Hadoop HA高可用集群搭建
之前我们搭建了hdfs集群环境,但是这个存在单点问题和内存限制,并不是高可用的,这一节我们就来搭建高可用HDFS集群。
亲自试验过可以做到单点故障切换!
HDFS2.x HA
解决HDFS1.0中单点故障和内存受限问题:
随着数据越来越多,NameNode的内存使用会暴增而受限,且一个集群中只有一个NameNode,一旦宕机则集群不可用。
解决NameNode单点故障:
HDFS HA:通过主备NameNode解决,如果主NameNode发生故障,则切换到备NameNode上
解决NameNode内存受限问题:
HDFS Federation(联邦,使用较少,官方提供的内存受限解决办法,用起来独立的,其实在一个集群中)
NameNode HA:
- 水平扩展,支持多个NameNode
- 每一个NameNode分管一部分目录
- 所有NameNode共享所有DataNode存储资源
2.x只是架构上发生了变化,使用方式不变。
对HDFS使用者透明
HDFS 1.x中的命令和API仍可以使用
【HA】集群
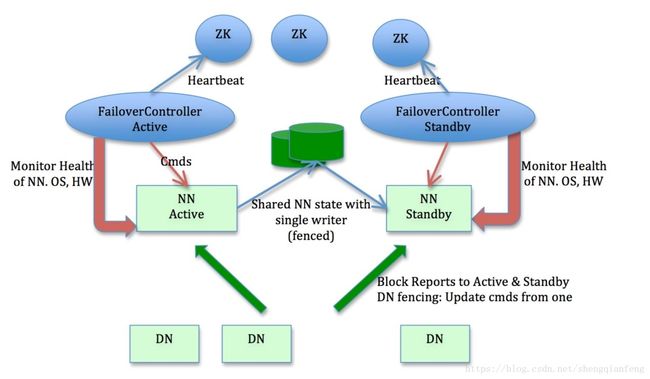
在企业中基本90%都会用到HA,很少用联邦。
假设集群中只有两个NameNode,而一个集群中只能有一个工作的nameNode,成为Active NN,而其他NameNode称为Standby NN.而Standby功能是来接管Active NN,也就是接管NN的所有功能。
NN有两大功能:1 接收客户端的读写服务。2 NN可以存放元数据
元数据:有两种,一个fsimage,一个edits。
NameNode第一次初始化产生metadata元数据fsimage的时间,是在NameNode执行Format格式化命令的时候。此时hdfs还没有启动。
Fsimage同步
提问:
假如Active和Standby两个NN都格式化format了,因为格式化是根据当前系统时间(毫秒级别,不可能一模一样)和系统环境来初始化fsimage,他们的id号是不一样的。所以他们的fsimage数据是不一样的。那么Standby到时候接管Active的fsimage元数据不一样该怎么办?
解决办法:是让其中一个NN格式化后得到的fsimage,另外一个NN就一定不要格式化了,直接拷贝已经格式化的元数据即可。这就保证两个NN的fsimage元数据一模一样,到时候为接管提供条件。
最初在Active NameNode产生的edits元数据日志文件(edits文件是客户端对文件进行增删改查时实时产生的),当activeNN瞬间挂掉的时候,standbyNN也是没有edits文件的,一样不能接管成功!怎么办?办法是edits共享。
Edits共享
解决办法:将edits文件共享,不要保存在是Active NN中,而要保存在共享的磁盘中。
但是这样做不好地方在于共享的机器挂掉的话,还是不能解决问题。
所以,最好的解决办法是:
当内存元数据有增删改查的时候,edits日志上传到一个叫JN(JournalNode)的集群中,只要集群中任何一台机器有edits文件,则edits数据就不会丢失,edits与fsimage合并也是JN帮我们做。
JN在进行edits与fsimage合并的时候,需要注意的是:
JN集群须要合并两个NameNode(active主和standby备)的fsimage,因为standby NN要保证随时能接管active NN,所以两个fsimage要保证同步。
当Active瞬间挂掉的时候,standbyNN瞬间接管,之后它的edits日志也会写到JournalNode集群中。
细节
1 JournalNode会合并fsimage和edits,但是它同时合并active和standby两个fsimage,以保证两个NN的fsimage元数据一致。
2 DataNode启动的时候汇报自己的位置信息给NN,一样要同时向active和standby汇报,因为两个NameNode都需要block的位置信息,从而保证可以实现瞬间接管。
3 综上,active和standby不同之处仅仅在于,standby因为不是活动的,所以不接收客户端的读写请求。但是standby的元数据fsimage是一模一样的!
