tensorflow2.0 实现垃圾分类 (加入注意力机制)
1 垃圾分类
数据下载:
https://pan.baidu.com/s/1sbyoJjVy51BXxoAJ9tUatg
密码:9a2g
有两种形式,一种是未加注意力通道的卷积。这种卷积运算速度较快,但是识别率低一些。我们进去代码看一下:
1.1导入需要的包
import numpy as np
import matplotlib.pyplot as plt
from keras.preprocessing.image import ImageDataGenerator,load_img,img_to_array,array_to_img
from tensorflow.keras import layers,Sequential,regularizers
from keras.layers import Conv2D,Flatten,MaxPooling2D,Dense
from keras.models import Sequential
import tensorflow.keras as keras
import glob,os,random
import tensorflow as tf
1.2导入数据,查看数据
base_path = "img地址"
img_list = glob.glob(os.path.join(base_path,"*/*.jpg"))
print(len(img_list)) #2295
#随机查看数据
for i, img_path in enumerate(random.sample(img_list, 6)):
img = load_img(img_path)
img = img_to_array(img, dtype=np.uint8)
plt.subplot(2, 3, i+1)
plt.imshow(img.squeeze())

1.3对数据进行划分及增强
train_datagen = ImageDataGenerator(
rescale=1./255, shear_range=0.1, zoom_range=0.1,
width_shift_range=0.1, height_shift_range=0.1, horizontal_flip=True,
vertical_flip=True, validation_split=0.1)
test_data = ImageDataGenerator(rescale=1./255,validation_split=0.1)
train_generator = train_datagen.flow_from_directory(
base_path, target_size=(300, 300), batch_size=16,
class_mode='categorical', subset='training', seed=0)
validation_generator = test_data.flow_from_directory(base_path,target_size=(300,300),
batch_size=16,class_mode="categorical",subset="validation",seed=0 )
labels = (train_generator.class_indices)
labels = dict((v,k) for k,v in labels.items())
print(labels)
#Found 2068 images belonging to 6 classes.
#Found 227 images belonging to 6 classes.
#{0: 'cardboard', 1: 'glass', 2: 'metal', 3: 'paper', 4: 'plastic', 5: 'trash'}
1.4 无注意力通道的网络模型
- 愿意尝试这个网络模型就把下面添加注意通道的网络注释掉就可以
# model = Sequential([
# Conv2D(filters=32, kernel_size=3, padding='same', activation='relu', input_shape=(300, 300, 3)),
# MaxPooling2D(pool_size=2),
# Conv2D(filters=64, kernel_size=3, padding='same', activation='relu'),
# MaxPooling2D(pool_size=2),
# Conv2D(filters=32, kernel_size=3, padding='same', activation='relu'),
# MaxPooling2D(pool_size=2),
# Conv2D(filters=32, kernel_size=3, padding='same', activation='relu'),
# MaxPooling2D(pool_size=2),
# Flatten(),
# Dense(64, activation='relu'),
# Dense(6, activation='softmax')
# ])
#model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])
#model.fit_generator(train_generator, epochs=100, steps_per_epoch=2276//32,validation_data=validation_generator,
# validation_steps=251//32)
1.4 添加通道注意力机制模型
我们在编写注意力通道模型时,先解释一下这个注意力机制
注意力机制分为:通道注意力机制 和 空间注意力机制
通道注意力模型结构:
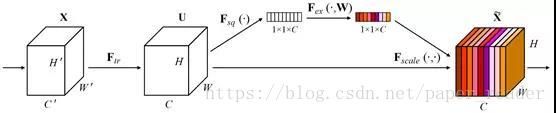
在这里我用的不是SEnet 插件网络。而是用的CBAM插件网络。
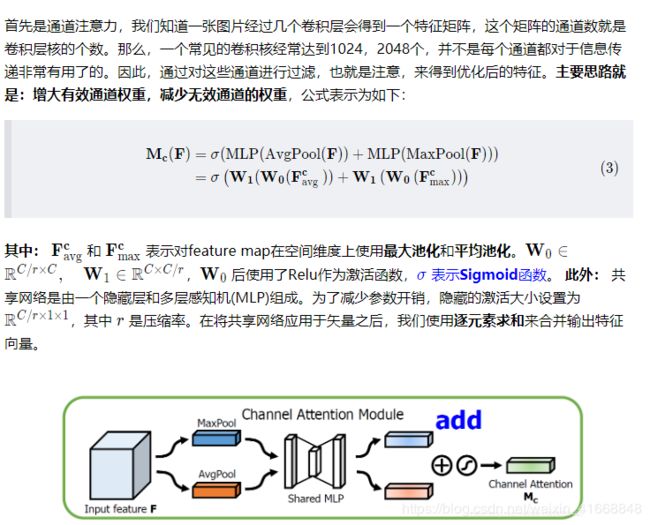
我们进入代码:
inputs = keras.Input(shape=(300,300,3),name="img")
h1 = layers.Conv2D(filters=32, kernel_size=3,padding="same",activation="relu")(inputs)
h1 = layers.MaxPooling2D(pool_size=2)(h1)
h1 = layers.BatchNormalization()(h1)
h1 = layers.Conv2D(filters=64, kernel_size=3, padding='same', activation='relu')(h1)
h1 = layers.MaxPooling2D(pool_size=2)(h1)
h1 = layers.BatchNormalization()(h1)
h1 = layers.Conv2D(filters=32, kernel_size=3, padding='same', activation='relu')(h1)
h1 = layers.MaxPooling2D(pool_size=2)(h1)
h1 = layers.BatchNormalization()(h1)
h1 = layers.Conv2D(filters=64, kernel_size=3, padding='same', activation='relu')(h1)
h1 = layers.MaxPooling2D(pool_size=2)(h1)
h1 = layers.BatchNormalization()(h1)
#加入通道注意力机制
#全局平均
hs = layers.GlobalAveragePooling2D()(h1)
hs = layers.Reshape((1,1,hs.shape[1]))(hs)
hs = layers.Conv2D(64//16,kernel_size=1,strides=1,padding="same",kernel_regularizer=regularizers.l2(1e-4),use_bias=True,activation="relu")(hs)
hs = layers.Conv2D(64,kernel_size=1,strides=1,
padding= "same",
kernel_regularizer=regularizers.l2(1e-4),
use_bias=True)(hs)
#全局最大
hb = layers.GlobalMaxPooling2D()(h1)
print(hb.shape[1])
hb = layers.Reshape((1,1,hb.shape[1]))(hb)
hb = layers.Conv2D(64//16,kernel_size=1,strides=1,padding="same",kernel_regularizer=regularizers.l2(1e-4),use_bias=True,activation="relu")(hb)
hb = layers.Conv2D(64,kernel_size=1,strides=1,padding= "same",kernel_regularizer=regularizers.l2(1e-4),use_bias=True)(hb)
out = hs + hb #最大加平均
out = tf.nn.sigmoid(out)
out = out * h1
out = layers.Flatten()(out)
out = layers.Dense(64,activation="relu")(out)
outputs = layers.Dense(6,activation="softmax")(out)
model = keras.Model(inputs,outputs,name="smallnet")
加入损失函数模块和优化模块、准确率模块
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['acc'])
#训练模型
model.fit_generator(train_generator, epochs=100, steps_per_epoch=2068//32,validation_data=validation_generator,
validation_steps=227//32)
1.5测试并查看预测图片
test_x, test_y = validation_generator.__getitem__(1)
preds = model.predict(test_x)
plt.figure(figsize=(16, 16))
for i in range(16):
plt.subplot(4, 4, i+1)
plt.title('pred:%s / truth:%s' % (labels[np.argmax(preds[i])], labels[np.argmax(test_y[i])]))
plt.imshow(test_x[i])
到这里就结束了。
总结:
加入了通道注意力,准确率非常高了,我随机了10几次抽查预测的图片,发下预测错误只有1次。
通道注意力部分参考自:
https://blog.csdn.net/abc13526222160/article/details/103765484