Memcached学习笔记
什么是Memcached
Memcached是开源的高性能分布式内存缓存服务器,支持分布式横向扩展,用于减少数据库负载,提升性能。包括服务端和客户端。
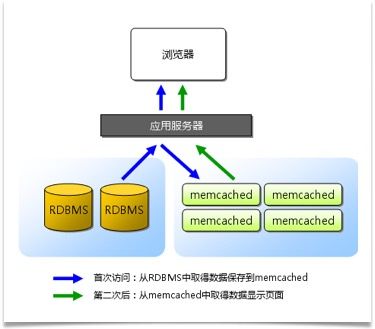
服务端本质是一个key-value的存储结构,通过在内存中维护一个大的HashMap,用来存储小数据块,对外提供统一的接口来操作。
客户端是一个类库,负责与服务端进行通信,针对不同的语言的不同实现封装成API来实现不同平台的集成。
应用程序则是通过客户端类库来使用Memcached进行数据对象缓存。
开发团队主页:http://danga.com/
项目主页: http://memcached.org/
Memchached安装
这里的安装是指安装Memcached服务端,目前最新的版本是memcached-1.4.17。
Memcached下载地址:http://memcached.org/downloads
注:安装Memcached必须首先安装libevent,Memcached基于此库处理异步事件。当然如里你的系统已经安装了libevent,这里可以不用安装。目前libevent最新版本是libevent-2.0.22。
libevent下载地址:http://libevent.org/
下载安装文件后,接下来安装:
第一步:安装libevent。假设libevent安装文件保存在/Downloads下。
$ cd Downloads/
$ tar -zxf libevent-2.0.22-stable.tar.gz
$ cd libevent-2.0.22-stable
//配置编译路径
$ sudo ./configure --prefix=/usr/local/libevent-2.0.22
$ sudo make
$ sudo make install第二步:安装Memcached。假设Memcached安装文件保存在/Downloads下。
$ cd Downloads/
$ tar -zxf memcached-1.4.25.tar.gz
$ cd memcached-1.4.25
//配置编译路径并指定libevent
$ sudo ./configure --prefix=/usr/local/memcached-1.4.25 ---with-libevent=/usr/local/libevent-2.0.22
$ sudo make
$ sudo make install
另:当然还有更加快捷有效的安装方式,就是使用包管理工具命令安装。例如在mac上也可以使用brew命令安装,ubuntu上可以使用apt-get命令安装等。
//mac上安装
#该命令会自动下载memcached依赖libevent和openssl
$ brew install memcached
//ubuntu上安装
#该命令会自动下载memcached依赖libevent和openssl
$ apt-get install memcached
到此,Memcached的安装工作已经完成,接下来我们就启动Memcached。
#启动参数后面会有详细说明
$ sudo ./memcached -p 11211 -m 64 -u root -vv
#结束memcached进程
$ sudo kill -9 memcached进程ID
常用功能参数
-p 指定服务TCP端口,默认为11211,默认会监听tcp和udp端口。
-m 分配给memcached用作缓存的内存大小,单位为MB。
-u 是运行Memcache的用户,如果当前为 root 的话,需要使用此参数指定用户。
-l 监听的 IP 地址,本机可以不设置此参数。
-f chunk size的增长因子(合理范围1.05~2,默认:1.25)。
-t Memcached启动的工作线程数,默认为4,建议不要超过系统 CPU的个数。
-I 改变slab page的容量大小,以调整ITEM容量的最大值,默认为1MB。
-vv 输出详细的信息。
-d 启动一个守护进程
-h 打印版本和帮助信息,然后退出。
Memcached命令列表