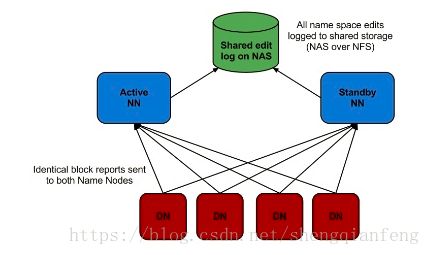
总结一下:
- 怎么保证两个NameNode的fsimage一模一样?
答:首先,Active NameNode格式化的时候生成的fsimage会拷贝到standby NameNode。
其次,DataNode启动时汇报自己的位置信息给active和standby两个NameNode。
第三,active NameNode的edits文件上报给了JN集群,JN集群同时合并active和standby两个NameNode的两个fsimage文件。
系统启动的时候必须选择出谁是ActiveNN,谁是standbyNN。通过zk选举实现。
- FailOverController怎么借助ZK进行故障转移的?
答:1 FailOverController节点帮助集群切换NameNode状态从standy切换为active,FailOverController和NameNode一一对应,就是active和standy各有一个FailOverController节点。
2 FailOverController对NameNode做健康检查,如果active NN出现宕机则汇报给zk集群,zk集群从standby NN中选择一台作为Active NN。
Tips:即使没有zk,我们也可以使用命令的方式切换NameNode。
搭建zk环境参考:https://blog.csdn.net/shengqianfeng/article/details/79513067
修改原HADOOP集群---搭建HDFS HA
停止hadoop进程:
#stop-dfs.sh
通过jps命令验证三台是否都停止!
删除masters
删除NAMENode(node1)节点的masters
由于hdfs HA不再需要SecondrayNameNode做为辅助NameNode进行fsimage跟edits日志合并,所以删除掉。
# cd /root/hadoop-2.5.1/etc/hadoop
# rm –rf masters
删除原集群数据
删除原来的数据文件
rm -rf /opt/hadoop-2.5
core-site.xml
fs.defaultFS
hdfs://laoxiang
hadoop.tmp.dir
/opt/hadoop-2.5
ha.zookeeper.quorum
node1:2181,node2:2181,node3:2181
hdfs-site.xml
编辑 hdfs-site.xml
#vi hdfs-site.xml删除
dfs.nameservices
laoxiang
dfs.ha.namenodes.laoxiang
nn1,nn2
dfs.namenode.rpc-address.laoxiang.nn1
node1:8020
dfs.namenode.rpc-address.laoxiang.nn2
node4:8020
dfs.namenode.http-address.laoxiang.nn1
node1:50070
dfs.namenode.http-address.laoxiang.nn2
node4:50070
dfs.namenode.shared.edits.dir
qjournal://node2:8485;node3:8485;node4:8485/abc
dfs.client.failover.proxy.provider.laoxiang
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_dsa
dfs.journalnode.edits.dir
/opt/journalnode
dfs.ha.automatic-failover.enabled
true
拷贝HA集群配置文件
配置完成后,拷贝node1配置文件到node2、node3、node4
scp ./* root@node2:/root/hadoop-2.5.1/etc/hadoop/
scp ./* root@node3:/root/hadoop-2.5.1/etc/hadoop/
scp ./* root@node4:/root/hadoop-2.5.1/etc/hadoop/
启动journalnode集群
启动单节点node2、node3、node4上的journalnode:
#hadoop-daemon.sh start journalnode
# tail -200 /root/hadoop-2.5.1/logs/hadoop-root-journalnode-node2.log查看日志,没报错!
Node2、node3、node4都要启动
格式化NN
同步node1和node4两个namenode的fsimage元数据:
注意前提是启动JournalNode才能格式化,两个nn任选一个即可,我选node4:
#hdfs namenode -format报错!原来是node4没有设置到node2、node3、node4的免登录!
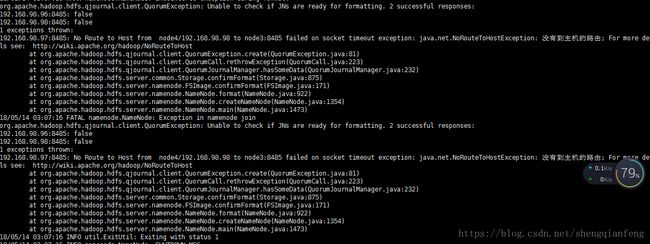
重新格式化!成功!
