深入理解 OpenStack Neutron:VXLAN

3.8 VXLAN
终于用上了这张图:

老爷子,鸡年大吉!
好吧,我们言归正传!(老爷子说:把“好”字去掉,^_^)
3.8.1 VXLAN 简介
VXLAN,Virtual eXtensible Local Area Network,表面的理解,是对 VLAN 的扩展。我们知道,VLAN ID,12 bits,最大4K(4096),在当前云时代,已经不足以承担租户隔离的重任了(太少了)。而 VXLAN,简单地说,将 12 bits 扩展到 24 bits,这样其数值就达到了 1600 万(16777216,4096 * 4096) ,暂时应该够用了。当然,VXLAN 可不是如此简单,我们下文会描述,这里先暂时不用纠结。
VXLAN,由 Storvisor,Cumulus Networks,Arista,Broadcom,Cisco,VMware,Intel,Red Hat 等8家公司,于 2014.8 提交草案“ draft-mahalingam-dutt-dcops-vxlan”(RFC7348,2011.8 启动,2014.8 发布 1.0 版本)
按照 RFC7348的说法,VXLAN 的提出,期望解决三个问题:
(1)Limitations Imposed by Spanning Tree and VLAN Ranges;
(2)Multi-tenant Environments;
(3)Inadequate Table Sizes at ToR Switch。
我们暂且不深究这三个问题,就当作只有一个问题:VLAN 数量不够了,需要扩展。等我们掌握了 VXLAN 的基本知识,再回头看这三个问题,就会事半功倍!
VXLAN 从报文结构上来讲,可以理解为 MAC in UDP。我们这里暂时只给一个示意,待到后面再详细描述这个报文结构,如下图所示:
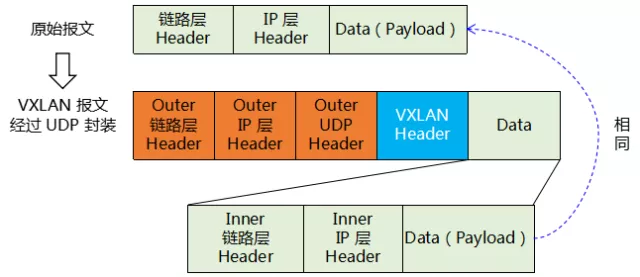
图1 VXLAN 报文结构示意图
如图,我们看到,VXLAN 就是在原来的报文头前面封装上一个新的“UDP Header”再加上一个 VXLAN Header。(UDP Header 包括 链路层 Header, IP 层 Header, UDP 层Header,可不要误解了)。由于链路层 Header 最主要的字段就是 MAC 地址,所以,我们有时候也称 VXLAN 为“MAC in UDP”。
3.8.2 VXLAN 概念模型
直接上图:

图2 VXLAN 概念模型
按道理来说,概念模型图应该画得抽象一点,可是这个图画的一点都不抽象。且听笔者一一道来:
DC:图中画了三个 DC(Data Center,数据中心),但是 VXLAN 可以在一个 DC 内,也可以在不同的 DC 间。从抽象的角度讲,VXLAN 不是说一定要跨越 DC。在一个 DC 内和跨越 DC,各有不同的场景。
L3 Network:只能说这是一个三层网络,不能说这个 L3 就一定是 Internet,也可以就是一个 DC 内的网络。
VM:VM(Visual Machine,虚拟机),图中只是一个示意,画出了一个 Host 内的 VM。实际 VM,当然会有很多。另外,从抽象的角度来讲,不是 VM,就仅仅是 Host,也未尝不可。只是,从使用场景来说,现在大家都说云,不谈 VM,好像不合适,^_^
VTEP:VTEP(VXLAN Tunnel End Point,VXLAN 隧道终结点,An entity that originates and/or terminates VXLAN tunnels,是一个 VXLAN 隧道的发起或终结点。),从实现角度来讲,是 VXLAN 里最重要的模型。前面的模型,都是使用场景相关,这个模型,承载了 VXLAN 的实现。图中,VTEP 体现在了 HOST 中的 vSWitch(OVS,Open Visual Switch),在实际使用场景中,VTEP 也可以由 ToR(Top of Rack,机架交换机,一般位于机架顶部,所以称为 ToR)实现。
VNI:VNI(VXLAN Network Identifier (or VXLAN Segment ID)),标识一个 VXLAN 网段(可以对比理解为 VLAN ID),24 bits,最大值是16777216(16 M)。
VSI:VSI(Virtual Switching Instance,虚拟交换实例),VTEP上为一个VXLAN网络提供二层交换服务的虚拟交换实例。VSI可以看作是VTEP上的一台基于VXLAN进行二层转发的虚拟交换机。
一个 VTEP 上可以创建多个 VSI。一个 VSI 与一个 VXLAN 网段(VNI)一一对应。不过我们在以后的描述中,为了叙述的方便,如无特别说明,VTEP 指的是 一个 VTEP 上对应的 VSI。
下面我们重点描述一下 VTEP。
VTEP,有几个功能,如图所示:

图3 VTEP 功能示意图
图中,VM1,VM2,属于同一个 VXLAN,VNI = 100;VM3,VM4 属于 VNI = 200。VM1 发送报文给 VM2。
当 VM1 发送的报文到达 VTEP1 后,VTEP1 会做两件事情:
(1)封装为 VXLAN 报文
(2)三层转发到 VTEP2
当 VTEP2 接收到 VTEP1 发送过来的报文后,VTEP2 会做两件事情:
(1)解封装,还原为原始报文(VM1 发送的原始报文)
(2)转发到 VM2。
所以我们总结一下 VTEP 的几个功能:
l 封装/解封装 VXLAN
l VXLAN 报文转发(图中对应的是“普通 L3 接口(UDP)”)
l 普通二层报文转发(图中对应的是“普通 L2 接口(比如 VLAN)”)
这里特别说明一下,“普通二层转发”,通过 VLAN 转发也可以,没有 VLAN,就是普通的 MAC 转发也可以,只是现在好像都习惯添加一个 VLAN。
具体到 OVS(或者其他 VTEP 应该也是这样的),这个 VLAN 是 OVS 自己分配的(需要给 OVS 分配一个 VLAN 范围),它只是把一个 HOST 内的 VM,属于同一个 VNI 的,分配为相同的 VLAN ID 即可。前段时间,有童鞋问我:VNI 的范围是 16M,而 VLAN ID 的范围只有 4K,这也没法映射啊。我们讲,在一个 HOST 内的 VM 是有限的,至少目前的技术来讲,远远小于 4K,所以这个映射是可以的。
在上述的介绍中,我们忽略了几个问题:(1)具体的报文格式到底是什么?(2)VM1 发送报文给 VM2,它是如何知道 VM2 的 MAC 地址的?(3)VTEP1 怎么知道是将报文转发给 VTEP2 的,而不是其他 VTEP?
