Spring IOC 容器源码分析:循环依赖的解决方法
文章目录
- 1 简介
- 2 背景知识
- 2.1 什么是循环依赖
- 2.2 一些缓存的介绍
- 2.3 回顾获取 bean 的过程
- 3 源码分析
- 3.1 创建原始 bean 对象
- 3.2 暴露早期引用
- 3.3 解析依赖
- 3.4 获取早期引用
- 4 总结
1 简介
本文,我们来看一下 Spring 是如何解决循环依赖问题的。在本篇文章中,我会首先向大家介绍一下什么是循环依赖。然后,进入源码分析阶段。为了更好的说明 Spring 解决循环依赖的办法,我将会从获取 bean 的方法getBean(String)开始,把整个调用过程梳理一遍。梳理完后,再来详细分析源码。通过这几步的讲解,希望让大家能够弄懂什么是循环依赖,以及如何解循环依赖。
循环依赖相关的源码本身不是很复杂,不过这里要先介绍大量的前置知识。不然这些源码看起来很简单,但读起来可能却也不知所云。那下面我们先来了解一下什么是循环依赖。
2 背景知识
2.1 什么是循环依赖
所谓的循环依赖是指,A 依赖 B,B 又依赖 A,它们之间形成了循环依赖。或者是 A 依赖 B,B 依赖 C,C 又依赖 A。它们之间的依赖关系如下:

这里以两个类直接相互依赖为例,他们的实现代码可能如下:
public class BeanB {
private BeanA beanA;
// 省略 getter/setter
}
public class BeanA {
private BeanB beanB;
}
配置信息如下:
<bean id="beanA" class="xyz.coolblog.BeanA">
<property name="beanB" ref="beanB"/>
bean>
<bean id="beanB" class="xyz.coolblog.BeanB">
<property name="beanA" ref="beanA"/>
bean>
IOC 容器在读到上面的配置时,会按照顺序,先去实例化 beanA。然后发现 beanA 依赖于 beanB,接在又去实例化 beanB。实例化 beanB 时,发现 beanB 又依赖于 beanA。如果容器不处理循环依赖的话,容器会无限执行上面的流程,直到内存溢出,程序崩溃。当然,Spring 是不会让这种情况发生的。在容器再次发现 beanB 依赖于 beanA 时,容器会获取 beanA 对象的一个早期的引用(early reference),并把这个早期引用注入到 beanB 中,让 beanB 先完成实例化。beanB 完成实例化,beanA 就可以获取到 beanB 的引用,beanA 随之完成实例化。这里大家可能不知道“早期引用”是什么意思,这里先别着急,我会在下一章进行说明。
好了,本章先到这里,我们继续往下看。
2.2 一些缓存的介绍
在进行源码分析前,我们先来看一组缓存的定义。如下:
/** Cache of singleton objects: bean name --> bean instance */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(256);
/** Cache of singleton factories: bean name --> ObjectFactory */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<String, ObjectFactory<?>>(16);
/** Cache of early singleton objects: bean name --> bean instance */
private final Map<String, Object> earlySingletonObjects = new HashMap<String, Object>(16);
根据缓存变量上面的注释,大家应该能大致了解他们的用途。我这里简单说明一下吧:
| 缓存 | 用途 |
|---|---|
singletonObjects |
用于存放完全初始化好的 bean,从该缓存中取出的 bean 可以直接使用 |
