Java线程怎样映射到操作系统线程
先说多线程模型,参考经典教材《Operating System Concepts , Silberschatz ,9th edition》
中文版是《操作系统概念,第9版》

https://www.cs.uic.edu/~jbell/CourseNotes/OperatingSystems/4_Threads.html
一个线程是CPU利用率的基本单元,包括一个程序计数器,堆栈,一组寄存器和线程ID。
传统(重量级)进程具有单个控制线程 - 有一个程序计数器,以及可在任何给定时间执行的一系列指令。
如图4.1所示,多线程应用程序在单个进程中具有多个线程,每个线程都有自己的程序计数器,堆栈和寄存器集,但共享公共代码,数据和某些结构(如打开文件)。
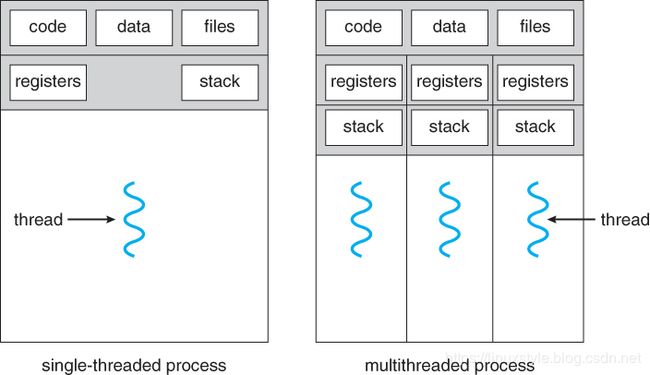
图4.1 - 单线程和多线程进程
多线程有四大类优点:
响应性 - 一个线程可以提供快速响应,而其他线程被阻塞或减慢进行密集计算。
资源共享 - 默认情况下,线程共享公共代码,数据和其他资源,这允许在单个地址空间中同时执行多个任务。
经济 - 创建和管理线程(以及它们之间的上下文切换)比为进程执行相同的任务要快得多。
可伸缩性,即多处理器体系结构的利用 - 单线程进程只能在一个CPU上运行,无论有多少可用,而多线程应用程序的执行可能在可用处理器之间分配。(请注意,当有多个进程争用CPU时,即当负载平均值高于某个特定阈值时,单线程进程仍然可以从多处理器体系结构中受益。)
多核编程
计算机体系结构的最新趋势是在单个芯片上生产具有多个核心或CPU的芯片。
在传统的单核芯片上运行的多线程应用程序必须交错线程,如图4.3所示。

但是,在多核芯片上,线程可以分布在可用内核上,从而实现真正的并行处理,如图4.4所示。
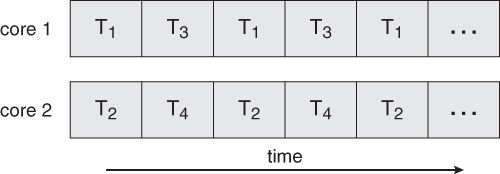
对于操作系统,多核芯片需要新的调度算法以更好地利用可用的多个核。
随着多线程变得越来越普遍和越来越重要(数千而不是数十个线程),CPU已被开发用于支持硬件中每个核心更多的同步线程。
多核芯片的挑战
识别任务 - 检查应用程序以查找可以同时执行的活动。
平衡 - 查找同时运行的任务,提供相同的价值。即不要浪费一些线程来完成琐碎的任务。
数据拆分 - 防止线程相互干扰。
数据依赖性 - 如果一个任务依赖于另一个任务的结果,则需要同步任务以确保以正确的顺序进行访问。
测试和调试 - 在并行处理情况下本身就更加困难,因为竞争条件变得更加复杂和难以识别。
并行类型
从理论上讲,有两种不同的工作负载并行化方法:
数据并行性
在多个核(线程)之间划分数据,并在数据的每个子集上执行相同的任务。例如,将大图像分成多个片段并对不同核心上的每个片段执行相同的数字图像处理。
任务并行性
划分要在不同核心之间执行的不同任务并同时执行它们。
在实践中,任何程序都不会仅仅由这些中的一个或另一个划分,而是通过某种混合组合。
多线程模型
在现代系统中有两种类型的线程需要管理:用户线程和内核线程。
用户线程由内核支持,而不需要内核管理。这些是应用程序员将在其程序中添加的线程。
内核线程由操作系统本身支持和管理。所有现代操作系统都支持内核级线程,允许内核同时执行多个同时任务或服务多个内核系统调用。
在特定实现中,必须使用以下策略之一将用户线程映射到内核线程。
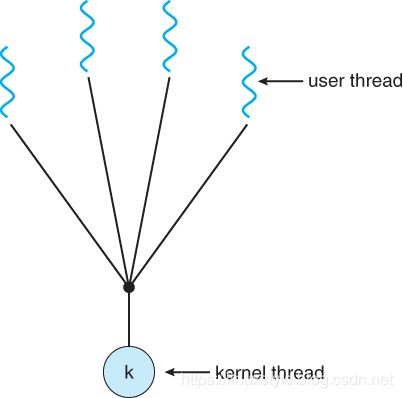
多对一模型
在多对一模型中,许多用户级线程都映射到单个内核线程。
线程管理由用户空间中的线程库处理,这非常有效。
但是,如果进行了阻塞系统调用,那么即使其他用户线程能够继续,整个进程也会阻塞。
