ElasticSearch核心基础之搜索
一 搜索方式
我们知道搜索有2种方式:一种是通过URL参数搜索,另一种是通过POST请求参数进行搜索
1.1 通过URL参数搜索
比如GET http://hadoop-all-01:9200/ecommerce/_search?参数列表
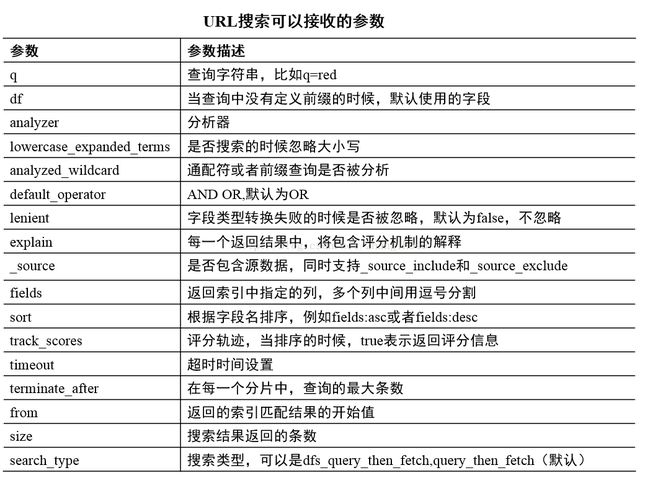
1.2 通过POST请求参数进行搜索
即DSL查询:
GET http://hadoop-all-01:9200/ecommerce/_search
{
"query":{
"term": {"tags": {"value":"Guitar"}}
}
}
二 重新平分
在ES中搜索单个词是比较快的,但是搜索短语,效率会比较低。所以ES提供了重新评分的方法来提高效率。
原理:当在整个索引中搜索短语消耗资源会比较多,但大多数的时候,人们只是关注最近发生的一部分文档,所以可以先在最近的一段文档中对短语进行重新评分,然后再查询,这个时候看起来效率会提升很多
处理排序之前,每一个分片上执行重新评分,通常情况下,当我们用重新评分API来重新评分的时候,这个过程只是执行一次,在未来的有可能会被调整。当查询中有排序或者search_type的设置为scan,count的时候将不执行重新评分。在用分页查询的时候每一页查询的window_size参数尽量不要修改,如果修改可能会引起排序的混乱,导致不可预知的结果。
查询重新评分只会在query和post_filter阶段返回的前K条结果上执行二次查询,在每一个分片分会的文档的数量由window_size控制,默认返回from到size之间的个数
默认情况下对每一个文档最终的得分_score是原始得分和重新评分后进行线性组合的结果。原始评分和重新评分的比例饿关系分布由query_weight和rescore_query_weight控制,默认都是1,比如重新评分查询如下:
三 搜索相关的函数
3.1 索引加权index_boost
当搜索一个以上的索引的时候,可以对每一个索引配置不同的索引加权级别。当有多个索引存储类似的文档的时候,索引加权特别有用,使得一个索引的命中级别高于另一个索引。
GET _search
{
"indices_bbost":{
"desc":1.4,
"tags":1.2
}
}
3.2 最小分值min_score
可以指定搜索时候的最小评分值,例如:
GET _search
{
"min_score":0.5,
"query":{"term":{"desc":"guitar"}}
}
3.3 分值解释explain
GET _search
{
"explain":true,
"query":{"term":{"desc":"guitar"}}
}
3.4 分片情况查询_search_shards
GET /ecommerce/_search_shards
3.5 总数查询_count
POST /ecommerce/_count
3.6 是否存在查询
当设置size为0的时候和terminate_after为1的时候可以验证查询是否有结果存在,例如:
GET _search
{
"size":0,
"terminate_after":1,
"query":{"term":{"desc":"guitar"}}
}
3.7 验证接口
验证一个查询接口是否正确,这样可以不用实际执行,提高效率,防止误操作
POST /ecommerce/_validate/query
{
"query":{
"term":{"tags":"guiatr"}
}
}
3.8 字段状态查询_field_stats
GET /ecommerce/_field_stats?fields=name,desc
四 搜索模板
对模板的使用有三种方式:
# 直接在请求体中使用脚本
# 把脚本存储在索引中,通过引用脚本id来使用
# 把脚本存储在本地磁盘中,默认的位置为:elasticsearch\config\scripts,通过引用脚本名称进行使用
4.1 直接在请求体中使用脚本
POST /ecommerce/_search
{
"query": {
"template":{
"inline":{
"match":{"desc":"{{query_string}}"}
},
"params":{"query_string":"guitar"}
}
}
}
上面这个查询也等价于:
POST /ecommerce/_search
{
"query": {"match": {"desc":"guitar"}}
}
或者
POST /ecommerce/music/_search/template
{
"inline":{
"query":{
"match":{
"{{field}}" : "{{value}}"
}
}
},
"params" : {
"field" : "desc",
"value" : "电子钢琴"
}
}
4.2把脚本存储在索引中,通过引用脚本id来使用
# 先把脚本存储在ES中,也叫预注册
POST /_search/template/templateTest