earlySingletonObjects |
存放原始的 bean 对象(尚未填充属性),用于解决循环依赖 |
singletonFactories |
存放 bean 工厂对象,用于解决循环依赖 |
上一章提到了”早期引用“,所谓的”早期引用“是指向原始对象的引用。所谓的原始对象是指刚创建好的对象,但还未填充属性。这样讲大家不知道大家听明白了没,不过没听明白也不要紧。简单做个实验就知道了,这里我们先定义一个对象Room:
/** Room 包含了一些电器 */
public class Room {
private String television;
private String airConditioner;
private String refrigerator;
private String washer;
// 省略 getter/setter
}
配置如下:
<bean id="room" class="xyz.coolblog.demo.Room">
<property name="television" value="Xiaomi"/>
<property name="airConditioner" value="Gree"/>
<property name="refrigerator" value="Haier"/>
<property name="washer" value="Siemens"/>
bean>
我们先看一下完全实例化好后的 bean 长什么样的。如下:
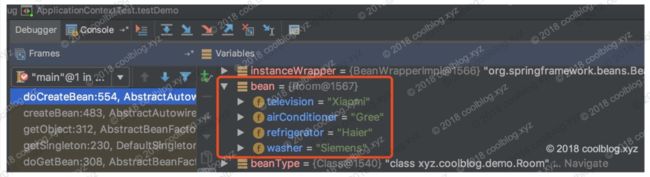
从调试信息中可以看得出,Room的每个成员变量都被赋上值了。然后我们再来看一下“原始的 bean 对象”长的是什么样的,如下:
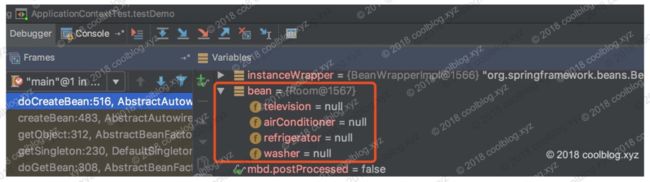
结果比较明显了,所有字段都是null。这里的 bean 和上面的 bean 指向的是同一个对象Room@1567,但现在这个对象所有字段都是null,我们把这种对象成为原始的对象。形象点说,上面的 bean 对象是一个装修好的房子,可以拎包入住了。而这里的 bean 对象还是个毛坯房,还要装修一下(填充属性)才行。
2.3 回顾获取 bean 的过程
本节,我们来了解从 Spring IOC 容器中获取 bean 实例的流程(简化版),这对我们后续的源码分析会有比较大的帮助。先看图:
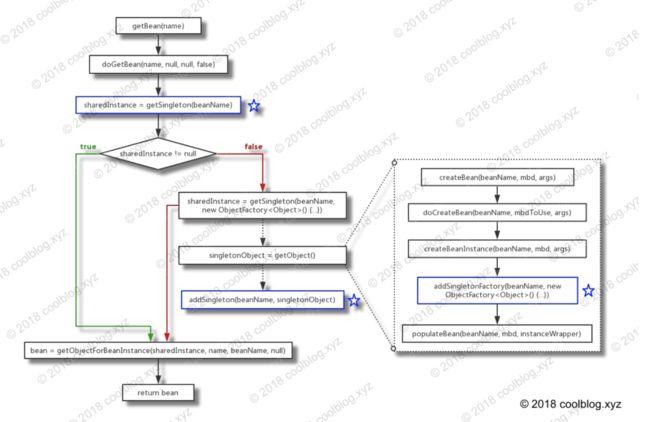
先来简单介绍一下这张图,这张图是一个简化后的流程图。开始流程图中只有一条执行路径,在条件sharedInstance != null这里出现了岔路,形成了绿色和红色两条路径。在上图中,读取/添加缓存的方法我用蓝色的框和 ☆ 标注了出来。至于虚线的箭头,和虚线框里的路径,这个下面会说到。
我来按照上面的图,分析一下整个流程的执行顺序。这个流程从getBean方法开始,getBean是个空壳方法,所有逻辑都在doGetBean方法中。doGetBean首先会调用getSingleton(beanName)方法获取sharedInstance,sharedInstance可能是完全实例化好的 bean,也可能是一个原始的 bean,当然也有可能是null。如果不为null,则走绿色的那条路径。再经getObjectForBeanInstance这一步处理后,绿色的这条执行路径就结束了。
我们再来看一下红色的那条执行路径,也就是sharedInstance = null的情况。在第一次获取某个 bean 的时候,缓存中是没有记录的,所以这个时候要走创建逻辑。上图中的getSingleton(beanName, new ObjectFactory方法会创建一个 bean 实例,上图虚线路径指的是getSingleton方法内部调用的两个方法,其逻辑如下:
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
// 省略部分代码
singletonObject = singletonFactory.getObject();
// ...
addSingleton(beanName, singletonObject);
}
如上所示,getSingleton会在内部先调用getObject方法创建singletonObject,然后再调用addSingleton将singletonObject放入缓存中。getObject在内部调用了createBean方法,createBean方法基本上也属于空壳方法,更多的逻辑是写在doCreateBean方法中的。doCreateBean方法中的逻辑很多,其首先调用了createBeanInstance方法创建了一个原始的 bean 对象,随后调用addSingletonFactory方法向缓存中添加单例 bean 工厂,从该工厂可以获取原始对象的引用,也就是所谓的“早期引用”。再之后,继续调用populateBean方法向原始 bean 对象中填充属性,并解析依赖。getObject执行完成后,会返回完全实例化好的 bean。紧接着再调用addSingleton把完全实例化好的 bean 对象放入缓存中。到这里,红色执行路径差不多也就要结束的。
我这里没有把getObject、addSingleton方法和getSingleton(String, ObjectFactory)并列画在红色的路径里,目的是想简化一下方法的调用栈(都画进来有点复杂)。我们可以进一步简化上面的调用流程,比如下面:

这个流程看起来是不是简单多了,命中缓存走绿色路径,未命中走红色的创建路径。好了,本节先到这。
3 源码分析
好了,经过前面的铺垫,现在我们终于可以深入源码一探究竟了,想必大家已等不及了。那我不卖关子了,下面我们按照方法的调用顺序,依次来看一下循环依赖相关的代码。如下:
protected <T> T doGetBean(
final String name, final Class<T> requiredType, final Object[] args, boolean typeCheckOnly)
throws BeansException {
// ......
// 从缓存中获取 bean 实例
Object sharedInstance = getSingleton(beanName);
// ......
}
public Object getSingleton(String beanName) {
return getSingleton(beanName, true);
}
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 从 singletonObjects 获取实例,singletonObjects 中的实例都是准备好的 bean 实例,可以直接使用
Object singletonObject = this.singletonObjects.get(beanName);
// 判断 beanName 对应的 bean 是否正在创建中
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
// 从 earlySingletonObjects 中获取提前曝光的 bean
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
// 获取相应的 bean 工厂
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 提前曝光 bean 实例(raw bean),用于解决循环依赖
singletonObject = singletonFactory.getObject();
// 将 singletonObject 放入缓存中,并将 singletonFactory 从缓存中移除
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return (singletonObject != NULL_OBJECT ? singletonObject : null);
}
上面的源码中,doGetBean所调用的方法getSingleton(String)是一个空壳方法,其主要逻辑在getSingleton(String, boolean)中。该方法逻辑比较简单,首先从singletonObjects缓存中获取 bean 实例。若未命中,再去earlySingletonObjects缓存中获取原始 bean 实例。如果仍未命中,则从singletonFactory缓存中获取ObjectFactory对象,然后再调用getObject方法获取原始 bean 实例的应用,也就是早期引用。获取成功后,将该实例放入earlySingletonObjects缓存中,并将ObjectFactory对象从singletonFactories移除。看完这个方法,我们再来看看getSingleton(String, ObjectFactory)方法,这个方法也是在doGetBean中被调用的。这次我会把doGetBean的代码多贴一点出来,如下:
protected <T> T doGetBean(
final String name, final Class<T> requiredType, final Object[] args, boolean typeCheckOnly)
throws BeansException {
// ......
Object bean;
// 从缓存中获取 bean 实例
Object sharedInstance = getSingleton(beanName);
// 这里先忽略 args == null 这个条件
if (sharedInstance != null && args == null) {
// 进行后续的处理
bean = getObjectForBeanInstance(sharedInstance, name, beanName, null);
} else {
// ......
// mbd.isSingleton() 用于判断 bean 是否是单例模式
if (mbd.isSingleton()) {
// 再次获取 bean 实例
sharedInstance = getSingleton(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() throws BeansException {
try {
// 创建 bean 实例,createBean 返回的 bean 是完全实例化好的
return createBean(beanName, mbd, args);
} catch (BeansException ex) {
destroySingleton(beanName);
throw ex;
}
}
});
// 进行后续的处理
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}
// ......
}
// ......
// 返回 bean
return (T) bean;
}
这里的代码逻辑和我在「2.3 回顾获取 bean 的过程」一节的最后贴的主流程图已经很接近了,对照那张图和代码中的注释,大家应该可以理解doGetBean方法了。继续往下看:
public Object getSingleton(String beanName, ObjectFactory<?> singletonFactory) {
synchronized (this.singletonObjects) {
// ......
// 调用 getObject 方法创建 bean 实例
singletonObject = singletonFactory.getObject();
newSingleton = true;
if (newSingleton) {
// 添加 bean 到 singletonObjects 缓存中,并从其他集合中将 bean 相关记录移除
addSingleton(beanName, singletonObject);
}
// ......
// 返回 singletonObject
return (singletonObject != NULL_OBJECT ? singletonObject : null);
}
}
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
// 将 映射存入 singletonObjects 中
this.singletonObjects.put(beanName, (singletonObject != null ? singletonObject : NULL_OBJECT));
// 从其他缓存中移除 beanName 相关映射
this.singletonFactories.remove(beanName);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
上面的代码中包含两步操作,第一步操作是调用getObject创建 bean 实例,第二步是调用addSingleton方法将创建好的 bean 放入缓存中。代码逻辑并不复杂,相信大家都能看懂。那么接下来我们继续往下看,这次分析的是doCreateBean中的一些逻辑。如下:
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final Object[] args)
throws BeanCreationException {
BeanWrapper instanceWrapper = null;
// ......
// ☆ 创建 bean 对象,并将 bean 对象包裹在 BeanWrapper 对象中返回
instanceWrapper = createBeanInstance(beanName, mbd, args);
// 从 BeanWrapper 对象中获取 bean 对象,这里的 bean 指向的是一个原始的对象
final Object bean = (instanceWrapper != null ? instanceWrapper.getWrappedInstance() : null);
/*
* earlySingletonExposure 用于表示是否”提前暴露“原始对象的引用,用于解决循环依赖。
* 对于单例 bean,该变量一般为 true。更详细的解释可以参考我之前的文章
*/
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
// ☆ 添加 bean 工厂对象到 singletonFactories 缓存中
addSingletonFactory(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() throws BeansException {
/*
* 获取原始对象的早期引用,在 getEarlyBeanReference 方法中,会执行 AOP
* 相关逻辑。若 bean 未被 AOP 拦截,getEarlyBeanReference 原样返回
* bean,所以大家可以把
* return getEarlyBeanReference(beanName, mbd, bean)
* 等价于:
* return bean;
*/
return getEarlyBeanReference(beanName, mbd, bean);
}
});
}
Object exposedObject = bean;
// ......
// ☆ 填充属性,解析依赖
populateBean(beanName, mbd, instanceWrapper);
// ......
