Kafka简介
Kafka简介
1.kafka是什么
1.1 Messaging System
kafka作为一个消息引擎具备哪些优势?
1.集成两种传统消息引擎的优点。
传统的消息引擎有两种模式:
- queuing
- publish-subscribe
queuing的缺点是消息不能重复消费,一个cosumer消费完后其他的consumer就不能再进行消费。
publish-subscribe 的缺点是,所有的consumer需要都去订阅主题(或者队列)这样就失去了扩展性,所有的consumer都要去订阅消费消息。
kafka使用了ConsumerGroup来同时实现了两种模式,扩展性强,又可以重复消费。
一个ConsumerGroup订阅一个Topic就是queuing模式。
多个ConsumerGroup订阅一个Topic就是publish-subscribe模式
2.Kafka has stronger ordering guarantees than a traditional messaging system, too.
kafka 对消息的顺序性有着很强的保障可以在不同的维度来保持消息的顺序性,这是其他的消息引擎所不能做到的。
- 分区顺序性(对需要保持顺序性的消息 ,使用相同key计算 hash来固定同一分区)
- 全局顺序性
3.持久化存储
Kafka 对消息的持久化是以LogSegment的形式持久化到磁盘的,由于消息是持久存储的(没有过清理时间,事实上,如果需要长时间存储,可以调大消息的持久化时间)。所以我们可以对消息做各种我们需要的处理。
4.消息Exactly once 的保障
MQTT 协议中,给出了三种传递消息时能够提供,服务质量标准,这三种服务质量从低到高依次是:
- At most once : 至多一次,传递过程中,只发送一次,不管是否发送失败。消息可能会发送失败,但是不会重复。
- at least once : 至少一次,消息不会丢失,可能会重复
- exactly once : 恰好一次 消息只被存储一次,不会丢失,也不会重复
我们可以看出消息的服务质量的最高的标准当然是 exctly once,kakfa通过事务性和幂等性实现了它。
保证了消息指存储到broker上一次,只发送给consumer一次。(但是这样做肯定是要牺牲掉kafka引以为傲的性能优势的。)
另外,作为业界的消息防止重复消费的模式:一般都是实现消费端去重或者消费端幂等性。具体选用哪种方式要根据我们现实的业务去评估选择最适合自己的方式。
5.高性能
如图为 kafka 、pulsar、rabbitmq的性能对比:
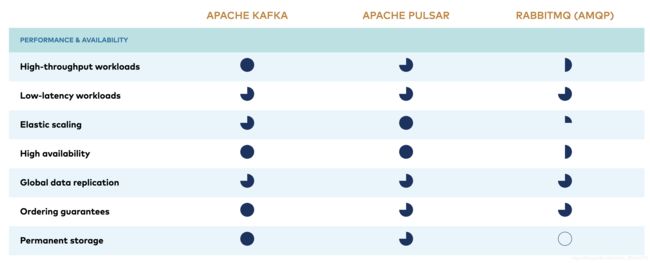
关于kafka、pulsar、rabbitmq的具体对比和解释请参考confluent官网kafak vs pulsar vs rabbitmq)
1.2 Distributed streaming platform
传统流处理平台
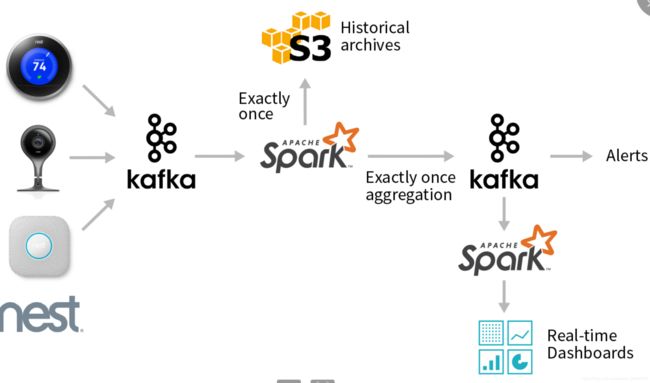
为kafka+Spark 实现的一个流处理平台。通过一些第三方的插件进行数据采集,然后放入kafka中,Sprak订阅Kafka获取数据,进行流处理操作,然后将处理后的数据再放入kafka中,后续的就是对处理的数据进行展示,存储等等的操作。
