数据结构精录&总结Episode.6 数据结构入门之树(基于Visual C++)
好久(可能一周)没有更新博文了吧。
国内的疫情控制情况已经接近尾声,同样地我们的这一学期也快接近尾声。其实感觉宅家学习虽然远远没有学校那么紧张了,但是效率有所降低,生活规律性也降低了。早晨很晚才起床但是会觉得很困,而在学校每天六点在北京的街头天还没亮吹着风骑车前往图书馆的日子反而感觉精神百倍。
子非鱼,焉知鱼之乐?佳句啊,而且被某位同学用在这里感觉更是多了一份回雪吹风之爽朗。
树是数据结构里面一种玄学的东西,我们知道顺序结构找到特定元素是O(1)的复杂度,但是移动删除等等却需要O(n)的复杂操作。链表存储结构与之相反。树正是这样一种结合了两者优点的存储结构,因为其多分枝的性质,使他能在O(logn)的时间里完成所有查找更新插入删除的操作。对于节点数量很大也即n值较大,同时需要进行多种类型的操作时,树存储结构无疑是首选的。
树的一些名词定义:
以下给出了树的一些重点的标准化中文定义,这些定义共同构成了我们这种全新的数据结构的总定义。
1、节点:数据元素及分支信息统称为节点
2、节点的度:节点拥有的子树个数
3、树的度:树种最大的节点的度
4、终端(叶子):度为0的节点
5、分支:度大于0的节点
6、内部:除了树根和叶子都是内部节点
7、双亲、孩子、兄弟、堂兄弟、祖先和子孙分别对应:根节点、子节点、双亲相同的节点、双亲是兄弟的节点、从树根到该节点经过的所有节点以及节点的子树中包含的所有节点
8、有序树和无序树分别代表:节点的各子数左右有序及节点各子树可以互换位置的树
9、森林:m>=0棵不相交的树组成的集合
10、二叉树:
①二叉树的性质包含:节点数(i层上之多2^(i-1)个节点)、深度(深度为k的最多有2^k-1个节点也就是满二叉树)、层数(n个节点的完全二叉树深度必为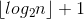 )、满二叉树、完全二叉树,后两者依据字面意义,不难理解,仅需注意满二叉树和完全二叉树的唯一区别是判定最后一层。满二叉树是全满,深度k的节点数2^k-1。完全二叉树是最后一层半满且节点均为从左至右出现。
)、满二叉树、完全二叉树,后两者依据字面意义,不难理解,仅需注意满二叉树和完全二叉树的唯一区别是判定最后一层。满二叉树是全满,深度k的节点数2^k-1。完全二叉树是最后一层半满且节点均为从左至右出现。
②n=m+1其中n为叶子数,m为2度的节点数
③对于完全二叉树,从上至下从左至右编号,则编号i的节点,其左孩子编号2i,右孩子编号2i+1,双亲的编号必为i/2
树的存储结构有五种,其中顺序存储包含:双亲表示法、孩子表示法、双亲孩子表示法。链式存储包含:孩子链表示法,孩子兄弟表示法。依据字面意义及之前提到的创建链表的具体代码方式,不难给出树的存储结构算法。
谈到树,我们不得不深入研究二叉树的具体性质。这是因为利用下面的口诀,我们可以将所有简单的树转化为二叉树,并且让一个不太容易研究性质的树结构变得紧凑而实用起来:
长子当作左孩子,兄弟关系向右斜。
什么意思呢, 首先树、森林与二叉树之间有一个自然的对应关系,它们之间可以互相进行转换,即任何一个森林或一棵树都可以唯一地对应一棵二叉树,而任何一棵二叉树也能唯一地对应到一个森林或一棵树上。树到二叉树的转换是孩子兄弟表示法,一个节点两个指针,一个指向长子,一个指向它右边的兄弟。这样就会生成一棵二叉树,左孩子是长子,长子的右子树是它的兄弟们。就是往左是长子,往右是其他兄弟。森林也是对应的。例如下面这个一般的树的结构例子:
A
/|\
B C D
转换成二叉树之后就是:
A
/
B
\
C
\
D
同样森林也可以转成二叉树,将森林中每棵树的根节点当成是平级的兄弟节点,依然是“左子女,右兄弟”的方式。
对于二叉树来说,遍历算法是比较重要的,它从根节点出发,按照某种次序依次访问二叉树中的所有节点,使得每个节点被访问一次且仅被访问一次的操作,我们给出了树存储结构的几种最佳查找算法选择,是历年来期末考研和面试的重点问题。这里用一个简单的导图即可描述:
1、前序遍历:根-左-右
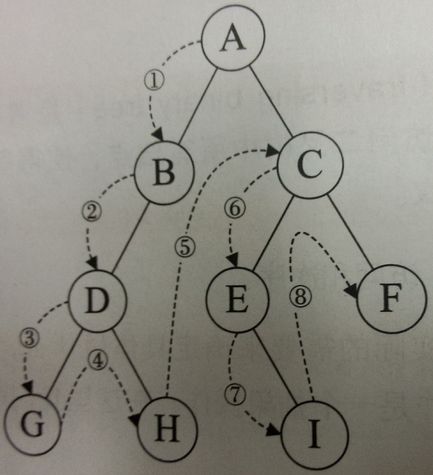
2、中序遍历:左-根-右

3、后序遍历:左-右-根
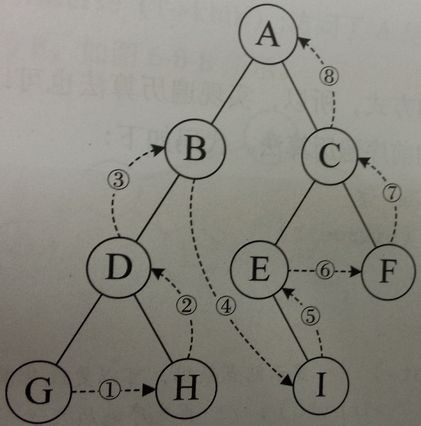
4、层序遍历:从根节点出发,依次访问左右孩子结点,再从左右孩子出发,依次它们的孩子结点,直到节点访问完毕
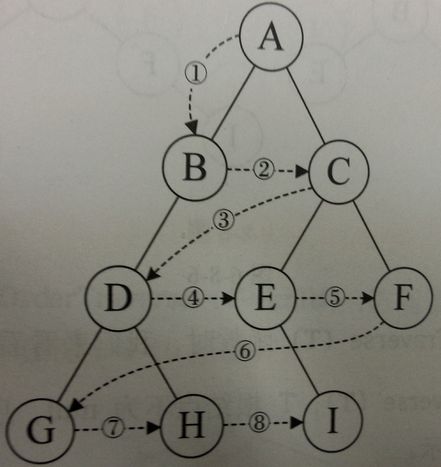
运用以上四种方式,的确可以遍历整个二叉树,但是遍历好后我们得到的是一个存有二叉树全部节点数据信息的单链式结构,如何将其还原为之前的二叉树呢?这里我们给出了几种条件下还原二叉树的算法:
P.S.给出二叉树的前序序列和后序序列是不能唯一还原二叉树的!
1、已知先序序列和中序序列还原二叉树的递归方法:先序序列第一个字符为根→中序序列以根为中心划分左右→还原左右子数→对左右子数分别重复上述操作