这些问题,我们将在下面的章节讲述。
3.8.3 VXLAN 的转发
转发有两个重要的步骤:转发表的查找(决定从哪个接口转发出去),报文的封装和转发。转发表的查找本身并不复杂,但是转发表涉及控制层面(转发表如何构建),所以这个我们放到下一小节再讲述。这一小节主要讲述报文的封装(即 VXLAN 报文格式)和转发。
3.8.3.1 VXLAN 报文格式
前面 VXLAN 概念模型中,简单讲述了 VXLAN 报文格式,我们这里重贴一下:

图4 VXLAN 报文结构示意图
这里面这些外层的“链路层 Header、IP 层 Header、UDP Header”,其报文结构就是普通的 TCP/IP 报文结构,没有什么特别的,关键是里面的字段的赋值,应该赋何值。
为了能更清晰的讲述,我们先给出一个简化的 VXLAN 转发示意图:
图5 VXLAN 转发示意图
我们基于这张图,分别描述 VXLAN 封装的几个报文结构:Outer 链路层 Header、Outer IP 层 Header、Outer UDP Header、VXLAN Header。
3.8.3.1.1 Outer Ethernet Header
直接上图:
图6 Outer Ethernet Header 报文结构
直接上表
| 字段 |
位数(bit) |
含义 |
备注 |
| Dst. MAC Addr. |
48 |
目的 MAC 地址,在图中,就是路由器 R 的 MAC 地址。 |
|
| Src. MAC Addr. |
48 |
源 MAC 地址,在图中,就是 VTEP1 的 MAC 地址。 |
|
| TPID |
16 |
Tag Protocol ID,标签协议标识,其值为0x8100时表示802.1Q/802.1P的帧 |
|
| User Priority |
3 |
User Priority,表示帧的优先级,取值范围0~7,值越大优先级越高,用于802.1P |
图中用“U”标识 |
| CFI |
1 |
CFI,值为0代表MAC地址是以太帧的MAC,值为1代表MAC地址是FDDI、令牌环网的帧。 |
图中用“C”标识 |
| VID |
12 |
表示VLAN的值。12bit共可以表示4096个VLAN,实际上,由于VID 0和4095被802.1Q协议保留,所以VLAN的最大个数是4094(1-4094)个 |
|
| Ethernet Type |
16 |
部分 Ethernet Type 枚举如下: 0x080: IPv4 0x0806:ARP 0x8100:EEE 802.1Q 0x86DD:IPv6 0x 8864:PPPoE |
表1 Outer Ethernet Header 报文结构
说明:VLAN TAG:4字节,包含2个字节的标签协议标识(TPID)和2个字节的标签控制信息(TCI),TCI字段具体又分为: User Priorty、CFI、Vlan ID。VLAN TAG 是可选字段。
3.8.3.1.2 Outer IPv4 Header
是的,这是 IPv4,不是 IPv6!我们直接上图:
图7 Outer IPv4 Header 报文结构
直接上表:
| 字段 |
位数(bit) |
含义 |
备注 |
| Version |
4 |
IP 版本号,0100表示IPv4,0110表示IPv6 |
|
| IHL |
4 |
Internet Header Length,就是这个 IPv4 Header 的长度(长度单位是 4 byte)。如果 IPv4 Header 没有可选项(图中没有画出可选项),那么 IHL = 5(即 5 * 4 = 20 bytes。您可以数一数,上图中的长度,就是 20 bytes) |
|
| TOS |
8 |
Type of Servcie,服务类型,表明服务质量特征。笔者不再啰嗦,读者如果感兴趣,可以参阅后面笔者给出的参考资料。 |
|
| Total Length |
16 |
整个 IP 数据报的长度(含 IP Header,不含前面的 Ethernet Header),长度单位是 byte |
|
| Identification |
16 |
唯一地标识主机发送的每一份数据报文 |
|
| Flags |
3 |
感兴趣的童鞋,请阅读参考资料,笔者在这里就不刷屏了 |
|
| Fragment Offset |
13 |
同上 |
|
| TTL |
8 |
同上 |
|
| Protocol |
8 |
指明IP层所封装的上层协议类型,如ICMP(1)、IGMP(2) 、TCP(6)、UDP(17)等。 |
|
| Header Checksum |
16 |
是根据IP头部计算得到的校验和码 |
|
| Src. IP |
32 |
源 IP,这里指的是 VTEP1 的 IP 地址(1.1.1.1) |
|
| Dst. IP |
32 |
目的 IP,这里指的是 VTEP2 的 IP 地址(2.2.2.1) |
表2 Outer IPv4 Header 报文结构
【注】感兴趣的读者,可以阅读“http://wenku.baidu.com/link?url=cEm7Ps_g_K9AYMO6DhXmRBsYSlLtgX9GtIcyrRkA_Rjpq0-ApCMGMzJRsRHizYeOnMIwegrmclKQPMH2Ki3wIxieTxkpQ4J-i9QYvKkY-oa”,以了解这些字段更详细的知识。这是一篇有良心的文章,写得比较详细。
3.8.2.1.3 Outer UDP Header
直接上图:
图8 Outer UDP Header 报文结构
直接上表:
| 字段 |
位数(bit) |
含义 |
备注 |
| Src. Port |
16 |
源端口号。RFC7348 推荐了这个源端口号的赋值(计算)方法,笔者不以为然,觉得太啰嗦。不过笔者还是把这一段贴出来吧,请您字节判断:It is recommended that the UDP source port number be calculated using a hash of fields from the inner packet --one example being a hash of the inner Ethernet frame's headers. This is to enable a level of entropy for the ECMP/load-balancing of the VM-to-VM traffic across the VXLAN overlay. When calculating the UDP source port number in this manner, it is RECOMMENDED that the value be in the dynamic/private port range 49152-65535 |
|
| Dst. Port |
16 |
这个是专门向 IANA(The Internet Assigned Numbers Authority,互联网数字分配机构) 申请的一个端口号 4789,专门标识是 VXLAN。 |
|
| UDP Length |
16 |
UDP 报文长度(含 UDP Header, 不包含前面的 Ethernet Header 和 IP Header),长度单位是 byte。 |
|
| UDP Checksum |
16 |
简单理解,直接填0即可。也可以真的计算这个校验和,具体请参考 RFC7348 |
表3 Outer UDP Header 报文结构
3.8.2.1.4 VXLAN Header
直接上图:
图9 VXLAN Header 报文结构
直接上表:
| 字段 |
位数(bit) |
含义 |
备注 |
| RI |
8 |
RRRRIRRR:I 必须为1,表示 VNI 字段是一个有效的 VNI;R 必须为0,暂时没啥用。 |
|
| Reserved |
24 |
保留字段,必须为0 |
|
| VNI |
24 |
费了半天劲,就是为了这个字段,表示一个 VXLAN 网段。 |
|
| Reserved |
8 |
保留字段,必须为0 |
表4 VXLAN Header 报文结构
3.8.2.1.5 VXLAN 报文格式小结
前面介绍了 VXLAN 报文的封装,这些报文封装,可以简单地理解(不是很精确,但是方便记忆)为:源 IP 是本端 VTEP,目的 IP 是对端 VTEP,再加上一个 VNI,欧了!
VXLAN 报文封装以后,再把原来的报文放在后面,即可。
3.8.3.2 VXLAN 的报文转发
我们前面已经介绍过 VXLAN 的报文转发,这里再简单重复一下,如下图所示:
图10 VXLAN 报文转发
VTEP1 接到 VM1 发送给 VM2 的报文后,做几件事情:
(1)查表(图中,给出了 VTEP 二层转发表的一个事宜):(a)判断两个家伙(VM1,VM2)是不是属于一个 VNI(不是的话,就 drop 这个报文);(b)查到对端 VTEP 的 IP 地址
(2)封装:如图所示,封装为 VXLAN 报文
(3)转发:根据对端 VTEP IP 地址,走三层转发(这个时候还需要查找路由表,不过这个不在本章节范围内,略过不表)
VTEP2 接到 VTEP1 转发过来(中间经过了 L3 Network)的报文后,做几件事情:
(1)解封装
(2)根据普通的二层转发(MAC/VLAN 转发),转发给 VM2。
3.8.4 VXLAN 的“控制面”
我们在上一小节提到了查表:查找二层转发表。这个二层转发表是如何构建的呢?这就涉及到了VXLAN 的“控制面”:“控制面”负责构建这个二层转发表。
但是,我将这个“控制面”打了引号,那是因为,VXLAN 构建这个二层转发表的方法有几种,并不完全都是经过控制面(这个时候,控制面没有打引号)来构建的。这些方法有:
(1)通过数据面学习(这就不是控制面板)
(2)通过 MP-BGP(EVPN)通告,这个是独立的控制面。不过抱歉,这个我们不在本章介绍,留待下一章“EVPN”再介绍
(3)通过那个啥都能“SDN”,这个也是一个独立的控制面。同样抱歉,这个放到以后相关章节再介绍。
本文只介绍 VXLAN 如何通过数据面进行二层转发表的构建。我们以一个具体的例子来讲述这个过程。例子的组网图,如下图所示:
图11 一个通过数据面构建转发表的例子(组网图)
图中,VM1,VM2,VM3,分别通过 VTEP1,VTEP2,VTEP3,构建为一个 VXLAN 网段,VNI = 100。三个虚拟机的 IP 地址如图所示,都在一个 subnet(10.1.1.0/24)。现在 VM1 要与 VM2 通信。
另外补充说明:VTEP知道自己都在一个 VNI = 100 的 VXLAN 网段中,并且 VTEP 知道它下挂的哪些 VM 在这个 VNI 中,这些都是靠“人工”配置的(有的通过命令行,有的通过函数调用,不细究,反正是“人工”配置,没办法自己学习。)
VM1 要与 VM2 通信,前提条件:VM1 知道 VM2 的 IP地址——IP 地址都不知道,那就不聊了。
VM1 与 VM2 通信的第一个问题是:VM2 的 MAC 地址是啥?呵呵,一上来就懵逼,^_^。
VM1 解决这个问题的方法,就是采用正常的 ARP。
(1)VM1 把这个 ARP 报文发给 VTEP1,VTEP1 做两件事情:
l VTEP1 通过这个 ARP 报文,学习到了 VM1 的 MAC 地址(呵呵,很鸡贼啊,^_^)
l VTEP1 将这个 ARP 报文,进行 VXLAN 封装(参见前面章节),分别转发到 VTEP2 和 VTEP3(这种行为叫头端复制)。
上述两个过程如下图所示:
图12 VTEP1 的学习和头端复制
(2)VTEP3 接到 VTEP1 转发过来的 ARP(经过 VXLAN 封装) 报文后,做如下几件事情:
l 解封装
l 发现是 ARP 报文,顺便学习一下 VM1 的 MAC 地址,^_^
l 将原始的 ARP 报文转发给其下挂的虚拟机,VM3
(3)VM3 收到进过千山万水转发过来的原始 ARP 报文后:
l 发现是 ARP 报文,顺便学习一下 VM1 的 MAC 地址,^_^
l 发现 IP 地址不是自己,丢弃这个报文
以上过程,如下图所示:
图13 VTEP3 和 VM3 的学习
(4)VTEP2 接到 VTEP1 转发过来的 ARP(经过 VXLAN 封装) 报文后,做如下几件事情:
l 解封装
l 发现是 ARP 报文,顺便学习一下 VM1 的 MAC 地址,^_^
l 将原始的 ARP 报文转发给其下挂的虚拟机,VM2
(5)VM2 收到进过千山万水转发过来的原始 ARP 报文后:
l 发现是 ARP 报文,顺便学习一下 VM1 的 MAC 地址,^_^
l 发现 IP 地址是自己,应答这个 ARP
(6)VTEP2 收到这个 ARP 应答报文后,做如下几件事情:
l 学习到 VM2 的 MAC 地址
l 封装,转发给 VTEP1
以上过程,如下图所示:
----------------------------------------------------------------
图14 VTEP2 & VM2 学习与应答
(7) VTEP1 收到 VTEP2 转发过来的 ARP reply 报文后,做如下几件事情:
l 解封装
l 发现是 ARP Reply报文,顺便学习一下 VM2 的 MAC 地址,^_^
l 将原始的 ARP Reply 报文转发给其下挂的虚拟机,VM1
(8)VM1 收到 转发过来的 VM2 的 ARP Reply 报文,就学习到了 VM2 的 MAC 地址。
以上过程,如下图所示:
图15 VTEP1 和 VM1 的学习
通过以上过程,我们看到:
l VTEP1,VTEP2,VTEP3,学习到了 VM1 的 MAC 地址
l VTEP2,VTEP3,学习到了 VM1 MAC 地址所对应的 VTEP(VTEP1)
l VTEP1,VTEP2 学习到了 VM2 的 MAC 地址
l VTEP1 学习到了 VM2 MAC 地址所对应的 VTEP(VTEP2)
l VM2,VM3 学习到了 VM1 的 MAC 地址
l VM1 学习到了 VM2 的 MAC 地址
这就是 VXLAN 通过数据面的学习(也叫 flood & learning,也叫 source mac learning),而达到“控制面”的功能
最后补一句,或者补一刀:很多数据中心,都不允许这种方式进行 MAC 地址学习!不允许!