{
"template":{
"query":{"match": {"desc":"{{query_string}}"}}
}
}
# 再引用脚本id查询
POST /ecommerce/_search
{
"query":{
"template":{
"id":"templateTest",
"params":{"query_string":"guitar"}
}
}
}
4.3 转换成JSON参数
POST /ecommerce/music/_search/template
{
"inline": "{ \"query\": { \"terms\":{ \"desc\": {{#toJson}}values{{/toJson}} }}}",
"params" : {
"values":["电子","钢琴"]
}
}
POST /ecommerce/music/_search/template
{
"inline": "{\"query\": {\"match\":{{#toJson}}condition{{/toJson}}}}",
"params": {
"condition": {"desc": "钢琴"}
}
}
4.4 默认值
我们可以提供一个默认值,类似于以下这样:
{{var}}{{^var}}default{{/var}}
POST /ecommerce/music/_search/template
{
"inline":{
"query":{
"range":{
"review":{
"gte":"{{start}}",
"lte":"{{end}}{{^end}}100{{/end}}"
}
}
}
},
"params" : {
"start" : 1,
"end" : 100
}
}
如果我们提供end参数,则使用提供的,如果没有则使用默认的 end参数
五 DSL 查询
5.1 查询和过滤的区别
DSL查询包括2种子句:
第一:叶查询子句:在特定的字段上查找特定的值,比如match,term或者range查询
第二:复合查询子句:包含其他叶子查询和复合查询
查询:用于检查内容与条件是否匹配,并且计算_score元字段表示匹配度
过滤:不计算匹配得分,只是简单的决定文档是否匹配
查询的子句的也可以传递filter参数,比如bool查询内的filter,constant_score查询内的filter参数
查询匹配符合下列所有条件的文档
POST /ecommerce/_search
{
"query": {
"bool":{
"must":[
{"match":{"desc":"guitar"}},
{"match":{"tags":"Electric"}}
],
"filter":[
{"term":{"type":"Acoustic"}},
{"range":{"price":{"gte":"599.99"}}}
]
}
}
}
5.2 全文搜索
执行查询前,我们需要了解查询字段的分词方式,在查询字符串上应用每一个被查询字段的映射分词器(搜索分词器)
标准查询接受文本、数字、日期的查询,分析参数并组成查询条件。例如:
POST /ecommerce/_search
{
"query": {
"must":{"desc":"guitar"}
}
}
主要有三中类型的match查询:布尔查询、短语查询、和短语前缀查询
5.2.1bool 查询
# 返回的文档必须满足must子句,并且参与计算分值
# 返回的文档必须满足filter子句,不计算分值
# 返回的文档可能满足should子句的条件。如果一个没有must和filter的有一个或者多个should子句,那么只要按满足一个就可以返回,minimum_should_match表示至少满足几个子句
# 返回的文档必须不满足must_not条件
比如我想查询 日期为2016-06-12,或者onSale为true的文档,且该文档不包含shape为round的文档
GET /ecommerce/glasses/_search
{
"query":{
"constant_score": {
"filter": {
"bool":{
"should":[
{"term":{"record.postDate":"2016-06-12"}},
{"term":{"record.onSale":true}}
],
"must_not":{
"term":{"record.shape":"round"}
}
}
}
}
}
}
5.2.2 短语查询:短语查询分析文本并且创建短语查询,例如:
POST /ecommerce/_search
{
"query": {
"match_phrase":{"desc":"Series Kingman"}
}
}
5.2.3 短语前缀查询:
POST /ecommerce/_search
{
"query":{
"match_phrase_prefix":{
"desc":{"query":"Series Kingman"}
}
}
}
5.2.4如何控制全文检索的精准度?