拷贝fsimage
拷贝node4的fsimage文件到node1
切换到node1机器进行拷贝fsimage
# scp -r root@node4:/opt/hadoop-2.5 /opt
另一种方法:
启动刚刚格式化的namenode:
#hadoop-daemon.sh start namenode在没有格式化的namenode上执行:
#hdfs namenode –bootstrapStandby启动第二个namenode
Tips:启动单个datanode命令:
#hadoop-daemon.sh start datenode
格式化ZK
初始化hdfs hA在zk中的状态:
#hdfs zkfc -formatZK只要在任何一个namenode上执行即可,我选择node1
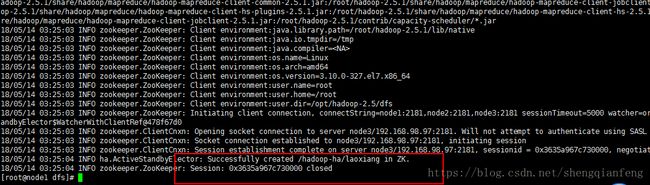
OK!
启动HA集群
#关闭全部节点
stop-dfs.sh我们启动node1:
#start-dfs.sh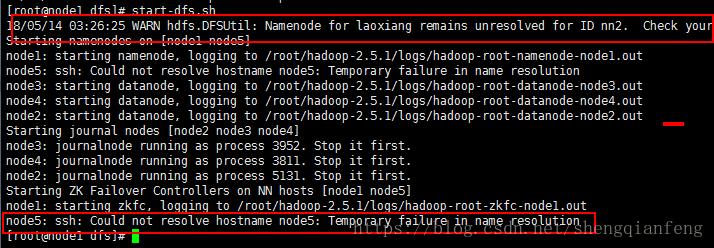
报了两个错误!修改hdfs-site.xml文件
stop-dfs.sh,重启!
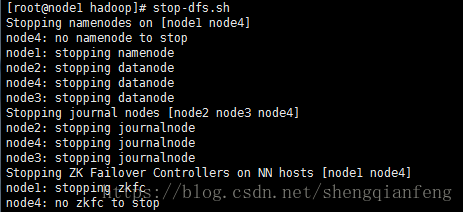
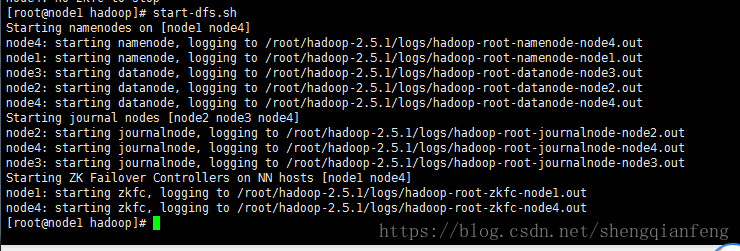
成功启动,没报错!
测试并验证故障转移
打开浏览器:http://node1.50070/
active
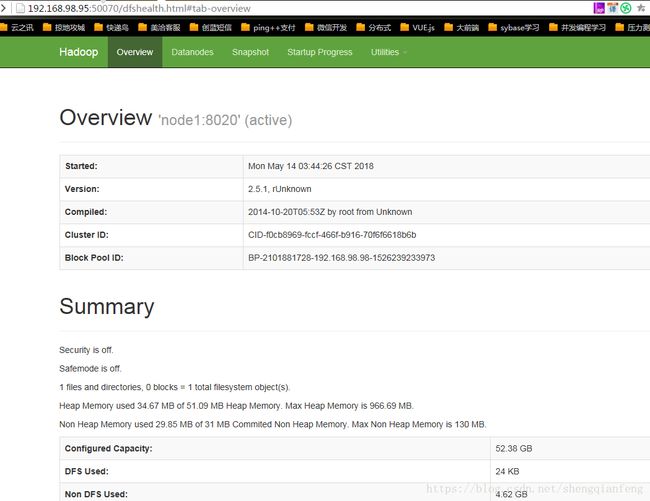
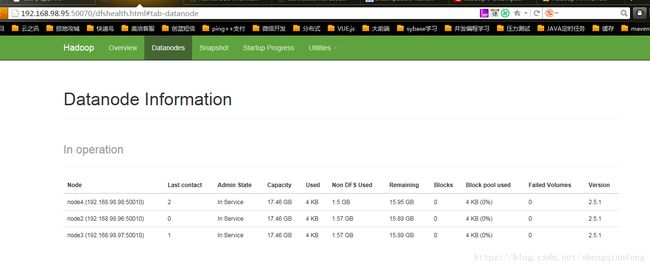
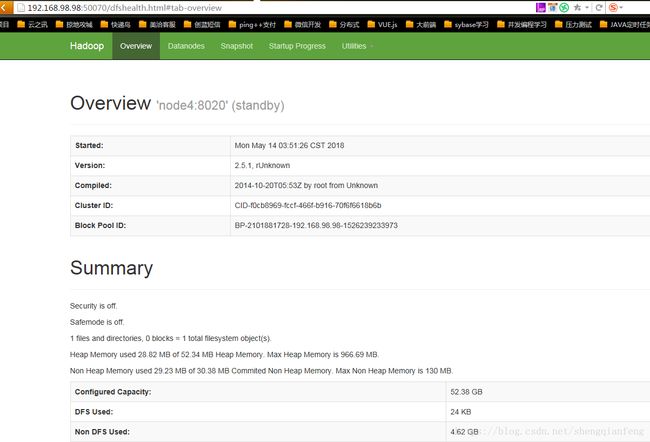