所以,SDN 或者 MP-BGP(EVPN) 还是必要的,这个我们留待后面的章节描述!
深度探索 OpenStack Neutron:Neutron 逻辑模型(1)
【说明:阅读本篇文章,需要一定的预备知识“Neutron 网络实现模型”。关注微信公众号“标哥说天下”,回复“NMI” 或者 “nmi”,可以获取该文章。】
第五章 Neutron 逻辑模型
这一章的写作,对我来说,太有挑战。因为 OpenStack 有官网介绍它的 RESTful API。而这些 API 的介绍,就是基于 Neutron 逻辑模型的 CRUD(Create,Retrieve,Update,Delete,增加/查询/修改/删除)讲述。这意味着什么?这意味着官网是“模型 + CRUD”一起介绍,而我这里仅仅介绍模型,我的内心是几乎崩溃的,^_^

好吧,让我们来一场冒险之旅,看看我的功力到底如何,能不能在有官方 wiki 的基础上,写下一篇不一样的文章。

【版权统一申明】不能否认也没法避免,本章统一参考 OpenStack 关于 Neutron API 的官网:https://developer.openstack.org/api-ref/networking/v2/?expanded=list-floating-ips-detail,show-subnet-details-detail 。
笔者也强烈建议您阅读该网页。
Neutron 把网络相关的逻辑模型,分为如下几个部分:
Layer2 Networking,Layer3 Networking,Security,Resource Management,QoS,LBaaS,Logging Resource (networking-midonet),Router interface floating IP (networking-midonet),FIP64 (networking-midonet),BGP/MPLS VPN Interconnection。
本章也将基本围绕这些分类展开讲述。
Neutron 之所以把这些称为逻辑模型,是因为它的基本原理如下(草图):
图1 Neutron 实现原理(草图)
这仅仅是一个草图,比较详细的图,我们会在 Neutron 架构分析相关章节描述,这里仅仅表达一个示意。从图中我们看到,所谓 Logic Model,其实直接地讲,只做了两件事情:(1)变身一套 RESTful API;(2)相关 API 操作所产生的数据存储在数据库(DB)里。非常完美,然并卵!
Neutron 要想把网络打通,还需要相关 Plugin/Agent 在计算节点/控制节点上做相关配置(请参见笔者所写的“Neutron 网络实现模型”),当然,Neutron 也可以通过相关的 Plugin 来配置真正的物理网元(这是另外的话题,笔者后面会在相关章节描述)。
总之,这些所谓的“逻辑”模型,真的只是一个逻辑上的表达而已!
我们会在本章后面的描述中,继续体会“逻辑”这两个字。
5.1 二层网络模型(Layer2 Networking Model)
L2(Layer2) Networking Model,主要包括 Network,Port 两个模型。下面我们一个一个讲述。
5.1.1 Network
Network,网络,即使在通信的语境里,也是一个非常大的概念。不过,Neutron 在这里特指 L2 Network。
5.1.1.1 Network 概述
我们直接 copy OpenStack 官网上关于 Network Model 的介绍,直接上表格:
| Name |
Type |
Description |
| admin_state_up |
boolean |
The administrative state of the network, which is up (true) or down (false). |
| availability_zone_hints |
array |
The availability zone candidate for the network. |
| availability_zones |
array |
The availability zone for the network. |
| created_at |
string |
Time at which the resource has been created (in UTC ISO8601 format). |
| id |
string |
The ID of the network. |
| mtu |
integer |
The maximum transmission unit (MTU) value to address fragmentation. Minimum value is 68 for IPv4, and 1280 for IPv6. |
| name |
string |
Human-readable name of the network. |
| port_security_enabled |
boolean |
The port security status of the network. Valid values are enabled (true) and disabled (false). This value is used as the default value of port_security_enabled field of a newly created port. |
| project_id |
string |
The ID of the project. |
| provider:network_type |
string |
The type of physical network that this network is mapped to. For example, flat,vlan, vxlan, or gre. Valid values depend on a networking back-end. |
| provider:physical_network |
string |
The physical network where this network is implemented. |
| provider:segmentation_id |
integer |
The ID of the isolated segment on the physical network. The network_type attribute defines the segmentation model. For example, if the network_type value is vlan, this ID is a vlan identifier. If the network_type value is gre, this ID is a gre key. |
| qos_policy_id |
string |
The ID of the QoS policy. |
| router:external |
boolean |
Indicates whether this network can provide floating IPs via a router. |
| segments |
array |
A list of provider segment objects. |
| shared |
boolean |
Indicates whether this network is shared across all tenants. By default, only administrative users can change this value. |
| status |
string |
The network status. Values are ACTIVE, DOWN, BUILD or ERROR. |
| subnets |
array |
The associated subnets. |
| tenant_id |
string |
The ID of the project. |
| updated_at |
string |
Time at which the resource has been updated (in UTC ISO8601 format). |
| vlan_transparent |
boolean |
Indicates the VLAN transparency mode of the network, which is VLAN transparent (true) or not VLAN transparent (false). |
| description |
string |
A human-readable description for the resource. |
表1 Network Logic Model
这个表格呢,我列在这里,您可以阅读,也可以暂时不阅读,因为我下面要展开描述。
5.1.1.2 租户(Tenant)
说到租户(Tenant),稍微有点尴尬,因为 tenant_id 和 project_id 的解释都是:The ID of the project。而且官网还说“Starting with the Newton release of the Networking service, the Networking API accepts the project_id attribute in addition to the tenant_id attribute in requests. The tenant_id attribute is accepted for backward compatibility. If both the project_id and the tenant_id attribute are provided in the same request, their values must be identical.”
也就是说,从 Newton 版本开始,tenant_id 存在的意义,可能只是为了后向兼容,只是一个历史的印记而已。
换句话说,笔者当年千辛万苦地把租户(Tenant)在脑中做个“脑筋急转弯”,好容易正确地理解了“租户不是人”这句话,好容易接纳了“租户”这个词,人家弃用了。
不过呢,笔者以为,玩笑归玩笑,无所谓是 tenant_id 也好,还是 project_id 也好,它(们)除了起到一个传统的 ID 的作用以外,还有一个更深层次的含义:租户隔离!
租户隔离,这四个字该怎么理解!笔者以为,需要往哲学意义上靠:租户隔离是为了共享!
隔离是为了共享!
这个世界最深沉的爱,不是在一起,而是离开!
好吧,不再感慨,一点一点分析这四个字:租户隔离!
说明几点:
(1)租户不是人,这句话的最简单的解释是:租户就是客户,而这里的客户指的是企业。
(2)虽然不能把租户理解为“人”,但是下文为了行文方便,还是把租户当作人来看待,把租户管理员简称为租户。
(3)租户隔离,其实是“多租户隔离”(单租户,也不存在隔离),但是下文为了行文方便,“多租户隔离”,简称“租户隔离”。
5.1.1.2.1 Neutron 语境下租户隔离的含义
租户隔离,在不同场景,不同语境下,有不同的含义,我们这里只讲述 Neutron 语境下,租户隔离的含义。
Neutron 语境下,从租户的视角,或者从需求的视角来讲,租户隔离有四种含义:管理面的隔离,数据面的隔离,逻辑资源层面的隔离,故障层面的隔离。
(1)管理面的隔离
管理面的隔离,指的是“管理权限”的隔离,如下图所示:
图2 管理(控制)层面的隔离
图中两个网络,都是 Neutron 的范围,但是 Network1 属于 Tenant1,Network2 属于 Tenant2,这也就意味着:Tenant1 无法管理(增删改查)Tenant2 的网络(Network2)。Tenant2 亦然!
