哈夫曼树/最优二叉树(WPL)(C语言实现)
哈夫曼树/最优二叉树(C语言实现)
带权路径长度(WPL):设二叉树有n个叶子结点,每个叶子结点带有权值Wκ,从根结点到每个叶子结点的长度为lκ,则每个叶子结点的带权路径长度之和就是WPL=∑Wκ•lκ(n,i=1)。
哈夫曼树/最优二叉树:WPL最小二叉树。
举个栗子(WPL)
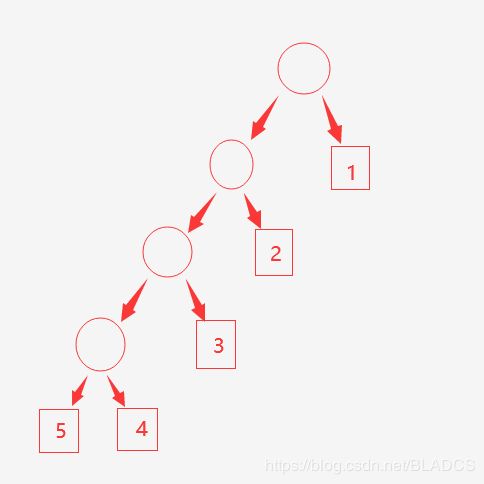
它的WPL=∑Wκ•lκ(n,i=1)=11+22+33+44+5*4=50
哈夫曼树就是要找WPL最小的树。
哈夫曼树的构造
每次把最小的两棵二叉树合并。将数据储存在最小堆中,每次找出最小的并从最小堆中删除。
这其实是一个找出数列其中最小的两个数,作为叶子,然后从数列中删除这两个数。用这两个数的和sum作为叶子的根,再将根值插入数列中。其过程为:
- 在堆中找出最小两个数a,b
- 从数列中删除a,b。并求和a+b=sum
- 建立哈夫曼树,a,b作为叶子结点,sum作为叶子的父节点
- 再将sum插入数列中
- 循环
C语言实现如下:
typedef struct TreeNode *HuffmanTree;
struct TreeNode{
int Weight;
HuffmanTree Left;
HuffmanTree Right;
}
HuffmanTree Huffman(MinHeap H){
int i;
HuffmanTree T;
BuildMinHeap(H);//按权值调整为最小堆
//H->size-1次合并,建树
for(int i = 1;i < H->Size;i++){
T = malloc(sizeof(struct TreeNode));
T->Left=DeleteMin(H);//从最小堆中删除一个结点,作为新T的左子结点
T->Right=DeleteMin(H);//从最小堆中删除一个结点,作为新T的右子结点
//计算权值
T->Weight=T->Left->Weight + T->Right->Weight;
Insert(H,T);
}
T=DeleteMin(H);
return T;
}
其实这里的堆只是为了找出最小的数,和方便插入数据。任何可以实现它的功能的方法都可以使用。
哈夫曼树的特点
1.没有度为1的结点
2.如果哈夫曼树有n个叶结点,则这棵树共有2n-1个结点
3.哈夫曼树的任意非叶结点的左右子树交换后仍是哈夫曼树。
4.相同的WPL,可能有不同构的哈夫曼树。
如果将结点记为其叶结点的和,那么所有非叶子结点的和也是权值。例如:

wpl=9+12+14+15=50
哈夫曼编码
假如储存一个只有a,b,c,d,e,f,g的共50个文本。则:
(1)用等长的ASCII编码:508=400;
(2)用等长的3位编码。503=150;
(3)不等长编码:出现频率高的字符用编码短些,出现频率低的用编码长些。
因为储存的是0和1,在长短不一的时候就会出现二义性。前缀码:避免二义性。
解决的就是二叉树用于编码。
当所有的字符都在叶结点的时候就不会出现一个字符的编码是另一个字符的前缀。
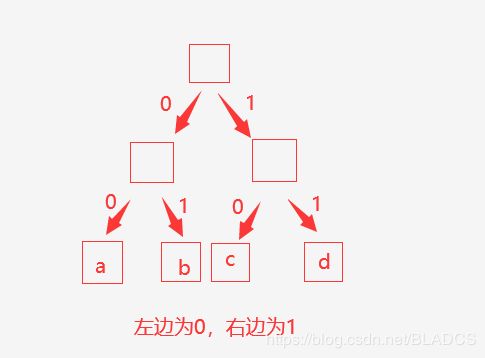
如图字符a的编码就是00,b:01,c:10,d:11
给出任何一段由上面编成的编码,都可以唯一翻译出正确字符。
哈夫曼编码的构造
根据a,b,c,d出现的频率不同就可以构建出WPL最小的哈夫曼树。用它储存文本的总长度就是最小的。
这里abcd的频率就是权值了,用他们构建出哈夫曼树。然后哈夫曼树从根结点到各叶结点的路径就是哈夫曼编码了。