Myqsl 流式查询
链接地址: Mybatis中使用流式查询避免数据量过大导致OOM
一、JDBC编程中mysql流式查询
1.为什么使用流式查询?
普通查询方式:
1)JVM进程内数据库线程池,某一线程执行查询时,调用mysql驱动程序。
2)mysql驱动向mysql服务器发起TCP请求,服务器端根据条件查询匹配的数据,然后通过TCP链接发送到MySQL驱动。
3)mysql驱动把符合条件的数据缓存到驱动内存中,待数据发送结束,返回给应用程序缓存数据。
所以,mysql驱动内存就可能在访问大量数据(使用场景)时发生OOM。
为了有效避免OOM,mysql客户端流式查询不会同时把服务器端的所有符合条件的数据缓存起来,而是一部分一部分的把服务器端返回的数据返回给应用程序层。
2.代码示例:
public void selectData(String sqlCmd,) throws SQLException {
validate(sqlCmd);
Connection conn = null;
PreparedStatement stmt = null;
ResultSet rs = null;
try {
conn = petadataSource.getConnection();
/** 设置为流式查询 */
stmt = conn.prepareStatement(sqlCmd, ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
stmt.setFetchSize(Integer.MIN_VALUE);
rs = stmt.executeQuery();
try {
while(rs.next()){
try {
System.out.println("one:" + rs.getString(1) + "two:" + rs.getString(2) + "thrid:" + rs.getString(3));
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} finally {
close(stmt, rs, conn);
}
}二、Mybaits中MyBatisCursorItemReader的使用
2.1 配置
- MyBatisCursorItemReader的注入
其中queryId为mapper文件中接口名称。
- Mapper.xml设置
![]()
其中fetchSize=”-2147483648″,Integer.MIN_VALUE=-2147483648
2.2 使用
static void testCursor1() throws UnexpectedInputException, ParseException, Exception {
try {
Map param = new HashMap();
AccsDeviceInfoDAOExample accsDeviceInfoDAOExample = new AccsDeviceInfoDAOExample();
accsDeviceInfoDAOExample.createCriteria().andAppKeyEqualTo("12345").andAppVersionEqualTo("5.7.2.4.5")
.andPackageNameEqualTo("com.test.zlx");
param.put("oredCriteria", accsDeviceInfoDAOExample.getOredCriteria());
// 设置参数
myMyBatisCursorItemReader.setParameterValues(param);
// 创建游标
myMyBatisCursorItemReader.open(new ExecutionContext());
//使用游标迭代获取每个记录
Long count = 0L;
AccsDeviceInfoDAO accsDeviceInfoDAO;
while ((accsDeviceInfoDAO = myMyBatisCursorItemReader.read()) != null) {
System.out.println(JSON.toJSONString(accsDeviceInfoDAO));
++count;
System.out.println(count);
}
} catch (Exception e) {
System.out.println("error:" + e.getLocalizedMessage());
} finally {
// do some
myMyBatisCursorItemReader.close();
}
} 2.3 原理简单介绍
- open函数
作用从session工厂获取一个session,然后调用session的selectCursor,它最终会调用
ConnectionImpl的prepareStatement方法:
public java.sql.PreparedStatement prepareStatement(String sql) throws SQLException {
return prepareStatement(sql, DEFAULT_RESULT_SET_TYPE, DEFAULT_RESULT_SET_CONCURRENCY);
}
private static final int DEFAULT_RESULT_SET_TYPE = ResultSet.TYPE_FORWARD_ONLY;
private static final int DEFAULT_RESULT_SET_CONCURRENCY = ResultSet.CONCUR_READ_ONLY;
至此三个条件满足了两个,在加上我们自己设置的fetchSize就通知mysql要创建流式ResultSet。
那么fectchsize何处设置那?