换句话说,一个 Tenant 只知道他自己的网络,其他网络他毫无知晓,毫无感觉。就像我们人类现在对“平行宇宙”的认识一样(如果真有的话):猜想也许还有其他的平行宇宙吧,但是一无所知,一无所觉。也许,上帝的上帝,也在做租户隔离吧,细思极恐,^_^
需要强调的是,从 Neutron 自身来说,就是指的“控制节点”(虽然 Neutron 称呼自己那个节点叫“控制节点”,实际做了很多很多“管理层面”的工作),但是,作为一个实际的商业系统,比如现在那个最性感的解决方案 SDN(Sex Defined Network),其中某些场景的可能的架构是这样的,如下图所示:
图3 SDN 解决方案中的一种架构
在这个架构中,Neutron(Control Node)解决好自己的租户权限隔离问题,而作为整个解决方案,还需要解决从 APP 到 Controller,每一层的租户权限隔离的问题。
(2)数据面的隔离
数据面的隔离,指的是数据转发的隔离。不同租户的网络之间,是不能互通的(除非租户特殊要求,这个属于抬杠,我们不讨论)。
从管理权限角度,一个租户不能管理另一个租户的网络。同理,不同租户的网络也不能互通。
可能有人会问,说了“管理面”和“数据面”,那么“控制面”呢?对于控制面,我们有两点解释:
A. 控制面,不属于用户视角。或者话句话说,控制面是否隔离,用户不关心,这仅仅是一个内部实现。说的更装逼一点,这不是一个问题。
B. 控制面,分为两种,一种是基于经典 TCP/IP 协议的,一种是基于性感解决方案(SDN)的。基于经典 TCP/IP 协议的,跟数据面一样,这个控制面的隔离也是天然的(因为不同租户的网络,也根本感知不到彼此的存在);基于 SDN 的控制面,也就是传说中的控制器(Controller),它怎么实现,取决于它自己,用户不关心。
(3)逻辑资源层面的隔离
逻辑资源,其实也有不同的定义,这里我们不纠结逻辑资源的定义本身,而是以举例(我负责举例)加联想(您负责联想)的方式来做个简单定义:逻辑资源指的是 IP 地址,VLANID,甚至可以包括 MAC 地址等等这些网络世界里,为了系统能正常运行,而人为定义的字段的取值范围。(好吧,就这么定义吧,我相信您知道什么叫逻辑资源,^_^)
因为不同租户网络不能感知到彼此的存在,所以说,“逻辑资源层面的隔离”,这句话其实意味着:逻辑资源的复用。
Tenant1 可以有一批私有网络 IP 地址:10.0.1.0/24,Tenant2 可以有一批同样的私有网络 IP 地址。这就是逻辑资源层面的隔离。逻辑资源的隔离,其实是为了解决逻辑资源的冲突,或者更好理解的说法是:逻辑资源的复用。
说到这里,可能也有人会问,既然讲了逻辑资源的隔离,那么物理资源呢?
我们讲,物理资源恰恰不是为了隔离,而是为了共享!
请您先往下看。
(4)故障层面的隔离
这个最有讲究。笔者观点:讲前三个隔离,如果不讲这个,那前三个就是废话!(因为前三个比较直白直接!)
故障隔离的范围太大!
故障隔离,简单地说,一个租户网络出问题了,不能影响另一个租户的网络!这句话太简单了,以至于“不太正确”!
一个租户网络的路由器本身出问题了(注意,我说的是“路由器本身”),比如它的路由表凌乱了,不应该影响其他租户的网络,这是正确的。
但是,我们知道,Neutron 的 Router 是位于控制节点的(不考虑 DVR),如果这个控制节点死机了,这个时候我们就不能讲:一个租户网络的路由器出问题了(注意,我这里没有说“路由器本身”),不应该影响其他租户的网络。要知道,控制节点出问题了,那就是全都出问题了。
我们再看计算节点,我们知道,一个计算节点只有一个 br-int,但是可以有多个 VM,如果这些 VM 可以分属多个租户,那么这个计算节点的 br-int 出问题了,也谈不上租户隔离。
我们也许可以这么说,一个租户一个控制节点(虽然目前还没有这样的解决方案,我们就假设有这样的解决方案),不同租户的 VM 不能在同一个 Host(因为 Host 内的 br-int 是共享的),这样是不是就做到租户的故障隔离了呢?
但是,我们可以这样追问,如果机架嗝屁了呢?那么是不是不同租户必须要不同机架?那如果数据中心嗝屁了呢?是不是不同租户需要不同数据中心?......我们可以一直追问下去,一直追问到:不同租户是不必须不在同一个地球......不在同一个宇宙......
这样的追问不仅没完没了,而且做不到!有的是由于经济学的原因(比如不在同一个数据中心),有的是由于科学技术原因(比如不在同一个地球),有的是由于哲学的原因(比如不在同一个宇宙)!
那么,租户隔离中的“故障隔离”到底该怎么定义???
此刻我的心情是这样的:
好吧,我们暂时忘记这个定义,先看下一小节,然后再给出这个定义。
5.1.1.2.2 Neutron 在租户隔离中的无限责任和有限责任
唉,这个标题取的也够装逼的,^_^
其实,我们在上一小节中,也已经有体会,Neutron(其实包含任何一个系统),在租户隔离这个层面,不会也无法承担全方位的无限责任,比如故障隔离,就不能承担无限责任!
我先直接说观点(或者说结论),然后再论述:
Neutron 在“管理面的隔离,数据面的隔离,逻辑资源层面的隔离”这三个层面,必须承担无限责任,而在“故障层面的隔离”的这个层面,只能承担有限责任。
所谓无限责任,就是错了必须修改(只能要求人家修改,你总不能要求人家从此就给你做牛做马)。
而所谓有限责任,就是只能在某些方面保证故障是可以隔离的。(到底是哪些方面,笔者下面会讲述)。
我们在前面讲过,租户隔离的哲学意义是:隔离是为了共享!
共享什么?共享物理资源!
OpenStack(包含 Neutron),是为云而服务的。那么云服务的物理资源是什么:数据中心地产(含房屋、空调、水电等等)、物理网络(数据中心里面的物理路由器、交换机、防火墙等等)、机架、主机。
我们讲,这些物理资源中,数据中心、物理网络是必须要共享的,不然云服务商要破产。(土豪把云服务商给包了,那是另说)
机架一般也是需要共享的,这取决于租户到底有多大。土豪租户可以独占机架。
主机有时候,也是需要共享的,这取决于租户到底有多小。屌丝租户(只租一两个虚机),也得共享主机。
所有这些物理资源,云服务商都不承诺“租户隔离”!
换句话说,这些资源的所谓“租户隔离”取决于租户自己到底有多壕,而不取决于技术层面的解决方案!
这个时候,我想,我们可以给出“故障隔离”的定义:管理面的故障,数据面的故障,逻辑资源层面的故障,必须要做到租户隔离;而物力资源层面的故障隔离,取决于租户的壕度,不是单纯的技术问题!
5.1.1.2.3 Neutron 的租户隔离实现方案
(一)数据面和逻辑资源层面
讲数据转发,离不开逻辑资源(VLANID, IP 地址等等),所以两者放在一起讲。
Neutron 在计算节点和网络节点都涉及到了数据转发。
(1)计算节点
计算节点实现模型如下图所示:
图4 计算节点实现模型
我们在“Neutron 网络实现模型”那一章中,也介绍了计算节点的实现模型,这里是以另外一种稍有不同的方式展现(只是展现形式稍有区别,模型本身是一样的,不能换个章节,模型就变了,^_^)。
图中,VM1-1,VM1-2,分属两个Tenant,当然,也就分属两个 Tenant Network。我们看到,涉及到租户网络隔离的组件有:br-ethx/tun(一个),br-int(一个),qbr(多个),router/dvr(多个)。
br-ethx/tun,br-int 分别只有一个实例,这个是属于“多租户共享一个组件”的方案,实现了“多租户隔离”的目的。
qbr 跟 VM 一一对应,这个属于“多租户隔离的组件”,实现了“多租户隔离”的目的。qbr 由于绑定了安全组,它是原生的二层转发租户隔离技术的基础上,再叠加一层“安全层”来保证租户隔离。原生二层转发(br-ethx/tun,br-int)负责“正常行为”的租户隔离,而安全技术(qbr)负责“异常行为”的租户隔离。(“异常行为”指的是一个租户网络非法访问另一个租户网络)
router/dvr 跟 Tenant 对应,而且每个 router/dvr 运行在一个 namespace 中,这个属于“多租户隔离的组件”并且“多租户 namespace 隔离”的方案,实现了“多租户隔离”的目的。Router/dvr 除了保证租户间网络不会互相访问以外,还解决了逻辑资源(IP 地址)冲突的问题。
(2)网络节点
网络节点的是实现模型,如下图所示:
图5 网络节点实现模型
网络节点中,br-ethx/tun,br-int, br-ex 分别只有一个实例,这个是属于“多租户共享一个组件”的方案,实现了“多租户隔离”的目的。
router 跟 Tenant 对应,而且每个 router 运行在一个 namespace 中,这个属于“多租户隔离的组件”并且“多租户 namespace 隔离”的方案,实现了“多租户隔离”的目的。Router/dvr 除了保证租户间网络不会互相访问以外,还解决了逻辑资源(IP 地址)冲突的问题。
(3)小结
我们直接上图:
图6 数据面及逻辑资源面租户隔离方案小结
我们看到,租户隔离度与资源共享度是成反比的。
(二)管理面的租户隔离方案
管理面,对于 Neutron 而言,指的是控制节点。是的,它虽然叫“控制节点”,笔者还是把它归为管理面。Openstack(Neutron)控制节点的实现模型如下图所示:
图7 OpenStack(Neutron)控制节点的实现模型
我们可以把控制节点当作一个普通的软件系统,或者类比为 SaaS(Software as a Service),当然只是类比,不能完全等同。
我们看到,OpenStack(Neutron)的控制节点,它的租户隔离方案也是没sei了:它基本等于没有!
抛开多实例及 HA(High Available,高可用性),控制节点的租户隔离方案就是:简单、粗暴、几乎没有。
硬件/操作系统层面隔离:没有!(就是运行在一个主机上)
应用程序层面隔离:没有!(就是单实例)
数据库层面隔离:几乎没有!
数据库层面的租户隔离方案一般有如下几种:
l 独立数据库
l 共享数据库,独立 Schema(简单地说,就是独立表的意思,不同的租户,不同的表,而且不同租户之间的表,也没有关联)
l 共享数据库,共享 Schema,共享表
OpenStack(Neutron)控制节点,数据库层面所采取的租户隔离方案就是“共享数据库,共享 Schema,共享表”,在表中加了一个字段“tenant_id”来区分不同的租户。
但是,OpenStack(Neutron)的控制节点,就是靠这个方案,基本上也实现了管理面的租户隔离的需求了吧。
写到这里,笔者想起一个题外话。那是在笔者的工作中,参加的一次两个部门之间的讨(si)论(bi)会(zhan)。其中一个部门的童鞋说:我们这个方案好啊,我们是多租户(隔离)的。另外一个部门童鞋弱弱地说了一句:啥多租户啊,不就是数据库表中加了一个tenant_id”字段吗?
