, \alpha, \beta) \leqslant \min _{x} \max _{\alpha, \beta : \alpha_{i} \geqslant 0} L(x, \alpha, \beta)=p^{*} \qquad(19) d∗=α,β:αi⩾0maxxminL(x,α,β)⩽xminα,β:αi⩾0maxL(x,α,β)=p∗(19)
推论1 \; 设 x ∗ x^* x∗ 和 α ∗ , β ∗ \alpha^*,\beta^* α∗,β∗分别是原始问题 ( 1 ) ∼ ( 3 ) (1)\sim(3) (1)∼(3)和对偶问题 ( 12 ) ∼ ( 13 ) (12)\sim(13) (12)∼(13)的可行解,并且 d ∗ = p ∗ d^*=p^* d∗=p∗,则 x ∗ x^* x∗和 α ∗ , β ∗ \alpha^*,\beta^* α∗,β∗分别是原始问题和对偶问题的最优解。
在某些条件下,原始问题和对偶问题的最优值相等, d ∗ = p ∗ d^*=p^* d∗=p∗,这时可以用解对偶问题代替原始问题。
定理2: \; 考虑原始问题 ( 1 ) ∼ ( 3 ) (1)\sim(3) (1)∼(3)和对偶问题 ( 12 ) ∼ ( 13 ) (12)\sim(13) (12)∼(13)。假设函数 f ( x ) f(x) f(x)和 c i ( x ) c_i(x) ci(x)是凸函数, h j ( x ) h_j(x) hj(x)是仿射函数;并且假设不等式约束 c i ( x ) c_i(x) ci(x)是严格可行的,即存在 x x x,对所有 i i i有 c i ( x ) < 0 c_i(x)<0 ci(x)<0,并且存在 x ∗ , α ∗ , β ∗ x^{*}, \alpha^{*}, \beta^{*} x∗,α∗,β∗,使 x ∗ x^* x∗是原始问题的解, α ∗ , β ∗ \alpha^{*}, \beta^{*} α∗,β∗是对偶问题的解,并且 p ∗ = d ∗ = L ( x ∗ , α ∗ , β ∗ ) ( 20 ) p^{*}=d^{*}=L\left(x^{*}, \alpha^{*}, \beta^{*}\right) \qquad(20) p∗=d∗=L(x∗,α∗,β∗)(20)定理3: \; 对原始问题 ( 1 ) ∼ ( 3 ) (1)\sim(3) (1)∼(3)和对偶问题 ( 12 ) ∼ ( 13 ) (12)\sim(13) (12)∼(13)。假设函数 f ( x ) f(x) f(x)和 c i ( x ) c_i(x) ci(x)是凸函数, h j ( x ) h_j(x) hj(x)是仿射函数;并且假设不等式约束 c i ( x ) c_i(x) ci(x)是严格可行的,即存在 x x x,对所有 i i i有 c i ( x ) < 0 c_i(x)<0 ci(x)<0,并且存在 x ∗ , α ∗ , β ∗ x^{*}, \alpha^{*}, \beta^{*} x∗,α∗,β∗,使 x ∗ x^* x∗是原始问题的解, α ∗ , β ∗ \alpha^{*}, \beta^{*} α∗,β∗是对偶问题的解充分必要条件是 x ∗ , α ∗ , β ∗ x^{*}, \alpha^{*}, \beta^{*} x∗,α∗,β∗满足下面的 K a r u s h − K u h n − T u c k e r ( K K T ) Karush-Kuhn-Tucker(KKT) Karush−Kuhn−Tucker(KKT)条件: ∇ x L ( x ∗ , α ∗ , β ∗ ) = 0 ( 21 ) \nabla_{x} L\left(x^{*}, \alpha^{*}, \beta^{*}\right)=0 \qquad(21) ∇xL(x∗,α∗,β∗)=0(21) ∇ α L ( x ∗ , α ∗ , β ∗ ) = 0 ( 22 ) \nabla_{\alpha} L\left(x^{*}, \alpha^{*}, \beta^{*}\right)=0 \qquad(22) ∇αL(x∗,α∗,β∗)=0(22) ∇ β L ( x ∗ , α ∗ , β ∗ ) = 0 ( 23 ) \nabla_{\beta} L\left(x^{*}, \alpha^{*}, \beta^{*}\right)=0 \qquad(23) ∇βL(x∗,α∗,β∗)=0(23) α i ∗ c i ( x ∗ ) = 0 , i = 1 , 2 , ⋯ , k ( 24 ) \alpha_{i}^{*} c_{i}\left(x^{*}\right)=0, \quad i=1,2, \cdots, k \quad(24) αi∗ci(x∗)=0,i=1,2,⋯,k(24) c i ( x ∗ ) ⩽ 0 , i = 1 , 2 , ⋯ , k ( 25 ) c_{i}\left(x^{*}\right) \leqslant 0, \quad i=1,2, \cdots, k \qquad(25) ci(x∗)⩽0,i=1,2,⋯,k(25) α i ∗ ⩾ 0 , i = 1 , 2 , ⋯ , k ( 26 ) \alpha_{i}^{*} \geqslant 0, \quad i=1,2, \cdots, k \qquad(26) αi∗⩾0,i=1,2,⋯,k(26) h j ( x ∗ ) = 0 j = 1 , 2 , ⋯ , l ( 27 ) h_{j}\left(x^{*}\right)=0 \quad j=1,2, \cdots, l \qquad(27) hj(x∗)=0j=1,2,⋯,l(27)特别指出,式 ( 24 ) (24) (24)称为KKT的对偶互补条件,由此条件可知:若 α i ∗ > 0 \alpha_{i}^{*}>0 αi∗>0,则 c i ( x ∗ ) = 0 c_{i}\left(x^{*}\right)=0 ci(x∗)=0