存储命令set/add/replace/append/prepend/cas
读取命令get/gets
删除命令delete
计数命令incr/decr
统计命令stats/settings/items/sizes/slabs
存储命令
命令格式:
[]
| 参数 | 说明 |
|---|---|
| command | set无论如何都进行存储,add只有数据不存在时进行添加 |
| key | 字符串,<250个字符,不包含空格和控制字符> |
| flags | 是一个16位的无符号的整数(以十进制的方式表示)。该标志将和需要存储的数据一起存储,并在客户端get数据时返回 |
| exptime | 存活时间s,0为永远,<30天60*60*24*30为秒数,>30天为unixtime |
| bytes | byte字节数,不包含\r\n,根据长度截取存/取的字符串,可以是0,即存空串 |
| datablock | 文本行,以\r\n结尾,当然可以包含\r或\n |
| status | STORED/NOT_STORED/EXISTS/NOT_FOUND/ERROR/CLIENT_ERROR/SERVER_ERROR服务端会关闭连接以修复 |
存储命令简单举例:
#1.保存数据长度必须正确
set key 32 0 5
zhang
STORED//正确
get key
VALUE key 32 5
zhang
END
set key1 32 0 5
zhan
CLIENT_ERROR bad data chunk
ERROR//长度错误
#2.add只能添加不存在的Key
set key1 32 0 5
zhang
STORED
add key1 32 0 5
wang
NOT_STORED
//已存在不能add
get key1
VALUE key1 32 5
zhang
END
add key2 32 0 5
wang
STORED
//不存在可以add
#3.replace只能替换存在的key
set key1 32 0 5
zhang
STORED
replace key1 32 0 5
wang
STORED
//已存在可以replace
get key1
VALUE key1 32 5
wang
END
replace key3 32 0 5
zhang
NOT_STORED
//不存在不能replace读取命令
命令格式:
<command> <key>*\r\n
VALUE <key1> <flags> <bytes> [<version>]\r\n
<datablock>\r\n
…
VALUE <keyn> <flags> <bytes> [<version>]\r\n
<datablock>\r\n
END\r\n
command: get普通查询,gets用于查询带版本的值
读取命令简单举例:
gets key1
VALUE key1 32 5 12
wang
END
//取得版本号
replace key1 32 0 5
zhang
STORED
//增加版本号
get key1
VALUE liu 32 5
zhang
END
gets key1
VALUE liu 32 5 13
zhang
END
检查存储命令
cas即check and set,只有版本号相匹配时才能存储,否则返回EXISTS。
设计意图:解决多客户端并发修改同一条记录的问题,防止使用经过改变了的value/key对。
举例:
cas key1 32 0 5 12
cplus
EXISTS
gets key1
VALUE key1 32 5 13
java
END//版本号不同不修改
cas key1 32 0 5 13
cplus
STORED
gets key1
VALUE key1 32 5 14
cplus
END//版本号相同才修改#Memcached的内存模型删除命令
命令格式:
delete <key> [<time>]
DELETE\r\n
time: 秒数或Unixtime,在time时间内不能add或replace,但能set,不能get。过期后才能够重新set有效并能get
举例:
delete key1
DELETED
get key1