我在那里硬憋着不笑,因为我也是那个实现了多租户方案的部门的。
5.1.1.2.4 租户隔离方案的思考
我们还是要做哲学的思考,这句话真不是装逼!思考一个事物的本质,就是要做哲学的思考。而哲学的本质,就是矛盾!(哲学的本质,就是矛盾。这句话是我说的,欢迎拍砖)
租户隔离的目的,是为了共享!这是我们的第一层哲学思考:事物是矛盾的和谐!
或者说,租户隔离,就是:用共享的组件,提供租户隔离的技术,达到租户隔离的目的。
比如,我们前面讲过,计算节点中的 br-int,是共享的组件,但是它提供了 VLAN 的技术,我们可以利用 VLAN 这种技术,从而达到租户隔离的目的。
但是,无论这个组件提供多么酷炫的租户隔离的技术,它本身仍然是共享的,它本身的租户隔离怎么做呢?这是一个实现层面的矛盾!
这个时候,我们需要第二层哲学思考:解决实现层面的矛盾,一定要跳出问题本身,不然就会死循环。
我们的实现方案,就是“共享组件实现租户隔离”,这个时候我们不能再纠缠于“共享组件本身如何实现租户隔离”,这样的纠缠是无解的。
我们一定要跳出问题本身,另外思考出路。
或者说,我们一定要跳出问题本身,重新思考问题的本质:问题到底是什么?
“共享组件实现租户隔离”,这个问题的本质,不是“共享组件本身如何实现租户隔离”,而是:
(1)这个共享组件真的能做到租户隔离吗?
(2)这个共享组件故障了怎么办(因为它故障了,影响的就不是一个租户)?
(3)这个共享组件的性能会是瓶颈吗?
对于第(1)个问题,答案是:增强!于是我们看到,在 br-int 的基础上,叠加 qbr,也就是叠加安全组。在后面的章节中,我们还会看到,其实 Neutron 还会继续叠加“FWaaS(Firewall as a Service)”。这些“叠加”都是“增强”,增强租户隔离的技术!
对于第(2)个问题,答案是:HA!
对于第(3)个问题,答案是:集群/分布式!
HA,集群/分布式,本身是另外的话题,这里我就不展开了。我应该会写一篇关于 Neutron 的 HA、集群/分布式方案的文章,敬请期待!
当然,我们还可以继续思考问题......但是最重要的一点是:实现层面,如果要解决矛盾的问题,一定要跳出问题,而不能陷入死循环!
也许您会说,你这太会装逼了,你这根本就是错的。
好吧,人生,谁不希望犯一次错误呢?!

微信扫一扫
关注该公众号
深度探索 OpenStack Neutron:Neutron 逻辑模型(1)
【说明:阅读本篇文章,需要一定的预备知识“Neutron 网络实现模型”。关注微信公众号“标哥说天下”,回复“NMI” 或者 “nmi”,可以获取该文章。】
第五章 Neutron 逻辑模型
这一章的写作,对我来说,太有挑战。因为 OpenStack 有官网介绍它的 RESTful API。而这些 API 的介绍,就是基于 Neutron 逻辑模型的 CRUD(Create,Retrieve,Update,Delete,增加/查询/修改/删除)讲述。这意味着什么?这意味着官网是“模型 + CRUD”一起介绍,而我这里仅仅介绍模型,我的内心是几乎崩溃的,^_^
好吧,让我们来一场冒险之旅,看看我的功力到底如何,能不能在有官方 wiki 的基础上,写下一篇不一样的文章。
【版权统一申明】不能否认也没法避免,本章统一参考 OpenStack 关于 Neutron API 的官网:https://developer.openstack.org/api-ref/networking/v2/?expanded=list-floating-ips-detail,show-subnet-details-detail 。
笔者也强烈建议您阅读该网页。
Neutron 把网络相关的逻辑模型,分为如下几个部分:
Layer2 Networking,Layer3 Networking,Security,Resource Management,QoS,LBaaS,Logging Resource (networking-midonet),Router interface floating IP (networking-midonet),FIP64 (networking-midonet),BGP/MPLS VPN Interconnection。
本章也将基本围绕这些分类展开讲述。
Neutron 之所以把这些称为逻辑模型,是因为它的基本原理如下(草图):
图1 Neutron 实现原理(草图)
这仅仅是一个草图,比较详细的图,我们会在 Neutron 架构分析相关章节描述,这里仅仅表达一个示意。从图中我们看到,所谓 Logic Model,其实直接地讲,只做了两件事情:(1)变身一套 RESTful API;(2)相关 API 操作所产生的数据存储在数据库(DB)里。非常完美,然并卵!
Neutron 要想把网络打通,还需要相关 Plugin/Agent 在计算节点/控制节点上做相关配置(请参见笔者所写的“Neutron 网络实现模型”),当然,Neutron 也可以通过相关的 Plugin 来配置真正的物理网元(这是另外的话题,笔者后面会在相关章节描述)。
总之,这些所谓的“逻辑”模型,真的只是一个逻辑上的表达而已!
我们会在本章后面的描述中,继续体会“逻辑”这两个字。
5.1 二层网络模型(Layer2 Networking Model)
L2(Layer2) Networking Model,主要包括 Network,Port 两个模型。下面我们一个一个讲述。
5.1.1 Network
Network,网络,即使在通信的语境里,也是一个非常大的概念。不过,Neutron 在这里特指 L2 Network。
5.1.1.1 Network 概述
我们直接 copy OpenStack 官网上关于 Network Model 的介绍,直接上表格:
| Name |
Type |
Description |
| admin_state_up |
boolean |
The administrative state of the network, which is up (true) or down (false). |
| availability_zone_hints |
array |
The availability zone candidate for the network. |
| availability_zones |
array |
The availability zone for the network. |
| created_at |
string |
Time at which the resource has been created (in UTC ISO8601 format). |
| id |
string |
The ID of the network. |
| mtu |
integer |
The maximum transmission unit (MTU) value to address fragmentation. Minimum value is 68 for IPv4, and 1280 for IPv6. |
| name |
string |
Human-readable name of the network. |
| port_security_enabled |
boolean |
The port security status of the network. Valid values are enabled (true) and disabled (false). This value is used as the default value of port_security_enabled field of a newly created port. |
| project_id |
string |
The ID of the project. |
| provider:network_type |
string |
The type of physical network that this network is mapped to. For example, flat,vlan, vxlan, or gre. Valid values depend on a networking back-end. |
| provider:physical_network |
string |
The physical network where this network is implemented. |
| provider:segmentation_id |
integer |
The ID of the isolated segment on the physical network. The network_type attribute defines the segmentation model. For example, if the network_type value is vlan, this ID is a vlan identifier. If the network_type value is gre, this ID is a gre key. |
| qos_policy_id |
string |
The ID of the QoS policy. |
| router:external |
boolean |
Indicates whether this network can provide floating IPs via a router. |
| segments |
array |
A list of provider segment objects. |
| shared |
boolean |
Indicates whether this network is shared across all tenants. By default, only administrative users can change this value. |
| status |
string |
The network status. Values are ACTIVE, DOWN, BUILD or ERROR. |
| subnets |
array |
The associated subnets. |
| tenant_id |
string |
The ID of the project. |
| updated_at |
string |
Time at which the resource has been updated (in UTC ISO8601 format). |
| vlan_transparent |
boolean |
Indicates the VLAN transparency mode of the network, which is VLAN transparent (true) or not VLAN transparent (false). |
| description |
string |
A human-readable description for the resource. |
表1 Network Logic Model
这个表格呢,我列在这里,您可以阅读,也可以暂时不阅读,因为我下面要展开描述。
5.1.1.2 租户(Tenant)
说到租户(Tenant),稍微有点尴尬,因为 tenant_id 和 project_id 的解释都是:The ID of the project。而且官网还说“Starting with the Newton release of the Networking service, the Networking API accepts the project_id attribute in addition to the tenant_id attribute in requests. The tenant_id attribute is accepted for backward compatibility. If both the project_id and the tenant_id attribute are provided in the same request, their values must be identical.”
也就是说,从 Newton 版本开始,tenant_id 存在的意义,可能只是为了后向兼容,只是一个历史的印记而已。
换句话说,笔者当年千辛万苦地把租户(Tenant)在脑中做个“脑筋急转弯”,好容易正确地理解了“租户不是人”这句话,好容易接纳了“租户”这个词,人家弃用了。
不过呢,笔者以为,玩笑归玩笑,无所谓是 tenant_id 也好,还是 project_id 也好,它(们)除了起到一个传统的 ID 的作用以外,还有一个更深层次的含义:租户隔离!
租户隔离,这四个字该怎么理解!笔者以为,需要往哲学意义上靠:租户隔离是为了共享!
隔离是为了共享!
这个世界最深沉的爱,不是在一起,而是离开!
好吧,不再感慨,一点一点分析这四个字:租户隔离!
说明几点:
(1)租户不是人,这句话的最简单的解释是:租户就是客户,而这里的客户指的是企业。
(2)虽然不能把租户理解为“人”,但是下文为了行文方便,还是把租户当作人来看待,把租户管理员简称为租户。
(3)租户隔离,其实是“多租户隔离”(单租户,也不存在隔离),但是下文为了行文方便,“多租户隔离”,简称“租户隔离”。
5.1.1.2.1 Neutron 语境下租户隔离的含义
租户隔离,在不同场景,不同语境下,有不同的含义,我们这里只讲述 Neutron 语境下,租户隔离的含义。
Neutron 语境下,从租户的视角,或者从需求的视角来讲,租户隔离有四种含义:管理面的隔离,数据面的隔离,逻辑资源层面的隔离,故障层面的隔离。
(1)管理面的隔离
管理面的隔离,指的是“管理权限”的隔离,如下图所示:
图2 管理(控制)层面的隔离
图中两个网络,都是 Neutron 的范围,但是 Network1 属于 Tenant1,Network2 属于 Tenant2,这也就意味着:Tenant1 无法管理(增删改查)Tenant2 的网络(Network2)。Tenant2 亦然!