首先,我们知道进行match query的时候,即全文检索查询,ES会对查询字符串进行分词,然后默认满足每一个分词的文档都给返回回来
举个例子:我搜索PremiumSunglasses
那么即只要被搜索字段中包含Premium或者Sunglasses都可以被返回,但有时候,我们需要返回同时包括Premium和Sunglasses的文档给返回回来,这样精度更好一些
POST /ecommerce/glasses/_search
{
"query":{
"match" : {
"record.desc":{
"query":"Premium Round Sunglasses",
"operator": "or",
"minimum_should_match":"68%"
}
}
}
}
这个东西,我们有时利用bool查询也可以做到,比如必须匹配哪些单词,必须不能匹配哪些单词,哪些单词可以匹配也可以不匹配,只是匹配了,有着更好相关度分数
计算分数的时候:
POST /ecommerce/glasses/_search
{
"query":{
"match":{
"record.desc":{
"query": "Premium Sunglasses",
"operator": "and"
}
}
}
}
而之前默认的就是operator为OR
假设我现在同时搜索4个单词,但是希望返回的结果必须至少匹配3个单词,才可以被返回。我们可以使用minimum_should_query参数进行百分比控制:
比如我要必须匹配record.color为Red,必须不能匹配record.onSale为false,可以匹配record.desc包含包含Premium 或者Sunglasses或者Aviator
POST /ecommerce/glasses/_search
{
"query":{
"bool":{
"must": [
{"match":{"record.color":"Red"}}
],
"must_not": [
{"match":{"record.onSale":false}}
],
"should": [
{"match":{"record.desc":"Premium"}},
{"match":{"record.desc":"Sunglasses"}}
]
}
}
}
POST /ecommerce/glasses/_search
{
"query":{
"bool":{
"must": [
{"match":{"record.color":"Red"}}
],
"must_not": [
{"match":{"record.onSale":false}}
],
"should": [
{"match":{"record.desc":"Premium"}},
{"match":{"record.desc":"Sunglasses"}},
{"match":{"record.desc":"Aviator"}}
],
"minimum_should_match": 2 //should至少匹配2个关键字
}
}
}
5.2.5 普通的match匹配如何转换成term+should
比如我们常用的match query,其实在底层它会转化成bool查询,怎么转化呢?
# 普通的match query或者说OR match query
{
"match": { "record.desc": "Premium Sunglasses "}
}
转换成:
POST /ecommerce/glasses/_search
{
"query":{
"bool":{
"should": [
{"match":{"record.desc":"Premium"}},
{"match":{"record.desc":"Sunglasses"}}
]
}
}
}
# AND match query
POST /ecommerce/glasses/_search
{
"query":{
"bool":{
"must": [
{"match":{"record.desc":"Premium"}},
{"match":{"record.desc":"Sunglasses"}}
]
}
}
}
# minimum_should_match
POST /ecommerce/glasses/_search
{
"query":{
"bool":{
"should": [
{"match":{"record.desc":"Premium"}},
{"match":{"record.desc":"Sunglasses"}},
{"match":{"record.desc":"Aviator"}}
],
"minimum_should_match": 2