由于单个内核线程只能在单个CPU上运行,因此多对一模型不允许在多个CPU之间拆分单个进程。
Solaris和GNU可移植线程的绿色线程在过去实现了多对一模型,但现在很少有系统继续这样做。
一对一模型
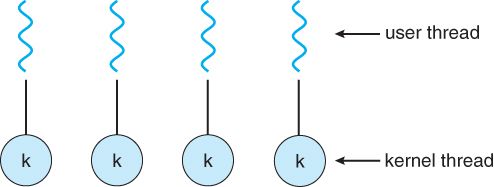
一对一模型创建一个单独的内核线程来处理每个用户线程。
一对一模型克服了上面列出的问题,涉及阻止系统调用和跨多个CPU分离进程。
但是,管理一对一模型的开销更大,涉及更多开销和减慢系统速度。
此模型的大多数实现都限制了可以创建的线程数。
Windows(从Win95开始)和Linux都实现了线程的一对一模型。
多对多模型
多对多模型将任意数量的用户线程复用到相同或更少数量的内核线程上,结合了一对一和多对一模型的最佳特性。
用户对创建的线程数没有限制。
阻止内核系统调用不会阻止整个进程。
进程可以分布在多个处理器上。
可以为各个进程分配可变数量的内核线程,具体取决于存在的CPU数量和其他因素。
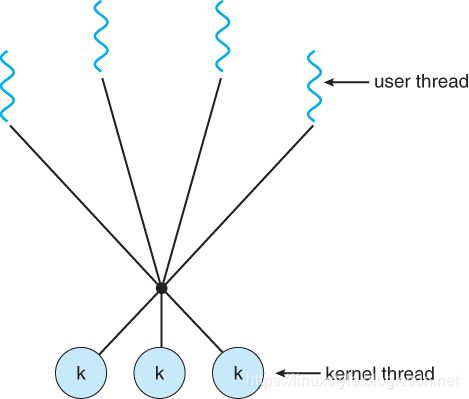
多对多模型的一个流行变体是双层模型,它允许多对多或一对一操作。
IRIX,HP-UX和Tru64 UNIX使用双层模型,Solaris 9之前的Solaris也是如此。
线程库
线程库为程序员提供了用于创建和管理线程的API。
线程库可以在用户空间或内核空间中实现。前者涉及仅在用户空间内实现的API函数,没有内核支持。后者涉及系统调用,并且需要具有线程库支持的内核。
三个主要的线程库:
POSIX Pthreads - 可以作为用户或内核库提供,作为POSIX标准的扩展。
Win32线程 - 在Windows系统上作为内核级库提供。
Java线程 - 由于Java通常在Java虚拟机上运行,因此线程的实现基于JVM运行的任何操作系统和硬件,即Pthreads或Win32线程,具体取决于系统。
Java线程
所有Java程序都使用Threads - 甚至是“常见的”单线程程序。
新线程的创建需要实现Runnable接口的对象,这意味着它们包含一个方法“public void run()”。Thread类的任何后代自然都会包含这样的方法。(实际上,必须重写/提供run()方法,以使线程具有任何实际功能。)
创建线程对象不会启动线程运行 - 为此,程序必须调用Thread的“start()”方法。Start()为Thread分配并初始化内存,然后调用run()方法。(程序员不直接调用run()。)
因为Java不支持全局变量,所以必须将Threads传递给共享Object的引用才能共享数据。
请注意,JVM在本机操作系统之上运行,并且JVM规范未指定用于将Java线程映射到内核线程的模型。此决定取决于JVM实现,可能是一对一,多对多或多对一..(在UNIX系统上,JVM通常使用PThreads,而在Windows系统上,它通常使用Windows线程。)
《Java中的全局变量》Java中没有全局变量的概念,关键字static定义的全局类公共字段。
线程池
每次需要创建新线程然后在完成时删除它可能效率低下,并且还可能导致创建非常大(无限)的线程数。
另一种解决方案是在进程首次启动时创建多个线程,并将这些线程放入线程池中。根据需要从池中分配线程,并在不再需要时返回池。如果池中没有可用的线程,则该进程可能必须等到一个可用。
线程池中可用的(最大)线程数可以由可调参数确定,可能动态地响应于改变的系统负载。
Win32通过“PoolFunction”函数提供线程池。Java还通过java.util.concurrent包为线程池提供支持,Apple支持Grand Central Dispatch架构下的线程池。
信号处理
问:当多线程进程收到信号时,该信号应传递到哪个线程?
答:有四个主要选择:
将信号传递给信号所适用的线程。
将信号传递给过程中的每个线程。
将信号传递给过程中的某些线程。
分配特定线程以接收进程中的所有信号。
最佳选择可能取决于涉及哪个特定信号。
UNIX允许各个线程指示它们接受哪些信号以及它们忽略哪些信号。但是,信号只能传递给一个线程,这通常是接受该特定信号的第一个线程。
UNIX提供了两个独立的系统调用:kill(pid,signal)和pthread_kill(tid,signal),分别用于向进程或特定线程传递信号。
Windows不支持信号,但可以使用异步过程调用(APC)模拟它们。APC被传递到特定线程,而不是进程。
线程取消
不再需要的线程可能会被另一个线程以两种方式之一取消:
异步取消立即取消线程。
延迟取消设置一个标志,指示线程在方便时应自行取消。然后由取消的线程定期检查此标志,并在看到标志设置时很好地退出。
异步取消(共享)资源分配和线程间数据传输可能会有问题。
线程局部存储
大多数数据在线程之间共享,这是首先使用线程的主要好处之一。
但是,有时线程也需要特定于线程的数据。
大多数主要线程库(pThreads,Win32,Java)都支持特定于线程的数据,称为线程本地存储或TLS。请注意,这更像是静态数据而不是局部变量,因为它在函数结束时不会停止存在。
Linux线程
Linux不区分进程和线程 - 它使用更通用的术语“Task”。
传统的fork()系统调用完全复制了一个进程(Task),如前所述。
另一个系统调用clone()允许父和子任务之间的不同程度的共享,由下表中显示的Flag控制:

调用没有设置Flag的clone()等同于fork()。使用CLONE_FS,CLONE_VM,CLONE_SIGHAND和CLONE_FILES调用clone()等同于创建线程,因为所有这些数据结构都将被共享。
Linux使用结构task_struct实现这一点,该结构实质上为任务资源提供了间接级别。如果未设置标志,则复制结构指向的资源,但如果设置了标志,则仅复制指向资源的指针,因此共享资源。(想想深层复制与OO编程中的浅层复制。)
Linux的几个发行版现在支持NPTL(Native POXIS Thread Library)
符合POSIX标准。
支持SMP(对称多处理),NUMA(非统一内存访问)和多核处理器。
支持数百到数千个线程。
《Linux 线程模型的比较:LinuxThreads 和 NPTL》
当 Linux 最初开发时,在内核中并不能真正支持线程。但是它的确可以通过 clone() 系统调用将进程作为可调度的实体。这个调用创建了调用进程(calling process)的一个拷贝,这个拷贝与调用进程共享相同的地址空间。LinuxThreads 项目使用这个调用来完全在用户空间模拟对线程的支持。不幸的是,这种方法有一些缺点,尤其是在信号处理、调度和进程间同步原语方面都存在问题。另外,这个线程模型也不符合 POSIX 的要求。
要改进 LinuxThreads,非常明显我们需要内核的支持,并且需要重写线程库。有两个相互竞争的项目开始来满足这些要求。一个包括 IBM 的开发人员的团队开展了 NGPT(Next-Generation POSIX Threads)项目。同时,Red Hat 的一些开发人员开展了 NPTL 项目。NGPT 在 2003 年中期被放弃了,把这个领域完全留给了 NPTL。
NPTL,或称为 Native POSIX Thread Library,是 Linux 线程的一个新实现,它克服了 LinuxThreads 的缺点,同时也符合 POSIX 的需求。与 LinuxThreads 相比,它在性能和稳定性方面都提供了重大的改进。与 LinuxThreads 一样,NPTL 也实现了一对一的模型。
《著名的c10k论文》
虽然有点老,但是还是值得一读。
注意:1:1线程与M:N线程
在实现线程库时有一个选择:您可以将所有线程支持放在内核中(这称为1:1线程模型),或者您可以将其中的相当一部分移动到用户空间(这称为M:N线程模型)。有一点,M:N被认为是更高的性能,但它太复杂了,很难做到正确,大多数人都在远离它。
《Java线程如何映射到OS线程?》
JVM线程映射到OS线程是一种常见的读取语句。但这究竟意味着什么呢?我们在java中创建Thread对象并调用其start方法来启动新线程。它是如何启动OS线程的?以及如何将Thread对象的run方法附加到执行的OS线程?
调用start0方法,该方法被声明为本机方法。“native”标记告诉JVM这是一个特定于平台的本机方法(用C / C ++编写),需要通过java本机接口调用。JNI是Java的本机方法接口规范,它详细说明了本机代码如何与JVM集成,反之亦然。(https://docs.oracle.com/javase/9/docs/specs/jni/design.html#jni-interface-functions-and-pointers)
从Java到C++,以JVM的角度看Java线程的创建与运行
参考:【JVM源码探秘】深入理解Thread.run()底层实现
以jdk8为例:
通过new java.lang.Thread.start()来启动一个线程,只需要将业务逻辑放在run()方法里即可,启动一个Java线程,调用start()方法:
在\openjdk-8u40-src-b25-10_feb_2015\openjdk\jdk\src\share\classes\java\lang\Thread.java

在启动一个线程时会调用start0()这个native方法,关于本地方法的注册请参照【JVM源码探秘】深入registerNatives()底层实现
在Java的系统包下如:
java.lang.System
java.lang.Object
java.lang.Class
都有一个静态块用来执行一个叫做registerNatives()的native方法:

\openjdk-8u40-src-b25-10_feb_2015\openjdk\jdk\src\share\native\java\lang\Thread.c
start0对应JVM_StartThread
VM_StartThread方法位于\openjdk-8u40-src-b25-10_feb_2015\openjdk\hotspot\src\share\vm\prims\jvm.cpp
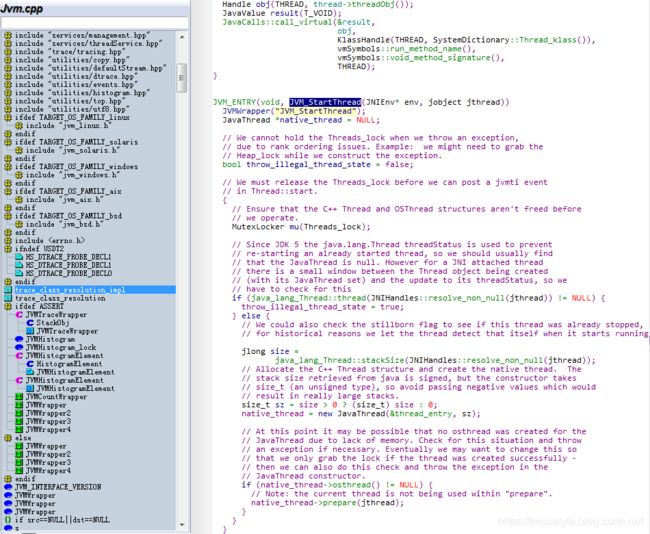
//分配C ++ Thread结构并创建本机线程。该
//从java检索的堆栈大小已签名,但构造函数需要
// size_t(无符号类型),因此请避免传递负值
//导致非常大的堆栈。
代码native_thread = new JavaThread(&thread_entry, sz);用于创建JavaThread实例,位于
\openjdk-8u40-src-b25-10_feb_2015\openjdk\hotspot\src\share\vm\runtime\thread.cpp
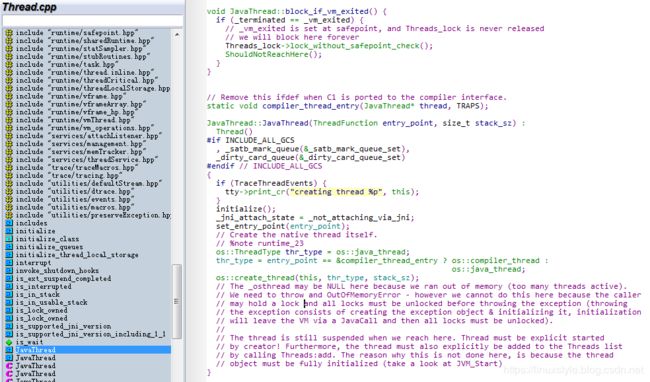
//这里的_osthread可能为NULL,因为我们的内存不足(活动的线程太多)。
//我们需要抛出OutOfMemoryError - 但是我们不能这样做,因为调用者
//可能会持有一个锁,并且在抛出异常之前必须解锁所有锁(抛出
//异常包括创建异常对象并初始化它,初始化
//将通过JavaCall离开VM,然后必须解锁所有锁。
//当我们到达这里时,线程仍然被暂停 线程必须显式启动
//由创作者! 此外,线程还必须显式添加到“线程”列表中
//通过调用Threads:add。 之所以没有这样做,是因为线程
//对象必须完全初始化(看看JVM_Start)
通过OS创建线程,位于\openjdk-8u40-src-b25-10_feb_2015\openjdk\hotspot\src\os\linux\vm\os_linux.cpp
bool os::create_thread(Thread* thread, ThreadType thr_type, size_t stack_size) {
assert(thread->osthread() == NULL, "caller responsible");
// Allocate the OSThread object
OSThread* osthread = new OSThread(NULL, NULL);
if (osthread == NULL) {
return false;
}
// set the correct thread state
osthread->set_thread_type(thr_type);
// Initial state is ALLOCATED but not INITIALIZED
osthread->set_state(ALLOCATED);
thread->set_osthread(osthread);
// init thread attributes
pthread_attr_t attr;
pthread_attr_init(&attr);
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED);
// stack size
if (os::Linux::supports_variable_stack_size()) {
// calculate stack size if it's not specified by caller
if (stack_size == 0) {
stack_size = os::Linux::default_stack_size(thr_type);
switch (thr_type) {
case os::java_thread:
// Java threads use ThreadStackSize which default value can be
// changed with the flag -Xss
assert (JavaThread::stack_size_at_create() > 0, "this should be set");
stack_size = JavaThread::stack_size_at_create();
break;
case os::compiler_thread:
if (CompilerThreadStackSize > 0) {
stack_size = (size_t)(CompilerThreadStackSize * K);
break;
} // else fall through:
// use VMThreadStackSize if CompilerThreadStackSize is not defined
case os::vm_thread:
case os::pgc_thread:
case os::cgc_thread:
case os::watcher_thread:
if (VMThreadStackSize > 0) stack_size = (size_t)(VMThreadStackSize * K);
break;
}
}
stack_size = MAX2(stack_size, os::Linux::min_stack_allowed);
pthread_attr_setstacksize(&attr, stack_size);
} else {
// let pthread_create() pick the default value.
}
// glibc guard page
pthread_attr_setguardsize(&attr, os::Linux::default_guard_size(thr_type));
ThreadState state;
{
// Serialize thread creation if we are running with fixed stack LinuxThreads
bool lock = os::Linux::is_LinuxThreads() && !os::Linux::is_floating_stack();
if (lock) {
os::Linux::createThread_lock()->lock_without_safepoint_check();
}
pthread_t tid;
int ret = pthread_create(&tid, &attr, (void* (*)(void*)) java_start, thread);
pthread_attr_destroy(&attr);
if (ret != 0) {
if (PrintMiscellaneous && (Verbose || WizardMode)) {
perror("pthread_create()");
}
// Need to clean up stuff we've allocated so far
thread->set_osthread(NULL);
delete osthread;
if (lock) os::Linux::createThread_lock()->unlock();
return false;
}
// Store pthread info into the OSThread
osthread->set_pthread_id(tid);
// Wait until child thread is either initialized or aborted
{
Monitor* sync_with_child = osthread->startThread_lock();
MutexLockerEx ml(sync_with_child, Mutex::_no_safepoint_check_flag);
while ((state = osthread->get_state()) == ALLOCATED) {
sync_with_child->wait(Mutex::_no_safepoint_check_flag);
}
}
if (lock) {
os::Linux::createThread_lock()->unlock();
}
}
// Aborted due to thread limit being reached
if (state == ZOMBIE) {
thread->set_osthread(NULL);
delete osthread;
return false;
}
// The thread is returned suspended (in state INITIALIZED),
// and is started higher up in the call chain
assert(state == INITIALIZED, "race condition");
return true;
}
主要是
// 调用系统库创建线程,thread_native_entry为本地Java线程执行入口 //
int ret = pthread_create(&tid, &attr, (void* (*)(void*)) thread_native_entry, thread);
这个方法是C++创建线程的库方法,通过调用这个方法,会创建一个C++ 线程并使线程进入就绪状态,即可以开始运行