
上一篇文章《Python | 数据分析实战Ⅰ》中,实现了对数据的简单爬取,在文末也遗留了了一些问题。
- 拉钩网对于同一ip的大量请求行为肯定会进行封禁,所以需要准备代理池。
- 为了实现高自动化,需要对一系列可能出现的异常情况进行处理,断点处理,确保程序不挂。
- 为了提高效率,加入多线程。
- 数据持久化,在持久化之前需要先进行清洗。
在这篇文章中,我们主要对以上几个问题进行思考,并采取一些解决方式。
这篇文章主要包括:
- 构建一个简易的代理池
- 记录异常日志
- 多线程
- 数据持久化
简易代理池
假如在对一个网站进行大量访问爬取时,略有反爬措施的网站一定会检测到你这个异常IP并进行封禁。如果你还没遇到这类情况,要么就是你爬取的数据量还太少,网站完全不care;要么是网站的基本安全措施不完善。
我在写这篇文章时,还没较大规模地爬取过一个网站,所以构建简易代理池暂时没有考虑效率方面的问题,主要是用来练手,学习之用。
现在的普遍情况是:免费,不稳定;稳定。不免费。所以大部分商业级爬虫开发者都是会付费购买有人专门维护的代理池,我们这种玩玩的,图个意思就好。不过我也希望,能有大佬发起一个开源项目,让有时间的同学能一起维护使用一个代理池。
我的思路很简单,首先爬取一些提供免费代理的网站,然后对这些代理进行测试筛选,将可用的一部分保存在本地,在需要的时候进行调用。
首先构建一个IpProxy类,在这个类中有三个主要方法,__init__(self)初始化方法,get_ip(self)用来抓取某网站的免费代理,validate_proxy(self,pool)对免费代理进行验证,然后暂存在文件中(我是觉得没有必要在本地持久化,因为这些代理存活率低,往往不久就会失效,所以在跑主爬虫前,有必要即时跑一下这个代理爬虫,获取最新的可用代理)。
思路很简单,也没什么技术含量,下面是主要代码实现部分。
class IpProxy():
def __init__(self):
self.ip_pool=[]
self.ip_pool_after_validate=[]
self.url="http://www.xicidaili.com/nn/"
self.headers={
"Host":"www.xicidaili.com",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36",
"Upgrade-Insecure-Requests":"1"
}
logging.basicConfig(filename=os.path.join(os.getcwd(), 'validateProxy.txt'), level=logging.INFO)
logging.basicConfig(filename=os.path.join(os.getcwd(), 'log_proxy.txt'), level=logging.ERROR)
def get_ip(self):
#暂时只爬取一页尝试
try:
result = requests.get(self.url, headers=self.headers)
except:
logging.error("获取免费代理失败")
raise
result.encoding="utf-8"
content=result.content
bs=BeautifulSoup(content,"html.parser")
trs=bs.find_all("tr")
for tr in trs[1:]:
try:
ip={}
tds=tr.find_all("td")
ip["address"] = tds[1].text
ip["port"] = tds[2].text
ip["type"] = tds[5].text.lower()
self.ip_pool.append(ip)
# print(ip)
# print(self.ip_pool)
except:
logging.error("将tag为:"+tds+"构造为数据字典失败")
pass
return self.ip_pool
def validate_proxy(self,pool):
proxies={
"http":"",
"https":""
}
for item in pool:
ip=item["type"]+"://"+item["address"]+":"+item["port"]
if item["type"]=="http":
proxies["https"]=""
