Elasticsearch:sniffing 的最佳实践:What, when, why, how
Elasticsearch 为当今使用的众多工具和应用程序提供强大的搜索体验,从运营分析仪表板到显示带有露台的最近餐馆的地图,你都可以出门在外。 在所有这些实现中,应用程序和集群之间的连接都是通过 Elasticsearch 客户端建立的。
优化客户端和 Elasticsearch 集群之间的连接对于最终用户的体验极为重要。 Elasticsearch 客户端的典型配置是你必须连接到的节点的 URL。 但是你还可以做更多的事情,一种优化此连接的方法是 sniffing。
以下是 sniffing 的工作原理,何时应使用 sniffing 以及如何知道何时应避免 sniffing。
Sniffing 到底是什么?
Elasticsearch 是一个分布式系统,这意味着其索引位于相互连接的多个节点中,形成一个集群。分布式系统的主要优点(容错性除外)之一是将数据分片到多个节点中,从而使搜索运行的速度比通过庞大的单个节点运行的速度快得多。
典型的客户端配置是指向 Elasticsearch 集群的一个节点的单个 URL。尽管这是最简单的配置,但此设置的主要缺点是你发出的所有请求都将发送到该特定的协调节点。由于这会使单个节点承受压力,因此可能会影响整体性能。
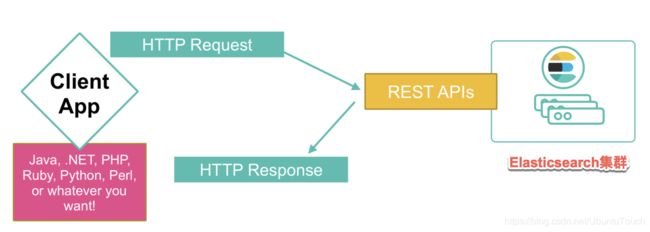
一种解决方案是将静态节点列表传递给客户端,因此你的请求将平均分布在节点之间。
或者,您可以启用称为 sniffing 的功能。
使用静态节点列表,不能保证节点将始终处于运行状态。例如,如果您关闭某个节点进行升级或添加新节点会发生什么?
如果启用 sniffing,则客户端将开始调用 _nodes /_all /http 端点,并且响应将是群集中存在的所有节点及其 IP 地址的列表。然后,客户端将更新其连接池以使用所有新节点,并使群集状态与客户端的连接池保持同步。请注意,即使客户端下载了完整的节点列表,master-only 节点也不会用于通用 API 调用。如果你对各个节点的功能还是不很清楚的话,请阅读我之前的文章 “Elasticsearch中的一些重要概念:cluster, node, index, document, shards及replica”
sniffing 解决了这个发现问题。那么为什么默认情况下不启用它呢?好问题!
什么时候使用 sniffing?
sniffing 可以是一把双刃剑。 如果你尝试调用 _nodes /_all /http 端点,则会看到节点及其各自端点的列表。 但是有几个问题需要考虑:
- 如果你的 Elasticsearch 集群安装于自己的单独网络中(比如 docker 的安装情形),会发生什么?
- 如果您的 Elasticsearch 集群位于负载均衡器后面怎么办?
两者的简短答案:由于你位于其他网络中,因此你将获得完全无用的 IP 地址。
你可以使用 Docker 自己尝试。 启动一个 Elasticsearch 实例(一个就足够了),然后从本地计算机调用 _nodes /_all /http。 你会看到节点的 IP 地址不会与你刚才使用的 IP 地址相同。
与以下命令一起使用来引导 Elasticsearch 实例:
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.8.0
docker run -p 9200:9200 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:7.8.0在上面,我们下载最新的 Elasticsearch 7.8.0 版本,并运用 Docker 来启动一个 Elasticsearch 的实例。
现在,你可以使用以下命令读取节点 IP。 (在以下代码段中,我们使用 jq 使阅读响应更容易。):
curl -s localhost:9200/_nodes/_all/http | jq .nodes[].http.publish_address$ curl -s localhost:9200/_nodes/_all/http | jq .nodes[].http.publish_address
"172.17.0.2:9200"最后,你可以复制终端中打印的 IP 地址,然后尝试向其发送请求:
curl {ip_address}:9200 | jq .$ curl 172.17.0.2:9200 | jq .
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- 0:00:07 --:--:-- 0如你所见,你不会获得成功的回应。
这意味着,如果在群集位于另一个网络中时在客户端中启用 sniffing,则客户端会将所有新节点添加到其连接池中。 那是因为它无法理解那些 IP 地址是错误的,并且针对这些节点之一的每个查询都会失败。
由于具有正确 IP 地址的初始节点不再处于群集状态,因此将其丢弃,并且很快会出现 “no living connections” 错误。
如何避免上面的错误?