2、已知后序序列和中序序列还原二叉树的递归方法:后序序列最后一个字符为根→中序序列以根为中心划分左右→还原左右子数→对左右子数分别重复上述操作
对于树和森林的还原,我们先依据上述规则还原二叉树,然后逆向进行长子当作左孩子,兄弟关系向右斜。即可将二叉树继续还原成树或者森林。
提到哈夫曼树和哈夫曼算法,我们需要先回忆哈夫曼编码在信息论中的介绍:
哈弗曼编码的目的是,如何用更短的bit来编码数据。
通过变长编码压缩编码长度。我们知道普通的编码都是定长的,比如常用的ASCII编码,每个字符都是8个bit。但在很多情况下,数据文件中的字符出现的概率是不均匀的,比如在一篇英语文章中,字母“E”出现的频率最高,“Z”最低,这时我们可以使用不定长的bit编码,频率高的字母用比较短的编码表示,频率低的字母用长的编码表示。
但这就要求编码要符合“前缀编码”的要求,即较短的编码不能是任何较长的编码的前缀,这样解析的时候才不会混淆。要生成这种编码,最方便的就是用二叉树,把要编码的字符放在二叉树的叶子上,所有的左节点是0,右节点是1,从根浏览到叶子上,因为字符只能出现在树叶上,任何一个字符的路径都不会是另一字符路径的前缀路径,符合前缀原则编码就可以得到。
给定n个权值作为n个叶子结点,构造一棵二叉树,若树的带权路径长度达到最小,则这棵树被称为哈夫曼树。对于一个哈夫曼树,通过算法是可以保证这个路径长度一直稳定在最小值的。
哈夫曼算法的步骤是这样的:
- 从各个节点中找出最小的两个节点,给它们建一个父节点,值为这两个节点之和。
- 然后从节点序列中去除这两个节点,加入它们的父节点到序列中。
- 重复上面两个步骤,直到节点序列中只剩下唯一一个节点。这时一棵最优二叉树就已经建成了,它的根就是剩下的这个节点。
以下为上述树数据结构的总结代码:
// 第六章 树.cpp : 此文件包含 "main" 函数。程序执行将在此处开始并结束。编写—JoeyBG,算法尚有不足之处,敬请谅解。
//
/*
#include
#include
#include
#include
using namespace std;
*/
// 运行程序: Ctrl + F5 或调试 >“开始执行(不调试)”菜单
// 调试程序: F5 或调试 >“开始调试”菜单
// 入门使用技巧:
// 1. 使用解决方案资源管理器窗口添加/管理文件
// 2. 使用团队资源管理器窗口连接到源代码管理
// 3. 使用输出窗口查看生成输出和其他消息
// 4. 使用错误列表窗口查看错误
// 5. 转到“项目”>“添加新项”以创建新的代码文件,或转到“项目”>“添加现有项”以将现有代码文件添加到项目
// 6. 将来,若要再次打开此项目,请转到“文件”>“打开”>“项目”并选择 .sln 文件 //二叉树的创建
#include
using namespace std;
typedef struct Bnode{ /*定义二叉树存储结构*/
char data;
struct Bnode *lchild,*rchild;
}Bnode,*Btree;
void createtree(Btree &T) /*创建二叉树函数*/
{
char check; /*判断是否创建左右孩子*/
T=new Bnode;
cout<<"请输入结点信息:"<>T->data;
cout<<"是否添加 "<data<<"的左孩子? (Y/N)"<>check;
if(check=='Y')
createtree(T->lchild);
else
T->lchild=NULL;
cout<<"是否添加"<data<<"的右孩子? (Y/N)"<>check;
if(check=='Y')
createtree(T->rchild);
else
T->rchild=NULL;
return;
}
int main()
{
Btree mytree;
createtree(mytree);/*创建二叉树*/
return 0;
}
//二叉树的四大遍历算法
#include
#include//引入队列头文件
using namespace std;
typedef struct Bnode{/*定义二叉树存储结构*/
char data;
struct Bnode *lchild,*rchild;
}Bnode,*Btree;
void Createtree(Btree &T) /*创建二叉树函数*/
{
//按先序次序输入二叉树中结点的值(一个字符),创建二叉链表表示的二叉树T
char ch;
cin>>ch;
if(ch=='#')
T=NULL; //递归结束,建空树
else{
T=new Bnode;
T->data=ch; //生成根结点
Createtree(T->lchild); //递归创建左子树
Createtree(T->rchild); //递归创建右子树
}
}
void preorder(Btree T)//先序遍历
{
if(T)
{
cout<data<<" ";
preorder(T->lchild);
preorder(T->rchild);
}
}
void inorder(Btree T)//中序遍历
{
if(T)
{
inorder(T->lchild);
cout<data<<" ";
inorder(T->rchild);
}
}
void posorder(Btree T)//后序遍历
{
if(T)
{
posorder(T->lchild);
posorder(T->rchild);
cout<data<<" ";
}
}
bool Leveltraverse(Btree T)
{
Btree p;
if(!T)
return false;
queueQ; //创建一个普通队列(先进先出),里面存放指针类型
Q.push(T); //根指针入队
while(!Q.empty()) //如果队列不空
{
p=Q.front();//取出队头元素作为当前扩展结点livenode
Q.pop(); //队头元素出队
cout<data<<" ";
if(p->lchild)
Q.push(p->lchild); //左孩子指针入队
if(p->rchild)
Q.push(p->rchild); //右孩子指针入队
}
return true;
}
int main()
{
Btree mytree;
cout<<"按先序次序输入二叉树中结点的值(孩子为空时输入#),创建一棵二叉树"< //创建及遍历中序线索二叉树
#include
using namespace std;
//线索二叉树的存储结点
typedef struct BTnode
{
char data; //结点数据域
struct BTnode *lchild,*rchild; //左右孩子指针
int ltag,rtag;
}BTnode,*BTtree;
//全局变量pre
BTtree pre;
//创建二叉树(补空法)
void CreateBiTree(BTtree &T)
{
//按先序次序输入二叉树中结点的值(一个字符),创建二叉链表表示的二叉树T
char ch;
cin>>ch;
if(ch=='#') T=NULL; //递归结束,建空树
else
{
T=new BTnode;
T->data=ch; //生成根结点
CreateBiTree(T->lchild); //递归创建左子树
CreateBiTree(T->rchild); //递归创建右子树
}
}
void InThread(BTtree &p)//中序线索化
{
//pre是全局变量,指向当前结点p的前驱
if(p)
{
InThread(p->lchild); //左子树递归线索化
if(!p->lchild) //p的左孩子为空
{
p->ltag=1; //给p加上左线索
p->lchild=pre; //p的左孩子指针指向pre(前驱)
}
else
p->ltag=0;
if(pre)
{
if(!pre->rchild) //pre的右孩子为空
{
pre->rtag=1; //给pre加上右线索
pre->rchild=p; //pre的右孩子指针指向p(后继)
}
else
pre->rtag=0;
}
pre=p; //保持pre指向p的前驱
InThread(p->rchild); //右子树递归线索化
}
}
void CreateInThread(BTtree &T)//创建中序线索二叉树
{
pre=NULL;//初始化为空
if(T)
{
InThread(T); //中序线索化
pre->rchild=NULL;// 处理遍历的最后一个结点,其后继为空
pre->rtag=1;
}
}
void Inorder(BTtree T)//中序遍历二叉树
{
if(T)
{
Inorder(T->lchild);
cout<data<<" ";
Inorder(T->rchild);
}
}
void InorderThread(BTtree T)//遍历中序线索二叉树
{
BTtree p;
p=T;
while(p)
{
while(p->ltag==0) p=p->lchild; //找最左结点
cout<data<<" ";//输出结点信息
while(p->rtag==1&&p->rchild) //右孩子为线索化,指向后继
{
p=p->rchild; //访问后继结点
cout<data<<" ";//输出结点信息
}
p=p->rchild;//转向p的右子树
}
}
int main()
{
BTtree tree;
cout<<"请输入先序创建二叉树的序列(补空法):\n";//例如ABD##E##CF#G###
CreateBiTree(tree); //创建二叉树
cout<<"二叉树的中序遍历结果:\n";
Inorder(tree); //中序遍历二叉树
cout< //二叉树的深度计算器
#include
using namespace std;
typedef struct Bnode /*定义二叉树存储结构*/
{ char data;
struct Bnode *lchild,*rchild;
}Bnode,*Btree;
void Createtree(Btree &T) /*创建二叉树函数*/
{
//按先序次序输入二叉树中结点的值(一个字符),创建二叉链表表示的二叉树T
char ch;
cin>>ch;
if(ch=='#')
T=NULL; //递归结束,建空树
else{
T=new Bnode;
T->data=ch; //生成根结点
Createtree(T->lchild); //递归创建左子树
Createtree(T->rchild); //递归创建右子树
}
}
int Depth(Btree T)//求二叉树的深度
{
int m,n;
if(T==NULL)//如果为空树,深度为0
return 0;
else
{
m=Depth(T->lchild);//递归计算左子树深度
n=Depth(T->rchild);//递归计算左子树深度
if(m>n)
return m+1;//返回左右子树最大值加1
else
return n+1;
}
}
int main()
{
Btree mytree;
cout<<"按先序次序输入二叉树中结点的值(孩子为空时输入#),创建一棵二叉树"< //二叉树的节点和叶子数计算器
#include
using namespace std;
typedef struct Bnode{ /*定义二叉树存储结构*/
char data;
struct Bnode *lchild,*rchild;
}Bnode,*Btree;
void Createtree(Btree &T) /*创建二叉树函数*/
{
//按先序次序输入二叉树中结点的值(一个字符),创建二叉链表表示的二叉树T
char ch;
cin>>ch;
if(ch=='#')
T=NULL; //递归结束,建空树
else{
T=new Bnode;
T->data=ch; //生成根结点
Createtree(T->lchild); //递归创建左子树
Createtree(T->rchild); //递归创建右子树
}
}
int LeafCount(Btree T)//求二叉树的叶子数
{
if(T==NULL)//如果为空树,深度为0
return 0;
else
if(T->lchild==NULL&&T->rchild==NULL)//左右子树均为空,则叶子数为1
return 1;
else
return LeafCount(T->lchild)+LeafCount(T->rchild);//递归计算左子树和右子树的叶子数之和
}
int NodeCount(Btree T)//求二叉树的结点数
{
if(T==NULL)//如果为空树,深度为0
return 0;
else
return NodeCount(T->lchild)+NodeCount(T->rchild)+1;//递归计算左子树和右子树的结点数之和加1
}
int main()
{
Btree mytree;
cout<<"按先序次序输入二叉树中结点的值(孩子为空时输入#),创建一棵二叉树"< //利用三元组节点进行二叉树的几大遍历方式的实现算法
#include
#include
#include
using namespace std;
/*
输入三元组 (F、C、L/R) 序列输入一棵二叉树的诸边(其中 F 表示双亲结点的标识,C 表示孩子结点标识,L/R 表示 C 为 F 的左孩子或右孩子),
且在输入的三元组序列中,C 是按层次顺序出现的。
设结点的标识是字符类型。F=NULL时 C 为根结点标识,若 C 亦为NULL,则表示输入结束。
试编写算法,由输入的三元组序列建立二叉树的二叉链表,并以先序、中序、后序序列输出。
*/
/*测试数据
NULL A L
A B L
A C R
B D R
C E L
C F R
D G L
F H L
NULL NULL L
*/
struct biTnode
{
string data;
biTnode *lChild,*rChild;
};
biTnode* T=NULL;
void CreatebiTree(biTnode* &T)
{
string a,b,c;
biTnode *node,*p;
queueq;
cin>>a>>b>>c;
if(a=="NULL"&&b!="NULL")//创建根结点
{
node=new biTnode;
node->data=b;
node->lChild=node->rChild=NULL;
T=node;
q.push(T);
}
cin>>a>>b>>c;
while(!q.empty()&&a!="NULL"&&b!="NULL")
{
p=q.front();
q.pop();
while(a==p->data)
{
node=new biTnode;
node->data=b;
node->lChild=node->rChild=NULL;
if(c=="L")
{
p->lChild=node;
cout<data<<"'s lChild is "<data<rChild=node;
cout<data<<"'s rChild is "<data<>a>>b>>c;
}
}
}
void preorder(biTnode* &T)
{
if(T)
{
cout<data<<" ";
preorder(T->lChild);
preorder(T->rChild);
}
}
void inorder(biTnode* &T)
{
if(T)
{
inorder(T->lChild);
cout<data<<" ";
inorder(T->rChild);
}
}
void posorder(biTnode* &T)
{
if(T)
{
posorder(T->lChild);
posorder(T->rChild);
cout<data<<" ";
}
}
int main()
{
cout<<"输入结点数据a,b,c(a为父亲,b为结点字符,c为‘L’左孩子或‘R’右孩子)"< //两类条件下的二叉树还原算法
#include
using namespace std;
typedef struct node
{
char data;
struct node *lchild,*rchild;
}BiTNode,*BiTree;
BiTree pre_mid_createBiTree(char *pre,char *mid,int len) //前序中序还原建立二叉树
{
if(len==0)
return NULL;
char ch=pre[0]; //找到先序中的第一个结点
int index=0;
while(mid[index]!=ch)//在中序中找到的根结点的左边为该结点的左子树,右边为右子树
{
index++;
}
BiTree T=new BiTNode;//创建根结点
T->data=ch;
T->lchild=pre_mid_createBiTree(pre+1,mid,index);//建立左子树
T->rchild=pre_mid_createBiTree(pre+index+1,mid+index+1,len-index-1);//建立右子树
return T;
}
BiTree pro_mid_createBiTree(char *last,char *mid,int len)//后序中序还原建立二叉树
{
if(len==0)
return NULL;
char ch=last[len-1]; //取得后序遍历顺序中最后一个结点
int index=0;//在中序序列中找根结点,并用index记录长度
while(mid[index]!=ch)//在中序中找到根结点,左边为该结点的左子树,右边为右子树
index++;
BiTree T=new BiTNode;//创建根结点
T->data=ch;
T->lchild=pro_mid_createBiTree(last,mid,index);//建立左子树
T->rchild=pro_mid_createBiTree(last+index,mid+index+1,len-index-1);//建立右子树
return T;
}
void pre_order(BiTree T)//前序递归遍历二叉树
{
if(T)
{
cout<data;
pre_order(T->lchild);
pre_order(T->rchild);
}
}
void pro_order(BiTree T)//后序递归遍历二叉树
{
if(T)
{
pro_order(T->lchild);
pro_order(T->rchild);
cout<data;
}
}
int main()
{
BiTree T;
int n;
char pre[100],mid[100],last[100];
cout<<"1. 前序中序还原二叉树\n";
cout<<"2. 后序中序还原二叉树\n";
cout<<"0. 退出\n";
int choose=-1;
while(choose!=0)
{
cout<<"请选择:";
cin>>choose;
switch(choose)
{
case 1://前序中序还原二叉树
cout<<"请输入结点的个数:"<>n;
cout<<"请输入前序序列:"<>pre[i];
cout<<"请输入中序序列:"<>mid[i];
T=pre_mid_createBiTree(pre,mid,n);
cout<>n;
cout<<"请输入后序序列:"<>last[i];
cout<<"请输入中序序列:"<>mid[i];
T=pro_mid_createBiTree(last,mid,n);
cout< //哈夫曼树
#include
#include
#include
using namespace std;
#define MAXBIT 100
#define MAXVALUE 10000
#define MAXLEAF 30
#define MAXNODE MAXLEAF*2 -1
typedef struct
{
double weight;
int parent;
int lchild;
int rchild;
char value;
}HNodeType; /* 结点结构体 */
typedef struct
{
int bit[MAXBIT];
int start;
}HCodeType; /* 编码结构体 */
HNodeType HuffNode[MAXNODE]; /* 定义一个结点结构体数组 */
HCodeType HuffCode[MAXLEAF];/* 定义一个编码结构体数组*/
/* 构造哈夫曼树 */
void HuffmanTree(HNodeType HuffNode[MAXNODE],int n)
/* i、j:循环变量,m1、m2:构造哈夫曼树不同过程中两个最小权值结点的权值,
x1、x2:构造哈夫曼树不同过程中两个最小权值结点在数组中的序号*/
{
int i,j,x1,x2;
double m1,m2;
/*初始化存放哈夫曼树数组HuffNode[]中的结点 */
for(i=0;i<2*n-1;i++)
{
HuffNode[i].weight=0;//权值
HuffNode[i].parent=-1;
HuffNode[i].lchild=-1;
HuffNode[i].rchild=-1;
}
/* 输入 n 个叶子结点的权值 */
for(i=0;i>HuffNode[i].value>>HuffNode[i].weight;
}
/* 构造 Huffman 树 */
for(i=0;i>n;
HuffmanTree(HuffNode,n); //构造哈夫曼树
HuffmanCode(HuffCode,n); // 哈夫曼树编码
//输出已保存好的所有存在编码的哈夫曼编码
for(i=0;i /*
参考资料:
1、陈小玉:趣学数据结构,人民邮电出版社,2019.09
2、world_7735:二叉树遍历(图解),简书,https://www.jianshu.com/p/55763ece5de5
3、joannae:经典贪心算法(哈夫曼算法,Dijstra单源最短路径算法,最小费用最大流),https://www.cnblogs.com/qionglouyuyu/p/4850679.html
*/北京理工大学徐特立学院乐学平台上含有几个关于树存储结构的练习题,这里我们给出具体的题目和代码,可供参考:
1、判断两棵二叉树是否相似:
按先序遍历序列建立两个二叉树的二叉链表 A 和链表 B ,设计算法判断 A 、 B 二叉树是否相似。
这个问题有两个不同的算法可以实现,这里我们以函数的形式进行分析:其一是层次遍历法,其二是递归算法,本质都是遍历+if语句判断的形式完成的相似性鉴别。
//层次遍历法判断两棵树是否相似
bool IsSemblable1(BiTree T1,BiTree T2)
{
stack _sta1,_sta2; //用来存放下一层元素的容器,此处栈和队列都行
BiTNode *p1 = T1,*p2 = T2; //p1用来跟踪T1,p2用来跟踪T2
while((_sta1.empty() == false || p1 != NULL) &&(_sta2.empty() == false || p2 != NULL))
{
if(p1 != NULL && p2 != NULL ) //如果p1和p2都不为空时
{
if(p1->lchild != NULL && p2->lchild != NULL) //如果p1和p2的左子树都不为空时
{
_sta1.push(p1->lchild);
_sta2.push(p2->lchild);
}
else if( p1->lchild != NULL || p2->lchild != NULL) //如果p1的左子树为空,但是p2的左子树不为空,或者相反
return false;
if(p1->rchild != NULL && p2->rchild != NULL) //如果p1和p2的右子树都不为空时
{
_sta1.push(p1->rchild);
_sta2.push(p2->rchild);
}
else if(p1->rchild != NULL || p2->rchild != NULL) //如果p1的右子树为空,但是p2的右子树不为空,或者相反
return false;
//访问完两棵树的当前结点后,置空让下一次循环弹出栈中元素(此处其实直接弹出元素也行)
p1 = NULL;
p2 = NULL;
}
else if(p1 != NULL || p2 != NULL) //当前节点有一个为空
return false;
else
{
//弹出两个树的栈顶元素
p1 = _sta1.top();
p2 = _sta2.top();
_sta1.pop();
_sta2.pop();
}
}
return true;
} //递归判断两棵树是否相似
bool IsSemblable2(BiTree T1,BiTree T2)
{
bool leftS = false,rightS = false; //用来接受子树返回的信息
if(T1 == NULL && T2 == NULL) //两个结点都为空
return true;
else if(T1 == NULL || T2 == NULL) //有一个结点不为空
return false;
else
{
int leftS = IsSemblable2(T1->lchild,T2->lchild); //递归左子树
int rightS = IsSemblable2(T1->rchild,T2->rchild); //递归右子树
return leftS && rightS ; //返回两个子树的信息
}
}注:其中“#”表示的是空格,空格字符代表空树。
2、叶子结点数及深度:
按先序遍历序列建立一个二叉树的二叉链表,统计二叉树中叶子结点个数和二叉树的深度。
#include
using namespace std;
template
struct BTNode{
T data;
BTNode * Lchild,*Rchild;
};
template
void createBinTree(BTNode * & root)
{
BTNode* p = root;
BTNode* k;
T nodeValue;
cin>>nodeValue;
if(nodeValue=='#') {root=NULL;}
else {root=new BTNode();root->data=nodeValue;createBinTree(root->Lchild);createBinTree(root->Rchild);}
}
template
int countNode(BTNode * & p)
{ if(p==NULL) return 0;
else if(p->Lchild==NULL&&p->Rchild==NULL) return 1;
return countNode(p->Lchild)+countNode(p->Rchild);
}
template
int depth(BTNode *& p) {
if(p == NULL) return 0;
int h1 = depth(p->Lchild); int h2 = depth(p->Rchild); if(h1>h2)return (h1+1); return h2+1; }
int main()
{
BTNode *rootNode=NULL;
createBinTree(rootNode);
cout<<"leafs="<
#include
using namespace std;
template
struct BTNode{
T data;
BTNode * Lchild,*Rchild;
};
template
void createBinTree(BTNode * & root)
{
BTNode* p = root;
BTNode* k;
T nodeValue;
cin>>nodeValue;
if(nodeValue=='#') {root=NULL;}
else {root=new BTNode();root->data=nodeValue;createBinTree(root->Lchild);createBinTree(root->Rchild);}
}
template
void preOrder( BTNode * & p)
{ if(p)
{cout<data<<" ";
preOrder(p->Lchild);
preOrder(p->Rchild);}
}
template
void inOrder(BTNode * & p)
{if(p)
{inOrder(p->Lchild);
cout<data<<" ";
inOrder(p->Rchild);}
}
template
void levelOrder(BTNode *& p)
{ if(p)
{levelOrder(p->Lchild);
levelOrder(p->Rchild);
cout<data<<" ";}
}
int main()
{
BTNode *rootNode=NULL;
createBinTree(rootNode);
cout<<"前序遍历结果:";preOrder(rootNode);cout<