}
}
}
5.2.6 基于boost细粒度搜索条件的权重控制
搜索条件的权重boost,可以将某个搜索的条件权重加大,此时当匹配这个搜索条件和匹配另一个搜索条件计算相关度分数的时候,boost权重越高的文档,分值越高,优先被返回
比如:我现在针对record.desc搜索Premium,但是希望返回的文档如果匹配到了Round,那么他的权重增加3倍,如果匹配到了Avitaor,他的权重增加2倍,即如果包含Round优先比Aviator返回
POST /ecommerce/glasses/_search
{
"query":{
"bool":{
"must": [
{"match":{"record.desc":"Premium"}}
],
"should": [
{"match":{"record.desc":{"query":"Round","boost":3}}},
{"match":{"record.desc":{"query":"","boost":2}}}
]
}
}
}
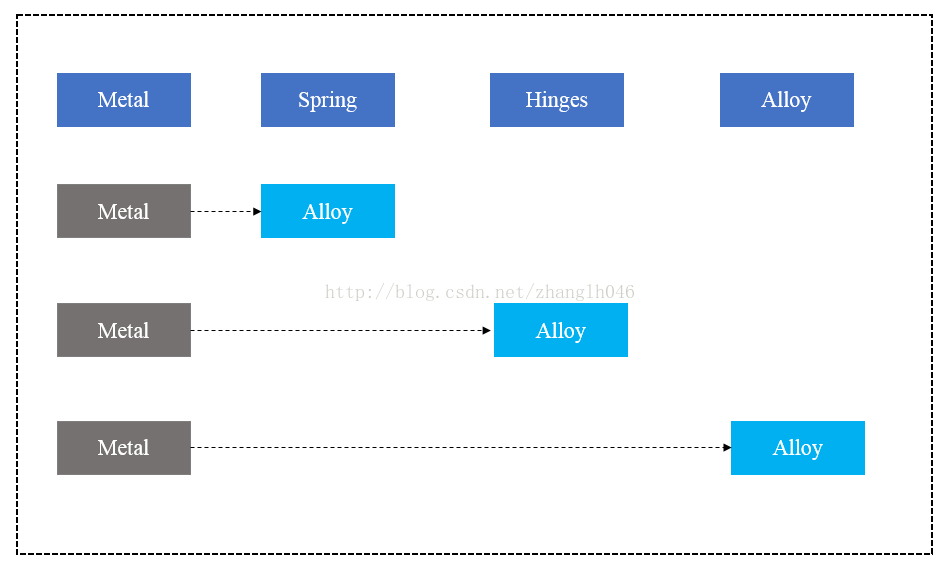
5.3 近似搜索
什么是近似匹配?
假设我们针对一个字段搜索,比如产品描述字段:
Children's Metal Frame With Alloy Spring Hinges。
Metal Alloy Spark Full-Rim Frame
当我们搜索Metal Alloy的时候,正常情况下,ES会对Metal Alloy分词,分成Metal 和 Alloy,所有匹配Metal 或者Alloy或者同时匹配Metal Alloy的document都会被返回。但是如果我们有以下需求:
# 我们希望Metal Alloy紧挨在一起的才返回
# 或者Metal Alloy同时出现,但是他们之间挨的跃进,让他们分值越高
如果使用match做全文检索是不行的。所以这个时候proximity match
就能满足以上需求。
近似搜索主要区分为短语匹配和近似匹配
5.3.1 短语匹配(Phrase Matching)
POST /ecommerce/glasses/_search
{
"query":{
"match_phrase": {"record.desc": {"query":"Metal Alloy"}}
}
}
原理:短语匹配使用到的原理其实就是索引中position
比如:

然后找到那些同时包含指定的查询term的文档,而且同一文档中,Metal之后的Alloy的position 必须只能比它大1个数,比如doc2中,Metal的position为2,所以Alloy的position为3才满足条件
5.3.2 slop参数
什么是slop?slop指定就是搜索中的几个term要经过几次的position的移动,才能与一个document匹配,这个移动的次数就是slop。
比如针对phrasematching,我们搜索Metal Alloy,但是某个文档该字段是这样的:Metal Spring Hinges Alloy ,请问现在我们短语搜索还能搜索到吗?肯定不行。
如果我们希望在指定的position范围内,如果还可以匹配到Alloy,那么就返回文档,如果没有就算了。
匹配流程如下图所示:
POST /ecommerce/glasses/_search
{
"query":{
"match_phrase": {
"record.desc": {
"query": "Metal Alloy",
"slop":2
}
}
}
}
而且,在slop参数参与的情况下,关键词离得越近,得分越高
5.3.3 召回率和精准度
Recall Rate(召回率):指的就是发起一次搜索,100个文档中有多少个可以返回的比例。
Precision(精准度): 即让最好包含全部搜索词或者搜索词挨的比较近的doc排在最前面。
如果是match进行全文检索,召回率很高,但是精准度不足;如果是近似搜索,进准度较高,但是牺牲了召回率。
所以有时候我们希望有较高的召回率,但是在返回的最前面的N个文档的精准度要比较好,因为用户可能只会点击前N个数据,后面的数据就不太关心了。
所以我们可以这样做:
POST /ecommerce/glasses/_search
{
"query": {
"bool":{
"must":[
{"match":{"record.desc":"Metal Alloy"}}
],
"should":[
{"match_phrase": {"record.desc": "MetalAlloy"}}
]
}
}
}
5.3.4 重新打分rescore
在有些场景下:比如我进行match搜索,返回1000个文档,但是希望精准度更高的结果显示在前面。就像我们产品展示页,可能用户只是对前几页的数据感兴趣,后面的就不会去查看了