要解决此问题,你可以配置 Elasticsearch 绑定到其主机,但对外通告的是另外一个。 http.publish_host 配置选项正是这样做的。 现在,尝试使用此新配置运行上述 Docker 命令:
docker run -p 9200:9200 -e "discovery.type=single-node" -e "http.publish_host=localhost" docker.elastic.co/elasticsearch/elasticsearch:7.8.0现在你再次重新运行:
$ curl -s localhost:9200/_nodes/_all/http | jq .nodes[].http.publish_address
"localhost/127.0.0.1:9200"在上面,我们可以看到:
"localhost/{ip_address}:9200"$ curl localhost:9200/_nodes/_all/http | jq .
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 661 100 661 0 0 94428 0 --:--:-- --:--:-- --:--:-- 107k
{
"_nodes": {
"total": 1,
"successful": 1,
"failed": 0
},
"cluster_name": "docker-cluster",
"nodes": {
"nfbZ9n97RIS5nHh9SLDKSQ": {
"name": "fd3b0ecf1610",
"transport_address": "172.17.0.2:9300",
"host": "172.17.0.2",
"ip": "172.17.0.2",
"version": "7.8.0",
"build_flavor": "default",
"build_type": "docker",
"build_hash": "757314695644ea9a1dc2fecd26d1a43856725e65",
"roles": [
"data",
"ingest",
"master",
"ml",
"remote_cluster_client",
"transform"
],
"attributes": {
"ml.machine_memory": "12303761408",
"xpack.installed": "true",
"transform.node": "true",
"ml.max_open_jobs": "20"
},
"http": {
"bound_address": [
"0.0.0.0:9200"
],
"publish_address": "localhost/127.0.0.1:9200",
"max_content_length_in_bytes": 104857600
}
}
}
}如果你配置发布主机,则正式客户端(v7及更高版本)足够聪明,可以使用主机地址而不是 IP。
这样做的主要好处是,在启用嗅探之前,您应该了解您的基础结构。 有许多解决此IP地址问题的方法,并且没有灵丹妙药,因为这完全取决于您的系统配置。
典型的开发设置是将 Elasticsearch 集群与你的客户端放在同一网络中,但这不能在现实世界中复制,因为这会导致安全问题-而且你的基础架构可能会更复杂。 你可以将负载均衡器配置为处理这些IP地址。 或者,就像 Elastic 在 Elastic Cloud 中所做的那样,你可以让代理处理发生故障的节点,以便客户端始终将查询发送到代理,然后将查询发送到适当的节点。
在什么样的情况下不适合使用 sniffing?
在许多情况下,sniffing 可能会导致一些问题,包括:
- 你的客户端要通过其进行身份验证的 Elasticsearch 用户没有访问节点 API 的正确权限(monitoring_user 角色)。
- 你正在与云提供商合作。
通常,云提供商将 Elasticsearch 隐藏在代理之后,这将使 sniffing 操作无效,因为返回的地址和主机名可能在你的网络中没有任何意义。通常,这些云提供商将为你处理 sniffing 和池处理的复杂性,因此你无需启用这些功能。
如果你使用的是 Elastic Cloud,则官方客户端会在内部简化大多数操作,例如连接池处理,以避免花时间进行已完成的操作。
如前所述,在使用 Docker 或 Kubernetes 时可能会发生其他问题。除非你配置了 http.publish_host 选项,否则 sniffing 结果将无法使用。
根据经验:如果 Elasticsearch 与你的客户端位于不同的网络中-或存在负载平衡器-则应禁用 sniiffing 功能,除非基础架构中进行了一些配置以使你可以准确地使用它。
如何使用 sniffing?
客户端设计提供多种 sniffing 策略。让我们对其进行分析:
在启动时 sniffing
顾名思义,启用此选项后,客户端将仅在客户端初始化或首次使用时尝试一次执行 sniffing 请求。
嗅探连接失败
如果启用此选项,则每当一个节点出现故障时,客户端将尝试执行 sniffing 请求,这意味着连接断开或节点失效。
sniffing 间隔
除了在启动时进行 sniffing 和对故障进行 sniffing 之外,定期进行 sniffing 还可以使群集在高峰时段经常水平扩展的方案受益匪浅。应用程序可能具有节点子集的健康视图。但是,如果不定期进行 sniffing,它将永远不会找到作为集群扩容的一部分添加的节点。
自定义配置
在某些情况下,你可能希望对 sniffing 过程进行更细粒度的控制。客户端足够灵活,可以配置自定义 sniffiing 端点,也可以完全覆盖 sniffing 逻辑并提供自己的 sniffing 逻辑。
结论
启用 sniffing 功能后,你将使你的应用程序更具弹性并能够适应变化。 在这样做之前,你应该了解您的基础架构,以便可以决定采用哪种最佳解决方案。 最好的解决方案甚至可能是不采用 sniffing。
参考:
【1】https://www.elastic.co/blog/elasticsearch-sniffing-best-practices-what-when-why-how