访问: http://192.168.98.98.50070/
standby
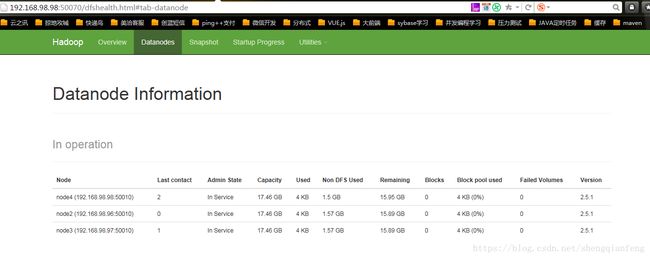
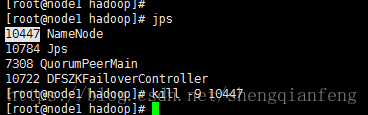
Kill掉node1的namenode,看下是否会切换到node4
可以看到已经切换了:
之前一直出现缺少fuser命令,可以安装
#yum provides "*/fuser"
#yum -y install psmisc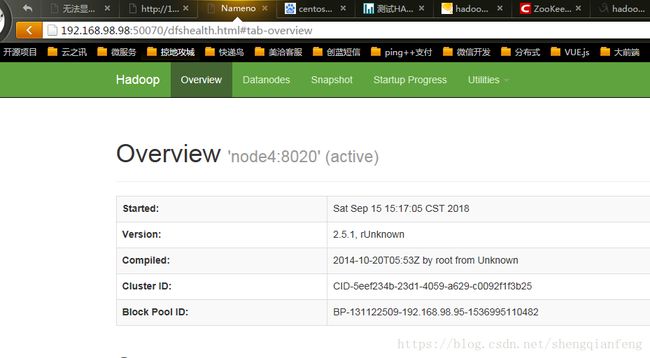
然后我们把node1启动起来:
#hadoop-daemon.sh start namenode
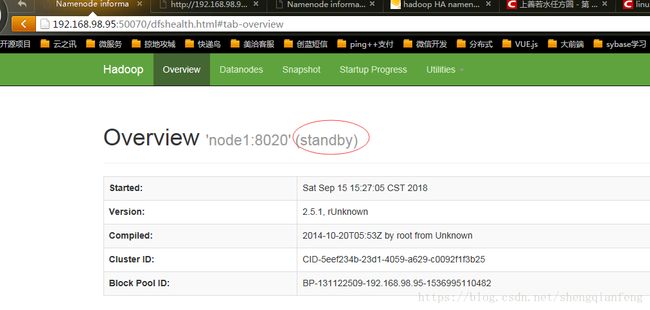
依然是standby状态,虽然之前是active,但是再次启动不会再变成active
手动命令
#hdfs haadmin
-transitionToActive:将nameNode变成Avtive
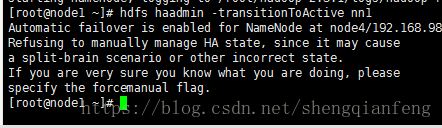
拒绝,告诉我们要关闭自动切换才能使用
-transitionToStandby:将namenode变成standby
-failover:同样是手动切换
-getServiceState:获得原始状态
-checkHealth:健康检查
【Federation】联邦集群
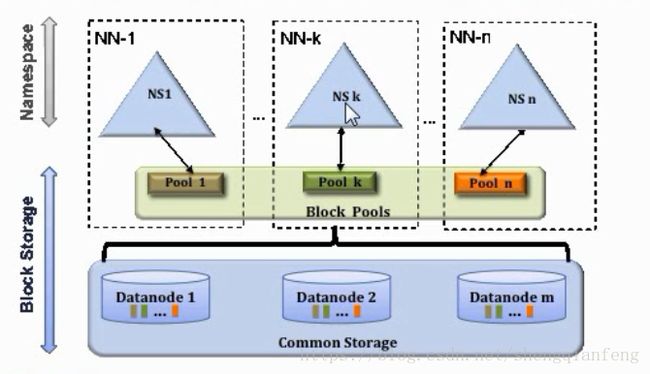
三个独立的NN联合在一起组成一个大的集群,所有NN共享DataNode,每个NN可以配置“HA“方式。
参考:http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/Federation.html