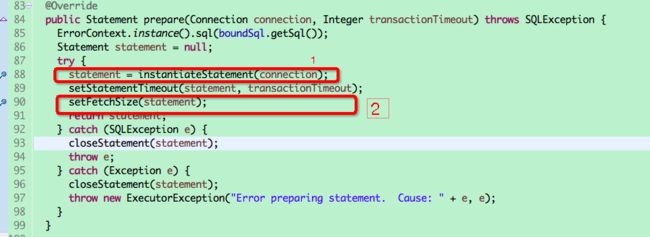
图中1创建prepareStatement,2设置fetchSize.
设置后最后会调用MysqlIO的sqlQueryDirect方法执行具体sql并把结果resultset存放到JDBC4PrepardStatement中。
- read函数
read函数作用是从结果集resultset中获取数据,首先调用.next判断是否有数据,有的话则读取数据。
这和纯粹JDBC编程方式就一样了,只是read函数对其进行了包装。
三、Mybatis中ResultHandler的使用
3.1 配置
- Mapper.xml设置
![]()
其中fetchSize=”-2147483648″,Integer.MIN_VALUE=-2147483648
3.2 使用
static void testCursor2() {
SqlSession session = sqlSessionFactory.openSession();
Map param = new HashMap();
AccsDeviceInfoDAOExample accsDeviceInfoDAOExample = new AccsDeviceInfoDAOExample();
accsDeviceInfoDAOExample.createCriteria().andAppKeyEqualTo("12345").andAppVersionEqualTo("1.2.3.4")
.andPackageNameEqualTo("com.hello.test");
param.put("oredCriteria", accsDeviceInfoDAOExample.getOredCriteria());
session.select("com.taobao.accs.mass.petadata.dal.sqlmap.AccsDeviceInfoDAOMapper.selectByExampleForPetaData",
param, new ResultHandler() {
@Override
public void handleResult(ResultContext resultContext) {
AccsDeviceInfoDAO accsDeviceInfoDAO = (AccsDeviceInfoDAO) resultContext.getResultObject();
System.out.println(resultContext.getResultCount());
System.out.println(JSON.toJSONString(accsDeviceInfoDAO));
}
});
} 3.3 原理简单介绍
类似第三节,只是第三节返回了操作ResultSet的游标让用户自己迭代获取数据,而现在是内部直接操作ResultSet逐条获取数据并调用回调handler的handleResult方法进行处理。
private void handleRowValuesForSimpleResultMap(ResultSetWrapper rsw, ResultMap resultMap, ResultHandler resultHandler, RowBounds rowBounds, ResultMapping parentMapping)
throws SQLException {
DefaultResultContext四、总结与结果对比
流式编程使用裸露JDBC编程最简单,灵活,但是sql语句需要分散写到需要调用数据库操作的地方,不便于维护,Mybatis底层还是使用裸露JDBC编程API实现的,并且使用xml文件统一管理sql语句,虽然解析执行时候会有点开销(比如每次调用都是反射进行的),但是同时还提供了缓存。
对于同等条件下搜索结果为600万条记录的时候使用游标与不使用时候内存占用对比:
- 非流式

流式

可知非流式时候内存会随着搜出来的记录增长而近乎直线增长,流式时候则比较平稳,另外非流式由于需要mysql服务器准备全部数据,所以调用后不会马上返回,需要根据数据量大小不同会等待一段时候才会返回,这时候调用方线程会阻塞,流式则因为每次返回一条记录,所以返回速度会很快。
这里在总结下:client发送select请求给Server后,Server根据条件筛选符合条件的记录,然后就会把记录发送到自己的发送buffer,等buffer满了就flush缓存(这里要注意的是如果client的接受缓存满了,那么Server的发送就会阻塞主,直到client的接受缓存空闲。),通过网络发送到client的接受缓存,当不用游标时候MySqIo就会从接受缓存里面逐个读取记录到resultset。就这样client 从自己的接受缓存读取数据到resultset,同时Server端不断通过网络向client接受缓存发送数据,直到所有记录都放到了resultset。
如果使用了游标,则用户调用resultset的next的频率决定了Server发送时候的阻塞情况,如果用户调用next快,那么client的接受缓存就会有空闲,那么Server就会把数据发送过来,如果用户调用的慢,那么由于接受缓存腾不出来,Server的发送就会阻塞