但是:如果search_type设置成scan或者count,rescore是不会执行的
POST /ecommerce/glasses/_search
{
"query":{
"match":{"record.desc":"Alloy Frame"}
},
"rescore":{
"window_size":2,
"query":{
"score_mode":"total",
"query_weight" : 0.7,
"rescore_query_weight" : 1.2,
"rescore_query":{
"match_phrase":{"record.desc":{"query":"AlloyFrame","slop":2}}
}
}
}
}
window_size: 表示窗口大小,默认值是from+size参数之和,他指定了每一个分片上参与二次评分的文档个数
query_weight: 查询权重,默认为1,原始查询得分和二次评分的得分相加之前乘以该值
rescore_query_weight: 二次品分查询权重,默认是1,二次评分的得分和原始查询得分相加之前乘以该值
score_model: 二次评分模式,默认是total,备选项有max,min,avg和multiply
备注:
total: 得分是两种查询之和
max: 得分是两者最大者
min: 得分是两者最小者
multiply: 两种查询的乘积
5.4 短语前缀查询、正则以及通配符搜索(都不建议使用,性能太差)
5.4.1 短语前缀查询match_phrase_prefix
POST /ecommerce/glasses/_search
{
"query":{
"match_phrase_prefix": {
"record.desc": {"query": "Metal Alloy"}
}
}
}
5.4.2 通配符搜搜
POST /ecommerce/glasses/_search
{
"query":{
"wildcard": {"record.color.keyword":"*la*"}
}
}
5.4.3 正则表达式搜索
POST /ecommerce/glasses/_search
{
"query":{
"regexp":{
"record.color.keyword":"Bl.*"
}
}
}
5.5 过滤查询
查询默认会计算每个返回文档的得分,然后根据得分排序。而过滤(filter)只会筛选出符合的文档,并不计算得分,且它可以缓存文档。所以,单从性能考虑,过滤比查询更快。
换句话说,过滤适合在大范围筛选数据,而查询则适合精确匹配数据。一般应用时,应先使用过滤操作过滤数据,然后使用查询匹配数据。
{
"query": {
"filtered":{
"query":{
"range":{
"date":{
"lte":"2015-10-11"
}
}
},
"filter":{
"match":{
"contents":"酒店"
}
}
}
}
}
过滤查询包含filtered关键字,里面又包含普通的查询query逻辑和filter 过滤逻辑。运行时先执行过滤语句,后执行普通查询。对比下面只使用了查询的DSL:
5.5.1 范围过滤
{
"query": {
"filtered":{
"query":{
"match":{
"contents":"酒店"
}
},
"filter":{
"range":{
"date":{
"gte":"2016-02-01"
}
}
}
}
}
}
5.5.2 exists、mising 过滤器
exists过滤指定字段没有值的文档
{
"query": {
"filtered":{
"filter":{
"exists":{"field":"color"}
}
}
}
}
missing 过滤器与exists相反,它过滤指定字段有值的文档。
{
"query": {
"filtered":{
"filter":{
"missing":{"field":"color"}
}
}
}
}
5.5.3 标识符过滤器
需要过滤出若干指定_id的文档,可使用标识符过滤器(ids)
{
"query": {
"filtered":{
"filter":{
"ids":{"values":[1,2]
}
}
}
}
}
5.5.4 term、terms过滤
term用于精确匹配、terms用于多词条匹配。不过既然过滤器既然适用于大氛围过滤,term、terms在过滤中使用意义不大。
POST /map/hotel/_search
{
"query":{
"constant_score": {
"filter": {
"term": {
"city": "成都"
}
}
}
}
}
5.5.5 limit 限定过滤器
限定过滤器限定单个分片返回的文档数。
如果你查询10条数据,则每个分片都会返回10条数据,集合后再选出前10条数据。如果使用limit限定过滤器,则可限定每个分片返回文档数。
限定每个分片返回2条数据
{
"query": {
"filtered":{
"filter":{
"limit":{
"value":2
}
}
}
}
}
5.5.6 组合过滤器
可以对这些过滤器组合使用,ES中有2类组合过滤器。一类是bool过滤器,一类是and、or、not过滤器
{
"query": {
"filtered":{
"filter":{
"bool":{
"should":[{
"match":{
"star":4
}
},{
"match":{
"city":"成都"
}
}],
"must":{
"range":{
"date":{
"gte":"2016-10-01",
"lte":"2016-10-31"
}
}
}
}
}
}
}
}
六 字段查询
我们知道,全文检索在查询前,会分析查询字符串,即进行分词,然后倒排索引中匹配;而字段查询不会分析查询字符串,即不分词,直接在倒排索引中去匹配
这些查询通常用于结构化数据,比如数字,日期,枚举而不是全文本字段或者处理前期的低等级查询
6.1 单字段查询
只查询过滤,不打分,使用constant_score,默认分值为1
GET /ecommerce/glasses/_search
{
"query":{
"constant_score": {
"filter": {"term":{"record.id":"11264"}}
}
}
}
6.2 多字段查询
terms对多个值过滤,只要满足其中任何一个即可
POST /ecommerce/glasses/_search
{
"query":{
"constant_score": {
"filter": {
"terms": {
"record.desc": ["Plastic","Alloy"]
}
}
}
}
}
6.3 范围查询
POST /ecommerce/glasses/_search
{
"query":{
"constant_score": {
"filter": {
"range": {
"record.review": {
"from": 10,
"to": 20
}
}
}
}
}
}
POST /ecommerce/glasses/_search
{
"query":{
"constant_score": {
"filter": {
"range": {
"record.review": {
"gt": 20,
"lt": 40
}
}
}
}
}
}
范围日期查询:
查询一个月内的文档
POST /ecommerce/glasses/_search
{
"query":{
"constant_score": {
"filter": {
"range": {
"record.postDate": {
"gt": "now-30d"
}
}
}
}
}
}
查询指定日期一个月内的文档
POST /ecommerce/glasses/_search
{
"query":{
"constant_score": {
"filter": {
"range": {
"record.postDate": {
"lt": "2016-01-20||-30d"
}
}
}
}
}
}
七 模糊搜索
我们在搜索的时候,可能会出现拼写错误的情况,比如Red 我们写成了Rad。Fuzzy搜索自动将写错误的搜索文本进行纠正,纠正以后去尝试匹配索引索引中的数据。
POST /_search
{
"query":{
"fuzzy": {
"record.color":{
"value":"Blaek",
"fuzziness":2
}
}
}
}
注意fuzziness的取值只有四种:
0,1,2,以及AUTO
0,1,2 表示的编辑距离,也就是搜索的字符串和原始的字符串需要几次编辑才可以查询到,举个例子
Hadoup 和 Hadoop
首先默认编辑距离为0,先检测第一个字母H,都一样,在检测第二字母都是a,也都一样,在检测第三个种字母,都是d,还是一样的,直到检测第5个字母前面的是u后面的是o,那么此时可编辑距离由0变为1

我们一般更多的是这样使用:
GET /ecommerce/glasses/_search
{
"query": {
"match": {
"record.desc": {
"query": "hadop spark",
"fuzziness": "AUTO",
"operator": "and"
}
}
}
}