换句话说,一个 Tenant 只知道他自己的网络,其他网络他毫无知晓,毫无感觉。就像我们人类现在对“平行宇宙”的认识一样(如果真有的话):猜想也许还有其他的平行宇宙吧,但是一无所知,一无所觉。也许,上帝的上帝,也在做租户隔离吧,细思极恐,^_^
需要强调的是,从 Neutron 自身来说,就是指的“控制节点”(虽然 Neutron 称呼自己那个节点叫“控制节点”,实际做了很多很多“管理层面”的工作),但是,作为一个实际的商业系统,比如现在那个最性感的解决方案 SDN(Sex Defined Network),其中某些场景的可能的架构是这样的,如下图所示:
图3 SDN 解决方案中的一种架构
在这个架构中,Neutron(Control Node)解决好自己的租户权限隔离问题,而作为整个解决方案,还需要解决从 APP 到 Controller,每一层的租户权限隔离的问题。
(2)数据面的隔离
数据面的隔离,指的是数据转发的隔离。不同租户的网络之间,是不能互通的(除非租户特殊要求,这个属于抬杠,我们不讨论)。
从管理权限角度,一个租户不能管理另一个租户的网络。同理,不同租户的网络也不能互通。
可能有人会问,说了“管理面”和“数据面”,那么“控制面”呢?对于控制面,我们有两点解释:
A. 控制面,不属于用户视角。或者话句话说,控制面是否隔离,用户不关心,这仅仅是一个内部实现。说的更装逼一点,这不是一个问题。
B. 控制面,分为两种,一种是基于经典 TCP/IP 协议的,一种是基于性感解决方案(SDN)的。基于经典 TCP/IP 协议的,跟数据面一样,这个控制面的隔离也是天然的(因为不同租户的网络,也根本感知不到彼此的存在);基于 SDN 的控制面,也就是传说中的控制器(Controller),它怎么实现,取决于它自己,用户不关心。
(3)逻辑资源层面的隔离
逻辑资源,其实也有不同的定义,这里我们不纠结逻辑资源的定义本身,而是以举例(我负责举例)加联想(您负责联想)的方式来做个简单定义:逻辑资源指的是 IP 地址,VLANID,甚至可以包括 MAC 地址等等这些网络世界里,为了系统能正常运行,而人为定义的字段的取值范围。(好吧,就这么定义吧,我相信您知道什么叫逻辑资源,^_^)
因为不同租户网络不能感知到彼此的存在,所以说,“逻辑资源层面的隔离”,这句话其实意味着:逻辑资源的复用。
Tenant1 可以有一批私有网络 IP 地址:10.0.1.0/24,Tenant2 可以有一批同样的私有网络 IP 地址。这就是逻辑资源层面的隔离。逻辑资源的隔离,其实是为了解决逻辑资源的冲突,或者更好理解的说法是:逻辑资源的复用。
说到这里,可能也有人会问,既然讲了逻辑资源的隔离,那么物理资源呢?
我们讲,物理资源恰恰不是为了隔离,而是为了共享!
请您先往下看。
(4)故障层面的隔离
这个最有讲究。笔者观点:讲前三个隔离,如果不讲这个,那前三个就是废话!(因为前三个比较直白直接!)
故障隔离的范围太大!
故障隔离,简单地说,一个租户网络出问题了,不能影响另一个租户的网络!这句话太简单了,以至于“不太正确”!
一个租户网络的路由器本身出问题了(注意,我说的是“路由器本身”),比如它的路由表凌乱了,不应该影响其他租户的网络,这是正确的。
但是,我们知道,Neutron 的 Router 是位于控制节点的(不考虑 DVR),如果这个控制节点死机了,这个时候我们就不能讲:一个租户网络的路由器出问题了(注意,我这里没有说“路由器本身”),不应该影响其他租户的网络。要知道,控制节点出问题了,那就是全都出问题了。
我们再看计算节点,我们知道,一个计算节点只有一个 br-int,但是可以有多个 VM,如果这些 VM 可以分属多个租户,那么这个计算节点的 br-int 出问题了,也谈不上租户隔离。
我们也许可以这么说,一个租户一个控制节点(虽然目前还没有这样的解决方案,我们就假设有这样的解决方案),不同租户的 VM 不能在同一个 Host(因为 Host 内的 br-int 是共享的),这样是不是就做到租户的故障隔离了呢?
但是,我们可以这样追问,如果机架嗝屁了呢?那么是不是不同租户必须要不同机架?那如果数据中心嗝屁了呢?是不是不同租户需要不同数据中心?......我们可以一直追问下去,一直追问到:不同租户是不必须不在同一个地球......不在同一个宇宙......
这样的追问不仅没完没了,而且做不到!有的是由于经济学的原因(比如不在同一个数据中心),有的是由于科学技术原因(比如不在同一个地球),有的是由于哲学的原因(比如不在同一个宇宙)!
那么,租户隔离中的“故障隔离”到底该怎么定义???
此刻我的心情是这样的:
好吧,我们暂时忘记这个定义,先看下一小节,然后再给出这个定义。
5.1.1.2.2 Neutron 在租户隔离中的无限责任和有限责任
唉,这个标题取的也够装逼的,^_^
其实,我们在上一小节中,也已经有体会,Neutron(其实包含任何一个系统),在租户隔离这个层面,不会也无法承担全方位的无限责任,比如故障隔离,就不能承担无限责任!
我先直接说观点(或者说结论),然后再论述:
Neutron 在“管理面的隔离,数据面的隔离,逻辑资源层面的隔离”这三个层面,必须承担无限责任,而在“故障层面的隔离”的这个层面,只能承担有限责任。
所谓无限责任,就是错了必须修改(只能要求人家修改,你总不能要求人家从此就给你做牛做马)。
而所谓有限责任,就是只能在某些方面保证故障是可以隔离的。(到底是哪些方面,笔者下面会讲述)。
我们在前面讲过,租户隔离的哲学意义是:隔离是为了共享!
共享什么?共享物理资源!
OpenStack(包含 Neutron),是为云而服务的。那么云服务的物理资源是什么:数据中心地产(含房屋、空调、水电等等)、物理网络(数据中心里面的物理路由器、交换机、防火墙等等)、机架、主机。
我们讲,这些物理资源中,数据中心、物理网络是必须要共享的,不然云服务商要破产。(土豪把云服务商给包了,那是另说)
机架一般也是需要共享的,这取决于租户到底有多大。土豪租户可以独占机架。
主机有时候,也是需要共享的,这取决于租户到底有多小。屌丝租户(只租一两个虚机),也得共享主机。
所有这些物理资源,云服务商都不承诺“租户隔离”!
换句话说,这些资源的所谓“租户隔离”取决于租户自己到底有多壕,而不取决于技术层面的解决方案!
这个时候,我想,我们可以给出“故障隔离”的定义:管理面的故障,数据面的故障,逻辑资源层面的故障,必须要做到租户隔离;而物力资源层面的故障隔离,取决于租户的壕度,不是单纯的技术问题!
5.1.1.2.3 Neutron 的租户隔离实现方案
(一)数据面和逻辑资源层面
讲数据转发,离不开逻辑资源(VLANID, IP 地址等等),所以两者放在一起讲。
Neutron 在计算节点和网络节点都涉及到了数据转发。
(1)计算节点
计算节点实现模型如下图所示:
图4 计算节点实现模型
我们在“Neutron 网络实现模型”那一章中,也介绍了计算节点的实现模型,这里是以另外一种稍有不同的方式展现(只是展现形式稍有区别,模型本身是一样的,不能换个章节,模型就变了,^_^)。
图中,VM1-1,VM1-2,分属两个Tenant,当然,也就分属两个 Tenant Network。我们看到,涉及到租户网络隔离的组件有:br-ethx/tun(一个),br-int(一个),qbr(多个),router/dvr(多个)。
br-ethx/tun,br-int 分别只有一个实例,这个是属于“多租户共享一个组件”的方案,实现了“多租户隔离”的目的。
qbr 跟 VM 一一对应,这个属于“多租户隔离的组件”,实现了“多租户隔离”的目的。qbr 由于绑定了安全组,它是原生的二层转发租户隔离技术的基础上,再叠加一层“安全层”来保证租户隔离。原生二层转发(br-ethx/tun,br-int)负责“正常行为”的租户隔离,而安全技术(qbr)负责“异常行为”的租户隔离。(“异常行为”指的是一个租户网络非法访问另一个租户网络)
router/dvr 跟 Tenant 对应,而且每个 router/dvr 运行在一个 namespace 中,这个属于“多租户隔离的组件”并且“多租户 namespace 隔离”的方案,实现了“多租户隔离”的目的。Router/dvr 除了保证租户间网络不会互相访问以外,还解决了逻辑资源(IP 地址)冲突的问题。
(2)网络节点
网络节点的是实现模型,如下图所示:
图5 网络节点实现模型
网络节点中,br-ethx/tun,br-int, br-ex 分别只有一个实例,这个是属于“多租户共享一个组件”的方案,实现了“多租户隔离”的目的。
router 跟 Tenant 对应,而且每个 router 运行在一个 namespace 中,这个属于“多租户隔离的组件”并且“多租户 namespace 隔离”的方案,实现了“多租户隔离”的目的。Router/dvr 除了保证租户间网络不会互相访问以外,还解决了逻辑资源(IP 地址)冲突的问题。
(3)小结
我们直接上图:
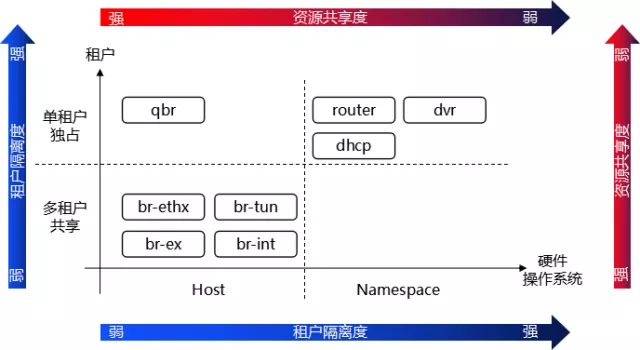
图6 数据面及逻辑资源面租户隔离方案小结
我们看到,租户隔离度与资源共享度是成反比的。
(二)管理面的租户隔离方案
管理面,对于 Neutron 而言,指的是控制节点。是的,它虽然叫“控制节点”,笔者还是把它归为管理面。Openstack(Neutron)控制节点的实现模型如下图所示:
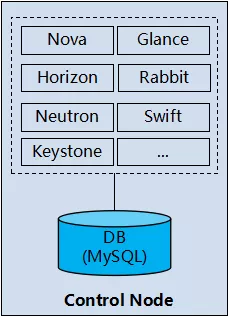
图7 OpenStack(Neutron)控制节点的实现模型
我们可以把控制节点当作一个普通的软件系统,或者类比为 SaaS(Software as a Service),当然只是类比,不能完全等同。
我们看到,OpenStack(Neutron)的控制节点,它的租户隔离方案也是没sei了:它基本等于没有!