// 返回 bean 实例
return exposedObject;
}
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
synchronized (this.singletonObjects) {
if (!this.singletonObjects.containsKey(beanName)) {
// 将 singletonFactory 添加到 singletonFactories 缓存中
this.singletonFactories.put(beanName, singletonFactory);
// 从其他缓存中移除相关记录,即使没有
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}
上面的代码简化了不少,不过看起来仍有点复杂。好在,上面代码的主线逻辑比较简单,由三个方法组成。如下:
- 创建原始 bean 实例
createBeanInstance(beanName, mbd, args) - 添加原始对象工厂对象到
singletonFactories缓存中addSingletonFactory(beanName, new ObjectFactory - 填充属性,解析依赖
populateBean(beanName, mbd, instanceWrapper)
到这里,本节涉及到的源码就分析完了。可是看完源码后,我们似乎仍然不知道这些源码是如何解决循环依赖问题的。难道本篇文章就到这里了吗?答案是否。下面我来解答这个问题,这里我还是以 BeanA 和 BeanB 两个类相互依赖为例。在上面的方法调用中,有几个关键的地方,下面一一列举出来:
3.1 创建原始 bean 对象
instanceWrapper = createBeanInstance(beanName, mbd, args);
final Object bean = (instanceWrapper != null ? instanceWrapper.getWrappedInstance() : null);
假设 beanA 先被创建,创建后的原始对象为BeanA@1234,上面代码中的 bean 变量指向就是这个对象。
3.2 暴露早期引用
addSingletonFactory(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() throws BeansException {
return getEarlyBeanReference(beanName, mbd, bean);
}
});
beanA 指向的原始对象创建好后,就开始把指向原始对象的引用通过ObjectFactory暴露出去。getEarlyBeanReference方法的第三个参数 bean 指向的正是createBeanInstance方法创建出原始 bean 对象BeanA@1234。
3.3 解析依赖
populateBean(beanName, mbd, instanceWrapper);
populateBean用于向 beanA 这个原始对象中填充属性,当它检测到 beanA 依赖于 beanB 时,会首先去实例化 beanB。beanB 在此方法处也会解析自己的依赖,当它检测到 beanA 这个依赖,于是调用BeanFactry.getBean("beanA")这个方法,从容器中获取 beanA。
3.4 获取早期引用
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
// ☆ 从缓存中获取早期引用
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// ☆ 从 SingletonFactory 中获取早期引用
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return (singletonObject != NULL_OBJECT ? singletonObject : null);
}
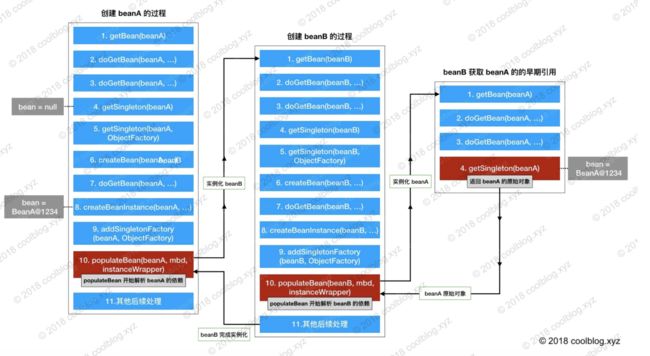
接着上面的步骤讲,populateBean调用BeanFactry.getBean("beanA")以获取 beanB 的依赖。getBean("beanA")会先调用getSingleton("beanA"),尝试从缓存中获取 beanA。此时由于 beanA 还没完全实例化好,于是this.singletonObjects.get("beanA")返回null。接着 this.earlySingletonObjects.get("beanA")也返回空,因为 beanA 早期引用还没放入到这个缓存中。最后调用singletonFactory.getObject()返回singletonObject,此时singletonObject != null。singletonObject指向BeanA@1234,也就是createBeanInstance创建的原始对象。此时 beanB 获取到了这个原始对象的引用,beanB 就能顺利完成实例化。beanB 完成实例化后,beanA 就能获取到 beanB 所指向的实例,beanA 随之也完成了实例化工作。由于beanB.beanA和 beanA 指向的是同一个对象BeanA@1234,所以 beanB 中的 beanA 此时也处于可用状态了。
以上的过程对应下面的流程图:
4 总结
到这里,本篇文章差不多就快写完了,不知道大家看懂了没。这篇文章在前面做了大量的铺垫,然后再进行源码分析。相比于我之前写的几篇文章,本篇文章所对应的源码难度上比之前简单一些。但说实话也不好写,我本来只想简单介绍一下背景知识,然后直接进行源码分析。但是又怕有的朋友看不懂,所以还是用了大篇幅介绍的背景知识。这样写,可能有的朋友觉得比较啰嗦。但是考虑到大家的水平不一,为了保证让大家能够更好的理解,所以还是尽量写的详细一点。本篇文章总的来说写的还是有点累的,花了一些心思思考怎么安排章节顺序,怎么简化代码和画图。如果大家看完这篇文章,觉得还不错的话,不妨给个赞吧,也算是对我的鼓励吧。
由于个人的技术能力有限,若文章有错误不妥之处,欢迎大家指出来。好了,本篇文章到此结束,谢谢大家的阅读。