一个语法分析器的实现
语法分析设计文档
LR分析法分LR(0),SLR(1),LALR,LR(1)好几种,具体是SLR(1)分析法,对于LR分析法来说,语法分析过程都由一个称为“总控程序”来完成的
总控程序是LR分析法的核心处理模块,而LR分析表又是总控程序的核心部分,所以整个LR分析法的核心部分就是求出LR分析表,下面就首先说明LR分析表的构造
给定文法(注意这里的标号表示的是第几条归约式,后面会用到!):
1. E -> E+T
2. E -> E-T
3. E -> T
4. T -> T*F
5. T -> T/F
6. T -> F
7. F -> (E)
8. F -> i文法的项目集:
E’ -> E (注意这个E’,其实目的就是说推导从这里开始)
E -> E+T
E -> E-T
E -> T
T -> T*F
T -> T/F
T -> F
F -> (E)
F -> i项目集规范族(这个跟书本上的是一样的,最好是自己先推一下):
I0:
E’ -> .E I1(下一步接收E)
E -> .E+T I1
E -> .E-T I1
E -> .T I2(下一步接收T)
T -> .T*F I2
T -> .T/F I2
T -> .F I3(下一步接收F)
F -> .(E) I4(下一步接收左括号)
F -> .i I5(下一步接收i)
I1:
E’ -> E.
E -> E.+T I6(下一步接收+)
E -> E.-T I7(下一步接收-)
I2:
E -> T.
T -> T.*F I8(下一步接收*)
T -> T./F I9(下一步接收/)
I3:
T -> F.
I4:
F -> (.E) I10(下一步接收E)
E -> .E+T I10
E -> .E-T I10
E -> .T I2(这个状态以前出现过)
T -> .T*F I2
T -> .T/F I2
T -> .F I3
F -> .(E) I4
F -> .i I5
I5:
F -> i.
I6:
E -> E+.T I11(下一步接收T)
T -> .T*F I11
T -> .T/F I11
T -> .F I3
F -> .(E) I3
F -> .i I5
I7:
E -> E-.T I12(下一步接收T)
T -> .T*F I12
T -> .T/F I12
T -> .F I3
F -> .(E) I4
F -> .i I5
I8:
T -> T*.F I13(下一步接收F)
F -> .(E) I4
F -> .i I5
I9:
T -> T/.F I14(下一步接收F)
F -> .(E) I4
F -> .i I5
I10:
F -> (E.) I15(下一步接收右括号)
E -> E.+T I6
E -> E.-T I7
I11:
E -> E+T.
T -> T.*F I8
T -> T./F I9
I12:
E -> E-T.
T -> T.*F I8
T -> T./F I9
I13:
T -> T*F .
I14:
T -> T/F .
I15:
F -> (E) .
这个推导过程应该没问题吧?如果有问题,仔细再检查一下!好,这个推导过程其实对于LR(0),SLR(1),LALR,LR(1)都是必经的一步,而且都是一样的,真正不一样的地方就体现在最终的分析表上
问题:这个文法是LR(0)文法吗?如果不是,那么它是SLR(1)文法吗?(请务必先自己认真思考一下,再看解答,因为这个问题很关键!)
解答:
从上述的项目集规范族观察I2,I11,I12:
I2:
E -> T.
T -> T.*F I8(下一步接收*)
T -> T./F I9(下一步接收/)
I11:
E -> E+T.
T -> T.*F I8
T -> T./F I9
I12:
E -> E-T.
T -> T.*F I8
T -> T./F I9注意到没有?对于I2,从I2状态出发,接收了T后,可以到达I8和I9状态,那么到底应该前往哪一个状态呢?
于是这个文法不是LR(0)文法!(I11和I12的分析同理)
要证明是不是SLR(1)文法,先求Follow集
Follow(E) = {+,-,),#}(# 是终结符)
因为E -> E+T
所以Follow(E)是Follow(T)的子集(就是E有的T里也要有)
Follow(T) = {+,-,),*,/,#}(# 是终结符)
因为T -> T*F
所以Follow(T)是Follow(F)的子集
Follow(F) = {+,-,),*,/,#}(# 是终结符)
好了,现在可以构造SLR(1)分析表了,先给出这个表

回顾项目集规范族,一步步填表:
1. 从I0出发,接收E到达I1,于是在状态栏0列,GOTO表E列填入1;接收T到达I2,同理填入2;接收F到达I3,同理填入3;接收左括号到达I4,在ACTION表(列填入S4;接收i到达I5,在ACTION表i列填入S5
2. 从I1出发,因为这里第一条“E’-> E.”意味着文法被接受(Accept),所以(1,#)填入ACC,表示到达此状态文法被接受,对应的(1,+)填入S6,(1,-)填入S7
3. 从I2出发,因为这个状态会导致冲突,因此要使用SLR(1)分析法消除冲突
对于“E -> T.”,还记得Follow(E)吧,现在就在(2,#)和(2,Follow(E))的所有元素,即(2,+),(2,-),(2,))上填入R3(R3表示将其归约为第三条归约式,还记得前面的标号吧)
对于:
T -> T.*F I8(下一步接收*)
T -> T./F I9(下一步接收/)
直接在(2,*)上填入S8,(2,/)上填入S9
我想到这里,你应该自己推出整个表了吧!不信?自己推一次!上述有错漏之处,望指正!