抛开多实例及 HA(High Available,高可用性),控制节点的租户隔离方案就是:简单、粗暴、几乎没有。
硬件/操作系统层面隔离:没有!(就是运行在一个主机上)
应用程序层面隔离:没有!(就是单实例)
数据库层面隔离:几乎没有!
数据库层面的租户隔离方案一般有如下几种:
l 独立数据库
l 共享数据库,独立 Schema(简单地说,就是独立表的意思,不同的租户,不同的表,而且不同租户之间的表,也没有关联)
l 共享数据库,共享 Schema,共享表
OpenStack(Neutron)控制节点,数据库层面所采取的租户隔离方案就是“共享数据库,共享 Schema,共享表”,在表中加了一个字段“tenant_id”来区分不同的租户。
但是,OpenStack(Neutron)的控制节点,就是靠这个方案,基本上也实现了管理面的租户隔离的需求了吧。
写到这里,笔者想起一个题外话。那是在笔者的工作中,参加的一次两个部门之间的讨(si)论(bi)会(zhan)。其中一个部门的童鞋说:我们这个方案好啊,我们是多租户(隔离)的。另外一个部门童鞋弱弱地说了一句:啥多租户啊,不就是数据库表中加了一个tenant_id”字段吗?
我在那里硬憋着不笑,因为我也是那个实现了多租户方案的部门的。
5.1.1.2.4 租户隔离方案的思考
我们还是要做哲学的思考,这句话真不是装逼!思考一个事物的本质,就是要做哲学的思考。而哲学的本质,就是矛盾!(哲学的本质,就是矛盾。这句话是我说的,欢迎拍砖)
租户隔离的目的,是为了共享!这是我们的第一层哲学思考:事物是矛盾的和谐!
或者说,租户隔离,就是:用共享的组件,提供租户隔离的技术,达到租户隔离的目的。
比如,我们前面讲过,计算节点中的 br-int,是共享的组件,但是它提供了 VLAN 的技术,我们可以利用 VLAN 这种技术,从而达到租户隔离的目的。
但是,无论这个组件提供多么酷炫的租户隔离的技术,它本身仍然是共享的,它本身的租户隔离怎么做呢?这是一个实现层面的矛盾!
这个时候,我们需要第二层哲学思考:解决实现层面的矛盾,一定要跳出问题本身,不然就会死循环。
我们的实现方案,就是“共享组件实现租户隔离”,这个时候我们不能再纠缠于“共享组件本身如何实现租户隔离”,这样的纠缠是无解的。
我们一定要跳出问题本身,另外思考出路。
或者说,我们一定要跳出问题本身,重新思考问题的本质:问题到底是什么?
“共享组件实现租户隔离”,这个问题的本质,不是“共享组件本身如何实现租户隔离”,而是:
(1)这个共享组件真的能做到租户隔离吗?
(2)这个共享组件故障了怎么办(因为它故障了,影响的就不是一个租户)?
(3)这个共享组件的性能会是瓶颈吗?
对于第(1)个问题,答案是:增强!于是我们看到,在 br-int 的基础上,叠加 qbr,也就是叠加安全组。在后面的章节中,我们还会看到,其实 Neutron 还会继续叠加“FWaaS(Firewall as a Service)”。这些“叠加”都是“增强”,增强租户隔离的技术!
对于第(2)个问题,答案是:HA!
对于第(3)个问题,答案是:集群/分布式!
HA,集群/分布式,本身是另外的话题,这里我就不展开了。我应该会写一篇关于 Neutron 的 HA、集群/分布式方案的文章,敬请期待!
当然,我们还可以继续思考问题......但是最重要的一点是:实现层面,如果要解决矛盾的问题,一定要跳出问题,而不能陷入死循环!
也许您会说,你这太会装逼了,你这根本就是错的。
好吧,人生,谁不希望犯一次错误呢?!
深度探索 OpenStack Neutron:Neutron 逻辑模型(3)
【说明:阅读本篇文章,需要一定的预备知识“Neutron 网络实现模型”。关注微信公众号“标哥说天下”,回复“NMI” 或者 “nmi”,可以获取该文章。】
感谢陈苍童鞋对我的帮助!
5.1.1.4 租户网络和运营商网络(Tenant Network & Provider Network)
租户网络(Tenant Network,现在新版本已经改为 Project Network,不过笔者还是习惯租户网络这个称呼)与运营商网络(Provider Network),并不是 Network Model 中的属性,它们就是 Network 本身,就是通过命令行或者 RESTful API 所创建的 Neutron Network(create Network)。
简单地说,租户创建的网络,就是租户网络,而管理员(Administrator)创建的网络,就是运营商网络。但是事情并没有这么简单。下面我们就来展开描述。
5.1.1.4.1 运营商网络的创建方法
我们前面说过,运营商网络仍然是一个 Network,它的创建方法仍然是通过命令行或者 RESTful API 来创建网络(create Network),它与租户创建一个租户网络相比,有两个不同点:
(1)必须是管理员或者具备管理员权限的用户
(2)必须传入如下三个参数(Network Model 里面的三个字段),如下表所示:
| Name |
Type |
Description |
| provider:network_type |
string |
The type of physical network that this network is mapped to. For example, flat,vlan, vxlan, or gre. Valid values depend on a networking back-end. |
| provider:physical_network |
string |
The physical network where this network is implemented. |
| provider:segmentation_id |
integer |
The ID of the isolated segment on the physical network. The network_type attribute defines the segmentation model. For example, if the network_type value is vlan, this ID is a vlan identifier. If the network_type value is gre, this ID is a gre key. |
表1 创建运营商网络必须传入的三个参数
【注】租户创建租户网络,恰恰不能传入这三个参数,这个我们会在下面讲述
上述表格,是原文摘抄的 Neutron 官网,笔者再补充说明一些内容。
字段中,有 provider 前缀,正是通过字段名给一个强烈的含义表达:这是 provider network 所需要的参数(与 tenant network 无关)。
我们知道,local 网络类型,指的是一个 Host 内部的网络,这个显然与 Provider Network 的使用场景不符合,所以,Provider Network 不会包含这种网络类型。而其他类型,都是可以的。
provider:physical_network,我们在上一节介绍过,在网络类型非隧道类型时(FLAT/VLAN),必须填入这个参数,在网络类型是隧道类型时(GRE/VXLAN/GENEVE),必须不能填入这个参数。
【注】关注微信公众号“标哥说天下”,回复“LNM2”,以获取讲述“物理网络”的该篇文章《深入探索 OpenStack Neutron:Neutron 逻辑模型(2)》
provider:segmentation_id,是对各种网络类型中的“ID”一种抽象。如果是 VLAN 网络,则其代表 VLANID;如果是 VXLAN 网络,则其代表 VNI;如果是 GRE 网络,则其代表 GRE Key。
这三个参数,是创建运营商网络与租户网络时的不同。其他参数,则两者的使用方法相同。
5.1.1.4.2 租户网络的创建方法
租户网络,是租户创建的网络。当然,从 Neutron 的权限管理来说,管理员也可以创建租户网络。
租户网络,从创建方法来说,跟运营商网络恰恰相反,它恰恰不能输入上述的“provider:xxx”三个参数。
但是,我们从 Network Model 中知道:除了“provider:network_type”,再也没有字段能表达网络类型;除了“provider:segmentation_id”,再也没有字段可以表达网络“ID”。
那么,问题来了:租户怎么决定他的网络的网络类型和网络“ID”?
租户决定不了!
说的好听点,这是云运营商对租户的一个友好界面,租户不需要感知这么多细节,这些由运营商搞定。
说的难听点,你租户创建一个网络,通了就行了,瞎 BB 个啥?什么网络类型,什么网络“ID”,管那么多干啥?
呵呵,我是开玩笑的。在 Neutron 的设计方案中,对租户封装这些细节,提升易用性,提高满意度,真的是 Neutron 的本意!