Kafka作为流处理平台
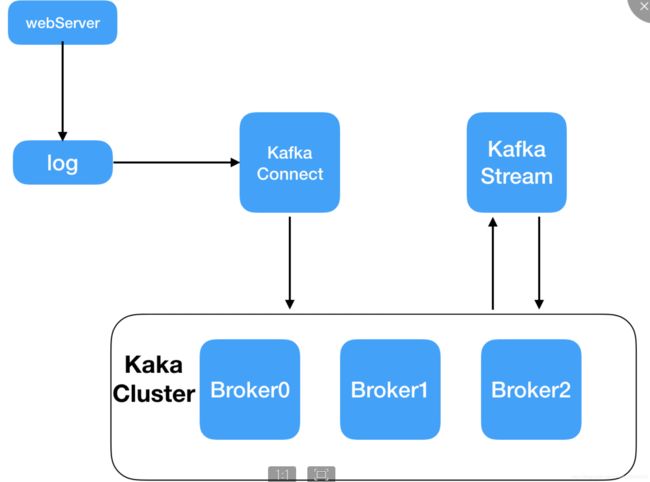
如图所示,为kafka 流处理的一次过程,首先Kakfa Connect 从日志服务器中拉取数据,发布一个特定的Topic到Kafka Cluster,然后Kafka Stream 从Kafka Cluster 中订阅主题,并且拉取消息进行流处理,处理完成后的数据在通过一个特定的Topic写入到kafka cluster ,需要获取流处理后的数据只需要订阅并拉取相应的主题即可,一次流处理结束。
Kafka具备的优势
1.更容易实现端到端的正确性(Correctness)
如右图所示为一次流处理的过程,主要的组件就是kafka 和Spark,kafka采集数据,交给Spark,Sprak处理完之后再放回kafka,不管是kafka和Spark都实现了Exactly ocne的消息服务等级,但是都是针对与框架内的,所以Kafka给Spark和Spark给Kafka 是否能实现精确一次处理语义,还不得而只。如果整个过程都是用kafka来做不,不仅仅降低了架构的复杂性,而且可以实现Exactly once,何乐而不为。
2.kafka对自己流处理平台的定位
Kafka Streams是一个用于搭建实时流处理的客户端库而非是一个完整的功能系统。
kafka不提供类似于集群调度、弹性部署等功能,都需要选择合适的工具或者系统来实现这些功能。所以说作为一个流处理平台来说,kafka更适合与中小型的企业,不必要搭建很大的一个集群环境。
1.3 Storage System
kafka持久化的特性,虽然得到极少的应用,但是在官网的 Ecosystem上可以看到,kafak还是非常适合做Event Sourcing的存储的。
Event Sourcing
领域驱动设计(Domain-Driven Design DDD)的名词,事件序列来表示状态变更,与kafka不可变更的消息序列来抽象化消息表示业务消息的设计理念不谋而合,非常适合Kafka来进行存储。
2.Kafka使用场景

1.消息传输
Kafka系统具备传统的消息总线或者消息代理解耦生产者消费者的功能,还具备批处理的功能,Kafka本身还具备吞吐量高,高可用和高容错性等特性,所以Kafka特别适合用于实现一个超大量级消息处理应用。
2.网站行为日志追踪
网站上用户操作的流量是非常大的,kafka的超强吞吐量也有了用武之地。
3.审计数据收集
可以便捷的对多路消息进行实时收集,持久化的特性,也可以给后续的离线审计提供可能性。(Kafka的持久化特性)
4.日志收集
目前我们所见的kafka最常用的使用方式了,每个企业都会产生大量的日志,Kafka可以对这些日志进行全量收集,并集中送到下游的分布式存储系统中,相比较于其他的主流日志抽取框架(Apache Flume)kafka性能更高,延时更低。
5.Event Sourcing
领域驱动设计(Domain-Driven Design DDD)的名词,事件序列来表示状态变更,与kafka不可变更的消息序列来抽象化消息表示业务消息的设计理念不谋而合,非常适合Kafka来进行存储。
6.流式处理
做为kafka0.10.0.0推出的新功能,竞争力还需时间的检验。