proxies["http"]=ip
try:
res = requests.get("http://www.baidu.com", proxies=proxies)
if res == None:
continue
else:
print(ip+"可用")
logging.info(ip)
self.ip_pool_after_validate.append(ip)
except:
print(ip+"不是可用的代理")
pass
else:
proxies["http"]=""
proxies["https"]=ip
try:
res = requests.get("http://www.baidu.com", proxies=proxies)
if res == None:
continue
else:
print(ip + "可用")
logging.info(ip)
self.ip_pool_after_validate.append(ip)
except:
print(ip+"不是可用的代理")
pass
return self.ip_pool_after_validate
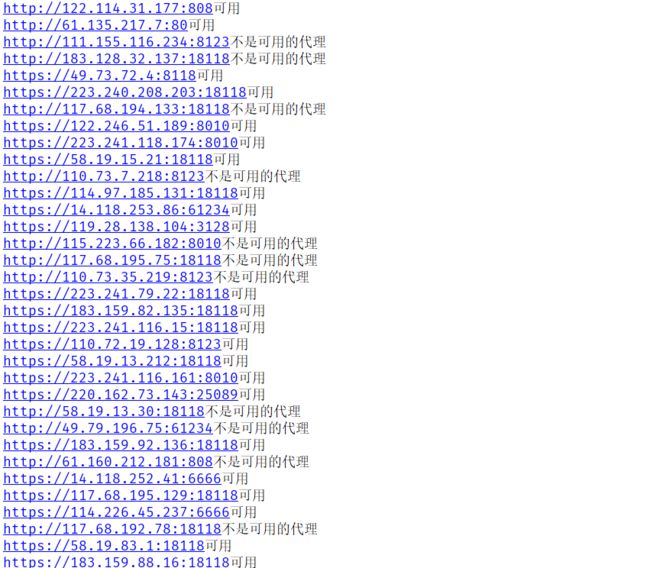
输出到文件中:
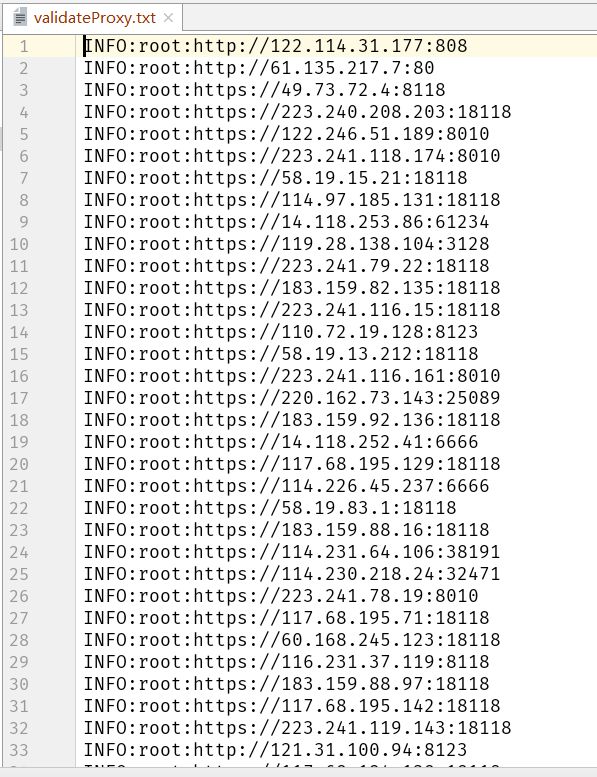
可以看到是能正常工作的,速度对我来说其实还可以,可以接受。如果想优化一下的话,这里有一个解决点:在代码中可以看到我是用代理ip去访问了一下百度看能不能返回状态200,能科学上网的时候,百度都是被用来测试网络是否连通的(笑,这是一种效率比较低的做法,同学可以去试试使用telnetlib模块。
异常日志
代码出现异常,那是再正常不过的事儿了。让我们看看代码中哪些地方比较容易出现异常。
代理爬虫中:
- 请求页面返回数据时
- 构造ip数据时
- 使用某不可用代理访问百度时
主爬虫中:
- 请求页面时
- 解析数据接口时
- 某一页数据未正常获取时
持久化时:
- 数据库连接时
- 数据插入失败时
使用os+logging模块来将信息打印到日志文件中。具体请看代码,这这里就具体演示了。
多线程
使用多线程来同时运行几只不同的主爬虫,比如同时Java和Python的岗位信息,或者做一些其他的操作。
为了面向对象,首先我们构建一个CrawThread类。其中主要的两个方法是run准备运行的函数,get_result获取返回值。
代码如下:
class CrawThread(threading.Thread):
def __init__(self,url,java_job):
threading.Thread.__init__(self)
self.url=url
self.job=java_job
self.all_page_info=[]
def run(self):
print("新线程开始")
for x in range(2, 4):
data = {
"first": "false",
"pn": x,
"kd": "Java"
}
try:
current_page_info = self.job.getJob(self.url, data)
print(current_page_info)
self.all_page_info.append(current_page_info)
print("第%d页已经爬取成功" % x)
time.sleep(5)
except:
print("第%d页爬取失败,已记录" % x)
logging.error("第%d页爬取失败,已记录" % x)
pass
def getResult(self):
return self.all_page_info
主函数中调取:
if __name__ == '__main__':
java_url="https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E4%B8%8A%E6%B5%B7&needAddtionalResult=false&isSchoolJob=0"
java_job = Job()
java_all_page_info=[]
python_url="https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E4%B8%8A%E6%B5%B7&needAddtionalResult=false"
python_job=Job()