END其他命令
stats settings 查看设置
stats slabs 输出slab中更详细的信息
stats items 输出各个slab中的item信息
stats sizes STAT 输出所有item的大小和个数
version 显示版本信息
flush_all 让缓存的所有数据失效
quit 退出命令行
Slab内存管理机制
提前分配1M内存,再利用对象填充Chunk
避免大量的重复初始化和清理,减轻内存管理器负担
减少系统碎片
几个重要名词解释
Slab:类似Page,是一块内存空间,是申请内存的最小单位,默认大小是1M。Memcached将Slab分割成多个大小相同的Chunk。
Chunk:数据区块,固定大小。保存一个Item及一对key/value.
Item:我们保存的数据,封装成Item。
Slabclass:不同各类的Slab分割成Tunk的大小也不相同。每个Slabclass是一个结构体,维护着指向它的一堆Slab指针。
Slots:当前Slab中空闲的Item链,即可用的Item,每次分配内存时,只需从Slots链中取出一个使用即可。
内存分配过程
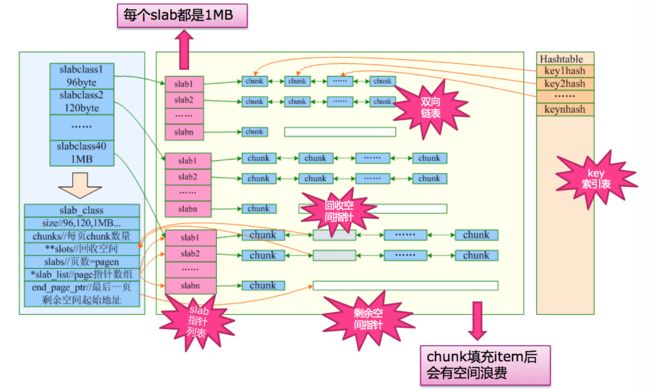
首先,初始化Slabclass数组,每个Slabclass元素都有不同size的Slab。
然后,申请一个新的Slab都会根据slabsize来分割Chunk,然后将Chunk空间初始化成一个个free Item,并插入到Slots链表中。
当使用Item时,直接从Slots链中删除,并加入到LRU队列中。
当使用过的Item被再次访问时,更新LRU队列,移动到链表的头部,老数据留在尾部,保证淘汰权重的正确性。
内部维护着一个Item线程不断检测LRU队列尾部的Item,若过期,淘汰之,并重新加入到Slots链表中。
当内存满时,需要强身淘汰一些项,采用LRU算法。每个Slabclass都保存着一个LRU队列,head和tail分别是队列的头尾,每次Item被访问到都会更新队列位置,更新到头部,而每次淘汰都是从尾部开始,也就是最近最少使用的项。
SET命令内存分配过程
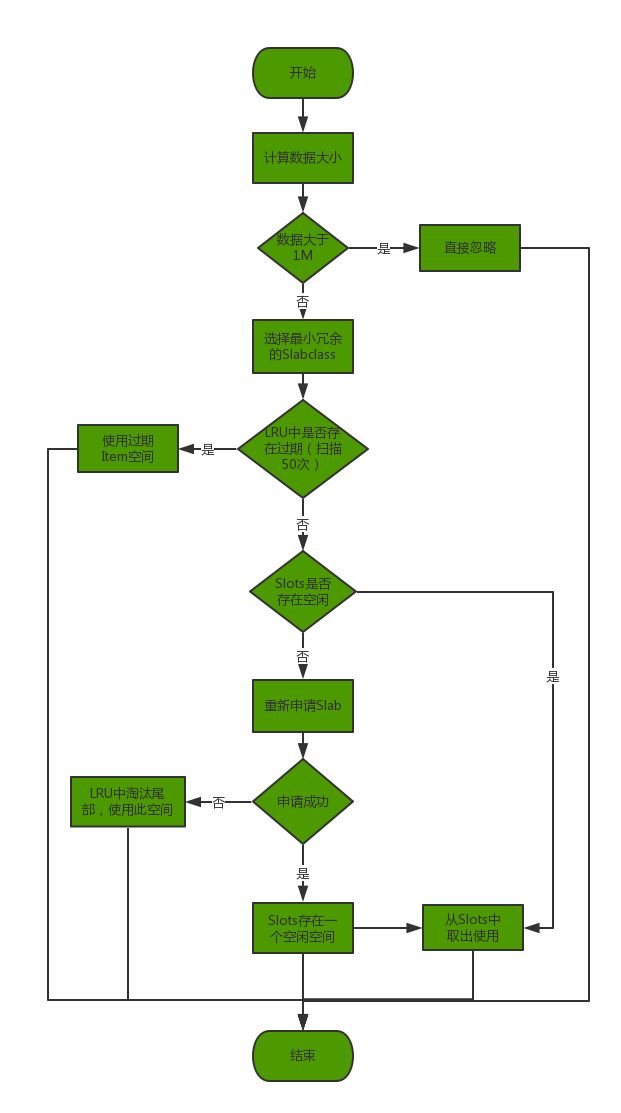
首先计算数据大小,大于1M,忽略掉,选择合适的Slabclass,然后从相应Slabclas的LRU队列中查看是否有过期的Item(50条),如果存在过期的Item,则利用这个过期的Item空间。如果不存在,则从Slots链中取出空闲的free Item。如果Slots链表中没有空闲的Item,则申请内存,重新开辟一片Slab空间,开辟成功后Slots链表中又有一个个freeItem,如果内存开辟失败,即内存已满,只能强制淘汰。从Slabclass中的LRU队列尾部的Item取出淘汰之,直接使用此Item。
Memcached优化考虑
优化的目标:提高内存利用率,减少内存浪费和提高命中率 。
调整配置参数
尽量使用小容量的数据内容或较短的key,节省内存和带宽。
增加Memcached提高服务获取的内存总量、提高命中率。
根据服务器的性能不同设置权重。
对需要使用Memcached服务的机器ip,服务端做访问限制。避免Memcached里的数据不会被别有心意的人再利用,或保证服务器的内存不被垃圾数据所堆积,造成命中降低。
优化Memcached客户端的代码。
Memcached特点与限制
内存存储,速度快,对内存的要求高,所缓存的内容非持久化,数据无法备份,重启无法恢复,无法查询。由于对CPU要求较低,通常将其和一些CPU高消耗内存低消耗的应用部署在一起。
采用分布式扩展的模式,可以将部署在一台机器上的多个Memcached服务端或者部署到多个机器上的Memcached服务端组成一个虚拟的服务端,对调用者屏蔽和透明,提高单机的内存利用率。
由于是集中式Cache,需要解决单点问题来保证其可靠性。
传输内容的大小和序列化问题,也是影响传输效率的因素。
当数据存入到Cache中后,采用LRU方式,将最久没被调用的对象从内存中清除,但存在空间浪费。
每取一个Cache内容,重新设置这个内容的过期时间,这样保证了经常被调用的内容可以一直长时间的留在缓存中,提高效率。