MapReduce再学习:资源管理框架YARN
在前面写到的三篇博客中,HDFS概述 和 MapReduce简介写的都是hadoop1.0的情况,针对1.0版本的各种不足,2.0都有相应的改动, HDFS再学习:HA和Federation机制写的是存储系统HDFS上的改动。针对我们的计算模型MapReduce,2.0版本设计了新的资源管理框架YARN。
| 组件 | Hadoop1.0的问题 | Hadoop2.0的改进 |
|---|---|---|
| HDFS | 单一节点问题 | Hdfs HA提供热备机制 |
| HDFS | 单一命名空间 | Hdfs Federation管理多命名空间 |
| MapReduce | 资源管理效率低 | 新的资源管理框架YARN |
MapReduce1.0的缺陷
回顾一下MapReduce1.0的结构,,详细的可以去看上一篇博客:

存在问题:
1、JobTracker“大包大揽”,导致任务过重且单结点限制了规模。
2、容易出现内存溢出问题。因为分配资源时考虑的是MapReduce的任务数,不考虑CPU,内存等问题。
3、资源划分不合理。如上一篇博客里面介绍道,MR1.0里面的资源单位为槽slot,强制分为MapSlot和ReduceSlot,即使没有map任务,但是reduce任务槽数不够用,reduce任务也没法使用map任务的槽。
YARN的设计思路
YARN是一个分布式资源管理系统,用于提高分布式的集群环境下资源的利用率,这些资源包括内存,I/O,网络,磁盘等。其产生的原因是为了解决MapReduce框架的不足。

我们从MapReduce1.0的结构图可以看到,1.0版本既是一个计算框架,也是一个资源调度框架。资源调度方面的jobTracker不仅负责了资源的管理还负责任务的调度和任务的监控。2.0版本把资源调度的任务分离出来,形成了YARN,也就是说,YARN是一个纯粹的资源管理调度框架,而2.0版本的mapReduce就只是一个纯粹的计算框架了,不再自己负责资源管理服务。
2.0版本中把jobTracker的资源管理交给了全局的资源管理器ResourceManager,任务方面的调度和监控交给了应用相关的ApplicationMaster,用节点NodeManage来替代TaskTracker。
ResourceManager
RM是一个全局的资源管理器,负责整个系统的资源管理与分配,主要包括两个组件:调度器Scheduler和应用程序管理器Applications Manager。
调度器接收来自ApplicationMaster的应用程序资源请求,把集群中的资源以“容器”的形式分配给提出申请的应用程序,容器的选择通常考虑应用程序所要处理的数据的位置,就近选择,实现“计算向数据靠拢”。
Container容器
动态资源分配的单位,每个容器中都封装一定数量的CPU、内存、磁盘等资源,从而限制每个应用程序可以使用的资源量。
scheduler调度器
是一个可插拔的组件,YARN不仅自身提供了很多可以直接用的调度器,也允许用户自定义。
Applications Manager应用程序管理器
负责系统中所有应用程序的管理工作,主要包括应用程序提交,与调度器协商资源以启动、监控、重启ApplicationMaster。
ApplicationMaster
ResourceManager接收用户提交的作业(记住,hadoop中处理的用户程序都是以作业的形式来处理的,只是我们计算的时候把作业变成了一个个的map/reduce任务),按照作业的上下文信息及从NodeManager收集来的容器状态信息,启动调度过程,在NodeManager中启动一个容器为ApplicationMaster(applicationMaster的运行也占用资源,它是由resourceManager在nodeManager中启动的一个container)。
其作用是:
为应用程序申请资源,并分配给内部任务。
负责这个任务的调度、监控与容错(任务失败时重申资源,重启任务)。
NodeManager
单个节点上的资源管理,每个节点上就有一个。
监控节点上容器的资源使用情况。
跟踪节点健康状况。
以“心跳”方式与ResourceManager保持通信。
接收来自ResourceManager和ApplicationMaster的各种请求。
YARN的工作流程
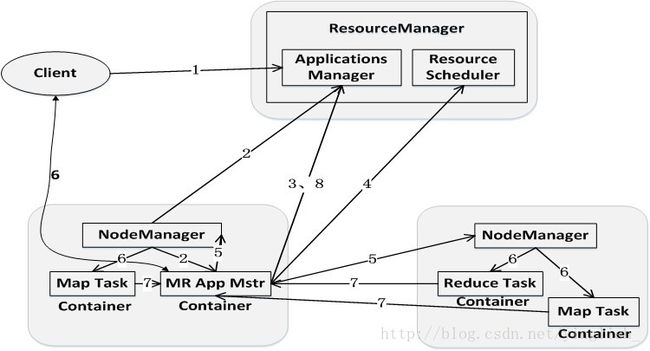
1、用户提交程序,包括ApplicationMaster程序,启动AM的命令和用户程序。
2、YARN中的ResourceManager负责接收和处理来自客户端的程序,选择NodeManager中的一个容器,启动ApplicationMaster。
3、ApplicationMaster创建后会先向 ResourceManager注册。
4、ApplicationMaster轮询向ResourceManager申请资源。
5、ResourceManager以容器的方式向提出申请的AM分配资源。
6、在容器中启动任务。
7、各个任务向Am报告状态与进度。
8、应用程序结束后,AM向RM注销并关闭自己。
YARN体系结构
集群部署上,YARN的各个组件是与Hadoop集群中的其他组件统一部署的。
ResourceManager和NameNode一起,是主节点。
ApplicationMaster可以和数据节点一起,由NodeManager管理。
container和数据节点一起,(方便计算),由NodeManager管理。

从MapReduce1.0框架发展到YARN框架,客户端并没有发生变化,其大部分调用API及接口都保持兼容,因此,原来针对Hadoop1.0开发的代码不用做大的改动,就可以直接放到Hadoop2.0平台上运行
Yarn与MapReduce1.0框架的对比分析
总体而言,YARN相对于MapReduce1.0来说具有以下优势
1、大大减少了承担中心服务功能的ResourceManager的资源消耗
ApplicationMaster来完成需要大量资源消耗的任务调度和监控
多个作业对应多个ApplicationMaster,实现了监控分布化
2、MapReduce1.0既是一个计算框架,又是一个资源管理调度框架,但是,只能支持MapReduce编程模型。而YARN则是一个纯粹的资源调度管理框架,在它上面可以运行包括MapReduce在内的不同类型的计算框架,比如storm实现流计算,spark实现内存计算等等,只要编程实现相应的ApplicationMaster
3、YARN中的资源管理比MapReduce1.0更加高效
以容器为单位,而不是以slot为单位
YARN的目标是实现“一个集群多个框架”,即在一个集群上部署一个统一的资源调度框架YARN,在此上可以部署其它各种计算框架。由YARN为这些计算框架提供统一的资源调度管理服务,并且能根据各种计算框架的负载需求,调整各自占用的资源,实现集群资源共享与资源弹性收缩。
这样,不同的计算框架可以共享底层的存储,避免了数据集跨集群的移动。