但是,既然租户不能填入这些参数,那么 Neutron 又是如何知道的呢?
Neutron 也没法知道,是管理员告诉他的(背后是云服务商老板决定的)。管理员通过配置文件,配置网络类型和网络“ID”。配置信息如下:
tenant_network_types = vxlan
[ml2_type_vxlan]
vni_ranges = 1:1000
还是那句话,我们暂时不用关心这个是哪个配置文件里描述的,我们只关心这些本质的内容(我会在后面的章节中,专门介绍配置文件)。
通过这个配置信息,我们看到,租户网络的网络类型是“VXLAN”,而相应的 VNI,是由 Neutron 根据一定的规则,自动分配,不过 VNI 的范围是“1~1000”。(具体什么规则,我们暂时也忽略,笔者会在后面的章节中讲述,这里可以简单理解为“顺序规则”,即“第一个租户网络的 VNI 是 1,第 2 个租户网络的 VNI 是 2,以此类推”)
5.1.1.4.3 运营商网络的使用场景
笔者以为,这个是重点!
我们知道,OpenStack 是云的解决方案之一,云服务商通过 OpenStack 为租户提供云服务。所以,租户创建一个 Network,是这个云服务里面一个正常的服务,而且租户也需要为使用这个服务而付费(create Network)。
但是,一个管理员为什么要创建一个网络呢?这好比一个饭店的领班,你就好好地做你的领班,你去占用饭店的一个桌位干什么?那个桌位可是要招待客户的,可是要挣钱的。
这个时候,我们就需要仔细分析一下,管理员创建的所谓运营商网络的使用场景。
Neutron 的官网中,是这么描述 Provider Network 的:
Provider networks are created with administrative credentials, specifying the details of how the network is physically realized, usually to match some existing network in the data center.
Provider networks enable administrators to create networks that map directly to the physical networks in the data center. This is commonly used to give projects direct access to a public network that can be used to reach the Internet. It might also be used to integrate with VLANs in the network that already have a defined meaning (for example, enable a VM from the marketing department to be placed on the same VLAN as bare-metal marketing hosts in the same data center).
【注】摘自 https://docs.openstack.org/admin-guide/networking-adv-features.html
这段话,强调了一点:运营商网络指明了物理网络的细节,并且(通常)是为了匹配数据中心已经存在的网络。(注意,这里的物理网络,指的是真正的物理网络,不是“provider:physical_network”这个字段)
指明物理网络的细节,靠的就是前面我们介绍的那三个字段“provider:xxx”。
这段话还提到了运营商网络所涉及的两个使用场景。下面我们就来描述这两个场景。
(一)场景一:VM 外接 Internet
我们在“Neutron 网络实现模型”那一章中提到 Neutron 的实现模型如下:
图1 Neutron 网络实现模型(不考虑 DVR)
为了易于描述,我采取了不考虑 DVR 的网络实现模型(加上 DVR 的网络实现模型,对于这一个场景讲述而言,除了增加讲述的复杂度,并不会有什么原理上的不同)。
图中,我们看到,VM 要访问外部网络(access to a public network that can be used to reach the Internet),必须通过 Router 和 br-ex 两个部件(其他部件我们忽略)。
这个时候,我们需要将这个场景继续细化为两个子场景。
(1)br-ex 是普通的 Ethernet 转发
为了易于描述,我们继续把上述的实现模型简化,删除一些“无关”组件,如下图所示:
图2 Neutron 的简化实现模型
而当 br-ex 作为普通的 Ethernet 转发时,我们甚至可以忽略它的存在(虽然它实际上桥接了 Router 和物理网口),如下图所示:
图3 br-ex 做 Ethernet 转发时的 Neutron 简化实现模型
按道理说,这个时候,是不需要什么所谓的“Provider Network”的,只需要把 Router 相关的路由表配置正确即可。
但是,Neutron 有它的逻辑自洽性。逻辑自洽的意思是,按照它的原则,它能自圆其说,但是不代表它就是合理的。
Neutron 的原则是:一个 Router(这个 Router 指的是虚拟路由器) 如果是对接外部网络(External Network,Neutron 称之为 Public Network)时,那么,Router 这个对象(这个 Router 指的是 Neutron 的一个模型,名字叫 Router)必须与一个 Provider Network(Network Model 的实例)挂钩(本质上是与这个 Provider Network 的 Subnet 挂钩),也就是说,它的路由表,是根据这个 Provider Network 的Subnet 来自动创建的。(Router,Subnet 这两个 Model,笔者会有专门的章节进行描述,这里先这么简单理解)
Router、Network、Subnet 这三个 Model 之间的关系,如下图所示:
图4 三个 Model 之间的关系
图中,实线表示直接关系,虚线表示间接关系。
所以,到这里我们知道,在这种场景下,并不是真的需要 Provider Network 这个概念和实例,只是 Neutron 自己的设计如此。您完全可以不用 Provider Network 这个概念,一样能达到这样的效果。
不过,它就是这么玩的,咱也不好说什么,^_^。
另外,更关键的,另一种场景,则需要 Provider Network 这个概念。
(2)br-ex 作为隧道终结点
我们直接上图:
图5 br-ex 作为隧道终结点的 Neutron 简化实现模型
图中,隧道类型画的是 VXLAN,实际上,其他类型隧道也可以,比如 GRE。
br-ex 与 DC GW 之间是 VXLAN 连接,两者是此 VXLAN 连接的 VTEP。这个时候,我们看到,必须要有一种方法告知 Neutron/br-ex,这个网络类型是什么(VXLAN),这个网络“ID”(VNI)是什么。
这种场景,Provider Network 就是有必要的了。因为创建 Provider Network 时,会传入参数:provider:network_type, provider:segmentation_id,而这两个参数是必须的。
很美好,是吗?
不是!
br-ex 要成为隧道终结点,无论是 VXLAN 隧道还是 GRE 隧道,它都必须要知道两个信息:自身的 IP 地址,对端的 IP 地址。
这两个信息,Neutron 并没有接口(或者其他方法,比如配置文件)能配置下去。也就是说,这种场景,靠 Neutron 自己的接口是懵逼的,是不自洽的,只能依赖人工另外配置那两个信息。
这个时候,就监介了。(我们的宝岛台湾,竟然发布公告,说尴尬也可以读作“监介”。好吧,我们让 Neutron 也“监介”一次)
(3)两种子场景的总结
我们直接上表格:
| 子场景 |
分析 |
| br-ex 作为普通 Ethernet 转发 |
(1)原理上并不是真的需要 (2)逻辑上是自洽的(按照 Neutron 的自身逻辑,可以自圆其说) |
| br-ex 作为隧道终结点 |
(1)原理上是需要的 (2)逻辑上不能自洽(Neutron 的接口不完备) |
表2 两种子场景的总结
呵呵,我都有点心虚了。上一小节,我把“provider:physical_network”批判了一把,这里,又把 Provider Network 监介了一把,^_^
好吧,我们来看看第二个场景吧。
(二)场景二:虚机与主机混合服务
Neutron 是这样描述这个场景的:
It might also be used to integrate with VLANs in the network that already have a defined meaning (for example, enable a VM from the marketing department to be placed on the same VLAN as bare-metal marketing hosts in the same data center).
这个场景,笔者以为,确实是需要 Provider Network 这个概念的。
我们知道,仅仅是为 VM 服务的 Network(类型是 VLAN),如下图所示:
图6 单纯为 VM 服务的 VLAN 网络
上图中的计算节点模型,是一个简化模型。两个计算节点之间,通过 br-ethx,组成一个 Network,VLANID = 100。
通过前面介绍,我们知道,这个 Network 是一个租户网络。而租户网络的创建,我们知道,租户是不能(不需要)填写网络类型和网络“ID”的,这些都是配置在配置文件中。我们同样知道,这个网络类型,很可能配置为“VXLAN”,而网络“ID”,是 Neutron 按照一定的规则自动生成的。
此时,如果遇到云服务商提供“VM(虚机) + Host(主机)”混合服务,如下图所示:
图7 VM + Host 混合服务
这个时候,有两点很关键:
(1)网络类型,不能是通过配置文件来配置,因为配置文件配置的“单纯为虚机服务的租户网络类型”。比如配置文件可能配置为 VXLAN,而此时却需要的是 VLAN。
(2)网络“ID”,不能通过配置文件(配置的是“ID”范围) + Neutron 按照一定的规则来实现。因为这里的网络“ID”根本就没有规则,它是根据实际情况而乱七八糟变化的。
怎么办?必须直接传递参数,告知 Neutron:网路类型是什么,网络“ID”是什么。
这个时候,Tenant Network 就不能胜任了,而 Provider Network 正好可以解决这个问题。
而且,从名称上来讲,图中画的那个交换机,只是一个简单示意,实际可能是一个比较复杂的物理网络 ,而这个网络,确实就是“Provider Network”。
所以,Neutron 提出“Provider Network”这个概念,在这个场景下,无论是从原理上还是从名称上,都是合适的!
给 Neutron 点个赞!(呵呵,我都吐槽它半天了,终于点了一个赞)
(三)运营商网络使用场景总结
我们直接上表:
| 子场景 |
子场景 |
分析 |
| VM 外接 Internet |
br-ex 作为普通 Ethernet 转发 |
(1)原理上并不是真的需要 (2)逻辑上是自洽的(按照 Neutron 的自身逻辑,可以自圆其说) |
| br-ex 作为隧道终结点 |
(1)原理上是需要的 (2)逻辑上不能自洽(Neutron 的接口不完备) |
|
| 虚机与主机混合服务 |
虚机与主机混合服务 |
原理上合理,逻辑上自洽 |
表3 运营商网络使用场景总结
今天很晚了,明天还要上班,就到这吧!

微信扫一扫
关注该公众号