Kafka如何实现高吞吐量 低延迟
1.为什么这么快?
kafka为什么这么快,就是kafka再各个层面做了各种各样的优化,尽可能的把资源最大化的利用
kafka做的优化主要有以下几个方面:
- 1.Producer批处理
- 2.PageCache(读写缓存的使用)
- 3.ZeroCopy
- 4.Kafka服务端处理请求的方式
- 5.顺序读写
- 6.分区机制,以及消费者组的使用
- 7.消息格式的演变,以及压缩消息
- 最主要的就是v2版本提取消息公共属性,使用可变长参数的优化
- 8.摒弃消息的SRC校验(但是损失了安全性,效果有待检验)
本篇接下来的内容就是详细讨论这些方面kafka所做的前三个优化。
2.Producer批处理
首先kafka发送消息不是一条一条发送的,而是攥一批,一批一批的发送的。叫做批量发送。
这样是很大的提高了发送消息的吞吐量的,我们假设发送一条消息的时间是1ms,而此时的吞吐量就是1000TPS。但是假如我们将消息批量发送,1000条消息需要10ms,而此时的吞吐量就达到了1000*100TPS。而且这样也很大程度的减少了请求Broker的次数,提升了总体的效率。
注:批量发送消息的大小是可以在配置文件中配置的,而且还可以进行类似于一个超时时间的配置,超过这个超时时间还没有达到配置文件中的消息大小,也是会发送消息的。
如图为kafka发送消息的一次Producer请求过程,整个过程有两个线程,send用户主线程,和发送消息的Sender线程。Sender线程异步的也是在构造KafkaProducer对象的时候创建的。
用户主线程: 1.消息序列化,计算消息分区。2.追加到对应的缓冲区
Sender线程:2.按照Broker进行分组(Topic+Partition)。2.轮询缓冲区获取到准备就绪的消息,进行分发送。

3.PageCache
说到PageCache,首先就说下缓存,缓存按照类型分,主要分为两大类只读缓存、读写缓存。
只读缓存和读写缓存的区别更新数据的时候是否经过缓存。
正常的场景我们对只读缓存的应用比较多,读写缓存的应用极其少,但是消息队列就是其中的应用场景之一,因为有着读与写近似于1:1的比例。
PageCache就是一种典型的读写缓存,是操作系用在内存那种来给文件做的缓存。Kakfa发送消息成功的标志就是只要写入PageCache就认定为成功,具体的入盘操作就交给OS自己去做处理(可以变为同步刷盘,但是不建议使用,性能损耗比较大,而且kafka具有replica的机制,很大程度上保证了消息不会丢失)。
好处:
- PageCache 和文件系统的一致性完全交给OS来处理,会比进程内维护更加安全有效。
- 对于一个配置比较好的Kafka集群,读写基本都是走的PageCache,基本很少查询磁盘,很大程度上的提供了kafka的效率。
如图为PageCache的基本介绍与操作。
producer发送消息,发送到PageCache之后,Broker就可以返回消息发送成功(要根据Broker端配置的消息发送成功定义来判断)。
consumer拉取消息,命中,直接放回,未命中,从磁盘同步到PageCache,然后返回。

4.ZeroCopy
Kafka在完成文件网络传输的时候,利用里OS的ZeroCopy极大的提升了,文件网络传输的效率,从而提升了系统的效率。
4.1普通Copy
拿java程序为例子,我们想要从磁盘copy一个文件,往往需要两个步骤:
1.read()
2.write()
但是一次普通的copy在OS中往往没有这么简单,如下图所示,为一次普通copy的时序图:
可以看到进行了四次数据copy,和四次上线文切换。

接下来通过普通copy的流程图来解释一次,copy的具体过程:
如下图所示结合时序图可以看出一共经历四个步骤:
1.掉用read() ,文件A中的内容被复制到了 内核模式中的Read Buffer中。此时用户状态切换到内核状态。
2.CPU控制将内核状态数据复制到应用(用户)状态下。用户状态 -> 内核状态。
3.调用write()时,将用户状态下的内容复制到内核状态下的 Socket Buffer 中。
4.将Socket Buffer 的数据复制到网卡缓存中去。最后 内核状态 -> 用户状态 ,一次普通copy结束。

我们可以看出一次普通的copy做了大量的上下文切换,与数据的copy,其实很多都是不必要的。数据的copy是io密集型的操作,而上下文的切换是cpu密集型的操作,尤其是上下文切换带来的系统性能的损耗,是巨大的。因此OS在这些方面开始做了一些优化,减少了不必要的copy次数和不必要的上下文切换的次数,就出现了ZeroCopy。
4.2ZeroCopy
**ZeroCopy:**零拷贝是指将数据直接从磁盘文件复制到网卡设备中,而不需要经由应用程序之手。零拷贝技术是通过DMA来实现的。将文件内容copy到内核空间的read Buffer中,不过不需要讲吧数据复制到Socket Buffer中,Socket Buffer仅仅包含了一些文件的描述符号(数据的地址和长度等等)。DMA引擎直接将数据从内核空间传递到网卡设备中去。需要注意的是零拷贝不是不进行copy而是,在内核空间下进行了0次copy。
对于Linux操作系统来言,就是通过**sendfile()系统方法的调用来完成一次零拷贝,对于java语言来说就是通过transferTo()**方法来去调用这个系统调用。
我们知道任何技术的出现都不是一蹴而就的,都是有一个演进过程的,零拷贝也是,经历了普通ZeroCopy到完全体的ZeroCopy的演进。我们相信以后的ZeroCopy可能要不现在的最终形态的零拷贝更加高效。
普通零copy
严格的意义来讲普通的ZeroCopy并不是一个严谨的零拷贝,在内核状态下还是会经过一次copy。
还是先来看下普通零拷贝的时序图:
我们需要注意的是零拷贝并不是不进行
可以和普通的copy进行对比,明显发现流程简介了很多,尤其是上下文切换的次数,减少到了两次,copy次数减少到了三次。
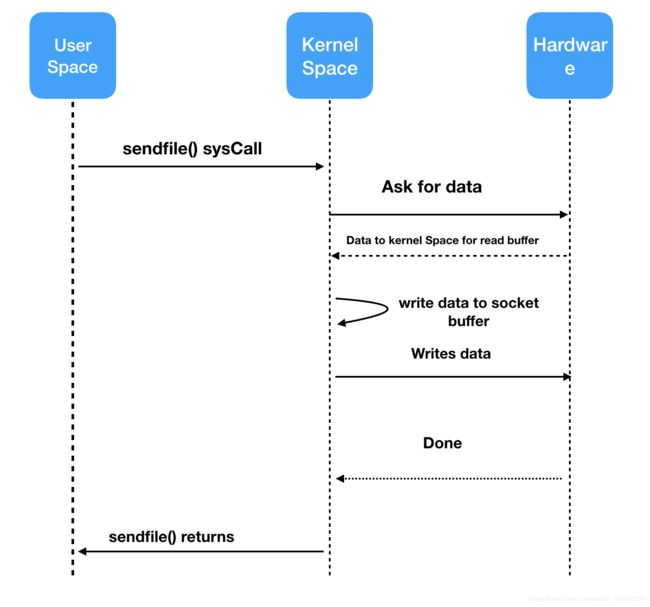
接下来我们通过流程图来分析一次普通零copy的过程:
1.调用transferTo()方法,用户空间转换为内核空间,将数据从存储copy到 内核空间的read Buffer中。
2.通过Block DMA技术直接将数据从 内核空间的 Read Buffer copy 到 内核空间的 Socket Buffer 中。
3.将数据copy到网卡Buffer中去。内核空间 -> 用户空间。一次普通的零拷贝结束。

通过对比我们可以看到,一次普通的零copy将 copy的次数减少了一次,上下文切换的次数减少到了两次。已经非常大程度上的提升了一次copy的性能,但是还是没有做到真正意义上的零拷贝,还需要将Read Buffer中的数据copy到Socket Buffer中去。
零拷贝
如下图所示,为一次最终意义上的零拷贝的时序图,怎么样?看起来是不是特别简洁。
整个过程仅仅出现了 两次copy和两次上下文切换。
最终完成了内核空间上数据零拷贝。将数据的拷贝次数和上线文切换的次数都减少到了两次。
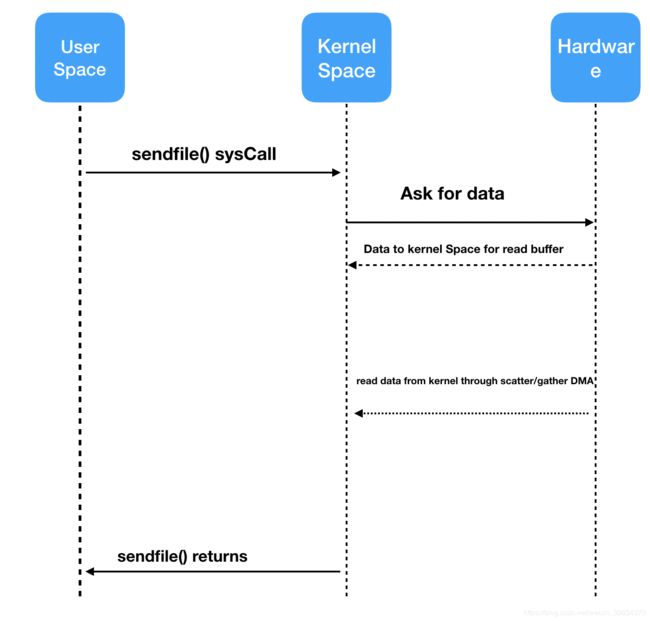
和普通零拷贝对比仅仅是最后一步发生了变化,就是最后一次copy直接将数据从内核空间copy到网卡缓存。而不需要再将数据copy到Socket Buffer中去了。将数据copy到内核空间下的Read Buffer中后,并没有再将数据copy到内核状态下的 socket buffer中去,仅仅是将数据的描述信息发给到了socket buffer中去,最终通过DMA引擎将数据从高内核模式直接传输到网卡设备中去,完成一次零拷贝。
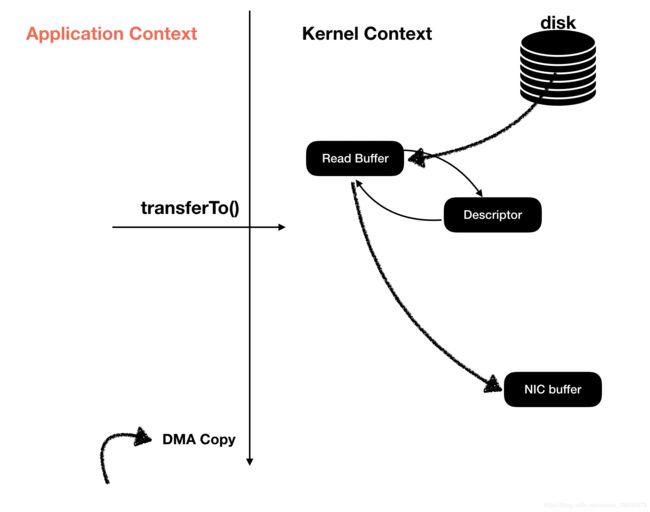
kafka通过使用 ZeroCopy技术来进一步提升了自己的性能。kafka对OS的使用基本就是无所不用其极呀!!
今天的文章主要讲了kafka为什么这么快的原因,以及对Kafka使用批处理、PageCache、ZeroCopy进行了详细的解释。
下篇文章会对接下来的几种优化,作出详细的分析。