既然有了分析表,现在就要使用总控程序对输入串进行语法分析了,分析表中有Si和rj大家都知道的。S是shift的缩写,也就是移进,R是reduce的缩写,也就是规约。规约是推导的逆操作。
先来看看在进行分析的时候S和R操作的规则
Si:移进,把i移入到状态栈,把a移入到符号栈。其中i,j表示状态号。
Ri:归约,用第i个产生式归约,同时状态栈与符号栈退出相应个符号,并把GOTO表相应状态和第i个产生式的左部非终结符入栈。
分析输入串“((i+i))”进行语法分析(我手写的分析过程和LemonParser的一样,直接上图吧)
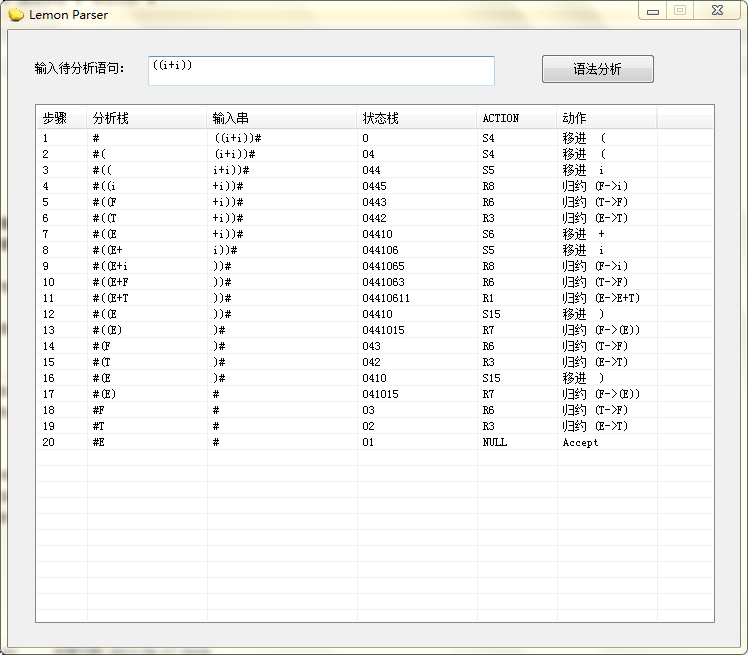

第一步,符号栈中是#,输入符号串就是给定的要分析的串,状态栈因为从0开始,所以状态栈直接填0,应该知道,LR分析是从左到右扫描的。所以心里想着一根指针p,p首先指向输入串的‘(’,然后我们查ACTION表的(0,‘(’),0就是状态0,‘(’就是指针的当前字符。分析表中的(0,‘(’)是S4,填入第一步的ACTION,并且动作列填入移进,根据规则,将4入状态栈,‘(’入符号栈
进入第二步,指针p肯定要前进一步了,所以输入符号串就进入b了,此步同上一步,不多解释
关键是进入第四步后,此时,符号栈中为#((i,输入符号串是+i))#,状态栈是0445,此时去查ACTION表,查得(5,+),5是状态栈顶,+是p指针的当前位置。发现是R8,根据规则,用第8条产生式F -> i来规约。把动作栏GOTO先填了,同时状态栈与符号栈退出相应个符号,也即是说,把状态栏的栈顶5退出来,同时符号栈的i也退出,心里想着,不填表,并把GOTO表相应状态和第8个产生式的左部非终结符F入栈。GOTO表需要查的是(4,F)=3,8是R8的8,F是第8个产生式的左部。所以,就把3入状态栈,F入符号栈
后面的都是一样的,不解释了,想明白这个过程,多动手是必需的,你也手工试试吧
SLR(1)的语法分析器:

