docker swarm集群下部署elasticsearch7.6.2集群+kibana7.6.2+es-head+中文分词
docker swarm集群下部署elasticsearch7.6.2集群+kibana7.6.2+es-head+中文分词
上一篇文章是:linux Centos7 安裝搭建elasticsearch7.6.2+kibana7.6.2+中文分词7.6.2详解
这里再说一下docker swarm下部署es集群的思路。此为个人研究的结果。如果博友有更好的方案还请留言告知。
目录
docker swarm集群下部署elasticsearch7.6.2集群+kibana7.6.2+es-head+中文分词
环境介绍:
准备镜像
配置elasticsearch
创建目录
添加elasticsearch配置文件
添加Dockerfile文件
添加中文分词器
启动elasticsearch
打包elasticsearch镜像
编写compose文件
启动elasticsearch
启动kibana
创建kibana配置文件
启动kibana
启动elasticsearch-head
1、单机运行head
2、集群模式启动
环境介绍:
- 服务器三台,后边分别简称68、69、70
| 10.**.**.68 | CentOS 7.4 (64 位) |
| 10.**.**.69 | CentOS 7.4 (64 位) |
| 10.**.**.70 | CentOS 7.4 (64 位) |
- 初始化好的docker swarm集群,三个节点
[root@elcndc2zhda01 ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
skq2d634av8scq5uumciwuedf * elcndc2zhda01 Ready Active Leader 19.03.8
1j1i345greywliwuyuwro01if elcndc2zhda02 Ready Active Reachable 19.03.8
xqxl9gs9igb7jyo3cohsarehi elcndc2zhda03 Ready Active Reachable 19.03.8
注意:注意:为了方便我三个集群节点已经配置了nas共享挂载目录,为/data目录。如果大家没有配置共享目录,那有些文件需要三个服务器都创建,比如下边提到的kibana。所以下边只要提到/data目录下的文件,我这里是三台服务器共享的,操作一个服务器即可,如果没有共享目录,需要每个服务器单独操作。
准备镜像
- 三台服务器分别下载官方镜像:elasticsearch:7.6.2,kibana:7.6.2(需要与es版本一致),elasticsearch-head:5
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.6.2
docker pull docker.elastic.co/kibana/kibana:7.6.2
docker pull mobz/elasticsearch-head:5镜像下载好后,开始准备配置es
配置elasticsearch
-
创建目录
在/data下为是三个服务器分别创建配置文件存放目录
mkdir /data/erms/es/{kinana,node1,node2,node3} -p三个node分别是给三个服务器用的,如果没有共享目录也可以手动一个服务器创建一个node目录。
创建后效果:
[root@elcndc2zhda01 es]# cd /data/erms/es
[root@elcndc2zhda01 es]# ls
kinana node1 node2 node3
[root@elcndc2zhda01 es]#
-
添加elasticsearch配置文件
在node1目录下新建elasticsearch.yml配置文件内容如下:
将配置文件中的 discovery.seed_hosts内容替换为自己集群的ip
# ======================== Elasticsearch Configuration =========================
#
# NOTE: Elasticsearch comes with reasonable defaults for most settings.
# Before you set out to tweak and tune the configuration, make sure you
# understand what are you trying to accomplish and the consequences.
#
# The primary way of configuring a node is via this file. This template lists
# the most important settings you may want to configure for a production cluster.
#
# Please consult the documentation for further information on configuration options:
# https://www.elastic.co/guide/en/elasticsearch/reference/index.html
#
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
cluster.name: es-cluster
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: node-1
#
# Add custom attributes to the node:
#
#node.attr.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
#path.data: /path/to/data
#
# Path to log files:
#
#path.logs: /path/to/logs
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
#bootstrap.memory_lock: true
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: 0.0.0.0
#
# Set a custom port for HTTP:
#
http.port: 9200
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when this node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
discovery.seed_hosts: ["10.**.**.68:10010","10.**.**.69:10010","10.**.**.70:10010"]
#
# Bootstrap the cluster using an initial set of master-eligible nodes:
#
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
# bootstrap.memory_lock: true
#
# For more information, consult the discovery and cluster formation module documentation.
#
# ---------------------------------- Gateway -----------------------------------
#
# Block initial recovery after a full cluster restart until N nodes are started:
#
#gateway.recover_after_nodes: 3
#
# For more information, consult the gateway module documentation.
#
# ---------------------------------- Various -----------------------------------
#
# Require explicit names when deleting indices:
#
#action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: '*'
http.cors.allow-headers: Authorization,X-Requested-With,Content-Length,Content-Type
在node2目录下新建elasticsearch.yml配置文件内容如下:
将配置文件中的 discovery.seed_hosts内容替换为自己集群的ip
# ======================== Elasticsearch Configuration =========================
#
# NOTE: Elasticsearch comes with reasonable defaults for most settings.
# Before you set out to tweak and tune the configuration, make sure you
# understand what are you trying to accomplish and the consequences.
#
# The primary way of configuring a node is via this file. This template lists
# the most important settings you may want to configure for a production cluster.
#
# Please consult the documentation for further information on configuration options:
# https://www.elastic.co/guide/en/elasticsearch/reference/index.html
#
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
cluster.name: es-cluster
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: node-2
#
# Add custom attributes to the node:
#
#node.attr.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
#path.data: /path/to/data
#
# Path to log files:
#
#path.logs: /path/to/logs
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
#bootstrap.memory_lock: true
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: 0.0.0.0
#
# Set a custom port for HTTP:
#
http.port: 9200
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when this node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
discovery.seed_hosts: ["10.**.**.68:10010","10.**.**.69:10010","10.**.**.70:10010"]
#
# Bootstrap the cluster using an initial set of master-eligible nodes:
#
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
# bootstrap.memory_lock: true
#
# For more information, consult the discovery and cluster formation module documentation.
#
# ---------------------------------- Gateway -----------------------------------
#
# Block initial recovery after a full cluster restart until N nodes are started:
#
#gateway.recover_after_nodes: 3
#
# For more information, consult the gateway module documentation.
#
# ---------------------------------- Various -----------------------------------
#
# Require explicit names when deleting indices:
#
#action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: '*'
http.cors.allow-headers: Authorization,X-Requested-With,Content-Length,Content-Type
在node3目录下新建elasticsearch.yml配置文件内容如下:
将配置文件中的 discovery.seed_hosts内容替换为自己集群的ip
# ======================== Elasticsearch Configuration =========================
#
# NOTE: Elasticsearch comes with reasonable defaults for most settings.
# Before you set out to tweak and tune the configuration, make sure you
# understand what are you trying to accomplish and the consequences.
#
# The primary way of configuring a node is via this file. This template lists
# the most important settings you may want to configure for a production cluster.
#
# Please consult the documentation for further information on configuration options:
# https://www.elastic.co/guide/en/elasticsearch/reference/index.html
#
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
cluster.name: es-cluster
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: node-3
#
# Add custom attributes to the node:
#
#node.attr.rack: r1
#
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
#path.data: /path/to/data
#
# Path to log files:
#
#path.logs: /path/to/logs
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
#bootstrap.memory_lock: true
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: 0.0.0.0
#
# Set a custom port for HTTP:
#
http.port: 9200
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when this node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
discovery.seed_hosts: ["10.**.**.68:10010","10.**.**.69:10010","10.**.**.70:10010"]
#
# Bootstrap the cluster using an initial set of master-eligible nodes:
#
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
# bootstrap.memory_lock: true
#
# For more information, consult the discovery and cluster formation module documentation.
#
# ---------------------------------- Gateway -----------------------------------
#
# Block initial recovery after a full cluster restart until N nodes are started:
#
#gateway.recover_after_nodes: 3
#
# For more information, consult the gateway module documentation.
#
# ---------------------------------- Various -----------------------------------
#
# Require explicit names when deleting indices:
#
#action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: '*'
http.cors.allow-headers: Authorization,X-Requested-With,Content-Length,Content-Type
-
添加Dockerfile文件
向node1,node2,node3三个目录下均添加Dockerfile,内容如下:
这里第三行是为了添加中文分词,如果不需要可删掉。
FROM docker.elastic.co/elasticsearch/elasticsearch:7.6.2
COPY --chown=elasticsearch:elasticsearch elasticsearch.yml /usr/share/elasticsearch/config/
ADD ik /usr/share/elasticsearch/plugins/ik
ADD ik/config /data/erms/es/node1/ik/config-
添加中文分词器
分词器下载网址:https://github.com/medcl/elasticsearch-analysis-ik/releases
选择自己es对应的版本,这里下载的7.6.2:https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.6.2
分别在三个node目录下创建ik目录,
将elasticsearch-analysis-ik-7.6.2.zip 上传到ik目录下,
解压elasticsearch-analysis-ik-7.6.2.zip
删除elasticsearch-analysis-ik-7.6.2.zip
命令依次如下:
[root@elcndc2zhda01 node1]# mkdir ik
[root@elcndc2zhda01 node1]# cd ik
[root@elcndc2zhda01 ik]# unzip elasticsearch-analysis-ik-7.6.2.zip
Archive: elasticsearch-analysis-ik-7.6.2.zip
creating: config/
inflating: config/main.dic
inflating: config/quantifier.dic
inflating: config/extra_single_word_full.dic
inflating: config/IKAnalyzer.cfg.xml
inflating: config/surname.dic
inflating: config/suffix.dic
inflating: config/stopword.dic
inflating: config/extra_main.dic
inflating: config/extra_stopword.dic
inflating: config/preposition.dic
inflating: config/extra_single_word_low_freq.dic
inflating: config/extra_single_word.dic
inflating: elasticsearch-analysis-ik-7.6.2.jar
inflating: httpclient-4.5.2.jar
inflating: httpcore-4.4.4.jar
inflating: commons-logging-1.2.jar
inflating: commons-codec-1.9.jar
inflating: plugin-descriptor.properties
inflating: plugin-security.policy
[root@elcndc2zhda01 ik]# rm -rf elasticsearch-analysis-ik-7.6.2.zip
[root@elcndc2zhda01 ik]# ls
commons-codec-1.9.jar config httpclient-4.5.2.jar plugin-descriptor.properties
commons-logging-1.2.jar elasticsearch-analysis-ik-7.6.2.jar httpcore-4.4.4.jar plugin-security.policy
启动elasticsearch
-
打包elasticsearch镜像
三台服务器需要分别打包镜像,这里因为es主从节点配置有点差异所以三个节点的es配置文件有所不同,才这么操作。有更好方式的请给我留言。不过我这个方式集群运行效果还不错。
68服务器下执行:
cd /data/erms/es/node1
docker build -t erms/es .69服务器下执行:
cd /data/erms/es/node2
docker build -t erms/es .70服务器下执行:
cd /data/erms/es/node3
docker build -t erms/es .-
编写compose文件
三台服务器分别对应的docker compose文件如下:
注意:这里es索引数据的持久化储存,没有单独创建目录存放,而是通过docker的volumes,由docker自行管理的。
这里向外暴露的端口号是10010
docker-compose-esnode1.yml
version: '3.3'
services:
ermsesnode1:
hostname: ermsesnode1
image: erms/es
labels:
"type": "2"
networks:
- edoc2_default
ports:
- target: 9200
published: 10010
mode: host
environment:
- node.name=ermsesnode1
- discovery.seed_hosts=ermsesnode2,ermsesnode3
- cluster.initial_master_nodes=ermsesnode1,ermsesnode2,ermsesnode3
- cluster.name=es-cluster
#- bootstrap.memory_lock=false
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- esdata2:/usr/share/elasticsearch/data
deploy:
#placement:
# constraints:
# - node.labels.nodetype == InDrive
replicas: 1
restart_policy:
condition: on-failure
volumes:
esdata2:
driver: local
networks:
edoc2_default:
external:
name: macrowingdocker-compose-esnode2.yml
version: '3.3'
services:
ermsesnode2:
hostname: ermsesnode2
image: erms/es
labels:
"type": "2"
networks:
- edoc2_default
ports:
- target: 9200
published: 10010
mode: host
environment:
- node.name=ermsesnode2
- discovery.seed_hosts=ermsesnode1,ermsesnode3
- cluster.initial_master_nodes=ermsesnode1,ermsesnode2,ermsesnode3
- cluster.name=es-cluster
#- bootstrap.memory_lock=false
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- esdata2:/usr/share/elasticsearch/data
deploy:
#placement:
# constraints:
# - node.labels.nodetype == InDrive
replicas: 1
restart_policy:
condition: on-failure
volumes:
esdata2:
driver: local
networks:
edoc2_default:
external:
name: macrowing
docker-compose-esnode3.yml
version: '3.3'
services:
ermsesnode3:
hostname: ermsesnode3
image: erms/es
labels:
"type": "2"
networks:
- edoc2_default
ports:
- target: 9200
published: 10010
mode: host
environment:
- node.name=ermsesnode3
- discovery.seed_hosts=ermsesnode2,ermsesnode1
- cluster.initial_master_nodes=ermsesnode1,ermsesnode2,ermsesnode3
- cluster.name=es-cluster
#- bootstrap.memory_lock=false
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- esdata2:/usr/share/elasticsearch/data
deploy:
#placement:
# constraints:
# - node.labels.nodetype == InDrive
replicas: 1
restart_policy:
condition: on-failure
volumes:
esdata2:
driver: local
networks:
edoc2_default:
external:
name: macrowing-
启动elasticsearch
依次执行三个compose文件,启动es三个节点。(这里是都在leader node(主节点)下执行的,每个服务器执行一个也没事儿。)
[root@elcndc2zhda01 ik]# docker stack deploy -c /data/erms/compose/docker-compose-esnode1.yml erms
Creating service erms_ermsesnode1
[root@elcndc2zhda01 ik]# docker stack deploy -c /data/erms/compose/docker-compose-esnode2.yml erms
Creating service erms_ermsesnode2
[root@elcndc2zhda01 ik]# docker stack deploy -c /data/erms/compose/docker-compose-esnode3.yml erms
Creating service erms_ermsesnode3
[root@elcndc2zhda01 ik]# docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
cmkfhkxjya79 erms_ermsesnode1 replicated 1/1 erms/es:latest
vw0kde788sx4 erms_ermsesnode2 replicated 1/1 erms/es:latest
vrt2jf9qf6d7 erms_ermsesnode3 replicated 1/1 erms/es:latest
[root@elcndc2zhda01 ik]#
一般集群都会添加portainer,可以通过portainer查看一下效果如下,
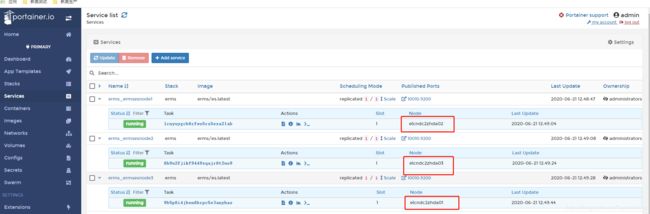
说明,三个es节点分别在swarm集群的三个node上运行的。
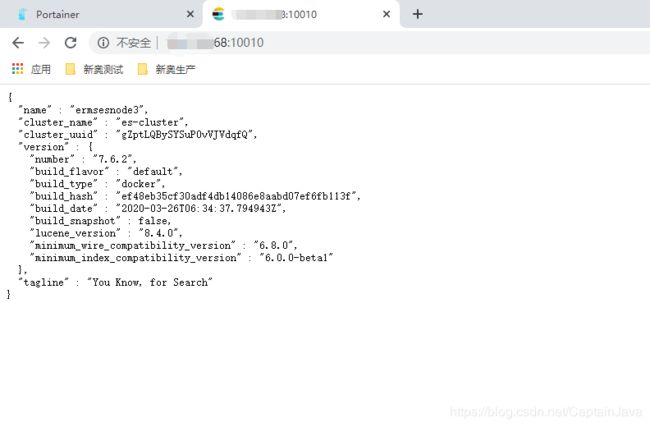
打开浏览器输入其中一个服务器的IP:10010接口访问es如下,即证明es启动成功。
启动kibana
-
创建kibana配置文件
切换到开始时创建的kibana目录
cd /data/erms/es/kinana/创建配置文件kibana.yml,内容如下
#
## ** THIS IS AN AUTO-GENERATED FILE **
##
#
# # Default Kibana configuration for docker target
server.name: kibana
server.host: "0"
#这里写你的es第一个node的地址
elasticsearch.hosts: [ "http://10.**.**.68:10010","http://10.**.**.69:10010","http://10.**.**.70:10010" ]
xpack.monitoring.ui.container.elasticsearch.enabled: true
i18n.locale: zh-CN创建compose文件,kinana-compse.yml,这里kibana启动一个节点就够了,开放端口号为10009。内容如下:
version: '3.3'
services:
kibana:
image: docker.elastic.co/kibana/kibana:7.6.2
container_name: kibana
ports:
- 10009:5601
volumes:
- /etc/localtime:/etc/localtime
- /data/erms/es/kinana/kibana.yml:/usr/share/kibana/config/kibana.yml:rw
networks:
edoc2_default:
external:
name: macrowing-
启动kibana
[root@elcndc2zhda01 kinana]# docker stack deploy -c /data/erms/es/kinana/kinana-compse.yml erms
[root@elcndc2zhda01 kinana]# docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
cmkfhkxjya79 erms_ermsesnode1 replicated 1/1 erms/es:latest
vw0kde788sx4 erms_ermsesnode2 replicated 1/1 erms/es:latest
vrt2jf9qf6d7 erms_ermsesnode3 replicated 1/1 erms/es:latest
2gi11fjxl67k erms_kibana replicated 1/1 docker.elastic.co/kibana/kibana:7.6.2 *:10009->5601/tcp
portainer:
输入集群任意ip:10009连接kibana,第一次进入需要选择,选第二项即可进入一下界面,点击小扳手进入开发工具界面
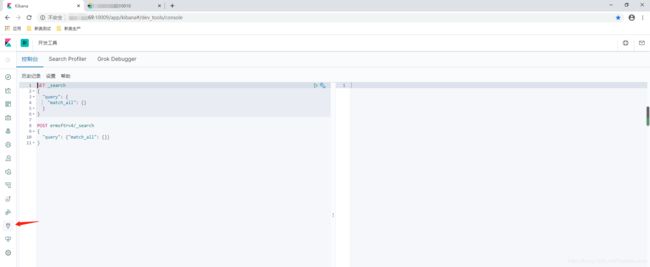
kibana也有监测等实用功能。如果需要安装es head的话,往下看。
启动elasticsearch-head
1、单机运行head
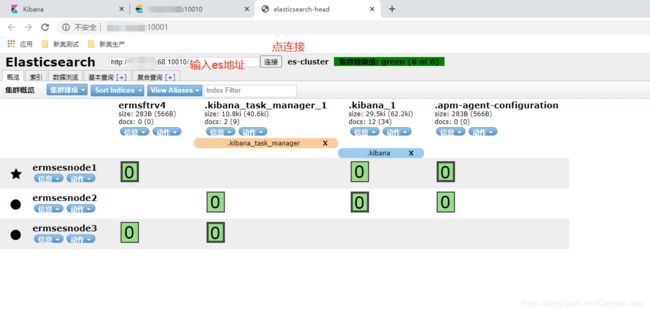
直接docker启动,例如我们在69服务器上执行docker命令,暴露端口号为10001
docker run -d -p 10001:9100 docker.io/mobz/elasticsearch-head:5启动成功后打开浏览器查看69服务器的ip:10001访问head,输入es集群地址点击链接,可以看到集群健康状态、索引以及es和kibana相关信息。
2、集群模式启动
创建eshead-compse.yml
version: '3.3'
services:
elasticsearch-head:
image: mobz/elasticsearch-head:5
container_name: elasticsearch-head
ports:
- "10001:9100"
links:
- ermsesnode1放到集群中启动,
docker stack deploy -c /data/erms/compose/eshead-compse.yml erms查看portainer
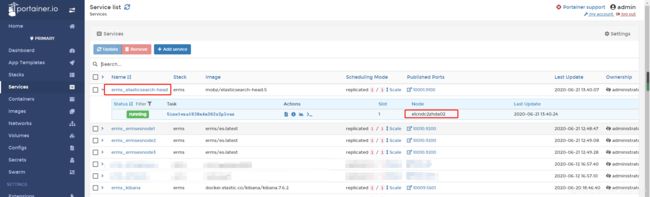
这样,head也被添加到集群中进行管理了。方便维护,并且输入集群任意ip都可以访问到。通过集群域名访问也可以。
使用方式与单机启动一样。
几篇关于elasticsearch的文章:
Java+springboot+elasticsearch7.6.2实现分组查询(平级+层级)并实现script多字段拼接查询以及大于小于等条件关系查询的实现
linux Centos7 安裝搭建elasticsearch7.6.2+kibana7.6.2+中文分词7.6.2详解