Hive分区
hive对表进行分区,如按照日期,城市等方式区分,可以起到提升查询速度的作用。
创建一个新的employee表,存储如下数据:
id, name, dept
1 lllis tp
2 sssll hr
3 jslsj sc
4 lslsl sc 然后我们按照年份来对数据进行分区存储。
1、添加分区基本语法:
ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION partition_spec [LOCATION 'location1'] partition_spec [LOCATION 'location2'] …
partition_spec:
: (p_column = p_col_value, p_column = p_col_value, ...)以下语句是将employee表按照年份分区的命令:
ALTER TABLE employee ADD PARTITION (year='2013') location '/2013/part2013';执行这个语句的时候直接报了如下的错:
Error: Error while compiling statement: FAILED: ValidationFailureSemanticException table is not partitioned but partition spec exists: {year=2013} (state=42000,code=40000)大意是表不是一个分区表,无法创建分区。搜索之后了解到需要在创建表时就创建分区。
删除employee表,重新创建,创建语句如下:
CREATE EXTERNAL TABLE IF NOT EXISTS userdb.employee(eid int,name String,dept String)
PARTITIONED BY (year_p int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE;数据格式:
1 lllis tp
2 sssll hr
3 jslsj sc
4 lslsl sc导入数据语句:
LOAD DATA LOCAL INPATH '/home/hadoop/HivePy/employee.txtn' OVERWRITE INTO TABLE userdb.employee PARTITION(year_p=2017);导入之后的结果为:
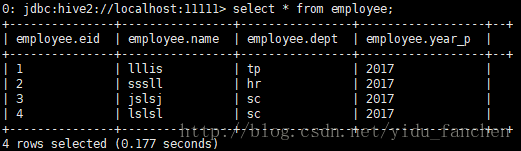
经验证,不能直接给一个表添加分区,可能是我没用对方法。。。
2、重命名分区:
ALTER TABLE table_name PARTITION partition_spec RENAME TO PARTITION partition_spec;修改employee表分区
ALTER TABLE employee PARTITION (year_p='2017')
RENAME TO PARTITION (year_p='2016');执行命令之后查看表数据,如图所示:

3、删除分区:
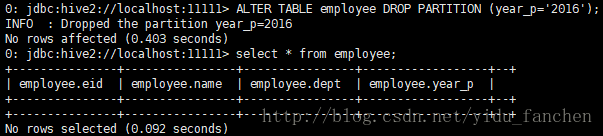
ALTER TABLE table_name DROP [IF EXISTS] PARTITION partition_spc,…删除employee表分区
ALTER TABLE employee DROP PARTITION (year_p='2016');执行语句之后会删除此分区的所有数据,如图所示: