hadoop二次排序流程实例详解
一、概述
MapReduce框架对处理结果的输出会根据key值进行默认的排序,这个默认排序可以满足一部分需求,但是也是十分有限的。在我们实际的需求当中,往往有要对reduce输出结果进行二次排序的需求。对于二次排序的实现,网络上已经有很多人分享过了,但是对二次排序的实现的原理以及整个MapReduce框架的处理流程的分析还是有非常大的出入,而且部分分析是没有经过验证的。本文将通过一个实际的MapReduce二次排序例子,讲述二次排序的实现和其MapReduce的整个处理流程,并且通过结果和map、reduce端的日志来验证所描述的处理流程的正确性。
二、需求描述
1、输入数据:
sort1 1
sort2 3
sort2 77
sort2 54
sort1 2
sort6 22
sort6 221
sort6 20
2、目标输出
sort1 1,2
sort2 3,54,77
sort6 20,22,221
三、解决思路
1、首先,在思考解决问题思路时,我们先应该深刻的理解MapReduce处理数据的整个流程,这是最基础的,不然的话是不可能找到解决问题的思路的。我描述一下MapReduce处理数据的大概简单流程:首先,MapReduce框架通过getSplit方法实现对原始文件的切片之后,每一个切片对应着一个map task,inputSplit输入到Map函数进行处理,中间结果经过环形缓冲区的排序,然后分区、自定义二次排序(如果有的话)和合并,再通过shuffle操作将数据传输到reduce task端,reduce端也存在着缓冲区,数据也会在缓冲区和磁盘中进行合并排序等操作,然后对数据按照Key值进行分组,然后每处理完一个分组之后就会去调用一次reduce函数,最终输出结果。大概流程我画了一下,如下图:
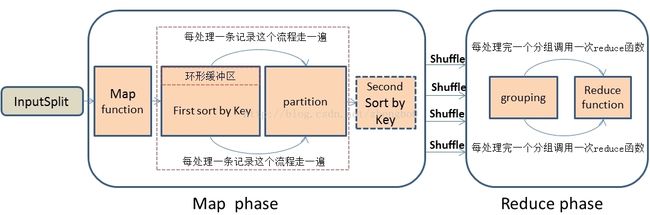
在图中,数据处理分为四个阶段:
(1)Mapper任务会接收输入分片,然后不断的调用map函数,对记录进行处理。处理完毕后,转换为新的
(2)对map函数输出的
(3)对于不同分区的数据,会按照key进行排序,这里的key必须实现WritableComparable接口。该接口实现了Comparable接口,因此可以进行比较排序。
(4)对于排序后的
(5)排序、分组后的数据会被送到Reducer节点。
2、具体解决思路
(1)Map端处理:
根据上面的需求,我们有一个非常明确的目标就是要对第一列相同的记录合并,并且对合并后的数字进行排序。我们都知道MapReduce框架不管是默认排序或者是自定义排序都只是对Key值进行排序,现在的情况是这些数据不是key值,怎么办?其实我们可以将原始数据的Key值和其对应的数据组合成一个新的Key值,然后新的Key值对应的还是之前的数字。那么我们就可以将原始数据的map输出变成类似下面的数据结构:
{[sort1,1],1}
{[sort2,3],3}
{[sort2,77],77}
{[sort2,54],54}
{[sort1,2],2}
{[sort6,22],22}
{[sort6,221],221}
{[sort6,20],20}
那么我们只需要对[]里面的新key值进行排序就ok了。然后我们需要自定义一个分区处理器,因为我的目标不是想将新key相同的传到同一个reduce中,而是想将新key中的第一个字段相同的才放到同一个reduce中进行分组合并,所以我们需要根据新key值中的第一个字段来自定义一个分区处理器。通过分区操作后,得到的数据流如下:
Partition1:{[sort1,1],1}、{[sort1,2],2}
Partition2:{[sort2,3],3}、{[sort2,77],77}、{[sort2,54],54}
Partition3:{[sort6,22],22}、{[sort6,221],221}、{[sort6,20],20}
分区操作完成之后,我调用自己的自定义排序器对新的Key值进行排序。
{[sort1,1],1}
{[sort1,2],2}
{[sort2,3],3}
{[sort2,54],54}
{[sort2,77],77}
{[sort6,20],20}
{[sort6,22],22}
{[sort6,221],221}
(2)Reduce端处理:
经过Shuffle处理之后,数据传输到Reducer端了。在Reducer端对按照组合键的第一个字段来进行分组,并且没处理完一次分组之后就会调用一次reduce函数来对这个分组进行处理输出。最终的各个分组的数据结构变成类似下面的数据结构:
{[sort1,2],[1,2]}
{[sort2,77],[3,54,77]}
{[sort6,221],[20,22,221]}
看到了这个最终的分组,很可能会有人会怀疑:为什么分组过后的key会变成这样?其实是这样的,数据通过排序之后会在reduce端进行分组,而且进入到分组函数的数据是已经经过排序的,我们拿第一个分组输入来说:{[sort1,1],1}、{[sort1,2],2}。当这2组数依次进入到分组函数,我们自定义的分组函数将组合key的第一个值作为分组key,然后进行合并,之后分组后数据变成:{[sort1,?],[1,2]},这了的?是究竟应该是什么值,MapReduce框架在分组的时候因为需要合并所以按照进入分组函数的顺序最后一个进入的则会成为这个分组后key的一部分,即为{[sort1,2],[1,2]}。文章最后面也做了验证,情况reduce端的日志信息。
四、具体实现
1、自定义组合键
package com.mr;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 自定义组合键
* @author zenghzhaozheng
*/
public class CombinationKey implements WritableComparable{
private static final Logger logger = LoggerFactory.getLogger(CombinationKey.class);
private Text firstKey;
private IntWritable secondKey;
public CombinationKey() {
this.firstKey = new Text();
this.secondKey = new IntWritable();
}
public Text getFirstKey() {
return this.firstKey;
}
public void setFirstKey(Text firstKey) {
this.firstKey = firstKey;
}
public IntWritable getSecondKey() {
return this.secondKey;
}
public void setSecondKey(IntWritable secondKey) {
this.secondKey = secondKey;
}
@Override
public void readFields(DataInput dateInput) throws IOException {
// TODO Auto-generated method stub
this.firstKey.readFields(dateInput);
this.secondKey.readFields(dateInput);
}
@Override
public void write(DataOutput outPut) throws IOException {
this.firstKey.write(outPut);
this.secondKey.write(outPut);
}
/**
* 自定义比较策略
* 注意:该比较策略用于mapreduce的第一次默认排序,也就是发生在map阶段的sort小阶段,
* 发生地点为环形缓冲区(可以通过io.sort.mb进行大小调整)
*/
@Override
public int compareTo(CombinationKey combinationKey) {
logger.info("-------CombinationKey flag-------");
return this.firstKey.compareTo(combinationKey.getFirstKey());
}
} 说明:在自定义组合键的时候,我们需要特别注意,一定要实现WritableComparable接口,并且实现compareTo方法的比较策略。这个用于mapreduce的第一次默认排序,也就是发生在map阶段的sort小阶段,发生地点为环形缓冲区(可以通过io.sort.mb进行大小调整),但是其对我们最终的二次排序结果是没有影响的。我们二次排序的最终结果是由我们的自定义比较器决定的。
2、自定义分区器
package com.mr.secondSort;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Partitioner;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 自定义分区
* @author zengzhaozheng
*/
public class DefinedPartition extends Partitioner{
private static final Logger logger = LoggerFactory.getLogger(DefinedPartition.class);
/**
* 数据输入来源:map输出
* @author zengzhaozheng
* @param key map输出键值
* @param value map输出value值
* @param numPartitions 分区总数,即reduce task个数
*/
@Override
public int getPartition(CombinationKey key, IntWritable value,int numPartitions) {
logger.info("--------enter DefinedPartition flag--------");
/**
* 注意:这里采用默认的hash分区实现方法
* 根据组合键的第一个值作为分区
* 这里需要说明一下,如果不自定义分区的话,mapreduce框架会根据默认的hash分区方法,
* 将整个组合将相等的分到一个分区中,这样的话显然不是我们要的效果
*/
logger.info("--------out DefinedPartition flag--------");
/**
* 此处的分区方法选择比较重要,其关系到是否会产生严重的数据倾斜问题
* 采取什么样的分区方法要根据自己的数据分布情况来定,尽量将不同key的数据打散
* 分散到各个不同的reduce进行处理,实现最大程度的分布式处理。
*/
return (key.getFirstKey().hashCode()&Integer.MAX_VALUE)%numPartitions;
}
} 说明:具体说明看代码注释。
3、自定义比较器
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 自定义二次排序策略
* @author zengzhaoheng
*/
public class DefinedComparator extends WritableComparator {
private static final Logger logger = LoggerFactory.getLogger(DefinedComparator.class);
public DefinedComparator() {
super(CombinationKey.class,true);
}
@Override
public int compare(WritableComparable combinationKeyOne,
WritableComparable CombinationKeyOther) {
logger.info("---------enter DefinedComparator flag---------");
CombinationKey c1 = (CombinationKey) combinationKeyOne;
CombinationKey c2 = (CombinationKey) CombinationKeyOther;
/**
* 确保进行排序的数据在同一个区内,如果不在同一个区则按照组合键中第一个键排序
* 另外,这个判断是可以调整最终输出的组合键第一个值的排序
* 下面这种比较对第一个字段的排序是升序的,如果想降序这将c1和c2倒过来(假设1)
*/
if(!c1.getFirstKey().equals(c2.getFirstKey())){
logger.info("---------out DefinedComparator flag---------");
return c1.getFirstKey().compareTo(c2.getFirstKey());
}
else{//按照组合键的第二个键的升序排序,将c1和c2倒过来则是按照数字的降序排序(假设2)
logger.info("---------out DefinedComparator flag---------");
return c1.getSecondKey().get()-c2.getSecondKey().get();//0,负数,正数
}
/**
* (1)按照上面的这种实现最终的二次排序结果为:
* sort1 1,2
* sort2 3,54,77
* sort6 20,22,221
* (2)如果实现假设1,则最终的二次排序结果为:
* sort6 20,22,221
* sort2 3,54,77
* sort1 1,2
* (3)如果实现假设2,则最终的二次排序结果为:
* sort1 2,1
* sort2 77,54,3
* sort6 221,22,20
*/
}
}说明:自定义比较器决定了我们二次排序的结果。自定义比较器需要继承WritableComparator类,并且重写compare方法实现自己的比较策略。具体的排序问题请看注释。
4、自定义分组策略
package com.mr;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 自定义分组策略
* 将组合将中第一个值相同的分在一组
* @author zengzhaozheng
*/
public class DefinedGroupSort extends WritableComparator{
private static final Logger logger = LoggerFactory.getLogger(DefinedGroupSort.class);
public DefinedGroupSort() {
super(CombinationKey.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
logger.info("-------enter DefinedGroupSort flag-------");
CombinationKey ck1 = (CombinationKey)a;
CombinationKey ck2 = (CombinationKey)b;
logger.info("-------Grouping result:"+ck1.getFirstKey().
compareTo(ck2.getFirstKey())+"-------");
logger.info("-------out DefinedGroupSort flag-------");
return ck1.getFirstKey().compareTo(ck2.getFirstKey());
}
}5、主体程序实现
package com.mr;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* @author zengzhaozheng
*
* 用途说明:二次排序mapreduce
* 需求描述:
* ---------------输入-----------------
* sort1,1
* sort2,3
* sort2,77
* sort2,54
* sort1,2
* sort6,22
* sort6,221
* sort6,20
* ---------------目标输出---------------
* sort1 1,2
* sort2 3,54,77
* sort6 20,22,221
*/
public class SecondSortMR extends Configured implements Tool {
private static final Logger logger = LoggerFactory.getLogger(SecondSortMR.class);
public static class SortMapper extends Mapper {
//---------------------------------------------------------
/**
* 这里特殊要说明一下,为什么要将这些变量写在map函数外边。
* 对于分布式的程序,我们一定要注意到内存的使用情况,对于mapreduce框架,
* 每一行的原始记录的处理都要调用一次map函数,假设,此个map要处理1亿条输
* 入记录,如果将这些变量都定义在map函数里边则会导致这4个变量的对象句柄编
* 程非常多(极端情况下将产生4*1亿个句柄,当然java也是有自动的gc机制的,
* 一定不会达到这么多,但是会浪费很多时间去GC),导致栈内存被浪费掉。我们将其写在map函数外边,
* 顶多就只有4个对象句柄。
*/
CombinationKey combinationKey = new CombinationKey();
Text sortName = new Text();
IntWritable score = new IntWritable();
String[] inputString = null;
//---------------------------------------------------------
@Override
protected void map(Text key, Text value, Context context)
throws IOException, InterruptedException {
logger.info("---------enter map function flag---------");
//过滤非法记录
if(key == null || value == null || key.toString().equals("")
|| value.equals("")){
return;
}
sortName.set(key.toString());
score.set(Integer.parseInt(value.toString()));
combinationKey.setFirstKey(sortName);
combinationKey.setSecondKey(score);
//map输出
context.write(combinationKey, score);
logger.info("---------out map function flag---------");
}
}
public static class SortReducer extends
Reducer {
StringBuffer sb = new StringBuffer();
Text sore = new Text();
/**
* 这里要注意一下reduce的调用时机和次数:reduce每处理一个分组的时候会调用一
* 次reduce函数。也许有人会疑问,分组是什么?看个例子就明白了:
* eg:
* {{sort1,{1,2}},{sort2,{3,54,77}},{sort6,{20,22,221}}}
* 这个数据结果是分组过后的数据结构,那么一个分组分别为{sort1,{1,2}}、
* {sort2,{3,54,77}}、{sort6,{20,22,221}}
*/
@Override
protected void reduce(CombinationKey key,
Iterable value, Context context)
throws IOException, InterruptedException {
sb.delete(0, sb.length());//先清除上一个组的数据
Iterator it = value.iterator();
while(it.hasNext()){
sb.append(it.next()+",");
}
//去除最后一个逗号
if(sb.length()>0){
sb.deleteCharAt(sb.length()-1);
}
sore.set(sb.toString());
context.write(key.getFirstKey(),sore);
logger.info("---------enter reduce function flag---------");
logger.info("reduce Input data:{["+key.getFirstKey()+","+
key.getSecondKey()+"],["+sore+"]}");
logger.info("---------out reduce function flag---------");
}
}
@Override
public int run(String[] args) throws Exception {
Configuration conf=getConf(); //获得配置文件对象
Job job=new Job(conf,"SoreSort");
job.setJarByClass(SecondSortMR.class);
FileInputFormat.addInputPath(job, new Path(args[0])); //设置map输入文件路径
FileOutputFormat.setOutputPath(job, new Path(args[1])); //设置reduce输出文件路径
job.setMapperClass(SortMapper.class);
job.setReducerClass(SortReducer.class);
job.setPartitionerClass(DefinedPartition.class); //设置自定义分区策略
job.setGroupingComparatorClass(DefinedGroupSort.class); //设置自定义分组策略
job.setSortComparatorClass(DefinedComparator.class); //设置自定义二次排序策略
job.setInputFormatClass(KeyValueTextInputFormat.class); //设置文件输入格式
job.setOutputFormatClass(TextOutputFormat.class);//使用默认的output格式
//设置map的输出key和value类型
job.setMapOutputKeyClass(CombinationKey.class);
job.setMapOutputValueClass(IntWritable.class);
//设置reduce的输出key和value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.waitForCompletion(true);
return job.isSuccessful()?0:1;
}
public static void main(String[] args) {
try {
int returnCode = ToolRunner.run(new SecondSortMR(),args);
System.exit(returnCode);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}