python_all_page_info=[]
java_t=CrawThread(java_url,java_job)
java_t.start()
java_t.join()
java_all_page_info =java_t.getResult()
# print(java_all_page_info)
# print(type(java_all_page_info))
addPosition(java_all_page_info)
# python_t=CrawThread(python_url,python_job)
# python_all_page_info=python_t.start()
持久化
为了便于后面的数据分析,所爬取的数据肯定是需要持久化到数据库的。我使用的是MySQL,这里可以使用pymysql模块。
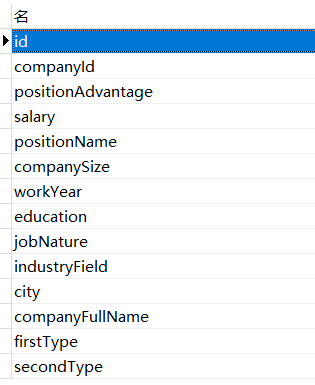
我这里选取了这几项数据进行采集。
接下来的操作也没什么需要着重强调的,但是在实际操作中,我发现了一个坑:
我一开始将我的职位表名命名为:position,结果在执行sql语句时一直出错。一条简单的插入语句,找来找去没发现错误,后来想到可能position是MySQL的保留字?便将表名更改,遂执行通过。
db_username="root"
db_password="root"
logging.basicConfig(filename=os.path.join(os.getcwd(), 'log_db.txt'), level=logging.ERROR)
def addPosition(positions):
db = pymysql.Connect(
host="127.0.0.1",
port=3306,
user=db_username,
passwd=db_password,
db='lagou_position',
charset='utf8'
)
try:
cursor = db.cursor()
except:
print("连接数据库失败")
logging.error("连接数据库失败")
print(len(positions))
for x in range(0,len(positions)):
for position in positions[x]:
print(position)
temp = []
temp.append(position["companyId"])
temp.append(position["positionAdvantage"])
temp.append(position["salary"])
temp.append(position["positionName"])
temp.append(position["companySize"])
temp.append(position["workYear"])
temp.append(position["education"])
temp.append(position["jobNature"])
temp.append(position["industryField"])
temp.append(position["city"])
temp.append(position["companyFullName"])
temp.append(position["firstType"])
temp.append(position["secondType"])
try:
sql = "INSERT INTO java_position(companyId,positionAdvantage,salary,positionName,companySize,workYear,education,jobNature,industryField,city,companyFullName,firstType,secondType) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
cursor.execute(sql,temp)
db.commit()
except:
print("插入数据出现错误:")
logging.error("插入数据出现错误")
db.rollback()
pass
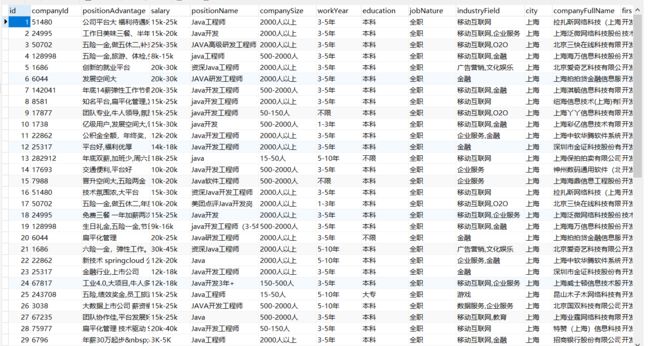
此时测试爬取几张页面,发现数据已经被采集到数据库中了。

一个点赞,一次转发,都是对原创者的支持。